-
【CMU15-445 Part-7】Tree Indexes i
Part07-Tree Indexes
-
hash vs Tree Index
hash table 仅在单点查询能够起到比较好的作用,范围查询效率很低,故后面引入了B plus Tree to query
-
table index
- 表索引就是我们表中属性的一个子集的一个副本,我们将它以一种更为高效的方式进行存储。
- index is a replica of the table 意味着要和表进行同步,插入之后也要更新表的索引。
可以使用大量的索引来加速查询,但是也要消耗一定的代价来维护索引,两者之间存在取舍。
B Tree Family
关系,有一类数据结构就叫做B Tree,然后里面有一种特定的数据结构叫做B Tree
B Tree
- B Tree,1971
- B+ Tree,1973
- B* Tree
- B l i n k T r e e B^{link} \, Tree BlinkTree
总之,有时候将B Tree和B+ Tree都叫做B Tree
B+ Tree
是self-balancing tree data structure,B means Balance,当插入数据的时候会保证数据的有序性,这允许我们可以沿着叶子节点进行高效的搜索或者循序扫描。
插入以及删除的复杂度是 O ( l o g n ) O(log \,\, n) O(logn)
优点
遍历到B+ Tree底部的时候可以沿着叶子节点进行扫描,顺序读取,不需要再back up。
Properties
B+ Tree是M路搜索树,多路查找树,特点:
- Perfectly balanced,每个叶子节点都是同样的深度
- 每个节点除了根,都是至少half-full, M 2 − 1 ≤ k e y s ≤ M − 1 \frac{M}{2}-1 \le keys \le M-1 2M−1≤keys≤M−1。注意最多是M-1个节点。
- 每个inner node 如果保存了K个keys,那么有K+1个非空孩子节点,K的大小最大是M-1。
示意图:
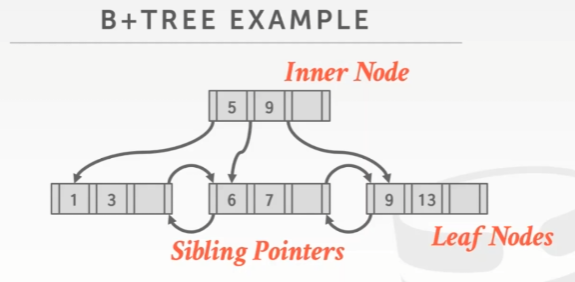
任何inner node之间没有sibling pointer,只有叶子节点(leaf nodes)之间有
- Inner Node: [node* | key] ,也就是指针和key的结合体,使用key来进行寻径
- Leaf Node:[value | key],**这里的value可以是tuple的record ID也可以是tuple本身。**如下图,开头结尾是兄弟指针,可以存放node id或者page id,或者null。
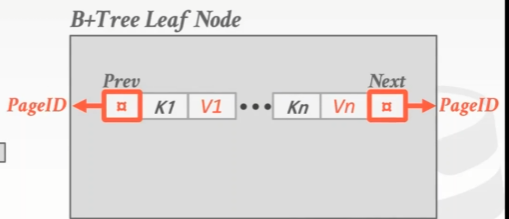
但是,实际上没有数据库会这样保存一个B+ 树叶子节点的KV对,一般都是分别分开保存。就像slotted page里面的header。
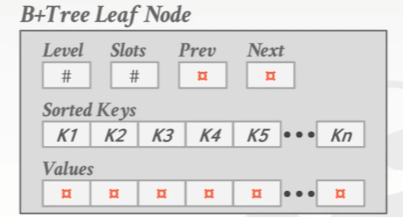
Leaf Node Values
- Record Ids:一个指向tuple位置的指针
- Tuple Data:
- 叶子节点里面存放tuple实际的内容
- secondary indexer have to store the record id as their values.
B-Tree VS. B+ Tree
-
在原始的B-树中,value可以存放在树的任意位置(inner node & leaf node),B+ Tree value(record id & tuple) 只能放在leaf node。这样做的原因
-
B树中,不会有重复的Key;B+ Tree 会有重复的key?yes!如下图,因为inner node用来索引,真正的key存在于leaf中,所以leaf和inner必然会重复的key。此外,如果删除了一个key,在B+树里面肯定会在left node把对应的删除,但是可能会把他保存在inner node里面不一定删除,因为还要用来寻径。

-
-
没人用B树的原因:当你用多个线程来进行更新操作的时候,代价会很昂贵。因为节点可以上下移动,inner 和 leaf可以变换。 修改inner node,并发下要锁latch他的指针(向上并且向下传播),所以会慢。
-
B+ Tree search 最终都要到leaf节点上看有没有,inner有的key不算。
B+ Tree Insert
- 向下遍历,find correct leaf node L to insert,找到要插入的叶子节点L
- 将要插入的数据按照node L的顺序放入
- 如果L有足够的空间,结束
- 如果L没有足够的空间:将L里面的keys进行拆分split为L和新的节点L2,具体:
- 将中间位置左边的所有key放入一个节点,右边的所有key放入另外一个节点
- 更新父节点,让父节点包含这个中间key,增加一个额外的指针指向新添加的节点,父节点可能会递归下去。
Max Degree D在B+树里面一般是指出来的路线有D条,Key有D-1条。
B+ Tree Delete
- 从根节点开始,找到要删除的entry所在的叶子节点L
- 删除该entry
- 如果L仍然至少半满,结束
- 如果L只有m/2 - 1,要rebalanced
- 看它的sibling节点,借一个key,来平衡。兄弟节点要和该节点有相同的父节点。
- 借不到,只能Merge。将sibling和当前节点的key合并在一起
Clustered Indexed
数据库的table heap是无序的,想要数据按照浓重顺序排序,例如primary Key,就叫做聚簇索引(Clustered Index),数据库系统会保证:索引会对page中tuple的物理布局进行匹配排序,即对磁盘上实际数据重新组织以按照指定的一个列或者多个列的值的大小进行排序。
MySQL将tuple保存在叶子节点上,保证磁盘上apge的tuple都是以主键顺序来排序的。PG支持,也可以指定以什么来聚簇索引,但是不会自动维护maintain,所以一开始是有序的后面慢慢就无序了。
Selection Conditions
相比hash table的优势
例如,index on
-
利用B+ Tree使用复合键索引
简单查询,在A和B上设计一个复合索引,查询KEY = (A,B) 如下:
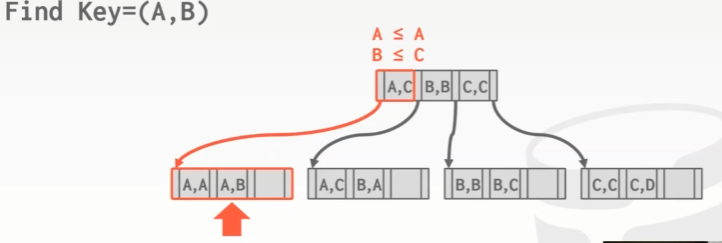
前缀查询,Find Key = (A , *),找到起点,循序扫描,直到遇到≥ 我Composite Key为止,结束搜索。
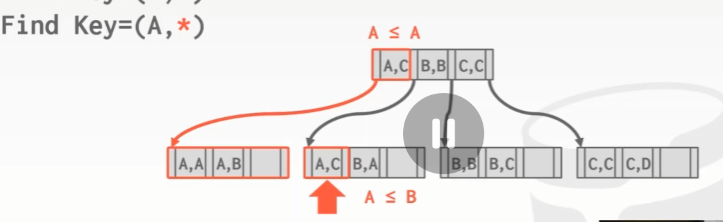
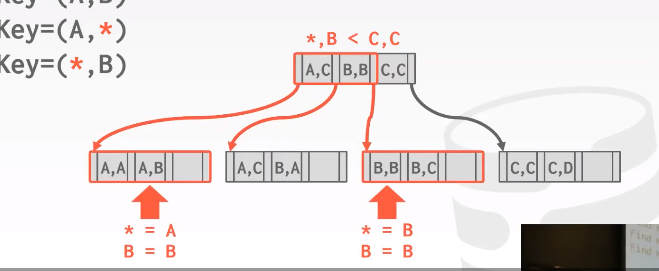
后缀查询,Find Key = (,B) 最难。我们要在根节点弄清楚需要去查看该树的哪一部分。只有前两个(A,C) (B,B) 才能满足第二个key的要求,(C,C)一定 > B 所以不需要去看。使用多个索引探针或者进行多次遍历,也就是用不同的值来替换。换成 A,B B,B 两个独立的查找,然后合并结果。Oracle 把这个叫做 skip scan
-
一个node 是 一个page 其实我不太理解?
这样M是不是会超大? 还是说key 占的bit比较大?
Node Size
机械硬盘:1MB SSD 10KB 内存512B。

理解:磁盘速度慢,节点要大一些,这样每次磁盘IO可以多读一些。如果跳到不同节点随机IO速度快,节点可以用更小的Size。
Leaf Node Scans
使用耗时长的循序扫描,更适合于比较大的节点。如果是随机IO 则想要体积更小的节点
Merge Threshold
在实际情况中,如果有不到半满的可能不想要立即合并,因为可能又接着插入,减少了合并拆分的代价。延迟处理!
Variable Length Keys
可变长的key。实际当中,value是固定长度的,key不一定。
Approach #1: Pointers
保存指向该属性或者tuple的指针。例如key是varchar,不会直接保存barchar,而是保存他的record id到节点中。 速度会变慢,因为需要二次去取出key来查看,保存的数据量减少,因为保存的是指针不是key。
Everyboy stores the keys always in the node.
Approach #2: Variable Length Nodes
可变长度的节点。node的size可以根据所保存的东西来变化大小,需要carefule memory management,没人用~
Approach #3: Padding
填充。不管key多大多小,使用null或者0给他填充,直到达到最大的size,设定的node size。
Approach #4: Key Map / Indirection
间接映射。将key的指针放在key的数组中,这里的指针实际是node中对应的offset值,不能指向其他的page。 利用node的基地址 + key map里面存的offset就能够在该page中取得对应的key。如下图:
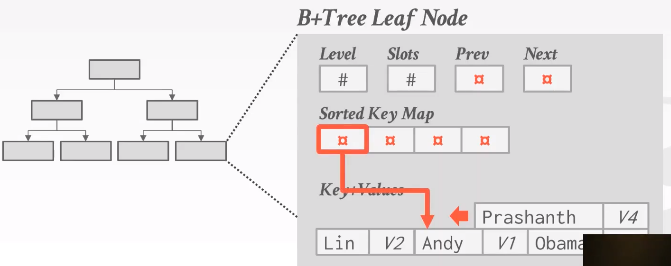
key + values 从后向前增长,sorted key map从前向后增长。
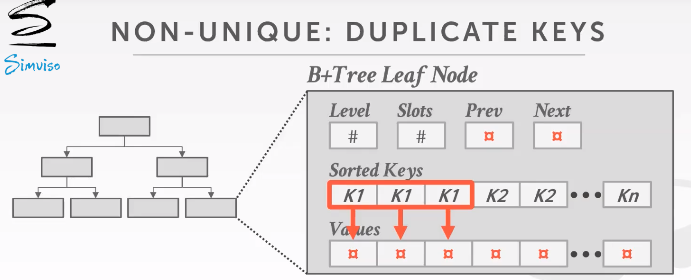
Non-unique Indexes
非唯一索引
Approach #1: Duplicate Keys
Approach #2: Value Lists
只保存key一次,使用一个单独的区域来保存给定key的所有value。
db 会记录是否是主键、唯一索引等等,在查询的时候叶子节点可以查到一个就结束,或者查到不是再end。
Intra-node Search
节点内对key进行搜索的方式
Approach #1: Linear
线性扫描
Approach #2: Binary
二分查询,key按顺序排序。
Approach #3: Interpolation
如果大概知道你的key的值,可以估计key所在的大概位置,并且要知道大概的key的分布函数(情况)。
例子:比如key=8,然后长度为7,知道最大值为10,那么10-8=2,然后7-2=5,那么可以从第五个位置开始搜索,这是最小起点。(但是貌似这种假设基于key都是整数?)理解一下,因为key最大为10,那么和8差两个数,最小每次加一,就是往前数两个位置,但是这个是需要前提假设的。
Optimizations
优化B+ Tree,查询加速。
Prefix Compression
前缀压缩。基于key都是有序排列的。例如如下key
robbed robbing robot 无须重复存储冗余字符串rob。提出相同前缀,变成如下情况
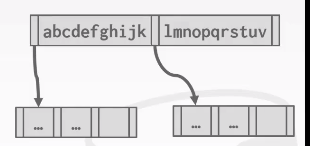
prefix:rob bed bing ot Suffix Truncation
后缀截断。基本思路:我们无需在inner node里面存储完整的key值以此来弄清楚我们是该往左走还是往右走。如下图,不需要全看就能知道往左走还是往右走,第一个就够了。在inner node存储能够区分key的唯一前缀即可。
可以修改成类似于二级索引比较的思路。需要维护。
Bulk Inserts
批量插入。
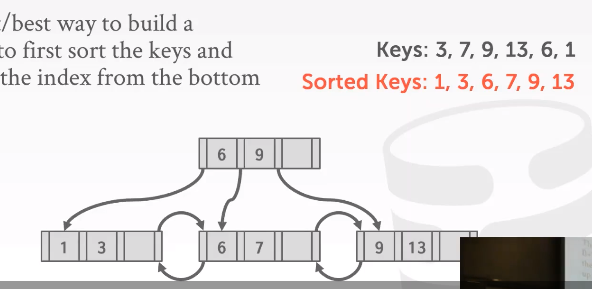
当拥有了要插入的全部Key,有一个fastest and best way to build a B+ Tree,自下而上去构建索引。
- 对key排序
- 构建叶子节点
- 自下而上构建inner node
Pointer Swizzling
指针旋转。我们保存的不是原始的内存指针,而是page id。下图,比如要找到比3大的key,怎么从根节点到下面叶子节点呢?指针保存了pageid,比如他在page #2,就到buffer pool去取该page,也就是访问该节点了。访问兄弟节点也是一样的。到buffer pool将page id转换为该page 的 指针。
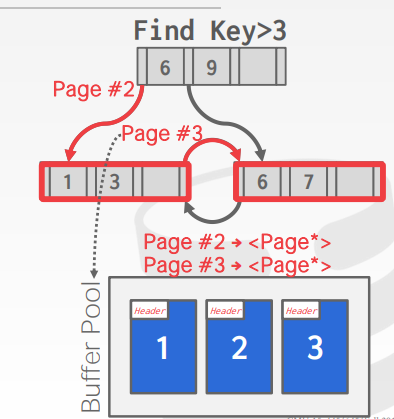
上面的方法非常expensive,因为需要latches来保护buffer pool里面的hash table(page table maybe)。
所以指针旋转pointer swizzling的思路是:如果我知道所有固定在内存的page,指针域不保存page id而是直接保存page 的指针。就不需要取buffer pool ask了。
延伸一下,这种pinning 的 page尽量是B+ Tree的inner node的上层,因为用的多,这样会加快速度。
-
-
相关阅读:
k线图分析法
程序产生自我意识,创造人工生命
视频修复工具助你完成高质量的视频作品!
python-爬虫(可直接使用)
[LCT刷题][边双缩点] P2542 [AHOI2005] 航线规划
随便看看官方教程-FPS Microgame
Fresco 图片框架简单使用
English语法_介词搭配
【Linux】单机版QQ之管道中的命名管道
如何拿捏个人电脑
- 原文地址:https://blog.csdn.net/qq_47865838/article/details/127827461