-
meta learning(李宏毅
meta 元
meta learning: learn to learn 学习如何学习
大部分的时候deep learning就是在调hyperparameter、调hyperparameter真的很烦,决定什么network的架构啊、决定learning rate啊等等、

实际上没有什么好方法来调这些hyperparameter、今天业界最常拿来解决调hyperparameter的方法呢就是买很多张gpu了、
他们训练model的时候就像是这个翻车鱼一样、一次训练多个model、有的train不起来就丢掉、最后只看那些可以串起来的model、他会得到什么样的performance
所以在业界,做实验时 往往就是一次开个1000张gpu、1000张gpu跑1000组不同的hyperparameter、看看哪一组hyperparameter可以给你最好的结果好
其实说1000都是低估了。那些大公司在采买gpu的时候、单位都是用万来算的、这次要买3万张gpu这种等级啊
所以业界今天在deep learning上的规模 真的是跟学界是不太一样啊
但是学界 没有这个多gpu。。在学校每个人只有一张gpu、凭着你的经验跟直觉定义一组好的hyperparameter、祈祷可以得到好的结果
hyperparameter能不能用学的?这就是meta learning其中一个可以帮助我们的事情

讲解meta learning之前,先回顾一下machine learning的三个步骤:
- 定义一个未知的function,用 fθ 表示,θ是未知的参数,需要学出来。

2. 定义一个Loss function。L(θ)

3. 优化Loss function。找一个参数θ*,让Loss越小越好。

接下来介绍Meta Learning。什么是Meta Learning呢?
其实“学习”这件事 本身也是一个func.
一个machine learning的algorithm、简化来看,其实它就是一个function(F)
输入:data set;输出:训练完的结果,e.g. classifier

Meta Learning也分为3个步骤:
1. 确定learning algorithm中要被学的东西。
像机器学习里,我们说neuron的weight和bias是要被学出来的
在这里 那就看你什么东西想要让机器自己帮你决定、那那些就是要被学出来的东西
比如network结构、初始化参数、学习率等等。需要学习的部分统称为 ϕ 。
那其实不同的mata learning的方法、它就是想办法去学不同的learning algorithm中的component

2. 为learning algorithm定义loss function L(ϕ) ,
如何决定L?在一般的机器学习中,L 来自于训练资料
Meta Learning里训练资料是什么?Meta Learning里 我们收集的是训练的任务
假设你今天想要训练一个binary classifier,那你要准备很多二元分类的任务. 比如task1分别苹果和橘子 task2分别车和脚踏车
L包括训练任务,训练集以及测试集。
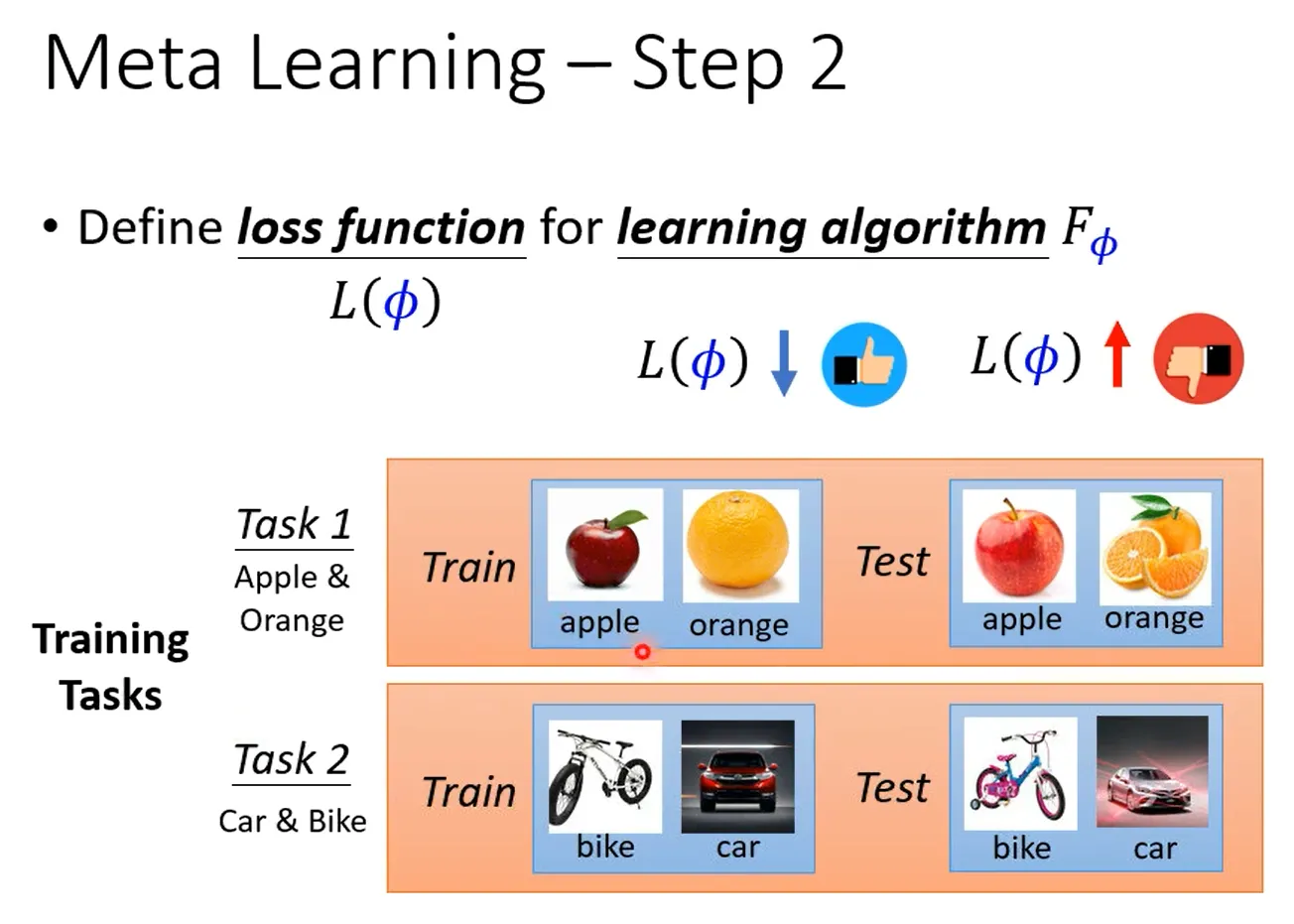
首先给network训练集,根据learning algorithm确定network,训练一个模型。如果这个模型效果是好的,那么说明learning algorithm是有效果的。


当然上述只是用在了一个任务上测试learning algorithm的效果,实际上应该还会给出好多个任务,每个任务虽然learning algorithm一样,但丢进去的资料不一样,产生的classifer也不一样。每个任务都重复上述步骤,并将最后的loss全加在一起让total loss最小。

这里可能有人会有疑问,上述方法在训练过程中用到了testing dataset,这在训练中应该是不被允许的啊。但是meta learning其实是以任务为单位的,是用已知的有限个任务(训练集和测试
-
相关阅读:
springboot基于spring的宽带管理系统以及实现毕业设计源码250910
Linux 环境搭建以及xshell远程连接
【MySQL篇】初识数据库
IntelliJ IDEA 2023 年下载、安装教程、好用插件推荐
项目管理之常见七大问题挑战
最廉价的5.1家庭影院系统解决方案
spring ioc源码解读
Java 数据结构总结
html盒子模型
Credit-based Flow Control的前世今生
- 原文地址:https://blog.csdn.net/linyuxi_loretta/article/details/127698934