-
Hadoop高手之路4-HDFS
文章目录

一、HDFS的简介
Hadoop的核心是HDFS和MapReduce。其中,HDFS是解决海量大数据文件存储的问题,是目前应用最广泛的分布式文件系统。
1. HDFS的演变
GFS(Google File System)->HDFS
HDFS 源于 Google 在2003年10月份发表的GFS(Google File System)论文,接下来,我们从传统的文件系统入手,开始学习分布式文件系统,以及分布式文件系统是如何演变而来?
1) 传统的文件系统
所谓传统的文件系统指的单机的文件系统,底层不会横跨多台机器实现。比如windows上的文件系统、 Linux上的文件系统、 FTP文件系统等。
这些文件系统的共同特征包括:
- 带有抽象的目录树结构,树都是从/根目录开始往下蔓延;
- 树中节点分为两类: 目录和文件;
- 从根目录开始,节点路径具有唯一性。
缺点:
- 当数据量越来越大时,会遇到存储的瓶颈,就需要扩容
- 由于文件过大,上传和下载都非常耗时
2) 分布式
扩容有两种方式,一种是纵向扩容,增加磁盘容量和内存,另一种是横向扩容,增加服务器的数量,这种存储形式就是分布式存储的雏形。

解决上传和下载就是将一个大文件分成多个数据块,将数据库以并行的方式进行存储

3) hdfs
大文件通过分块存储在服务器集群中,如何获取一个完整的文件呢?需要增加一台服务器,专门用来存储被分割后的数据块信息已经它的存储位置,这就是namenode,也就是HDFS的雏形
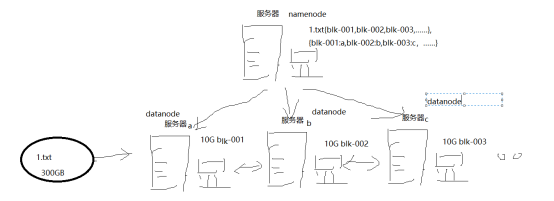
再添加备份机制,形成HDFS


2. HDFS的概念
1) NameNode(名称节点)
主节点(集群老大)以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问,主节点一旦关闭整个集群就无法访问。
2) DataNode(数据节点)
从节点,再namenode的管理下,存储访问数据
3) Block(数据块)
默认是128mb,且备份3份,每个数据块尽可能存储在不同的datanode中
4) Rack(机架)
用来存放集群服务器的机架,通过交换机进行通信,HDFS通过机架的感知策略,namenode能够确定每个datanode所在的机架id
5) Metadata(元数据)
有三种形式,一是维护HDFS的文件和目录的信息,如文件名、目录名、文件大小等,二是记录文件的内容,如数据分块情况,副本个数,每个副本所在的DataNode信息等,三是记录HDFS中所有DataNode的信息,用于DataNode的管理
二、HDFS的特点
1. 优点
1) 高容错
2) 流式数据访问
3) 支持超大文件
4) 高数据吞吐量
5) 可构建在廉价的集群上
2. 缺点
1) 高延迟
2) 不适合小文件的存储
3) 不适合并发写入
三、HDFS的架构和原理
1. HDFS的存储架构
主从式
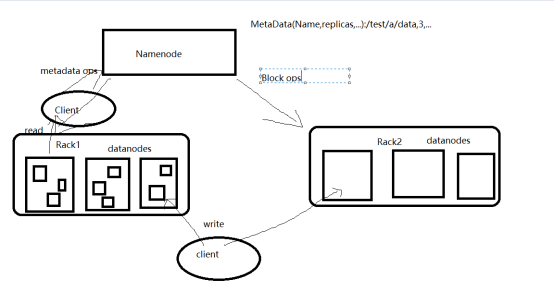
2. HDFS的文件读写原理
Client(客户端)对HDFS中的数据进行读写操作
1) HDFS写数据的原理
- 客户端发起文件的上传请求,通过RPC(远程过程调用)与NameNode建立通信
- NameNode检查元数据目录树
- 若系统目录树不存在该文件的相关信息,则客户端可以上传文件
- 客户端请求上传第一个Block,以及副本的数量
- NameNode检查元数据文件中datanode的信息池,找到可用的节点
- 将可用节点的IP返回给客户端
- 客户端请求一台服务器上传数据,建立管道pipeline
- 开始传送第一个数据块
- 传送成功后给出相应
- 依次进行下一个数据块的传送,直到全部数据传送完成。
2) HDFS读数据的流程
- 客户端向NameNode发出RPC的请求,获取数据块所在的位置
- Namenode会检查元数据文件,返回block块信息及副本的信息
- 客户端会选取排序靠前的Datanode来依次读取Block
- 客户端合并读取的全部block成一个完整的文件
四、HDFS的shell操作
有两种形式:
hadoop fs
hdfs dfs
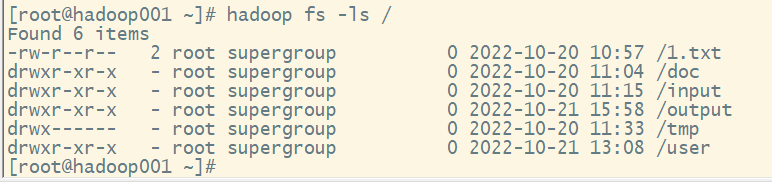
1.ls命令
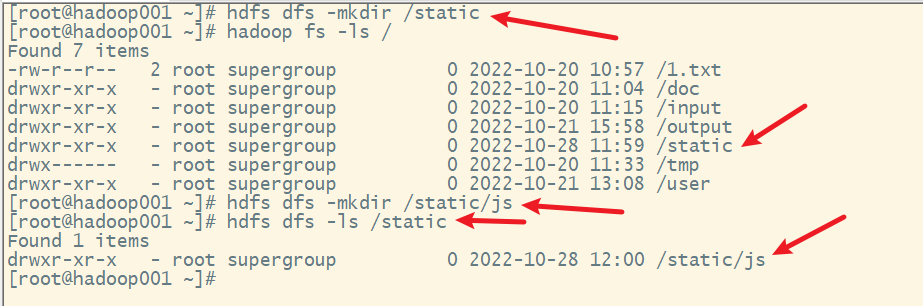
2. mkdir
创建子目录
格式
hdfs dfs -mkdir [-p] 子目录名
选项:
-p:递归创建各级子目录
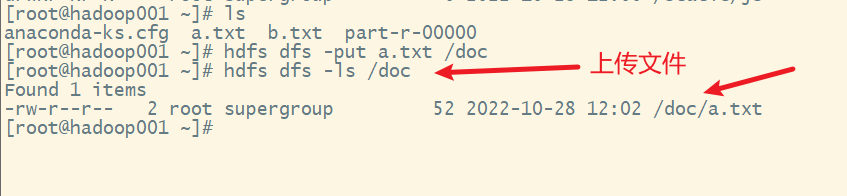
3. put命令
上传文件
格式:
hdfs dfs -put 源文件 目的文件
4. get命令
下载文件
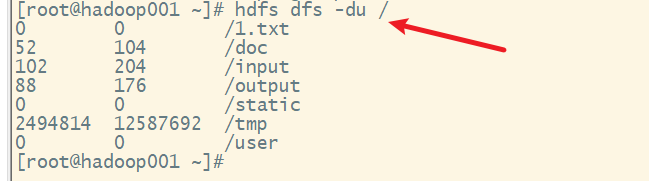
5. du命令
统计目录下所有文件的大小
6. mv命令
移动文件
7. cp
复制文件
8. rm
删除文件
9. cat
查看文件内容
10. help
获取帮助
五、HDFS的JAVA API操作
开发需要java环境,可以测试java是否已经安装,打开命令提示符
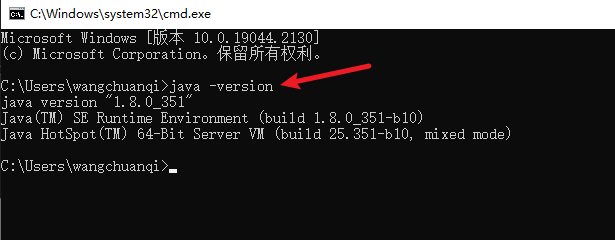
说明已经安装成功,如果没有出现上述界面,那么还需要安装java
1. 下载安装配置JDK
1) 下载JDK 1.8 64位安装包
可以直接在网上搜索下载

当然也可以去官网下载,需要注册且下载速度比较慢
官网:https://www.oracle.com/java/technologies/downloads/#java8
进入官网:
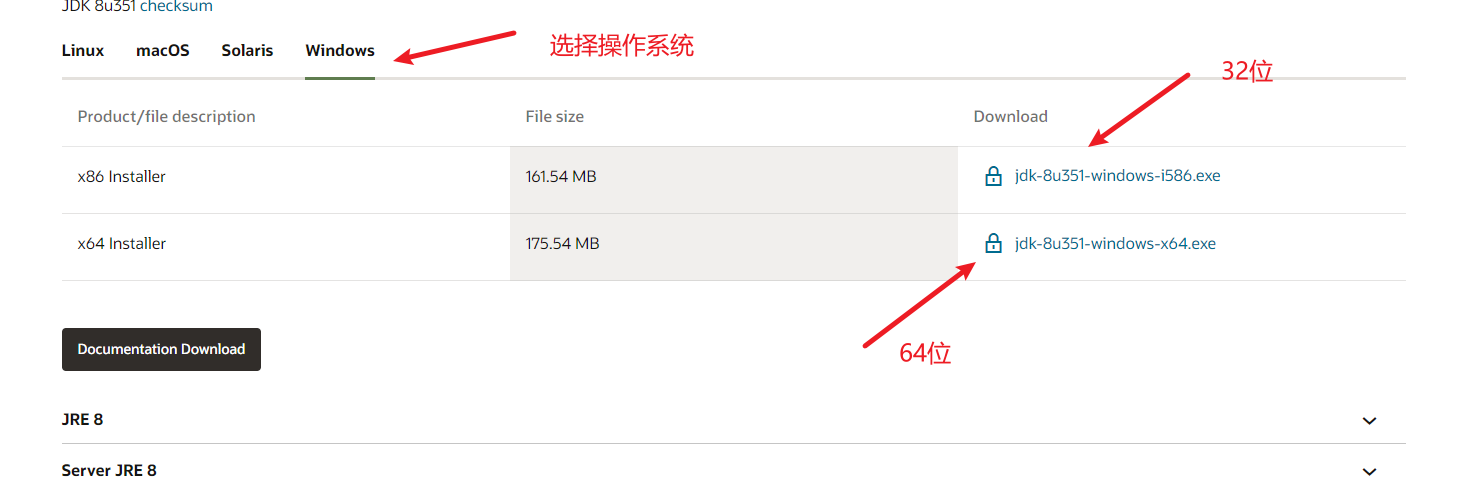
2) 安装
找到下载好的文件

点击下一步。

选择安装目录。

点击下一步

安装完成,点击关闭。
3) 配置环境变量
安装好环境,我们开始进行环境配置。
右击此电脑,点击属性。
点击高级系统设置。

点击环境变量。

点击新建系统变量。
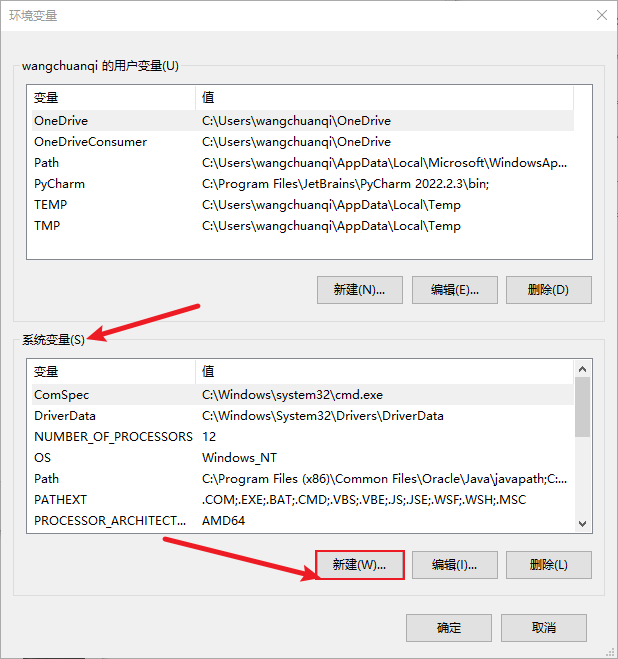
变量名为
JAVA_CLASS,变量值为刚安装的jre的路径,点击确定。
然后再新建
JAVA_HOME,变量值为刚安装的jdk的路径,点击确定。
然后我们找到
Path变量。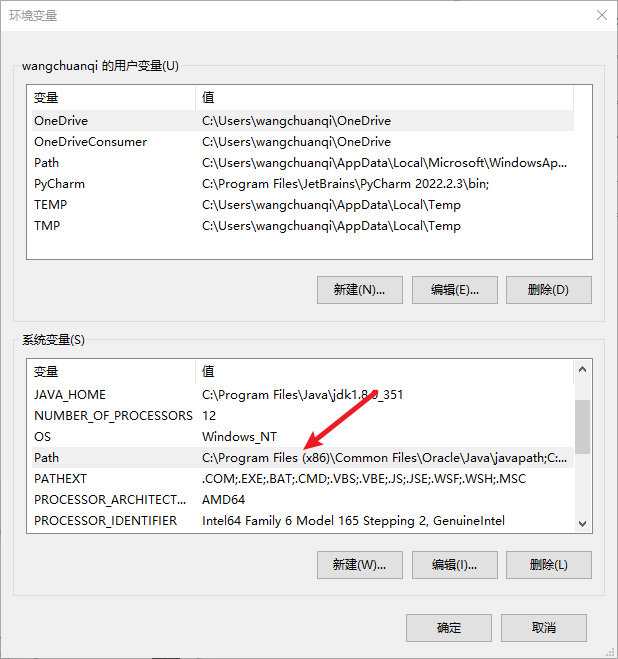
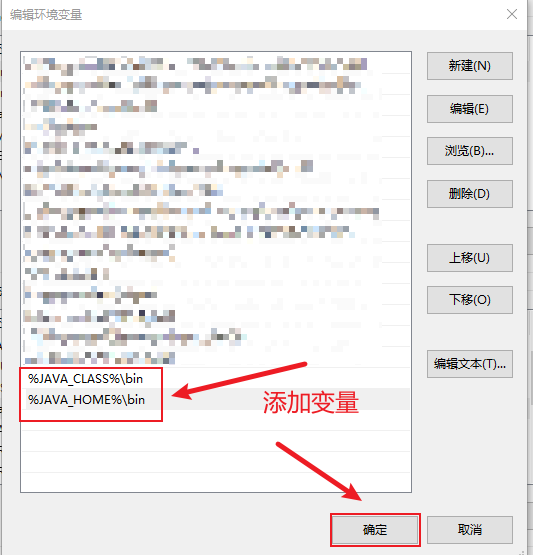
添加变量,完成后一路确定。
%JAVA_CLASS%\bin %JAVA_HOME%\bin- 1
- 2
2. 下载安装配置MAVEN
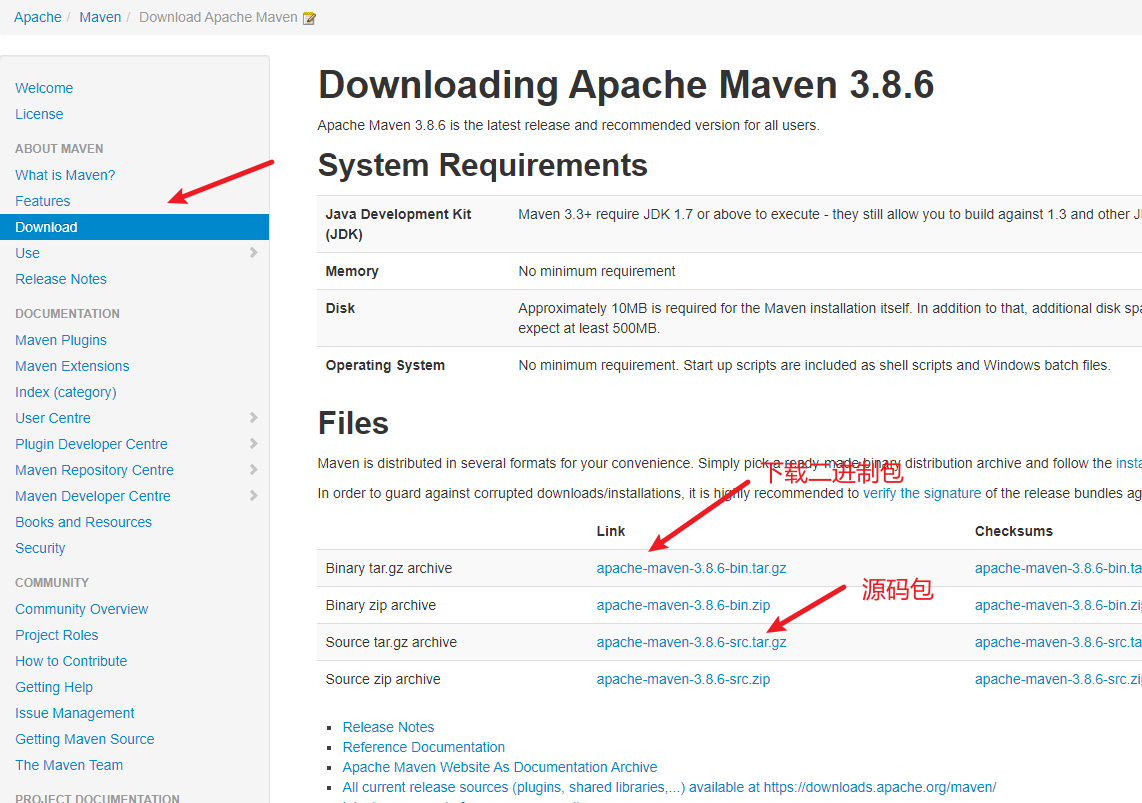
1) 下载


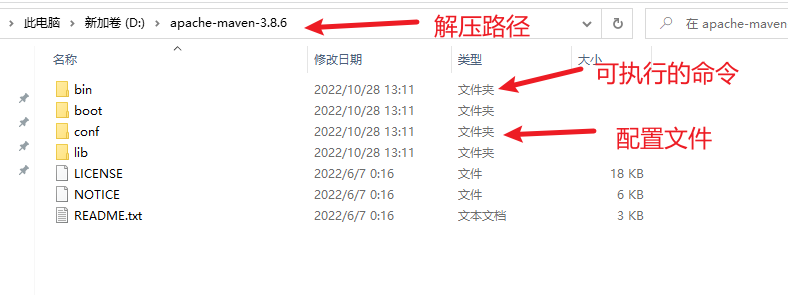
2) 解压
3) 配置环境变量

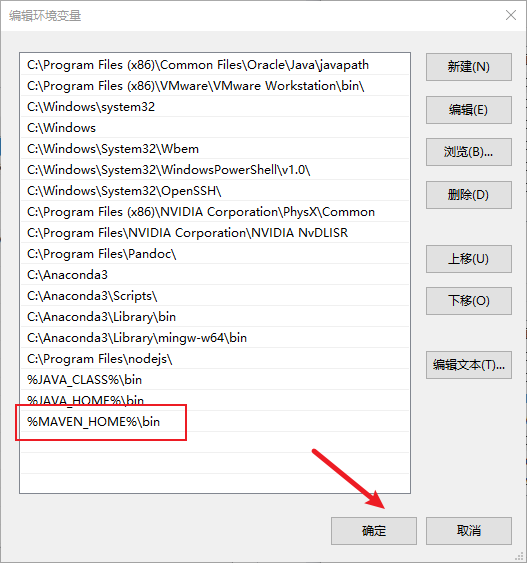
4) 测试是否安装成功

说明安装成功
3. 安装idea

下载后点击启动安装,完成安装
学生可以申请企业版免费使用,不过需要等7天时间
4. 创建一个maven项目,测试各环境是否正常允许
1) 启动idea,新建一个maven项目

点击create按钮,开始构建项目,下载依赖包
2) 项目结构

3) 新建一个包

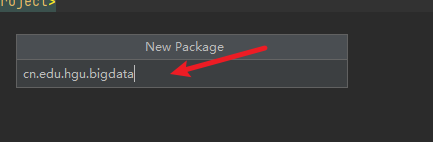
4) 在包下新建一个类



5) 输入代码
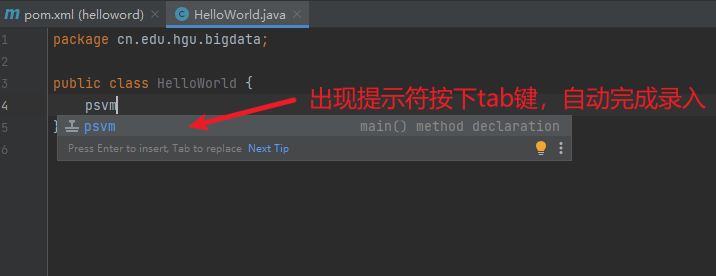
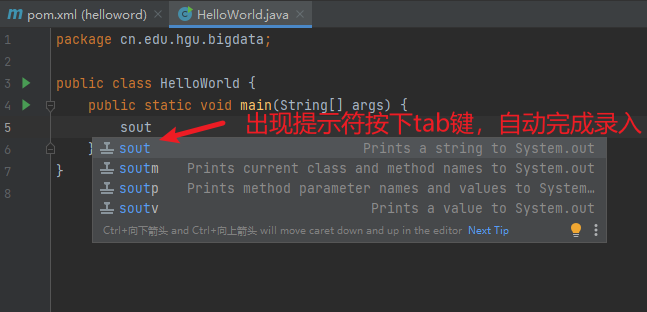
注意:这里使用tab和Enter(回车)都可以实现自动填充。

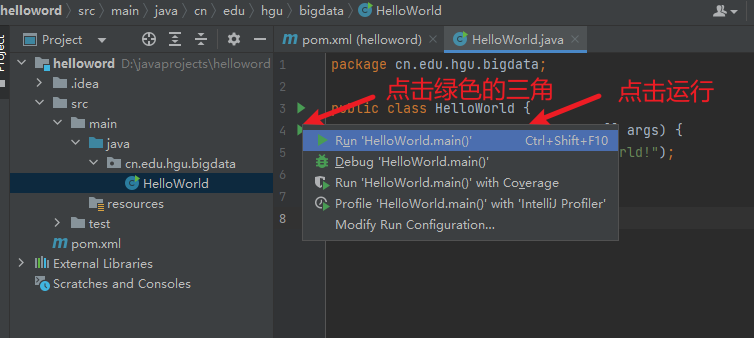
6) 运行,查看结果
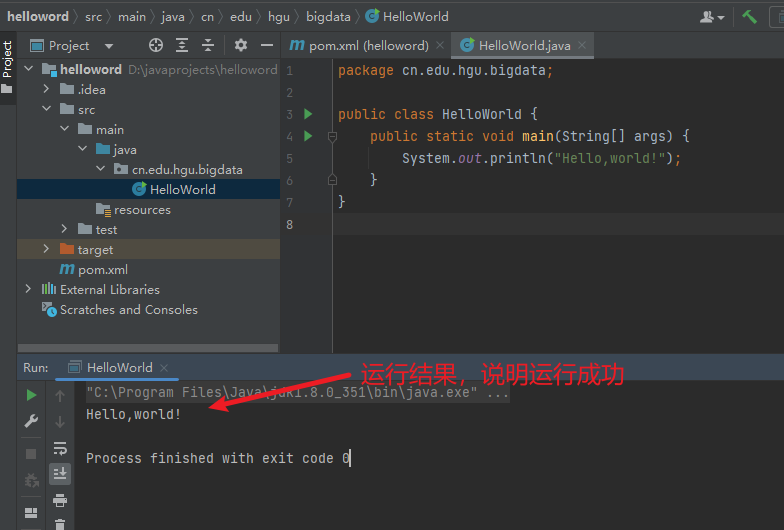
5. 给idea配置maven国内镜像库
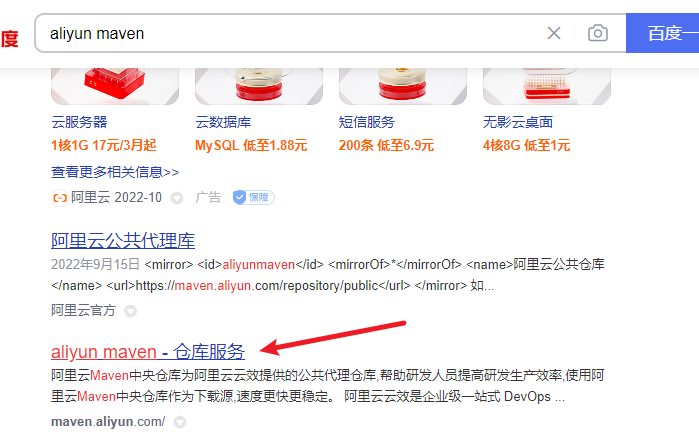
默认仓库在国外的站点,下载比较慢,需要maven的仓库位国内的镜像,一个配置位阿里的仓库镜像
1) 搜索aliyun的maven仓库服务

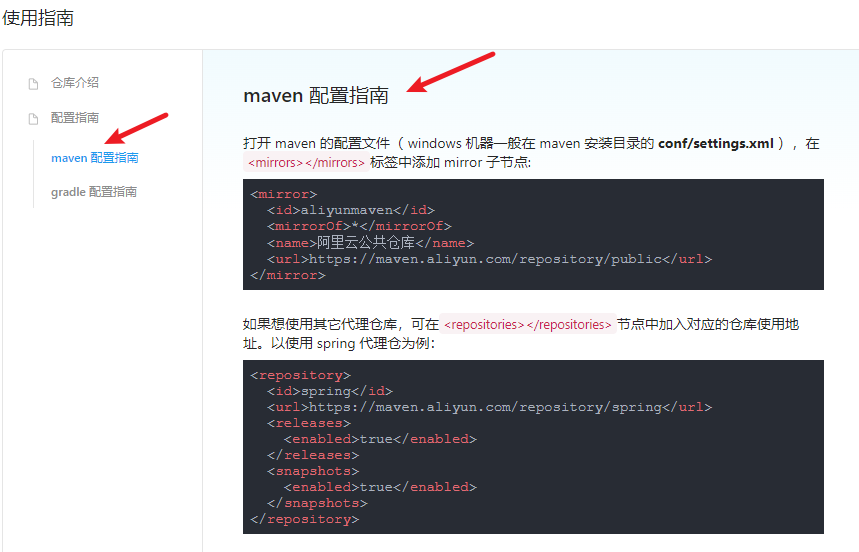

2)编辑 maven 配置文件
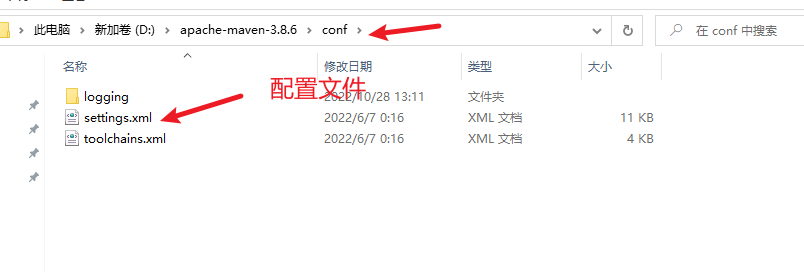
修改仓库为阿里云仓库服务的国内镜像
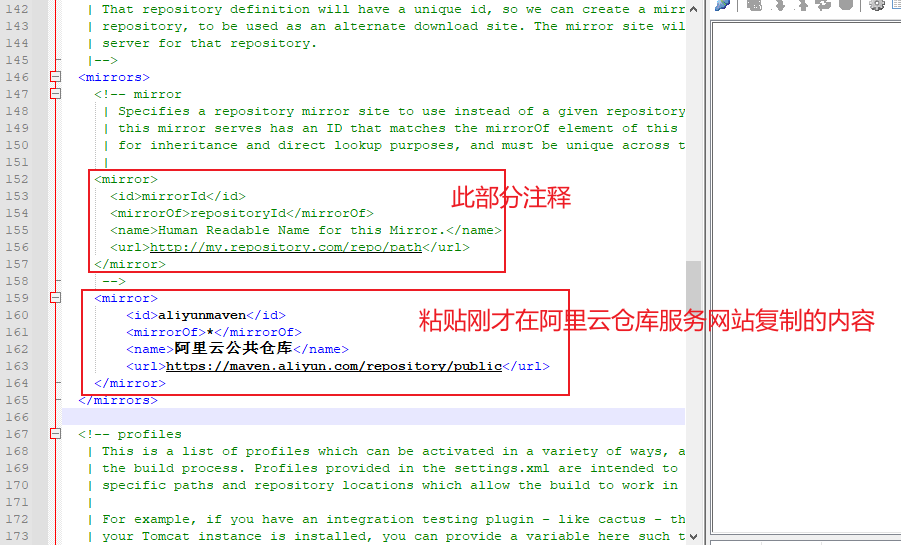
修改maven仓库的存放位置,默认在c盘,容易造成c盘空间满

修改为自定义文件夹
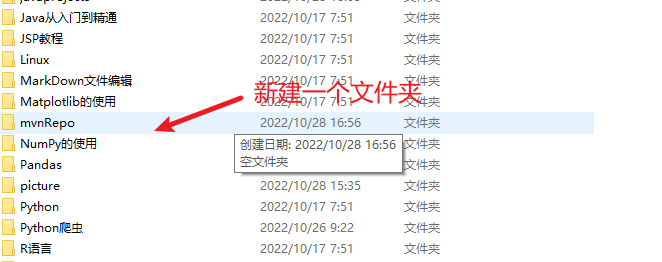
修改 maven 的配置文件

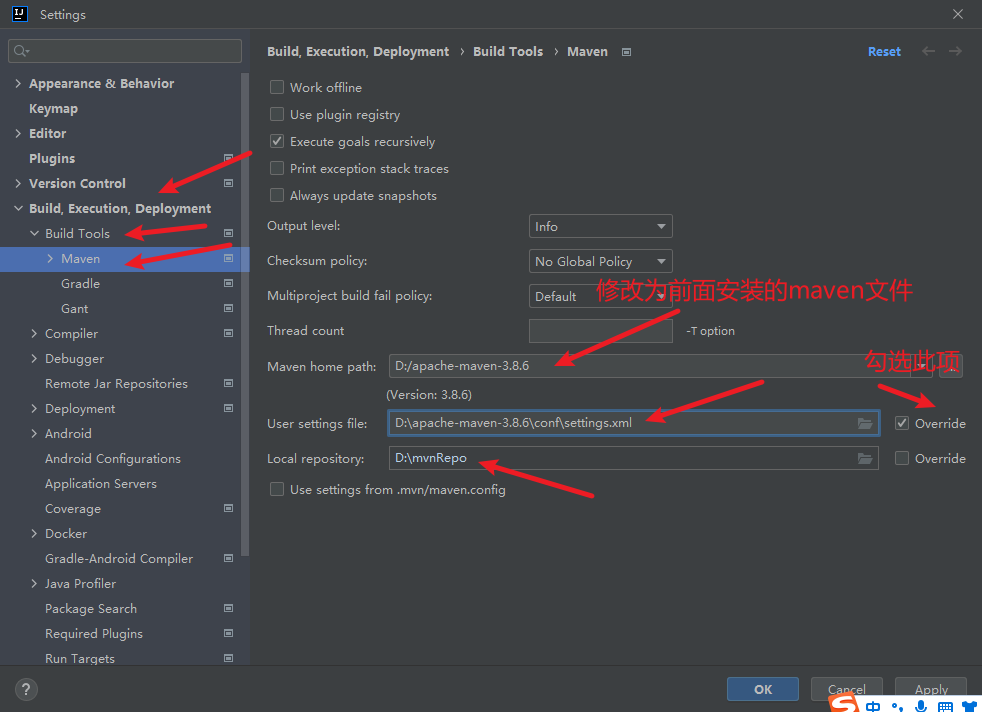
3) 修改idea的配置

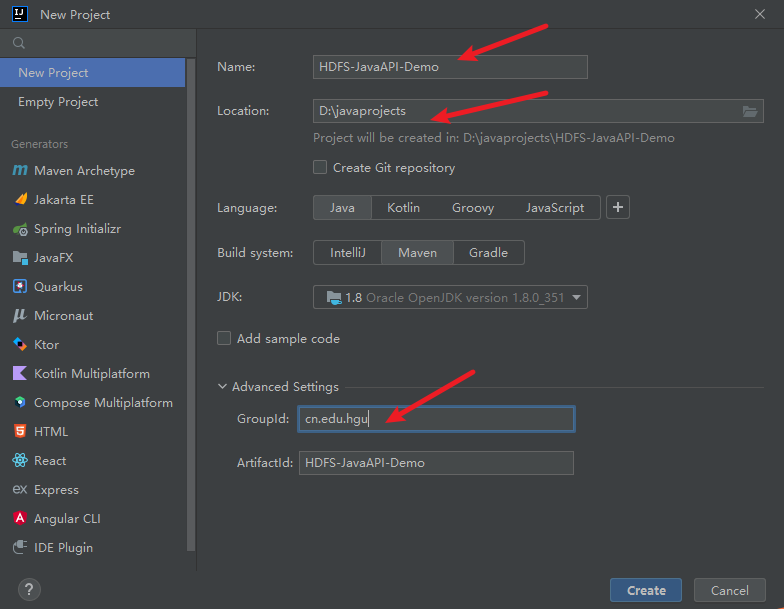
6. 案例-Java api操作HDFS
1) 新建一个maven项目
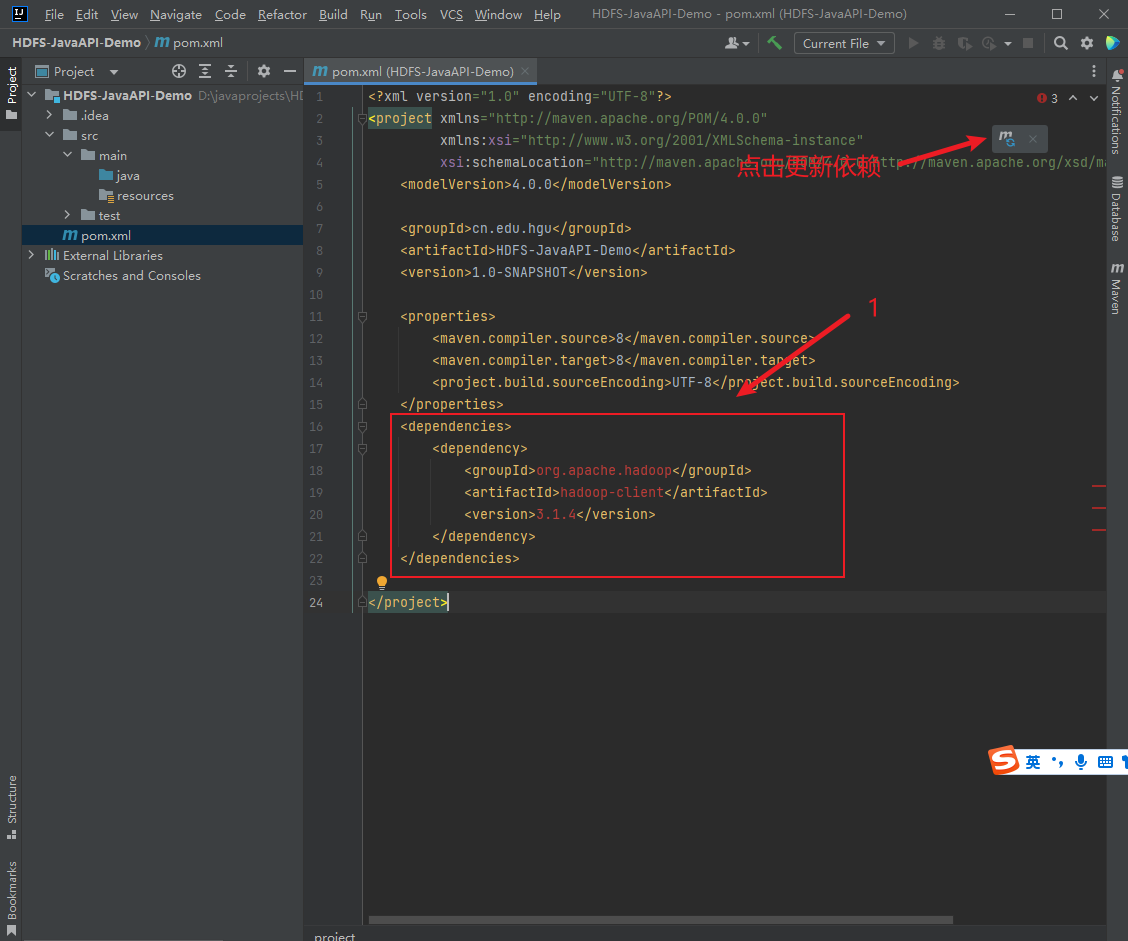
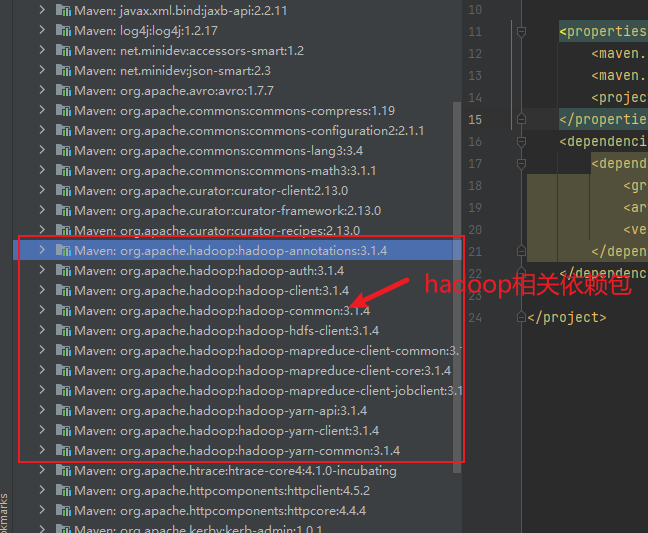
2) 修改pom文件,添加HDFS的依赖包

3) 新建相关的包和类
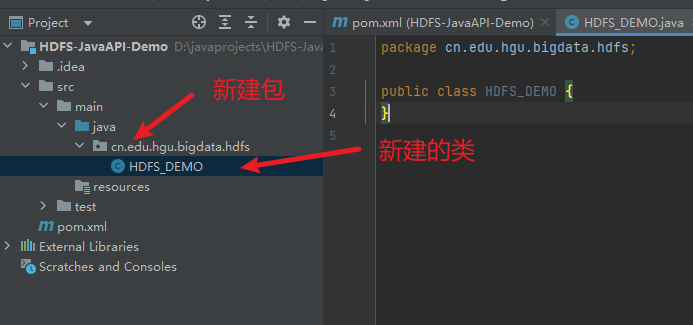
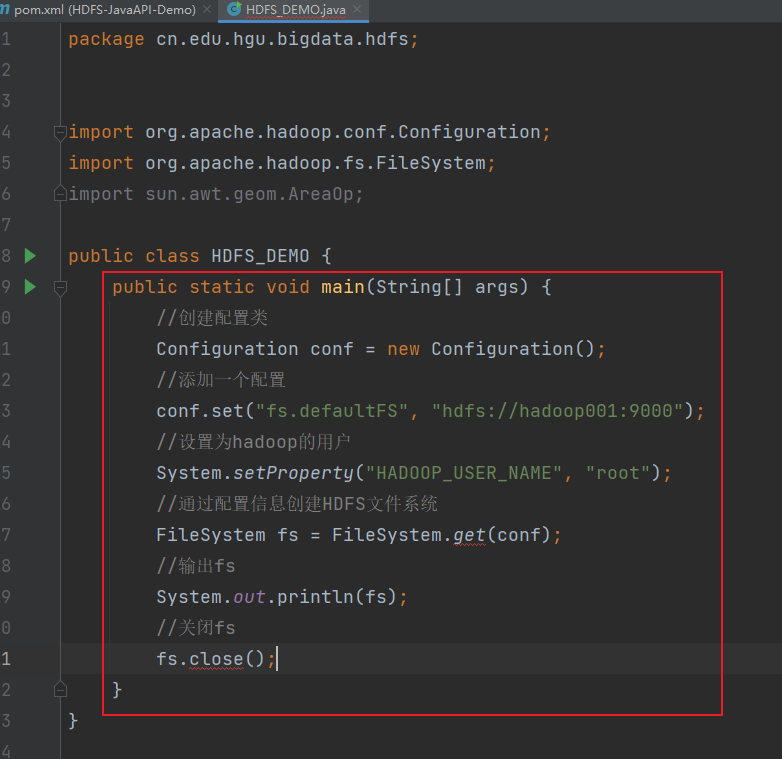
4) 编写代码,初始化HDFS客户端对象
输入如下代码
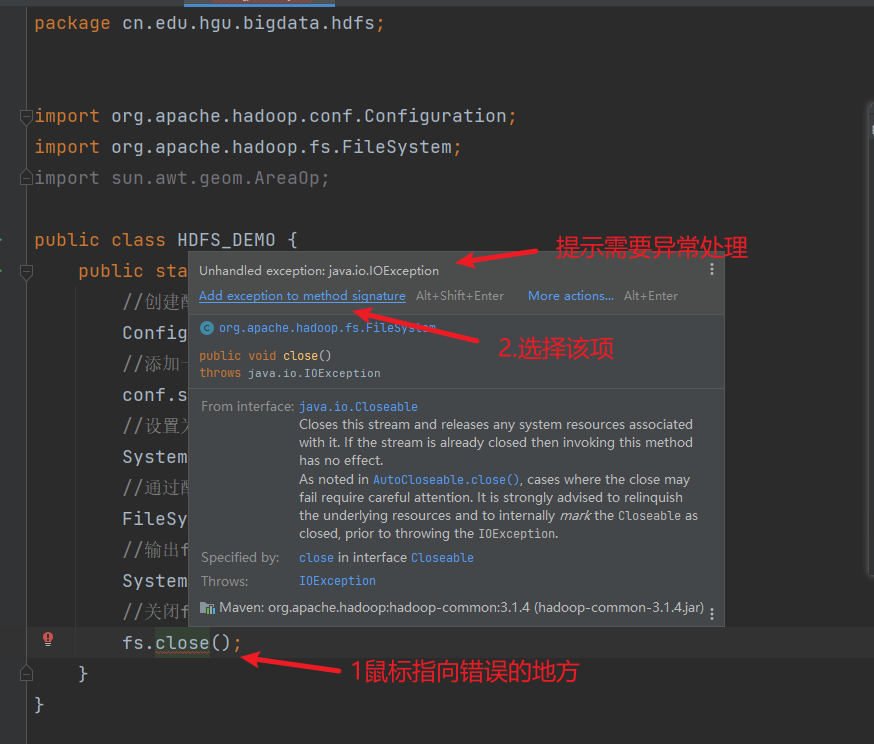
提示代码有错误

5) 运行查看结果


6) 在HDFS上创建一个文件夹

再次运行,查看结果
出现错误,提示连接拒绝,这是因为没有启动hadoop集群

7) 启动hdfs集群

webui查看
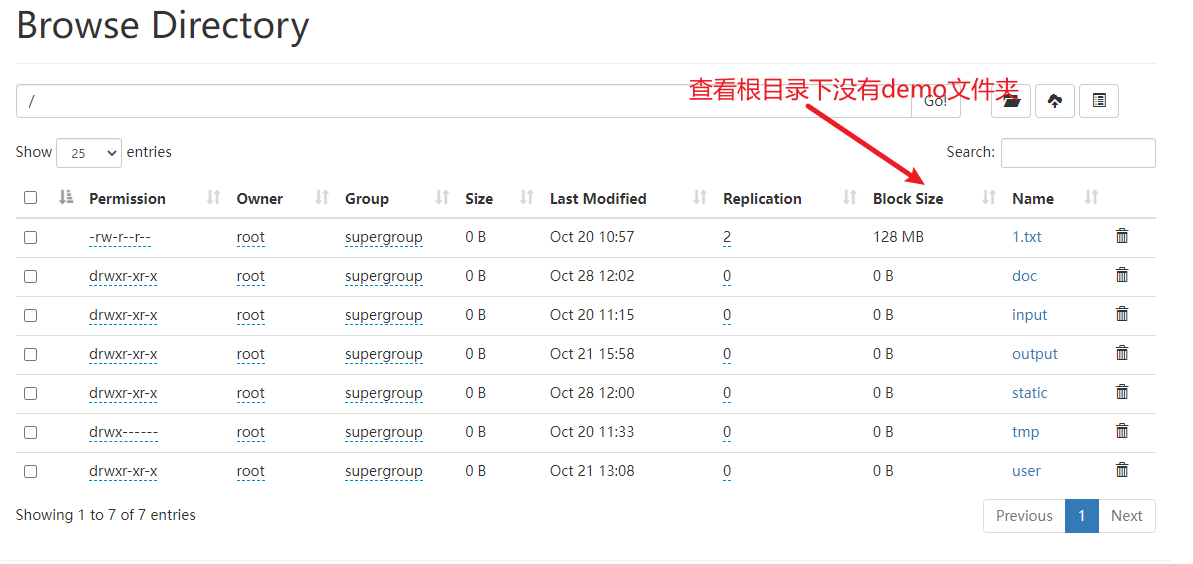
8) 再次运行java程序

webui查看执行结果
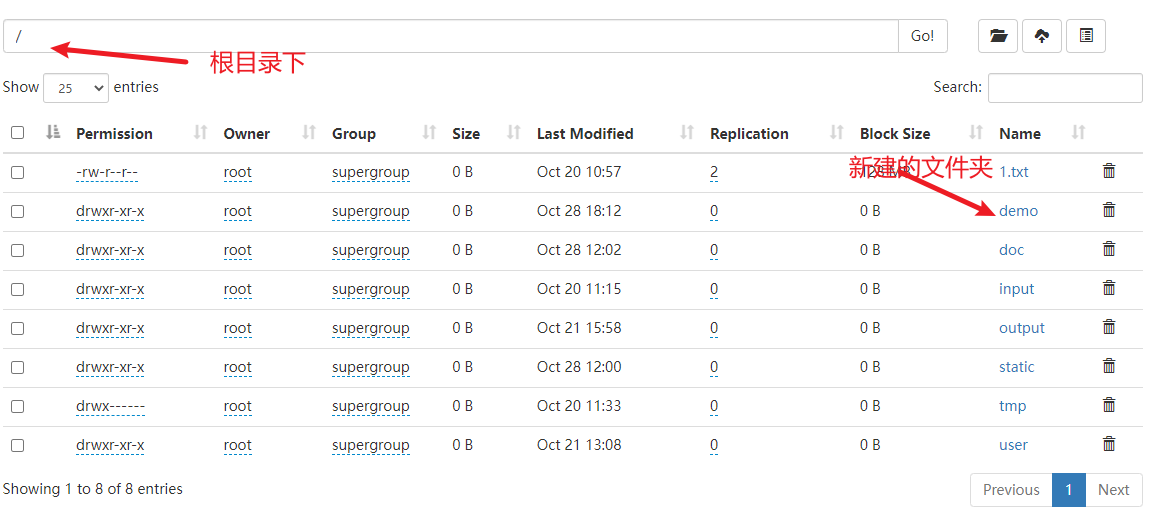
说明运行成功
9) 删除一个文件夹


10) 上传本地文件到HDFS集群
准备好本地文件

添加上传代码

运行查看结果
webui查看
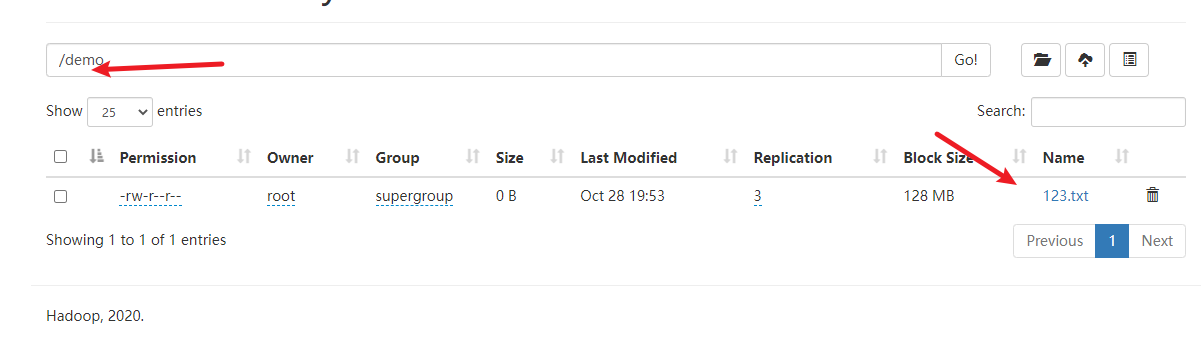
说明上传成功的
11) 下载HDFS集群的文件到本地
添加下载的代码

运行,出现错误提示
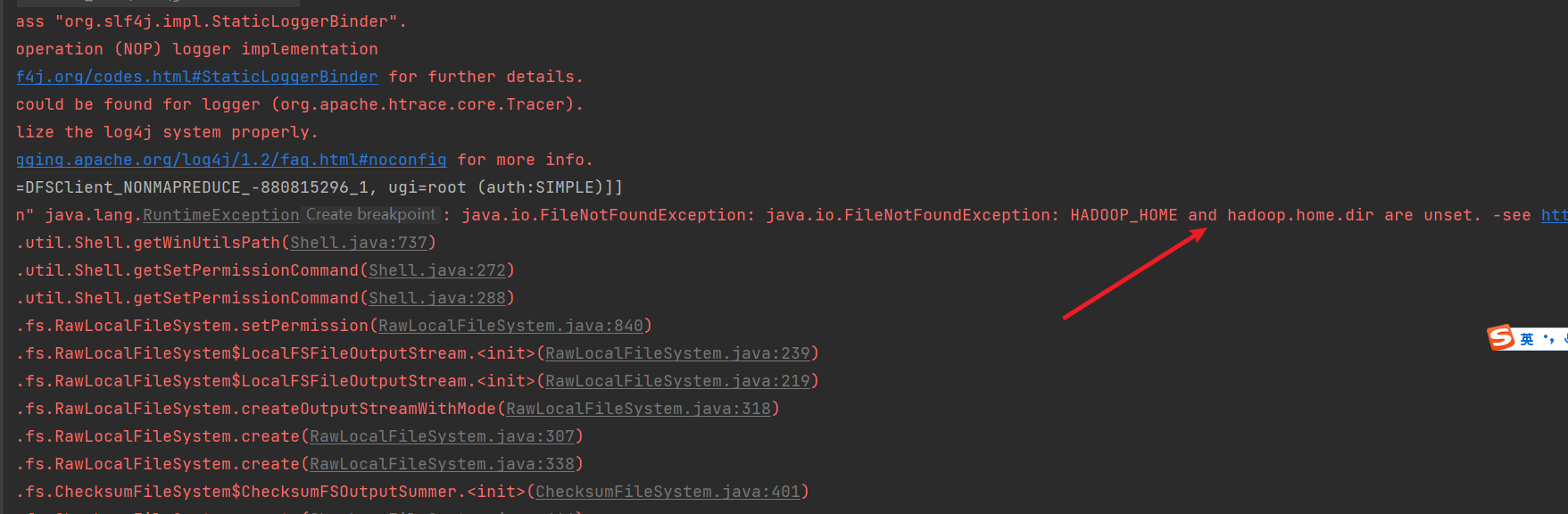
12) 配置本地windows的hadoop环境变量
下载windoes下的hadoop包,3.0以上版本即可

解压

配置环境变量
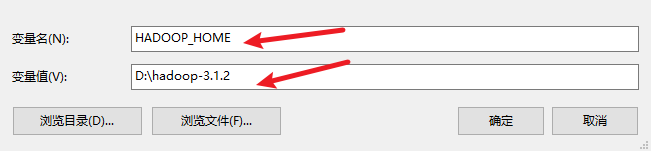

配置好后,再次运行,查看结果

-
相关阅读:
【趣学算法】第一章读书笔记
互联网公司研发效能团队为啥必须独立?何时独立?
全国双非院校考研信息汇总整理 Part.8
监听元素替换
通过AWS ALB Nginx代理Jenkins引发的一个问题
探索基于VSCode的远程开发插件,进行远程指令和本地指令的运行
Git学习笔记1
Monoxide relay机制和连弩挖矿
【Spring boot 拦截器 HandlerInterceptor】
Java Web 7 JavaScript 7.9 RegExp对象
- 原文地址:https://blog.csdn.net/W_chuanqi/article/details/127831399