-
python-(6-4-1)爬虫---利用re解析获得数据信息
一 正则表达式(re)
1-1 正则表达式规则
1)使用元字符进行排列组合来匹配字符串。
2)每一个元字符默认只匹配一个字符串。1-2 正则表达式含义
元字符是具有固定含义的特殊符号,如下所示。
. 匹配除换行符以外的其他字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配\w范围之外的所有字符 \S 匹配\s范围之外的所有字符 \D 匹配\d范围之外的所有字符 a|b 匹配字符a或字符b () 匹配括号内部的表达式(一个整体) [] 匹配括号内部的所有字符(每一个) [^] 匹配除了括号内部字符的其他所有字符 下面6个是量词,用来控制前面元字符的次数 * 重复0次或更多次 + 重复1次或更多次 ? 重复0次或1次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n次到m次 .* 贪婪匹配 .*? 惰性匹配- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1-3 部分举例说明
贪婪匹配是,如果满足条件,会尽可能多的匹配内容。
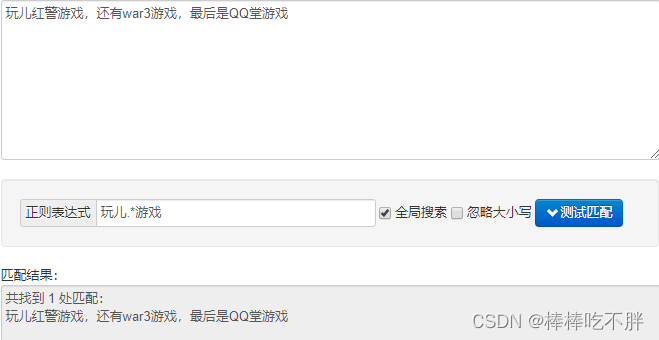
惰性匹配是,如果满足条件,会尽可能少的匹配内容。(回溯机制)
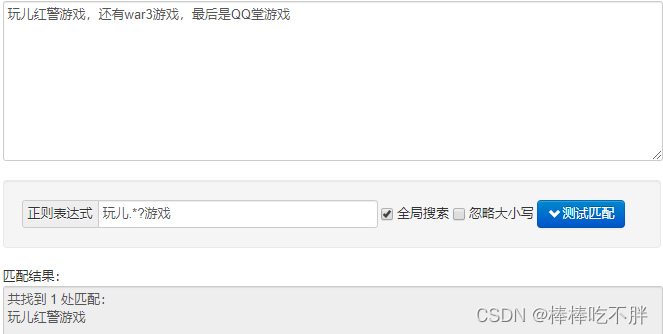
二 正则表达式(re)模块
2-1 findall()
作用:匹配字符串中所有符合正则的内容
缺点:返回的是列表,效率不高import re # 强迫症看到\d下面的波浪线很难受,在前面加一个r即可 lst = re.findall(r"\d+","我的一个手机号是:10086,另一个手机号是10010") # findall()返回的数据类型是列表 print(lst)- 1
- 2
- 3
- 4
- 5
- 6
- 7
2-2 finditer()
作用:匹配字符串中所有符合正则的内容
优点:返回的是迭代器,效率更高import re it = re.finditer(r"\d+","我的手机号是:10086,另一个手机号是10010") # 返回的数据类型是迭代器(看不到数据) print(it) # 从迭代器中拿到数据 for i in it: print(i.group())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2-3 search()
特点:找到一个结果就返回值,类似于惰性匹配
import re se = re.search(r"\d+","我的手机号是:10086,另一个手机号是10010") # 返回的数据类型是match对象 print(se.group())- 1
- 2
- 3
- 4
- 5
- 6
2-4 compile()
特点:预加载正则表达式,可以在后面反复调用
import re obj = re.compile(r"\d+") # 第一次调用 ret1 = obj.finditer("我的手机号是:10086,另一个手机号是10010") for i in ret1: print(i.group()) # 第二次调用 ret2 = obj.findall("我的200块钱该还我了吧") print(ret2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2-5 (?P<分组名字>正则)
特点:单独从正则匹配的内容中进一步提取内容
import re str = """\d+)> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
三 实战练习
3-1 需求
得到某瓣电影排名前25名的电影名
3-2 分析
首先,需要拿到页面的源代码。(导入requests模块)
其次,利用正则提取想要的数据信息。(导入re模块)
最后,重点是分析如何提取电影名(ctrl+U打开网页源代码)。
这里笔者从
开始,直到肖申克的救赎那一栏,中间的内容全部用.*?惰性匹配符号。如果使用贪婪匹配符合,那么前24个电影名字都会被跳过,最终只会显示第25个电影的名字。接着照抄电影名前面的内容,将电影名这一堆字符串通过
compile()进一步提取出来,后面继续照抄。最后记得关闭访问请求。

同理,我们也可以按照这样的办法得到其他信息,比如电影上映的年份、电影评分的人数、电影的最终评分等信息,注意正确使用正则即可。3-3 代码
import requests import re url = "https://movie.douban.com/top250" # 伪装成正常的浏览器用户访问 headers = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36" } # 请求访问并得到响应 response = requests.get(url=url,headers=headers) # 得到网页源代码 code = response.text # 解析数据 obj = re.compile(r'- .*?(?P
, re.S) # 开始正则匹配 result = obj.finditer(code) # 得到电影名字 for i in result: print(i.group("name")) # 访问结束,关闭请求 response.close().*?) '- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3-4 补充说明
想要得到电影的名字、电影上映时间、电影评分、参与评分电影的人数这四个数据信息,并且将这些数据以CSV格式输出,代码如下。
import requests import re import csv url = "https://movie.douban.com/top250" # 伪装成正常的浏览器用户访问 headers = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36" } # 请求访问并得到响应 response = requests.get(url=url,headers=headers) # 得到网页源代码 code = response.text # 解析数据 obj = re.compile(r'- .*?(?P
.*?(?P.*?) .*?
(?P.*?) .*?age">(?P .*?) .*?)人评价 ', re.S) # 开始正则匹配 result = obj.finditer(code) # 打开文件,开始向文件中写入数据 f = open("movie.csv",mode="w") csv_write = csv.writer(f) for i in result: # 将得到的所有数据整理成字典的形式 dic = i.groupdict() # 处理数据year前面的空格 dic['year'] = dic['year'].strip() # 将字典里的数据写出去 csv_write.writerow(dic.values()) # 处理完成 print("over!!!!") # 关闭页面 f.close() # 访问结束,关闭请求 response.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
-
相关阅读:
启发式合并、DSU on Tree
【广州华锐互动】车辆零部件检修AR远程指导系统有效提高维修效率和准确性
数字化转型风险大,企业该如何应对?
[附源码]JAVA毕业设计-高中辅助教学系统-(系统+LW)
[附源码]Python计算机毕业设计Django演唱会门票售卖系统
时刻保持学习状态
OCR 文字检测,可微的二值化(Differentiable Binarization --- DB)
cf #832 Div.2(A-D)
工作中我们应该具备的能力
Docker Compose安装
- 原文地址:https://blog.csdn.net/oldboy1999/article/details/127764948
