-
看红帽巨佬解析⭐《一、G1垃圾回收期简介》⭐
笔者最近在看关于G1垃圾收集器,发现了一篇十分优秀的文章,来自红帽(Red Hat)大佬。
笔者通过自己的理解后翻译后,有了本篇文章
本篇是Part 1:⭐⭐原文地址⭐⭐序
对于大多数人来说,Java垃圾收集器是一个黑匣子,可以愉快地开展业务。程序员开发应用程序,QE验证功能,运营团队部署它。在这个过程中,你可以对整个堆、方法区/ 元空间 或线程设置进行一些调整,但除此之外,事情似乎只是工作。那么问题来了,当你开始挑战极限时会发生什么?当这些默认值不再足够时会发生什么?作为开发人员、测试人员、性能工程师或架构师,了解垃圾回收工作原理的基础知识以及如何收集和分析相应数据并将其转化为有效的调优实践是一项宝贵的技能。在这个正在进行的系列中,我们将带您踏上 G1 垃圾收集器的旅程,并将您的理解从初学者转变为将 GC 置于性能堆的顶部的爱好者。
可能国外没那么卷吧?,笔者从大上就开卷jvm了😓
本文在笔者看来,还是需要读者有一定的GC了解后才能阅读正文
我们将以最基本知识开始本系列:G1(Garbage First:号称最强垃圾处理器)收集器的意义是什么,它实际上是如何工作的?如果不大致了解它的目标、它如何做出决策以及如何设计,本文会带你从0深入了解G1。
G1 收集器的核心目标是实现通过 -XX:MaxGCPauseMillis 定义的可预测的软目标暂停时间,同时保持一致的应用程序吞吐量。关键和最终目标是能够维护这些目标,以满足当今对高性能、多线程应用程序的需求,这些应用程序需要不断扩大的堆大小。G1 的一般规则是暂停时间目标越高,可实现的吞吐量和总体延迟就越高。暂停时间目标越低,可实现的吞吐量和总体延迟就越低。垃圾回收的目标是结合对应用程序运行时要求的理解、应用程序的硬件配置和对 G1 的理解,以调整G1配置并实现满足业务需求的最佳运行状态。
请务必记住,优化是一个不断调整的过程,在这个过程中,您可以通过重复的测试和评估来建立一组基线和最佳设置。没有明确的指南或一组神奇的选项,您有责任评估性能,进行增量更改并重新评估,直到达到目标。
优化的意义:结合业务特性、硬件环境,调整出一套适合某个场景的配置
就其本身而言,G1致力于以几种不同的方式实现这些目标。首先,顾名思义,G1 收集活跃对象最少的区域,并将活跃对象压缩/撤离到新“region”。其次,它使用并发、并行和多阶段循环来实现其软暂停时间目标。这种特性使G1可以在定义的时间内执行必要的操作,而不管整体堆大小如何。
通过这种多阶段的执行,评估出可以在提供的预期时间内,完成堆清理
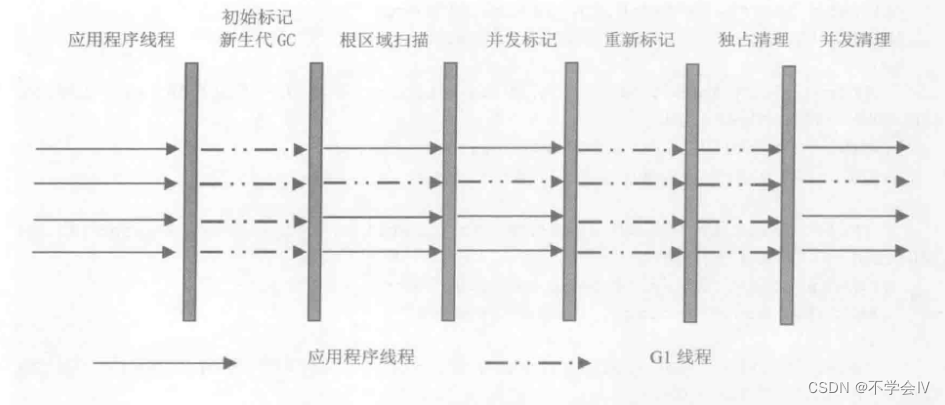
上面,我们提到了G1中的一个新概念,称为“region”。简单地说,区域代表一个分配的空间块,可以容纳任何一代的对象,而无需保持与同代其他区域的连续性。在G1中,传统的年轻代和老年代仍然存在。年轻代包括伊甸园区,所有新分配的对象都从那里开始,幸存者区,在收集过程中将活伊甸园对象复制到其中。对象将保留在幸存者空间中,直到它们经历过垃圾回收但没被回收或经历过多次回收后,由 XX:MaxTenuringThreshold(默认为 15)定义。
意思在伊甸园区,经历一次GC但没有被回收就会进入幸存者区,进入幸存者区经历过15次GC进入老年代
老年代生成由”old region“组成,当对象达到 XX:MaxTenuringThreshold (默认为 15)时,它们将从幸存者空间升级。当然,这有一个例外,我们将在文章末尾介绍。区域大小是在 JVM 启动时计算和定义的。它基于尽可能接近 2048 个区域的原则,其中每个区域的大小为 1 到 64 MB 之间的 2 次方。更简单地说,对于 12 GB 的堆:
- 12288 MB / 2048 区域 = 6 MB - 这不是 2 的幂
- 12288 MB/ 8 MB = 1536 个区域 - 太低
- 12288 MB/ 4 MB = 3072 个区域 - 可接受
根据上述计算,12GB的堆,JVM 默认将分配 3072 个区域(region),每个区域能够容纳 4 MB,如下图所示。您还可以选择通过 -XX:G1HeapRegionSize 显式指定区域大小。设置区域大小时,创建的区域数非常重要,因为区域越少,G1 的灵活性就越低,扫描、标记和收集每个区域所需的时间就越长。在所有情况下,空区域都会添加
无序列表(也称为“空闲列表”)中。这种情况下每个region,都没有表明是给年轻代使用还是老年代使用。
被记 年轻代/老年代 申请使用后,在清理(GC)过后还是会回到”空闲列表“ 关键在于,虽然G1是分代的垃圾回收,但空间的分配和消耗既不连续,又可以自由发展,因为它可以更好地了解最有效的年轻代与老年代的比例。对象生产开始时,使用比较和交换(CAS)方法从空闲列表中分配区域(region:上表白色的)作为线程本地分配缓冲区 (TLAB) 以实现同步。然后,可以在这些线程本地缓冲区中分配对象,而无需进行其他同步。当区域的空间用尽时,将选择、分配和填充一个新区域。这种情况一直持续到累积的伊甸园区域空间被填满,触发疏散暂停(也称为Young GC/年轻GC/年轻暂停或Mix GC /混合gc/混合暂停)。Eden 空间的内存使用量表示我们认为可以在定义的软暂停时间目标内收集的区域数。分配给 Eden 区域的总堆的百分比范围为 5% 到 60%,并在每个年轻集合后根据上一个年轻集合的性能进行动态调整。
关键在于,虽然G1是分代的垃圾回收,但空间的分配和消耗既不连续,又可以自由发展,因为它可以更好地了解最有效的年轻代与老年代的比例。对象生产开始时,使用比较和交换(CAS)方法从空闲列表中分配区域(region:上表白色的)作为线程本地分配缓冲区 (TLAB) 以实现同步。然后,可以在这些线程本地缓冲区中分配对象,而无需进行其他同步。当区域的空间用尽时,将选择、分配和填充一个新区域。这种情况一直持续到累积的伊甸园区域空间被填满,触发疏散暂停(也称为Young GC/年轻GC/年轻暂停或Mix GC /混合gc/混合暂停)。Eden 空间的内存使用量表示我们认为可以在定义的软暂停时间目标内收集的区域数。分配给 Eden 区域的总堆的百分比范围为 5% 到 60%,并在每个年轻集合后根据上一个年轻集合的性能进行动态调整。mix gc:是相比其他老垃圾收集器多的一种回收情况,它在达到一定阈值后,会清理较少的一部分区域
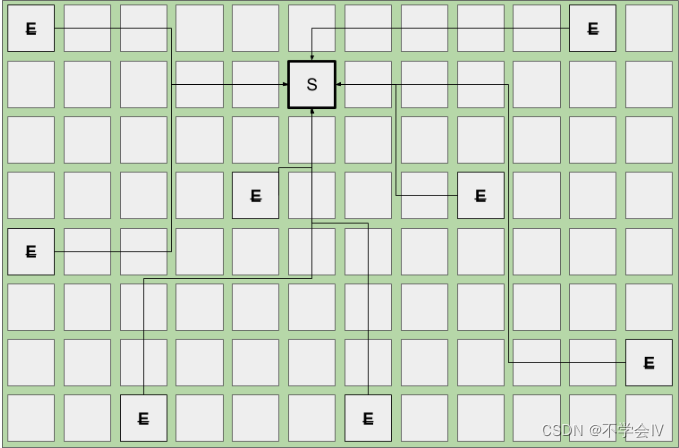
下面是将对象分配到非连续 Eden 区域的示例;
可以看到区域是一点点申请的,还有很多在”空闲列表“

这里是GC的日志记录,Jdk9之前的版本,添加以下两条JVM指令,会在指定的文件夹下输出GC日志:
-XX:+UseG1GC
-Xloggc:D:\gclog\jdk8.logGC pause (young); #1 [Eden: 612.0M(612.0M)->0.0B(532.0M) Survivors: 0.0B->80.0M Heap: 612.0M(12.0G)->611.7M(12.0G)] GC pause (young); #2 [Eden: 532.0M(532.0M)->0.0B(532.0M) Survivors: 80.0M->80.0M Heap: 1143.7M(12.0G)->1143.8M(12.0G)]- 1
- 2
根据上面的“GC 暂停(年轻)”日志,您可以看到在暂停 #1 中,触发了GC,因为 Eden 在总共 612.0M(153 个区域)中使用了612.0M。目前的伊甸园空间被完全疏散-0.0B,考虑到所花费的时间,它还决定将伊甸园的总分配减少到532.0M或133个区域。在暂停 #2 中,您可以看到当我们达到532.0M 的新限制时触发疏散。因为我们实现了最佳暂停时间,伊甸园保持在532.0M。
G1的特性,动态调节了内存分配,所以使用G1,尽量不要使用-Xmn设置新生代内存,影响G1的性能
当上述年轻收集发生时,将收集垃圾(无用对象),并将任何剩余的活跃对象疏散并压缩到幸存者空间中。G1 有一个明确的硬边距,由 G1ReservePercent(默认为 10%)定义,这会导致在撤离期间(动态调节年轻代region)始终有一定百分比的堆是幸存者空间。如果没有此可用空间,堆可能会填充到没有可用区域进行疏散的程度。不能保证这不会仍然发生,但这就是调节的目的!这一原则确保在每次成功撤离后,所有先前分配的伊甸园区域都会返回到自由列表,任何撤离的活体最终都会进入幸存者空间。
撤离:region被清理后,但region是空的时候就会重新进入自由列表(空闲列表)
疏散:可以理解为垃圾清理,因为垃圾清理后,被清理的region会被整理
-XX:G1ReservePercent=10 初始新时代占比下面是一个标准年轻系列的示例:
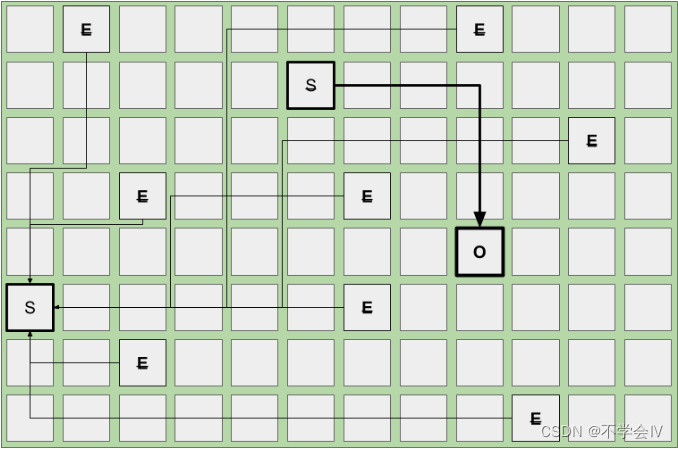
继续这种模式,对象再次被分配到新请求的 Eden(伊甸园) 区域。当伊甸园空间填满时,另一个年轻代GC(Young GC)就会出现,根据现有活物的年龄(各种GC幸存下来的次数),您将看到升级到旧区域。下面是一个示例,当幸存者空间中的活体被疏散并提升到旧空间中的新区域,而来自伊甸园的活体物体被疏散到新的幸存者空间区域时,年轻代GC(Young GC)的样子。由删除线表示的疏散区域现在为空并返回到自由列表。
G1 会一直使用此模式,直到发生以下三种情况之一:- 它达到一个可配置的软边距,称为启动堆占用百分比(IHOP)。
- 它达到其可配置的硬边距(G1储备百分比)
- 它遇到了巨大的对线需要分配内存(这是我之前提到的例外,最后会详细介绍)。
硬边距:-Xmx 最大分配的堆内存
软边距:-Xms 初始堆内存,这里的软边距是,但前堆内存还没到达硬边距的上线,表示还可以申请硬件内存启动堆占用百分比(IHOP),表示在年轻GC期间,计算的一个阈值,其中旧区域(old region)中的对象数占总堆的 45%(默认值)以上。这种活度比,将作为每个年轻系列的一个组成部分不断计算和评估。当命中其中一个触发器时,将请求启动并发标记周期。
意思到到达软边距后,会触发一些动作
下面的日志表示,到达软边距后,如果当前申请的内存没有到达-Xmx,申请内存,第一行就表示去申请内存,但已经到达了-Xmx,所以触发了GC(3,4行)的标记周期8801.974: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 12582912000 bytes, allocation request: 0 bytes, threshold: 12562779330 bytes (45.00 %), source: end of GC] 8804.670: [G1Ergonomics (Concurrent Cycles) initiate concurrent cycle, reason: concurrent cycle initiation requested] 8805.612: [GC concurrent-mark-start] 8820.483: [GC concurrent-mark-end, 14.8711620 secs]- 1
- 2
- 3
- 4
在 G1 中,并发标记基于初始快照 (snapshot-at-the-beginning SATB) 原则。这意味着,出于效率目的,它只能将拍摄初始快照时存在的对象标识为垃圾。在并发标记周期中出现的任何新分配的对象都被视为活动对象,无论其真实状态如何。这一点很重要,因为完成并发标记所需的时间越长,可回收对象与被视为隐含实时的比率就越高。如果在并发标记期间分配的对象多于最终收集的对象,则最终将耗尽堆。在并发标记周期中,您会看到年轻GC继续,因为它不是一个停止世界(STW)的事件。
下面是一个示例,说明当达到 IHOP 阈值时,年轻集合后堆可能是什么样子,触发并发标记。
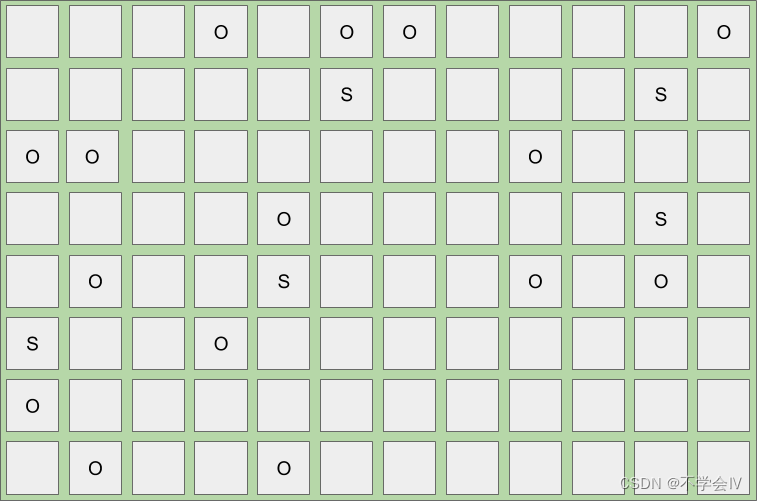
一旦并发标记周期完成,将立即触发年轻GC(Young GC)Mix GC
然后是第二种类型的疏散,称为混合收集(Mix GC)。混合系列的工作方式几乎与年轻 GC 完全相同,但有两个主要区别。首先,混合 GC 还将收集、疏散和压缩一组选定的旧区域(老年代/Old Region)。其次,混合GC 不是基于与年轻GC 相同的疏散触发因素。他们的运作目标是尽可能快速和频繁地收集。他们这样做是为了最小化分配的伊甸园/幸存者区域的数量,以便最大化在软暂停目标中选择的旧区域的数量。
有些不好理解,大概就是他收集了年轻代和符合要求的个别老年代,并会控制年轻代清理的个数,来保证时间符合要求;
8821.975: [G1Ergonomics (Mixed GCs) start mixed GCs, reason: candidate old regions available, candidate old regions: 553 regions, reclaimable: 6072062616 bytes (21.75 %), threshold: 5.00 %]- 1
上面的日志告诉我们,混合GC 正在启动,因为候选旧区域的数量 (553) 具有 21.75% 的可回收空间。此值高于 G1HeapWastePercent 定义的 5% 最小阈值(JDK8u40+ 中默认值为 5%,JDK7 中默认值为 10%),因此,混合收集将开始。因为我们不想执行浪费的工作,所以 G1 坚持垃圾优先策略。根据有序列表,根据其活动对象百分比选择候选区域。如果旧区域的活动对象少于 G1MixedGCLiveThresholdPercent 定义的百分比(JDK8u40+ 中默认为 85%,JDK7 中默认为 65%),我们会将其添加到列表中。简而言之,如果旧区域大于 65% (JDK7) 或 85% (JDK8u40+),那这个区域就不会被Mix GC选中回收。
8822.178: [GC pause (mixed) 8822.178: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 74448, predicted base time: 170.03 ms, remaining time: 829.97 ms, target pause time: 1000.00 ms]- 1
与年轻GC相比,混合GC将寻求在同一暂停时间目标内收集所有类型 region。它通过基于 G1MixedGCCountTarget 的值(默认为 8)增量收集旧区域来管理此区域。这意味着,它将候选旧区域的数量除以G1MixedGCCountTarget,并尝试在每个周期中收集至少那么多的区域。每个周期结束后,将重新评估旧区域的活跃度。如果可回收空间仍然大于 G1HeapWastePercent,则混合收集将继续。
G1中的MIXGC选定所有新生代里的Region, 外加根据全局并发标记统计得出收集收益高的若干老年代Region,在用户指定的开销目标范围内尽可能选择收益高的老年代Region进行回收.所以MIXGC回收的内存区域是新生代+老年代. 根据参数 -XX:InitiatingHeapOccupancyPercent,当老年代大小占整个堆大小百分比达到该阈值时(默认 45%),
会触发一次mixed gc.
————————————————
版权声明:本文为CSDN博主「谈谈1974」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45505313/article/details/991785278822.704: [G1Ergonomics (Mixed GCs) continue mixed GCs, reason: candidate old regions available, candidate old regions: 444 regions, reclaimable: 4482864320 bytes (16.06 %), threshold: 10.00 %]- 1
此图表示混合GC。所有伊甸园区域都被收集并疏散到幸存者区域,根据年龄,所有幸存者区域都会被收集,并且足够终身的活体被提升到新的旧区域。同时,还会收集旧区域的选定子集,并将任何剩余的活动对象压缩到新的旧区域中。压实和抽真空过程可以显着减少碎片,并确保保持足够的自由区域。

此图表示混合集合完成后的堆。所有伊甸园区域都被收集,活体对象驻留在新分配的幸存者区域中。收集现有幸存者区域,并将活动对象提升到新的旧区域。收集的旧区域集将返回到空闲列表,任何剩余的活动对象将压缩到新的旧区域中。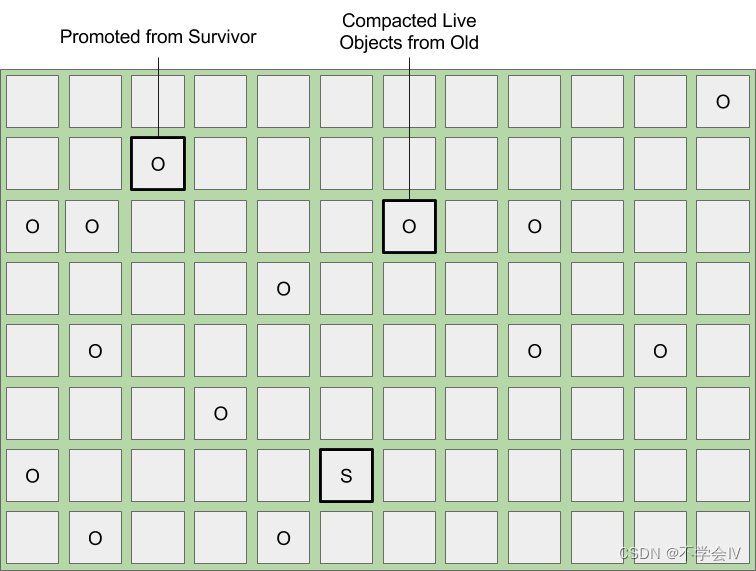
混合收集将继续,直到所有选中的old region都完成或直到可回收百分比不再符合 G1HeapWastePercent。下面的日志,您将看到混合GC 周期结束,以下事件将返回到标准年轻GC。8830.249: [G1Ergonomics (Mixed GCs) do not continue mixed GCs, reason: reclaimable percentage not over threshold, candidate old regions: 58 regions, reclaimable: 2789505896 bytes (9.98 %), threshold: 10.00 %]- 1
Mix GC:老年代可回收region大于阈值时触发
Young GC:Eden空间耗尽时会被触发现在我们已经介绍了标准用例,让我们回过头来讨论我之前提到的异常。它适用于对象大小大于单个区域的 50% 的情况。在这种情况下,对象被认为是巨大的,并通过执行专门的巨型分配来处理。
区域大小: 4096 KB
对象 A: 12800 KB
结果:跨 4 个区域的庞大分配此图概述了跨 4 个连续区域的 12.5 MB( 12800 KB) 对象的巨大分配。
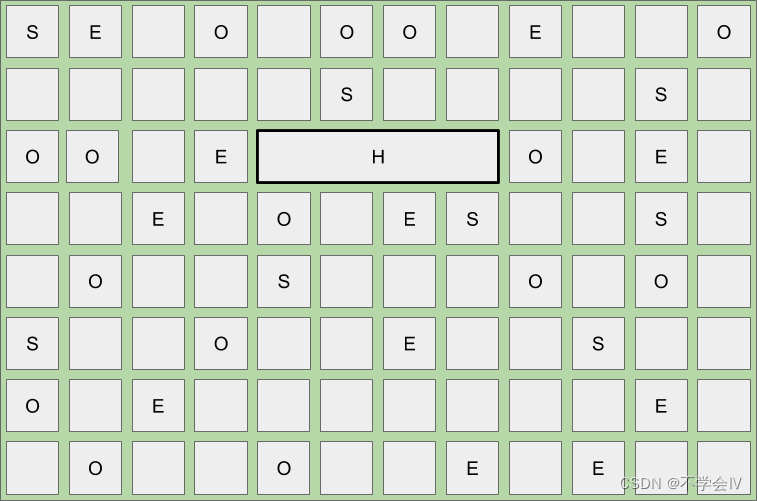
- 大对象分配表示单个对象,因此必须分配到连续的空间中,否者能会导致严重的碎片化。
- 大对象被直接分配到老一代内部的一个特殊的巨大区域。这是因为在年轻一代中疏散和复制此类物体的成本太高。
- 即使有问题的对象只有 12.5 MB,它也必须占用四个完整的区域,占总使用量的 16 MB。
- 无论是否满足IHOP标准,巨大的分配总是会触发并发标记周期。
一些庞大的对象可能不会引起问题,但稳定分配它们可能会导致严重的堆碎片和明显的性能影响。在 JDK8u40 之前,巨大的对象只能通过完整的 GC 收集,因此这影响了 JDK7 和早期 JDK8 性能的可能性非常高。这就是为什么了解应用程序生成的对象的大小以及 G1 为区域大小定义的内容至关重要的原因。即使在最新的 JDK8 中,如果您正在进行大量巨大的分配,最好尽可能多地评估和调整。
4948.653: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: requested by GC cause, GC cause: G1 Humongous Allocation] 7677.280: [G1Ergonomics (Concurrent Cycles) do not request concurrent cycle initiation, reason: still doing mixed collections, occupancy: 14050918400 bytes, allocation request: 16777232 bytes, threshold: 12562779330 32234.274: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 12566134784 bytes, allocation request: 9968136 bytes, threshold: 12562779330 bytes (45.00 %), source: concurrent humongous allocation]- 1
- 2
Full GC
最后,不幸的是,G1还必须处理可怕的Full GC。虽然G1最终试图避免使用Full GC,但它们仍然是一个严酷的现实,尤其是不当的环境中。鉴于 G1 的目标是更大的堆大小,Full GC 的影响可能对正在进行的处理业务造成灾难性的影响。主要原因之一是Full GC 在 G1 中仍然是单线程操作(STW)。
[Full GC (Metadata GC Threshold) 2065630K->2053217K(31574016K), 3.5927870 secs]- 1
一个前提是更新到 JDK8u40+,其中类卸载不再需要Full GC!您可能仍然会在元空间上遇到完整的GC,但这将与UseCompressedOops和UseCompressedClassesPointers或并发标记所需的时间有关(我们将在以后的帖子中讨论)。
后两个原因是真实的,而且往往是不可避免的。作为工程师,我们的工作是通过调整和评估生成我们尝试收集的对象的代码,尽最大努力延迟和避免这些情况。第一行日志问题是“to-space exhausted”事件,然后是Full GC。此事件说明了撤出失败,其中堆无法再扩展,并且没有可用的区域来容纳撤出。如果你还记得,我们之前讨论过由G1ReservePercent定义的硬保证金。该日志表示gc对活跃对象疏散,并且堆已满,我们没有其他可用区域。在某些情况下,如果JVM可以解决空间条件,就不会导致Full GC,但这仍然是一个非常昂贵的停止世界事件。
6229.578: [GC pause (young) (to-space exhausted), 0.0406140 secs] 6229.691: [Full GC 10G->5813M(12G), 15.7221680 secs]- 1
- 2
上面主要介绍了触发Full GC的两种种可能
- 元空间达到上限,可以用UseCompressedOops和UseCompressedClassesPointers优化
- 年轻代空间不够,年轻代的对象就会直接进入老年代,该情况100%会触发Full GC,可以通过XX:G1ReservePercent和XX:InitiatingHeapOccupancyPercent优化
如果您经常看到下面三行日志,您可以立即假设您有很大的调整空间!第二行日志的情况是并发标记期间的完整 GC。在这种情况下,我们并没有失败撤离,我们只是在并发标记完成并触发混合集合之前用完了堆。这两个原因是内存泄漏,或者您生成和升级对象的速度快于收集对象的速度。如果Full GC 集合是堆的经常出现,则可以假定它与生产和升级相关。如果收集的很少,并且您最终遇到内存不足错误,那么您很可存在内存泄漏。
可以通过XX:G1ReservePercent和XX:InitiatingHeapOccupancyPercent优化
上面这个描述,如果读者不一定程度了解gc,可能有点难理解,自行扩展学习八57929.136: [GC concurrent-mark-start] 57955.723: [Full GC 10G->5109M(12G), 15.1175910 secs] 57977.841: [GC concurrent-mark-abort]- 1
- 2
- 3
总结
Young GC:
- Eden区不够分配时触发
- 根据暂停时间选择最大可能区域数
Mix GC:
- 老年代可回收region大于阈值时触发
- 回收数量XX:G1MixedGCCountTarget(默认八个region)
Full GC:
- 整体堆内存不足,或年轻代清理后也不足以分配
- 整体堆回收,可以优化年轻代大小来尽量避免
本章就到这里了,下篇文章会有更详细的日志解析
-
相关阅读:
红日内网渗透靶场vulnstack2
性能调优读书笔记(上篇)
10款录屏软分析与选择使用,只看这篇文章就轻松搞定所有,高清4K无水印录屏,博主UP主轻松选择
机器学习基础算法--回归类型和评价分析
日常工作中需要避免的9个React坏习惯
云计算【第一阶段(16)】安装及管理程序
LeetCode-278(Python)—— 第一个错误的版本
C++线程库的基本使用(初级)
数据结构(C++)[B树(B-树)插入与中序遍历,效率分析]、B+树、B*树、B树系列应用
hadoop 3.x大数据集群搭建系列7-安装Hudi
- 原文地址:https://blog.csdn.net/qq_35040959/article/details/127811697