-
【C/C++】结构体&内存对齐

本章重点
简介
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。结构体的声明
- struct tag
- {
- member - list;//成员
- };
例如,用结构来描述一个学生:
- struct student
- {
- char name[20];//名字
- int age;//年龄
- char sex[5];//性别
- char id[20];//学号
- };//分号不能丢!!!
注意:此时我们所做的事是在申明一个结构体类型!此时的struct student为一种类型,就如同我们常见的int,char,double...
结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?我们将结构中包含一个类型为该结构本身的成员的行为叫作结构的自引用。那么下面这种写法,是否正确呢?- struct Node
- {
- int data;
- struct Node next;
- };
答案是这种写法是错误的!
有疑惑的同学不妨假设一下这种写法是正确的,那么我们该如何计算该结构体类型的大小
呢?
当我们计算struct Node的大小时,我们发现结构体里面又有一个struct Node类型的大小需要
我们计算......这样我们就一直循环下去了也算不出结构体的大小。
当我们编译时,就会出来这样的报错:

那正确的做法是怎样的呢?
既然结构体类型是不确定的,那我们就试着用一个该结构体类型的指针,在使用时对这个指
针解引用就好了。不管是什么类型的指针,它的大小总是固定的4字节或者8字节。在32位平
台上是4字节,在64位平台上是8字节。
顺着这个思路我们就可以这样做:
- struct Node
- {
- int data;
- struct Node* next;
- };
这种样式在学习数据结构的链表时,我们经常会看到它的身影。
typedef注意事项
有时候当我们觉得结构体类型名字太长,试图简化的时候,我们可以用typedef来对结构体类型重
定义。例如:
- ·typedef struct student
- {
- char name[20];
- int age;
- char sex[5];
- char id[20];
- }stu; //将struct student类型重定义为stu
那我们就想着,在结构体自引用时,能否偷这个懒呢?
比如:
- typedef struct Node
- {
- int data;
- Node* next;
- }Node;
答案是,这种写法是错误的!
当我们语句执行到最后一个分号时,这个typedef的动作才会结束。也就是最后一个分号走完
我们才将struct Node类型重定义为Node。所以在此之前编译器是不认识Node这个类型的!
正确的做法:
- typedef struct Node
- {
- int data;
- struct Node* next;
- }Node;
一种特殊的声明
在声明结构的时候,可以不完全的声明。我们称之为匿名结构体类型例如:- struct
- {
- int a;
- };
那么问题来了,匿名结构体省略了结构体标记,下面这种情况第一个结构体与第二个结构体是否类型相同呢?
- struct //匿名结构体1
- {
- int a;
- };
- struct //匿名结构体2
- {
- int a;
- };
- int main()
- {
- return 0;
- }
答案是编译器会把上面的两个声明当成完全不同的两个类型。
当然匿名结构体看着花里胡哨,其实作用不大。这个下一段介绍。
结构体变量的定义和初始化
有了结构体类型,那我们就可以来定义一个结构体变量了。
例如现在使用struct student类型来定义几个学生变量:
- struct student
- {
- char name[20];
- int age;
- char sex[5];
- char id[20];
- }s1,s2; //声明类型的同时定义结构体变量
- //定义结构体变量
- struct student s3;
- struct student s4;
- int main()
- {
- return 0;
- }
以上s1,s2,s3,s4就是普通的变量,放在全局中就是全局变量,刚在函数内部就是局部变量。再来看结构体的初始化:- struct student
- {
- char name[20];
- int age;
- char sex[5];
- char id[20];
- };
- int main()
- {
- //初始化:定义变量的同时赋值
- struct student s1 = { "zhangsan",15,"male","12345" };
- return 0;
- }
或者这样:
- struct student
- {
- char name[20];
- int age;
- char sex[5];
- char id[20];
- }s1 = { "zhangsan",15,"male","12345" };
- int main()
- {
- return 0;
- }
匿名结构体定义变量与初始化
那我们刚才提到的匿名结构体类型该如何定义变量呢?
这样做是否可行呢?
- struct
- {
- int data;
- };
- struct n1;
- struct n2 = { 20 };
答案是,这种写法是错误的

编译器直接告诉我们不认识这个东西。
正确的做法其实是这样:
- struct
- {
- int data;
- }n1,n2={20};
我们必须在声明匿名结构体类型时就定义变量。否则出了这个村就没这个店了。所以它就相当于一
次性产品,不过,匿名结构体看似鸡肋,但有时候也会很有用。
而且,匿名结构体类型更加做不到自引用了!
计算结构体大小&结构体内存对齐
学习之前我们不妨猜一猜这个结构体的大小是多少:
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
以我们目前的印象,S1的大小这样算:1+4+1=6
那我们运行一下看结果对不对呢?
- #include
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- int main()
- {
- printf("%d\n", sizeof(struct S1));
- return 0;
- }
结果: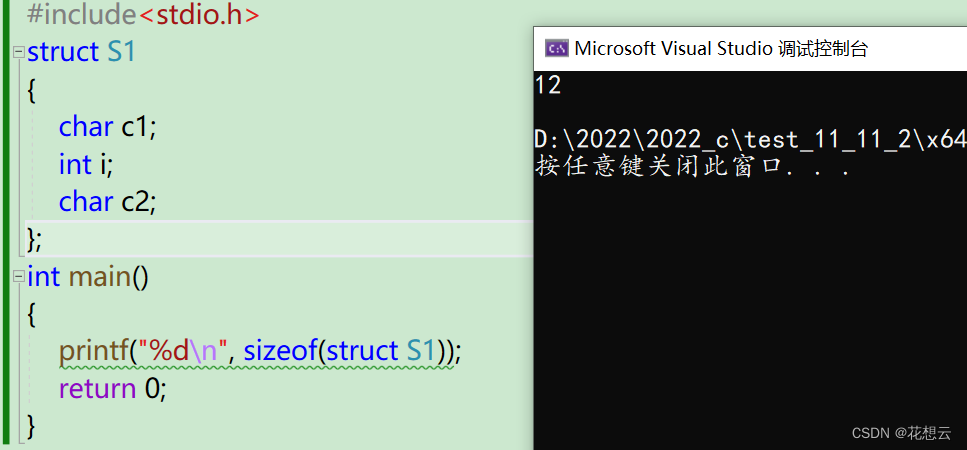
结果与我们所想相差甚远。
再来看一组:
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
- int main()
- {
- printf("%d\n", sizeof(struct S2));
- return 0;
- }
结果如下:

有点诡异,我们仅仅是改变了变量的位置两个结构体的大小就改变了。
那我们究竟该如何计算结构体的大小呢?
首先得掌握结构体的 对齐规则 :1. 第一个成员在与结构体变量偏移量为0的地址处。2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。这里有两个点需要说明:偏移量: 偏移量就是程序的 逻辑地址 与段首的差值。对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。VS中默认的值为83. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。现在我们来实际操作一下吧,以结构体S1为例:- struct S1
- {
- char c1;
- int i;
- char c2;
- };

再来看看S2吧:
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
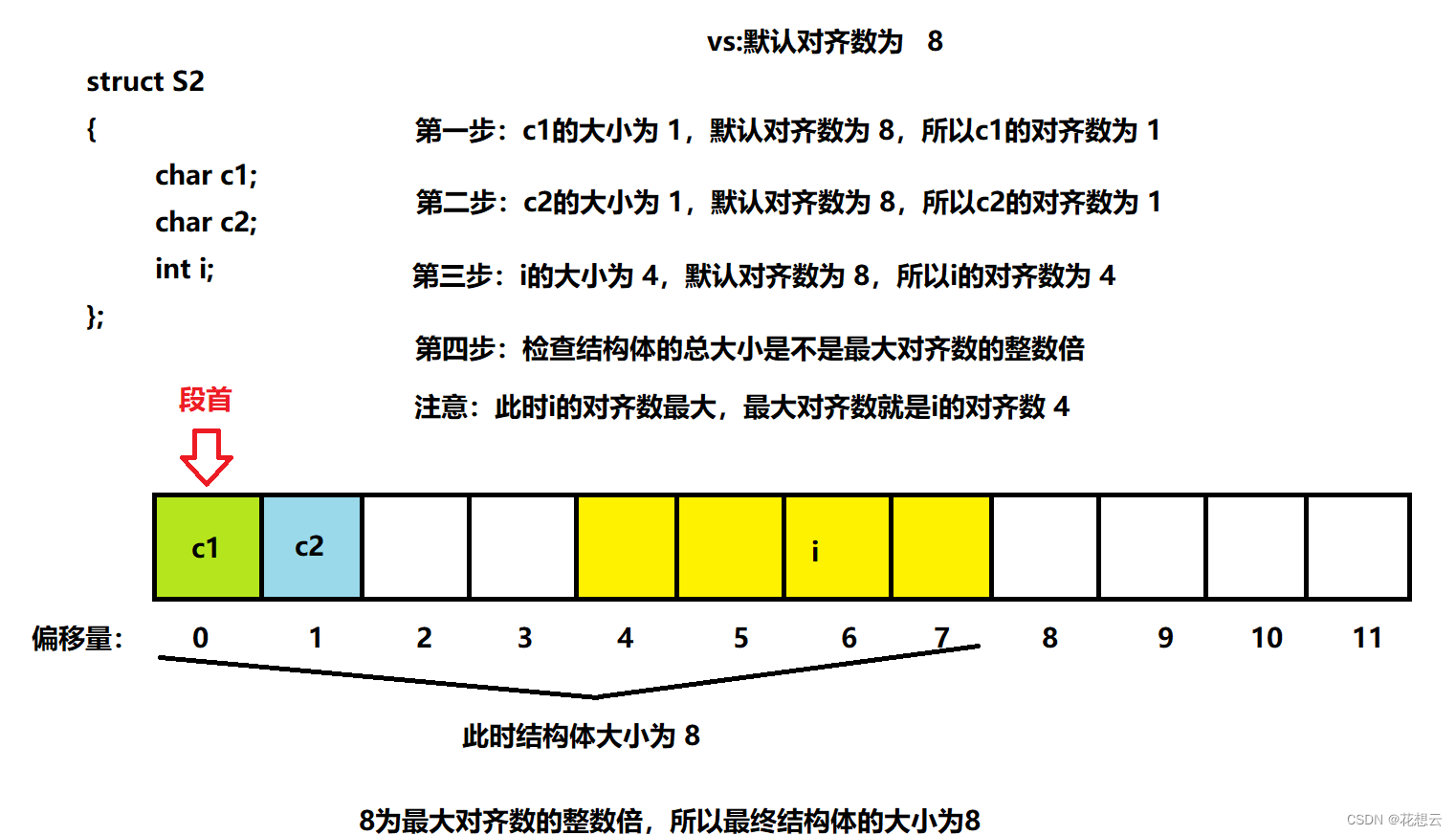
切记:最后一步一定要检查结构体大小是否为最大对齐数的整数倍!
了解了内存对齐的规则之后我们思考一下为什么要存在内存对齐?
大部分的参考资料都是如是说的:1. 平台原因 ( 移植原因 ) :不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。例如:某硬件平台规定,在一块地址上访问int类型的数据时,只找偏移量为4的整数倍的地址。这时,如果没有内存对齐,int类型的数据有可能存储在偏移量非4的整数倍的位置上。那就会出现访问不到的错误。2. 性能原因 :数据结构 ( 尤其是栈 ) 应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。总体来说:结构体的内存对齐是拿空间来换取时间的做法。那在设计结构体的时候,我们既要满足对齐,又要节省空间,所以我们这样做:让占用空间小的成员尽量集中在一起。- //例如:
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- struct S2
- {
- char c1;
- char c2;
- int i;
- };
S1和S2虽然存储的内容类型相同,但是二者所占空间大小却不相同。
修改默认对齐数
认识了默认对齐数,有时候默认对齐数的大小使用起来可能会造成不方便,这时候我们就可以修改
默认对齐数。如下:
- #include
- #pragma pack(8)//设置默认对齐数为8
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- #pragma pack()//取消设置的默认对齐数,还原为默认
- #pragma pack(1)//设置默认对齐数为1
- struct S2
- {
- char c1;
- int i;
- char c2;
- };
- #pragma pack()//取消设置的默认对齐数,还原为默认
- int main()
- {
- //输出的结果是什么?
- printf("%d\n", sizeof(struct S1));
- printf("%d\n", sizeof(struct S2));
- return 0;
- }
结构体传参
我们直接看代码:
- struct S
- {
- int data[1000];
- int num;
- };
- struct S s = { {1,2,3,4}, 1000 };
- //结构体传参
- void print1(struct S s)
- {
- printf("%d\n", s.num);
- }
- //结构体地址传参
- void print2(struct S* ps)
- {
- printf("%d\n", ps->num);
- }
- int main()
- {
- print1(s); //传结构体
- print2(&s); //传地址
- return 0;
- }
如上所示两种结构体传参的形式其实是有优劣之分的。
函数在创建形参时,参数需要压栈,会在空间和时间上有开销。
当结构体所包含的内容过大时,一定程度上会导致程序的性能下降,所以我们选择第二种方
法。

本章完!
-
相关阅读:
学神经网络需要什么基础,神经网络快速入门
基于AT89C51单片机的直流数字电压表设计
基于PHP的汉服文化交流平台毕业设计源码240903
Scratch 第十六课-弹珠台游戏
聚类分析-书后习题回顾总结
单片机硬件和软件延时、RTOS相对延时和绝对延时
堆排序与优先队列
Python计算机二级中常考函数
[计算机毕业设计]大数据疫情分析与可视化系统
【细读Spring Boot源码】重中之重refresh()
- 原文地址:https://blog.csdn.net/gllll_yu/article/details/127814428