-
【深度学习】第三章:卷积神经网络
1. 为什么要使用卷积神经网络?
因为前馈神经网络存在如下缺点:
- 处理图像时,参数过多,导致训练效率低,也容易导致过拟合。 因为图像的维度比较高,而前馈神经网络参数个数是层之间乘积之和的形式,比如:
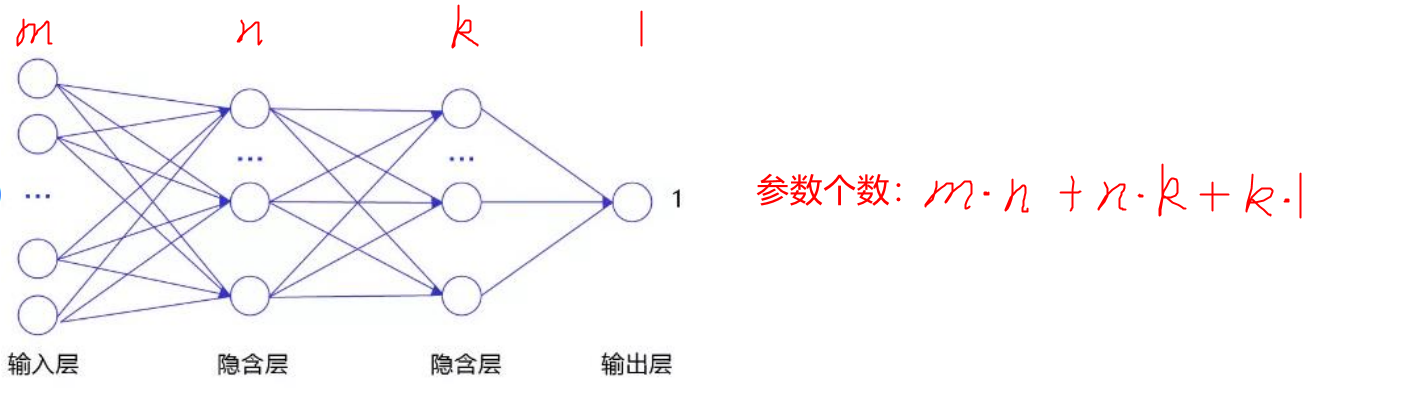
- 输入数据的空间信息被丢失。 因为全连接层的输入层是一维的,如果数据是多维的,比如二维的黑白图片,那么必须把它拉伸为一维数据才可以使用前馈神经网络,但这样就将空间信息丢失了。

因为卷积可以解决上面的两个问题,所以引入卷积代替全连接网络的点积运算。而全连接的隐藏层
2. 卷积
2.1 数学上的卷积
卷积本质上就是先将一个函数翻转,然后进行滑动叠加,从运算上来看就是先乘后加。整体流程是:翻转——>滑动——>叠加——>滑动——>叠加——>滑动——>叠加…

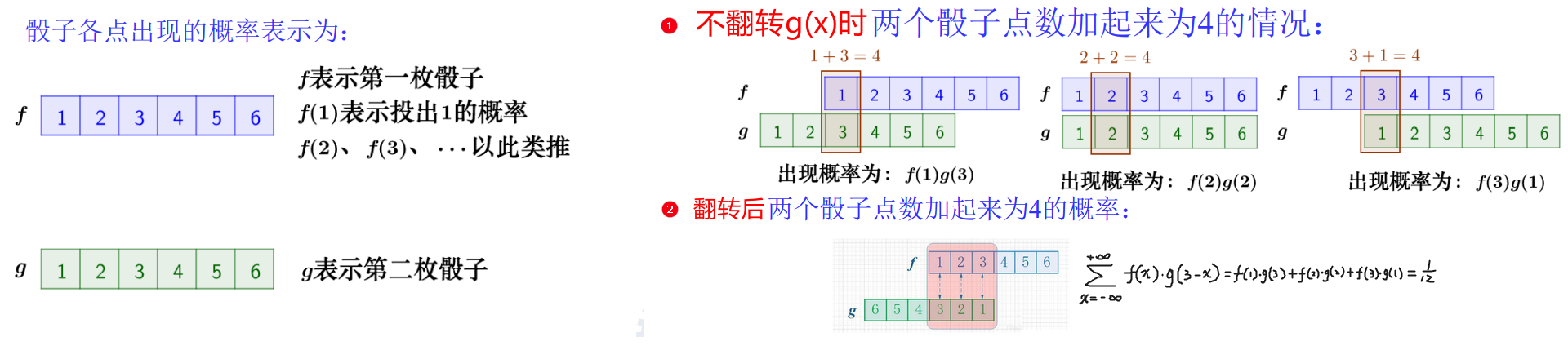
- 问:卷积中为什么要将g(x)翻转再平移?
- 答:卷积和加减乘除一样是个运算,规定的卷积运算过程就是这样。
① 从几何上看,就是翻转平移之后,能够将离散化的重叠面积整合到一起,能够用一个积分式表示;
② 从现实意义上看,f(x)、g(x)通过卷积运算得到的函数a(x)与f(x)具有很强的相关性。
2.2 深度学习的卷积
前面提到,f(x)、g(x)通过卷积运算得到的函数a(x)与f(x)具有很强的相关性。因此,将图片当做f(x),权重当做g(x),那么f(x)与g(x)通过卷积运算就可以得到图片f(x)的特征a(x)。
注意:在深度学习中的卷积运算,只是对卷积核平移,并不需要对卷积核做翻转。因为没有必要,卷积核本来就是参数,旋转只是将参数的位置变了,而特征翻转并为改变特征之间的相对位置,类似于做了一次线性变换,并不会影响训练结果。
因此,在深度学习中:
- 卷积:代表特征提取器
- 卷积核:代表权重参数
- 计算结果:代表图片的特征,即 特征图
- 感受野:卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
卷积网络卷积层越多,提取到的特征就越抽象,感受野将会越大,输出特征图中的一个像素点将会包含更多的图像语义信息。就像看一张照片,离的越远,越能看到完整的图片,同时更加的模糊抽象。所以,卷积层不可太多也不可太少。
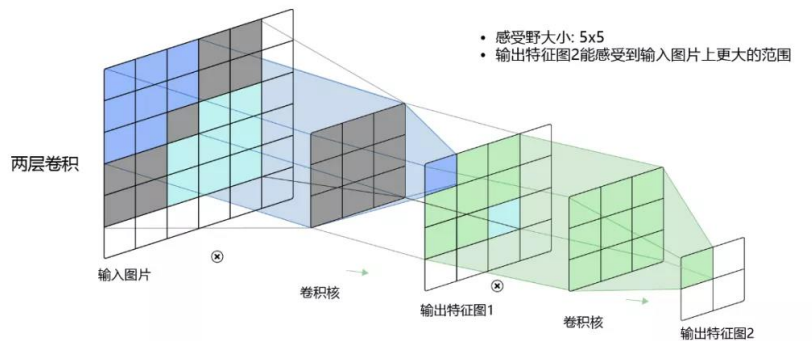
相对于全连接神经网络来说就是:用卷积来代替全连接

3. 卷积的构成
- 卷积核:里面存放是权重参数,其维度通常与输入图像维度一样。
- 步长:每次滑动的长度
- 问:为什么要使用步长?
- 答:在卷积操作时,通常希望输出图像分辨率与输入图像分辨率相比会逐渐减少,即图像被约减。因此,可以通过改变卷积核在输入图像中移动步长大小来跳过一些像素,进行卷积滤波。
- 零填充:在图片扩大后在四周填零
问:为什么要零填充?
答:原始图片边缘信息对输出贡献得少,输出图片丢失边缘信息,使用零填充能够充分的利用边缘信息,使得最终模型预测效果更好。 - 特征图:图像与卷积核进行卷积运算得到的结
4. 卷积的特征
- 卷积层的卷积特征:
- 局部连接:在卷积层(假设是第 𝑙层)中的每一个神经元都只和上一层(第 𝑙 −1层)中某个窗口内的神经元都连接。
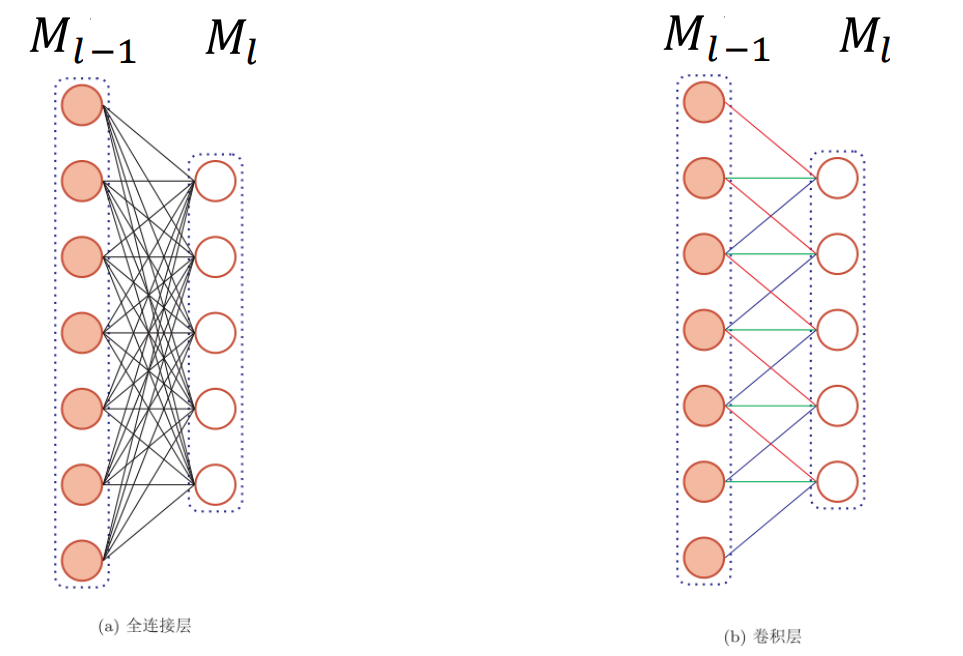
- 权重共享:第 𝑙 -1层的每个窗口都和相同的卷积核做内积,而卷积核就是权重参数。
- 局部连接:在卷积层(假设是第 𝑙层)中的每一个神经元都只和上一层(第 𝑙 −1层)中某个窗口内的神经元都连接。
- 池化层的卷积特征:空间或时间上的下采样
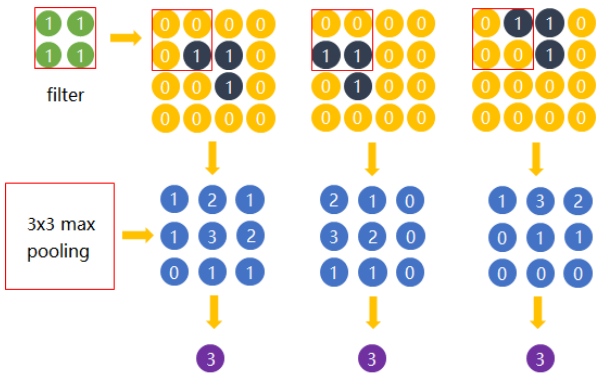
5. 卷积的计算
把握两个点:
- 卷积计算过程:无论是输入是几维,即无论是几通道,都是:内积求和–>滑动–>内积求和–>滑动…
- 给出输入大小、卷积核大小、零填充数、步长大小,能够计算输出大小。无论是输入是几维,计算公式都一样:

(1) 一维卷积计算

(2) 二维卷积计算(黑白图片)
黑白图片能够用一个二维矩阵表示,每一个像素点的范围是[0, 255]。
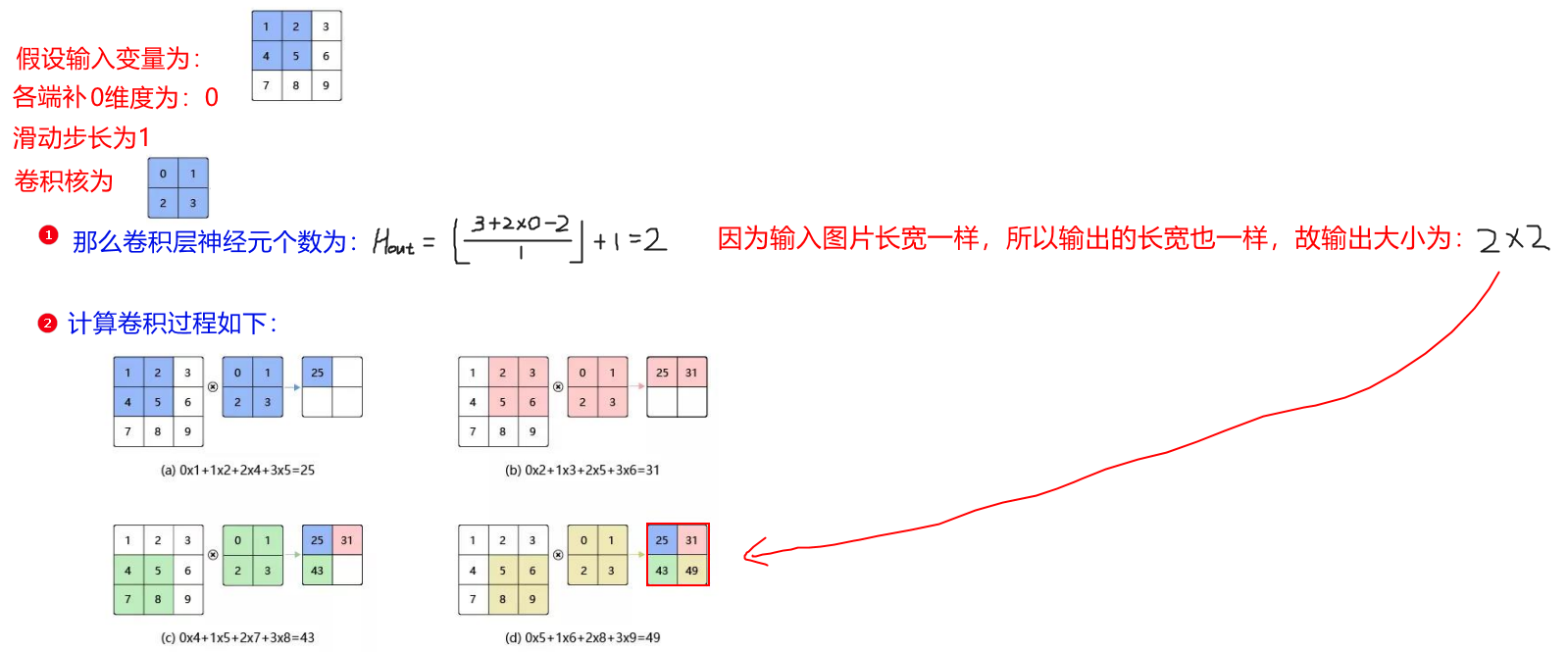
注意:
- 卷积核一般是正方形的。
- 输入图片可能不是正方形,这时计算输出大小时,长宽要分别计算。
(2) 三维卷积计算(彩色图片)
因为任意彩色可以用红绿黄三种颜色调和而成。所以彩色图片能够用一个三维矩阵表示,即能够用一个张量表示 𝑋 = (𝑋𝑅, 𝑋𝐺, 𝑋𝐵) 。其中𝑋𝑅, 𝑋𝐺, 𝑋𝐵是三个通道的数据,各自用矩阵表示。
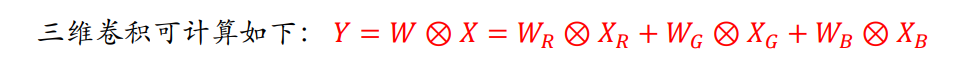
注意:卷积核的维数通常与图片维数一样。
6. 卷积的优势
-
保留空间信息:对比全连接层将输入展开成一维的计算方式,卷积运算可以有效学习到输入数据的空间信息。
-
局部连接:对于二维图像,局部像素关联性较强,这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征。

-
权重共享:与图像计算的过程中,卷积核的权重是共享的,这就大大降低了网络的训练难度。
-
不同层级卷积提取不同特征:在卷积神经网络中,通过使用多层卷积进行堆叠,从而达到提取不同类型特征的作用。比如,浅层卷积提取的是图像中的边缘等信息;中层卷积提取的是图像中的局部信息;深层卷积提取的则是图像中的全局信息。这样,通过加深网络层数,CNN就可以有效地学习到图像从细节到全局的所有特征了
7. 卷积神经网络
- 本质:卷积网络本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
- 组成:

- 应用场景:卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性。
7.1 卷积层
- 作用:提取一个图片的特征,不同的卷积核相当于不同的特征提取器。
- 计算:卷积后还要加上偏置,再经过激活函数

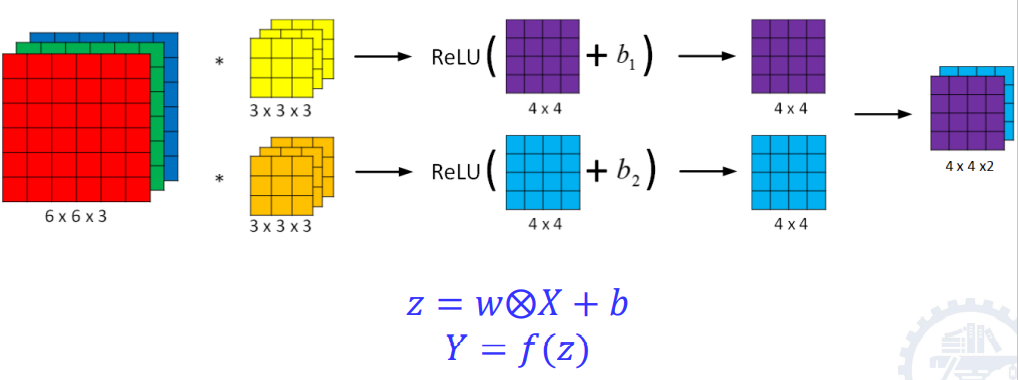
7.2 池化层
-
作用:Pooling layers是CNN中用来对特征进行缩小概括的,降低特征数量,从而减少参数数量,提高运算速度的,同样能减小noise影响,让各特征更具有健壮性。

-
关于上采样和下采样:
① 上采样:使数据矩阵变大
② 下采样:使数据矩阵变小 -
池化标准:采样下采样,一般是Max或Average

7.3 全连接层
在全连接层中,我们将最后一个卷积层的输出展平,然后与下一次进行全连接。
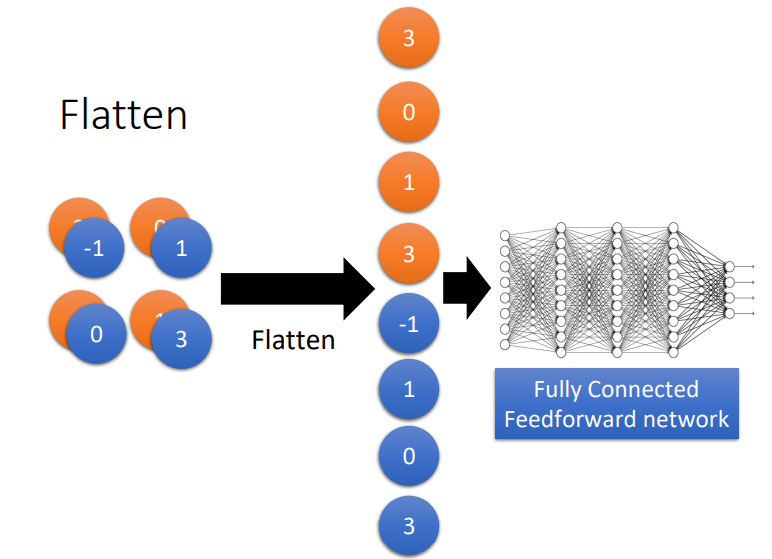
8. 前向传播

9. 反向传播
CNN反向传播的不同之处:
-
首先要注意的是,一般神经网络中每一层输入输出a,z都只是一个向量,而CNN中的a,z是一个三维张量,即由若干个输入的子矩阵组成。
-
其次:
- 池化层没有激活函数。这个问题倒比较好解决,令池化层的激活函数为其本身,即𝑓(𝑧) = 𝑧。这样池化层激活函数的导数为1。
- 池化层在前向传播的时候,对输入进行了压缩,那么我们向前反向推导上一层的误差时,需要做upsample(上采样) 处理。
- 卷积层是通过张量卷积,或者说若干个矩阵卷积求和而得到当前层的输出,这和一般的网络直接进行矩阵乘法得到当前层的输出不同。这样在卷积层反向传播的时候,上一层误差的计算方法肯定有所不同。
- 卷积层 W使用的运算是卷积,那么由该层误差推导出该层的所有卷积核的W,b的方式也不同。
虽然CNN的反向传播和DNN有所不同,但本质上还是4个核心公式的变形,思路是一样的。

9.1 池化层的反向传播算法
- 第一步:正向求激活值:前面已经介绍使用max或average求输出
- 第二步:反向求误差:
首先,回顾一下全连接神经网络的反向传播的四个核心公式:
反向传播就是要从缩小后的误差δ𝑙+1,还原池化前较大区域对应的误差δ𝑙。也就是说要根据上面的第二个式子计算误差:- f 𝑙 ′ ( z ( 𝑙 ) ) f_{𝑙}^{'} (z^{(𝑙)}) fl′(z(l)) 是已知的
-
(
W
l
+
1
)
T
δ
l
+
1
(W^{l+1})^{T}\delta ^{l+1}
(Wl+1)Tδl+1 不知道,如何求?

- 第三步:更新参数w,b:由于池化层没有参数,所以没有w,b的更新
9.2 卷积层的反向传播
-
第一步:正向求激活值
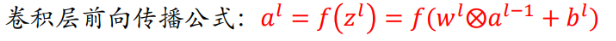
-
第二步:反向求误差:

-
第三步:更新参数w,b
-
更新w


-
更新b
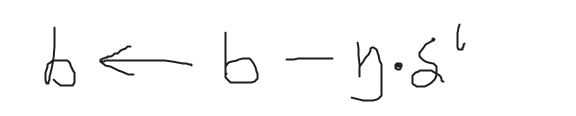
-
10. 典型的卷积神经网络
- LeNet:典型的卷积神经网络
- AlexNet
- VGG
- GooLeNet
- ResNet
- DenseNet
11. 总结
11.1 关于输出尺寸和参数个数的计算

例题:
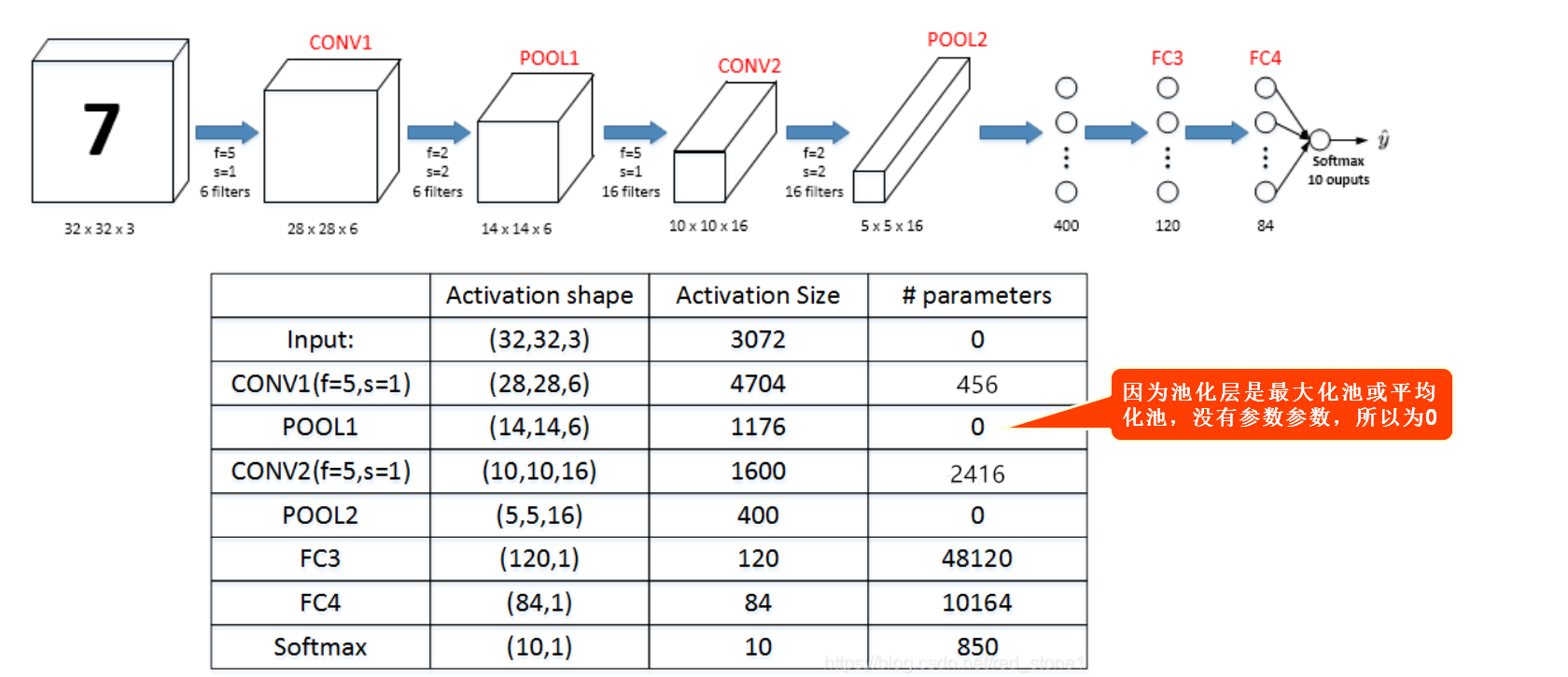
11.2 与全连接神经网络的区别
- CNN一个非常重要的特点就是头重脚轻(越往输入权值越少,越往输出权值越多),呈现出一个倒三角的形态,这就很好地避免了BP神经网络中反向传播的时候梯度损失得太快。
- 由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;而全连接神经网络的特征抽取和模型训练分开独立的。
- 由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势
- 处理图像时,参数过多,导致训练效率低,也容易导致过拟合。 因为图像的维度比较高,而前馈神经网络参数个数是层之间乘积之和的形式,比如:
-
相关阅读:
代码坏味道与重构之霰弹式修改和依恋情结
2021美亚杯个人赛
数据库MySQL----(二)语句
Redis快速入门
工业控制系统面临的安全问题分析
思科模拟器--08.三层交换机配置实验(两个交换机)--24.5.22
花生壳内网穿透+Windows系统,如何搭建网站?
阿里云WAF应用防火墙核心概念与购买使用
【log4j】基本使用
打造高效互联网医院系统源码:解读其核心功能及应用
- 原文地址:https://blog.csdn.net/qq_43546676/article/details/127713760