-
4.累积分布函数CDF
1. CDF(cumulative distribution function)
从数学上来说,对于连续型随机变量,累积分布函数(Cumulative Distribution Function, 简称CDF)是概率分布函数的积分。
累积分布函数就是 分布函数 。对于一维数据的可视化,直方图(Histogram)与核密度估计(Kernel Density Estimates)可以很好的表示各个数据值的概率分布,但在表示数据累积分布上这两种方法就无能为力了。
数据的累积分布,也即小于等于当前数据值的所有数据的概率分布,对于表示数据点在某个区间内出现的概率有很大的帮助。

2.累积分布函数(CDF)的使用
以-4到4之间分布的10000个数据点为例,绘制成直方图与核密度估计是这样的:

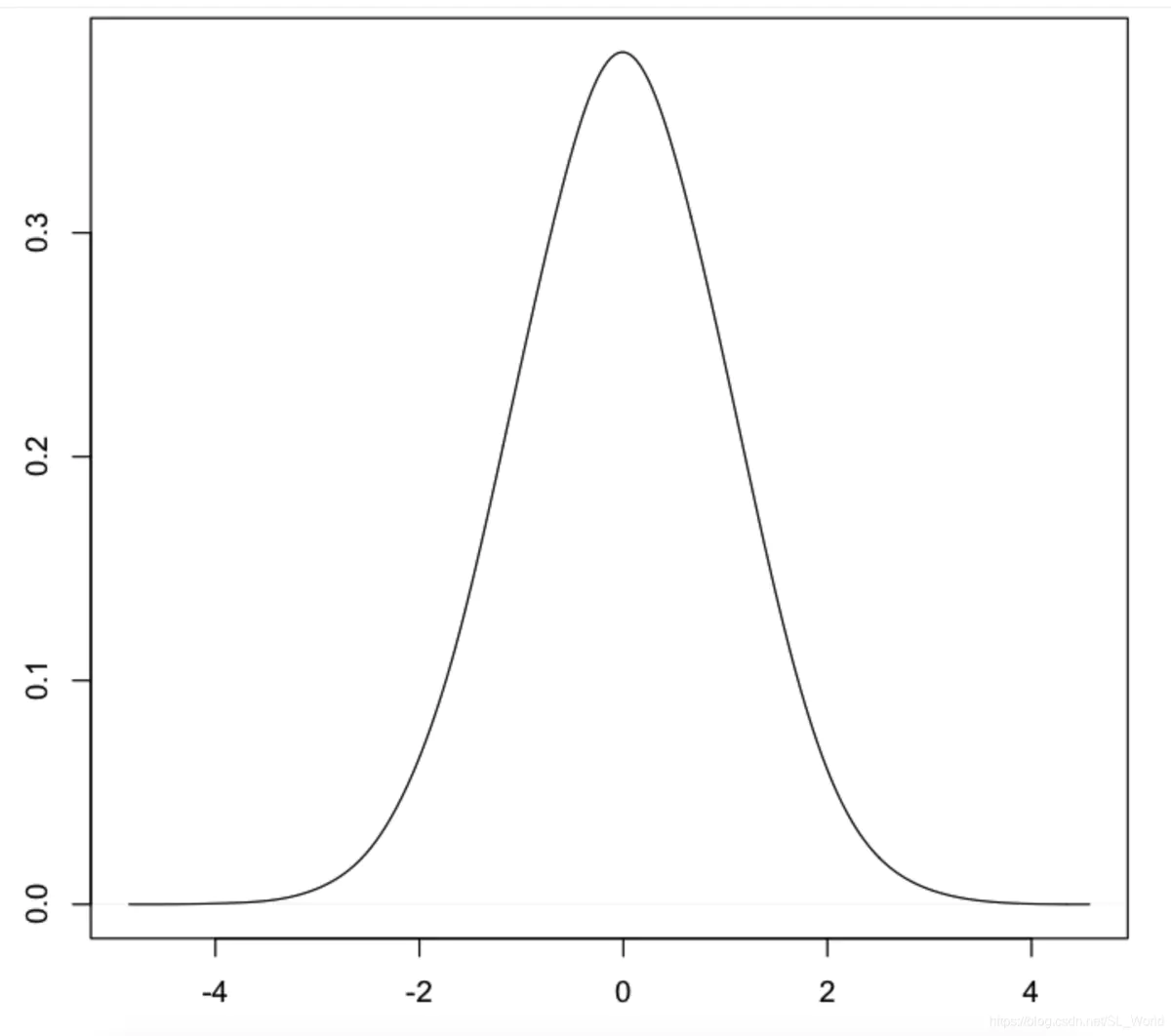
这两张图可以很好的表示-4到4之间任意数据值的概率大小,但是在回答下面几个问题的时候就比较困难了:-
所有大于2的数据点在总数据集中所占比例约有多大?
-
所有大于1.3而小于2的数据点在总数据集中所占比例是多少?
在上述例子中,数据集大致遵循正态分布,因此从直方图或核密度估计的结果中推测这两个问题的答案还是可能的;但是对于不规则的概率分布曲线来说,这样做就基本上行不通了。回答上述问题的通用方法是绘制累积分布函数图:

根据这张累积分布函数图,可以很方便地回答之前的两个问题:-
CDF中横轴上的2对应的Y值约为0.98,因此所有大于2的数据点所占比例约为2%。
-
CDF中横轴上的1.3对应的Y值约为0.75,因此所有介于1.3和2之间的数据点所占比例约为23% (0.98-0.75)。
3. 累积分布函数的特点
与直方图、核密度估计相比,累积分布函数存在以下几个特点:
-
累积分布函数是X轴单调递增函数。
-
累积分布函数更加平滑,图像中噪音更小。
-
累积分布函数没有引入带宽等外部概念,因此不会丢失任何数据信息。对于给定的数据集,累积分布函数是唯一的。
-
所有的CDF中,在x趋近最小值时,CDF趋近于0,当x趋近最大值时,CDF趋近与1(100%)
4. PDF (probability density function)
PDF:连续型随机变量的概率密度函数是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。
概率密度函数,描述可能性的变化情况,比如正态分布密度函数,给定一个值, 判断这个值在该正态分布中所在的位置后, 获得其他数据高于该值或低于该值的比例。
CDF:能完整描述一个实数随机变量x的概率分布,是概率密度函数的积分。随机变量小于或者等于某个数值的概率P(X<=x)即:F(x) = P(X<=x)。
可使用 CDF 确定取自总体的随机观测值将小于或等于特定值的概率。还可以使用此信息来确定观测值将大于特定值或介于两个值之间的概率。
对于所有实数x,CDF(cumulative distribution function),与概率密度函数PDF(probability density function)相对。任何一个CDF,是一个不减函数,累积和为1。累计分段概率值就是所有比给定x小的数在数据集中所占的比例。任意特定点处的填充x的 CDF 等于 PDF 曲线下直至该点左侧阴影面积。
5. 例子
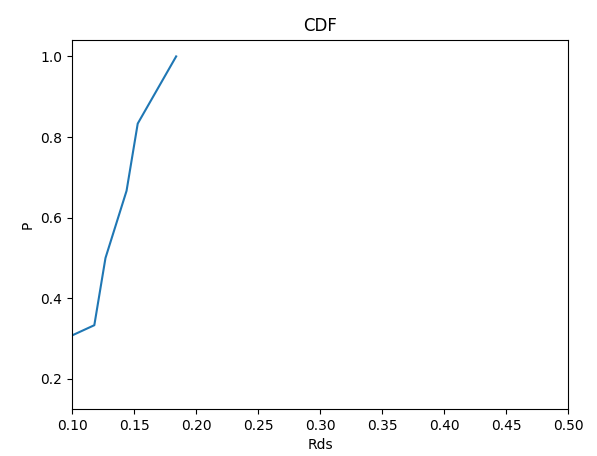
import pandas as pd import matplotlib.pyplot as plt import numpy as np data = [] data = pd.read_csv("D:\\dataset.csv", header=None) print(data) denominator = len(data[0]) # 分母数量 Data = pd.Series(data[0]) # 将数据转换为Series利用分组频数计算 Fre = Data.value_counts() Fre_sort = Fre.sort_index(axis=0, ascending=True) Fre_df = Fre_sort.reset_index() # 将Series数据转换为DataFrame Fre_df[0] = Fre_df[0] / denominator # 转换成概率 Fre_df.columns = ['Rds', 'Fre'] Fre_df['cumsum'] = np.cumsum(Fre_df['Fre']) plot = plt.figure() ax1 = plot.add_subplot(1, 1, 1) ax1.plot(Fre_df['Rds'], Fre_df['cumsum']) ax1.set_title("CDF") ax1.set_xlabel("Rds") ax1.set_ylabel("P") ax1.set_xlim(0.1, 0.5) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
-
相关阅读:
接口和抽象类有什么区别?
黑客技术(自学)——网络安全
S-3A5001 DPDK性能优化
Emgu CV4图像处理之打开Tensorflow训练模型17(C#)
UG\NX二次开发 连接曲线、连结曲线 UF_CURVE_auto_join_curves
AtCoder Beginner Contest 233 (A-Ex)
【2012NOIP普及组】T4. 文化之旅 试题解析
Arduino驱动FXLN83XXQ三轴加速度传感器(惯性测量传感器篇)
大数据之LibrA数据库系统告警处理(ALM-12031 omm用户或密码即将过期)
【22年11月12日更新】搭建宝塔面板、青龙面板“京东代挂”
- 原文地址:https://blog.csdn.net/u014217137/article/details/127800831
