-
redo丢失的各种情况处理
测试环境oracle版本:19.3(NOARCHIVELOG MODE)
场景1:被删的redo组有冗余(无论redo的状态如何)
1、构造故障场景
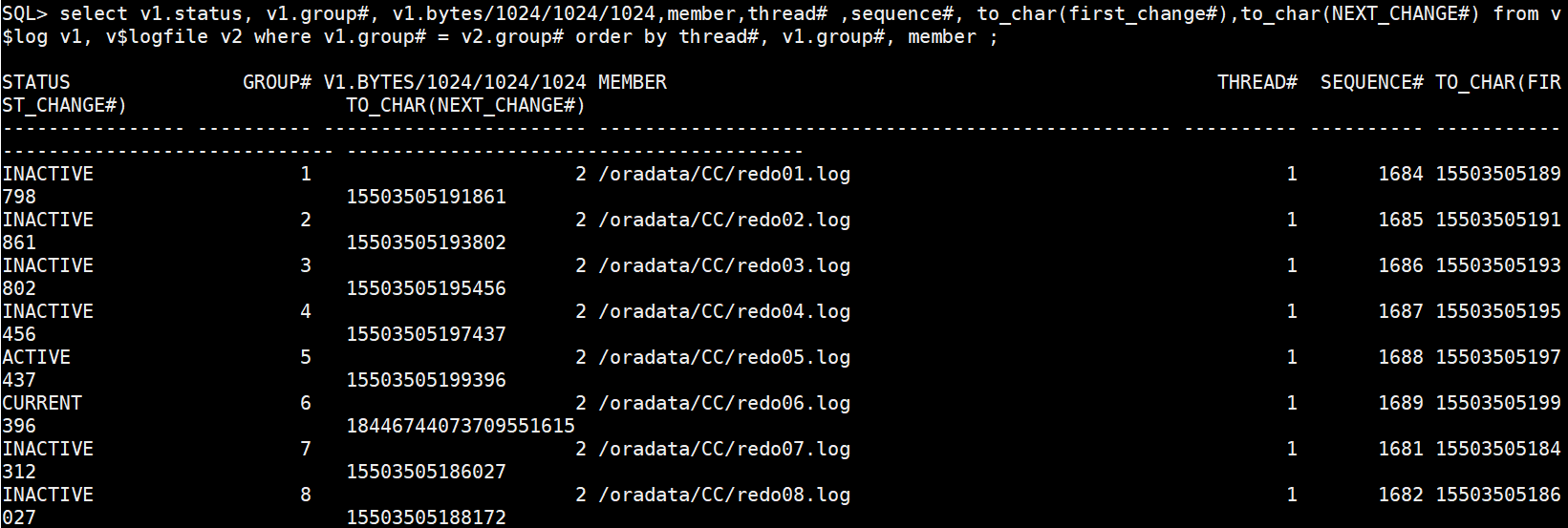
(1)查看当前redo配置
set lines 400 pages 9999
col MEMBER for a50
select v1.status, v1.group#, v1.bytes/1024/1024/1024,member,thread# ,sequence#, to_char(first_change#),to_char(NEXT_CHANGE#) from v$log v1, v$logfile v2 where v1.group# = v2.group# order by thread#, v1.group#, member ;
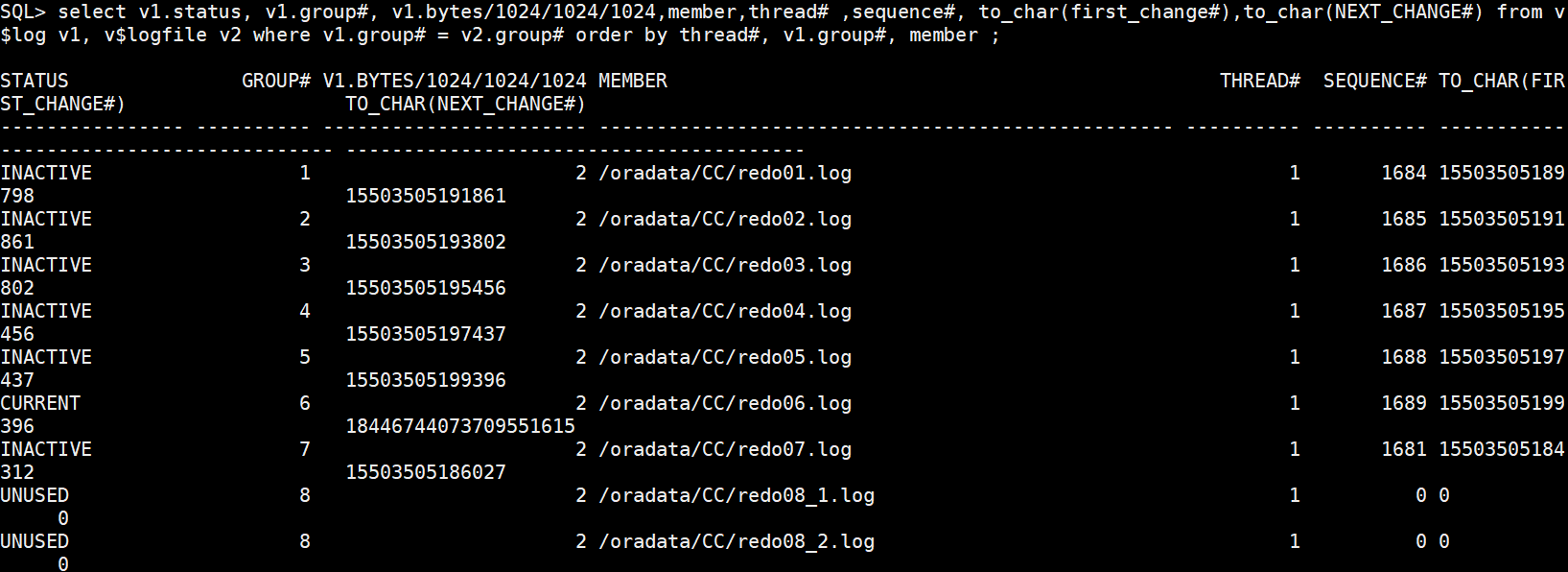
(2)构造冗余的redo组
alter database drop logfile group 8;
alter database add logfile thread 1 group 8 ('/oradata/CC/redo08_1.log','/oradata/CC/redo08_2.log') size 2g ;

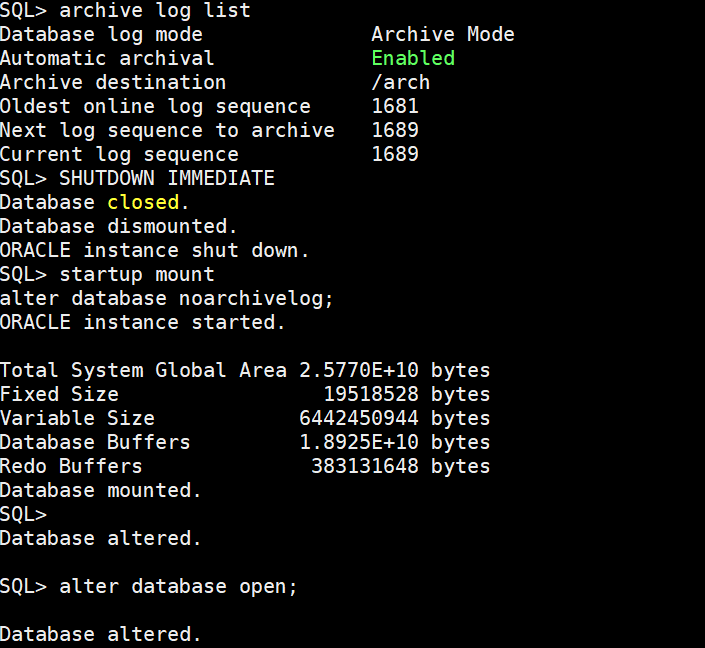
(3)关闭归档
shutdown immediate
startup mount
alter database noarchivelog;
alter database open;
(4)切归档,将冗余的log组设为current
alter system switch logfile;
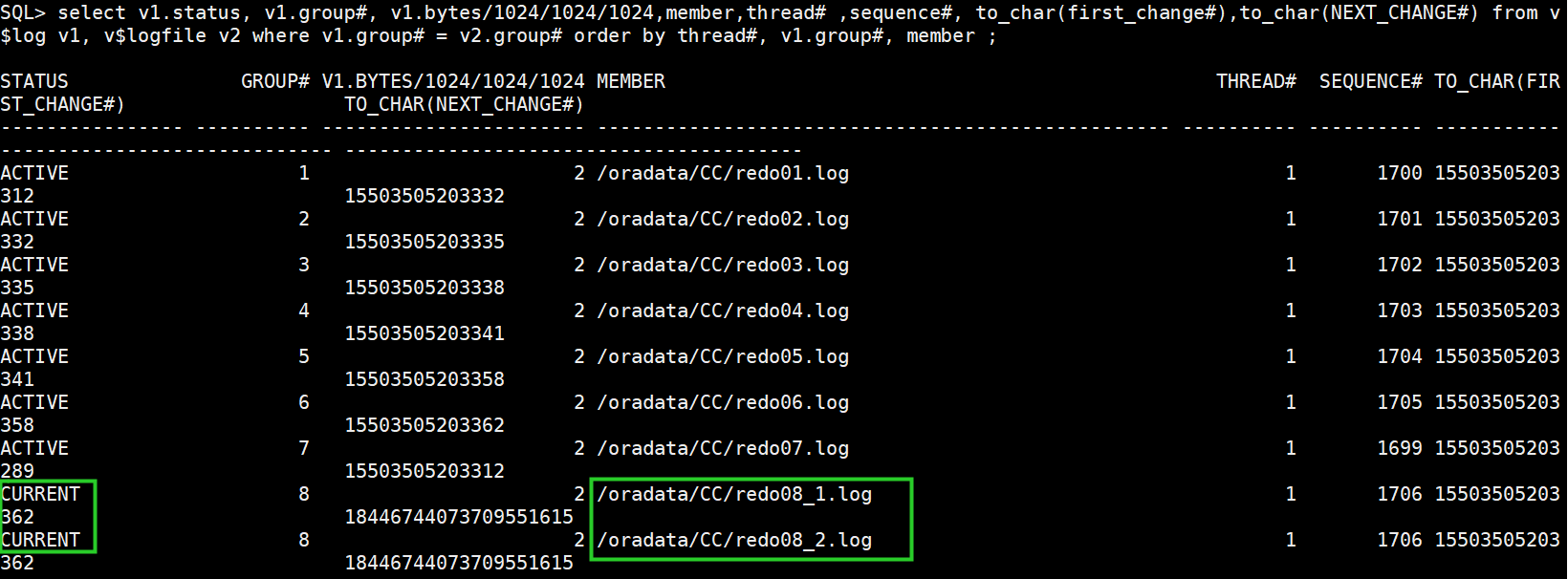
(5)删除冗余的member
rm -f /oradata/CC/redo08_2.log
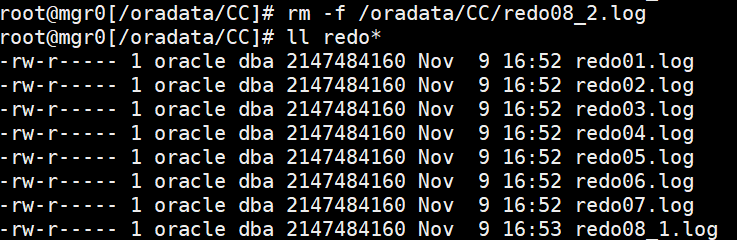
(6)查看alert日志
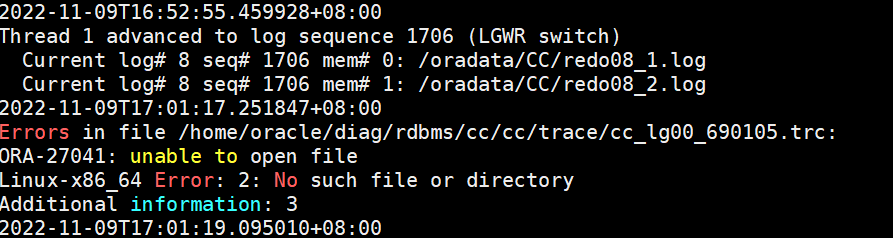
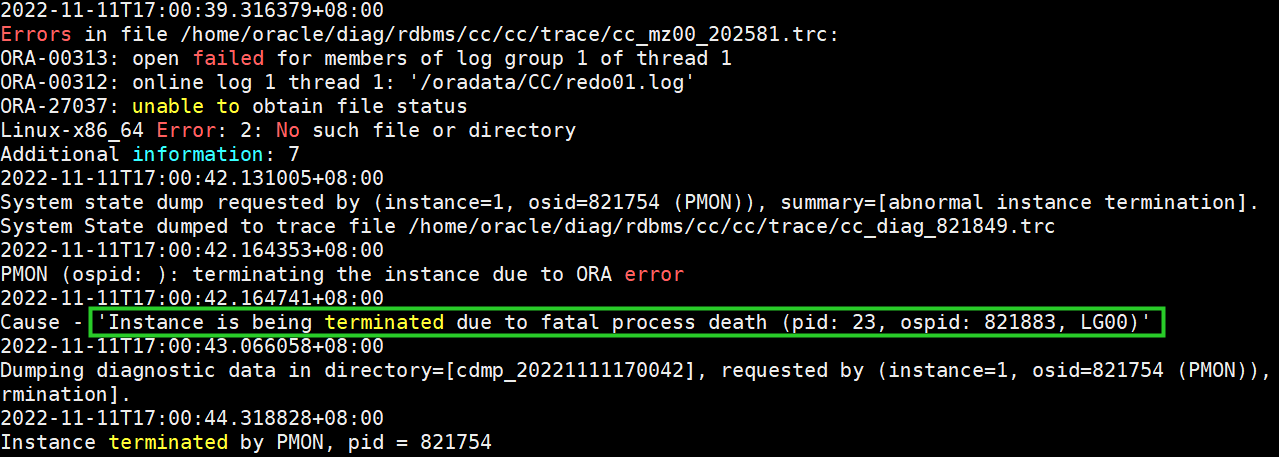
查看alert日志中lg00的trace日志,报错如下

2、解决思路
redo组若有冗余不影响数据库的写入操作,但是alert会有报错,可以把缺失的member从数据库中移除,然后重新添加即可
3、解决步骤
(1)切归档,将缺少redo member的组切换非current
alter system switch logfile;
CURRENT状态会导致drop不成功
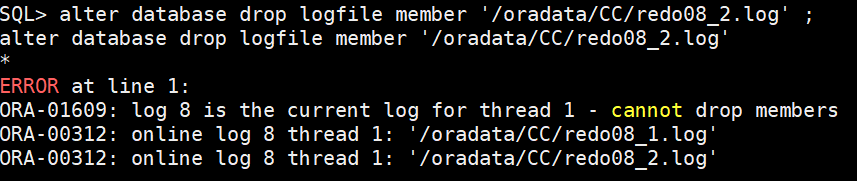
(2)执行drop缺失的member
alter database drop logfile member '/oradata/CC/redo08_2.log'
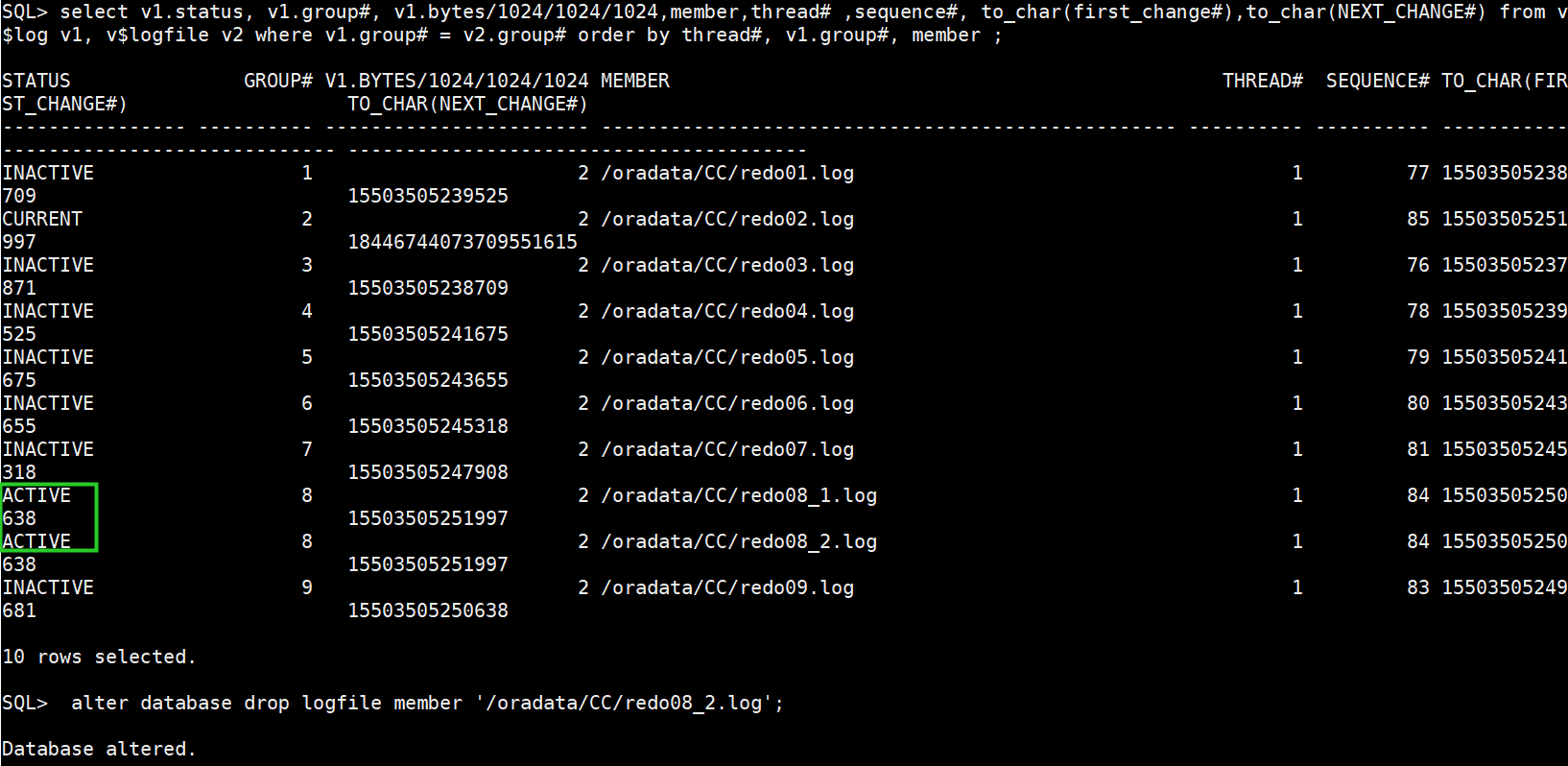
(3)重新添加member
alter database add logfile member '/oradata/CC/redo08_2.log' to group 8;

(4)将current redo切到此磁盘组,alert日志不再报错
4、风险评估
由于redo member有冗余,即使丢失一个member也不会影响业务,无大的风险
场景2:被删的redo组无冗余(INACTIVE的redo组)
1、构造故障场景
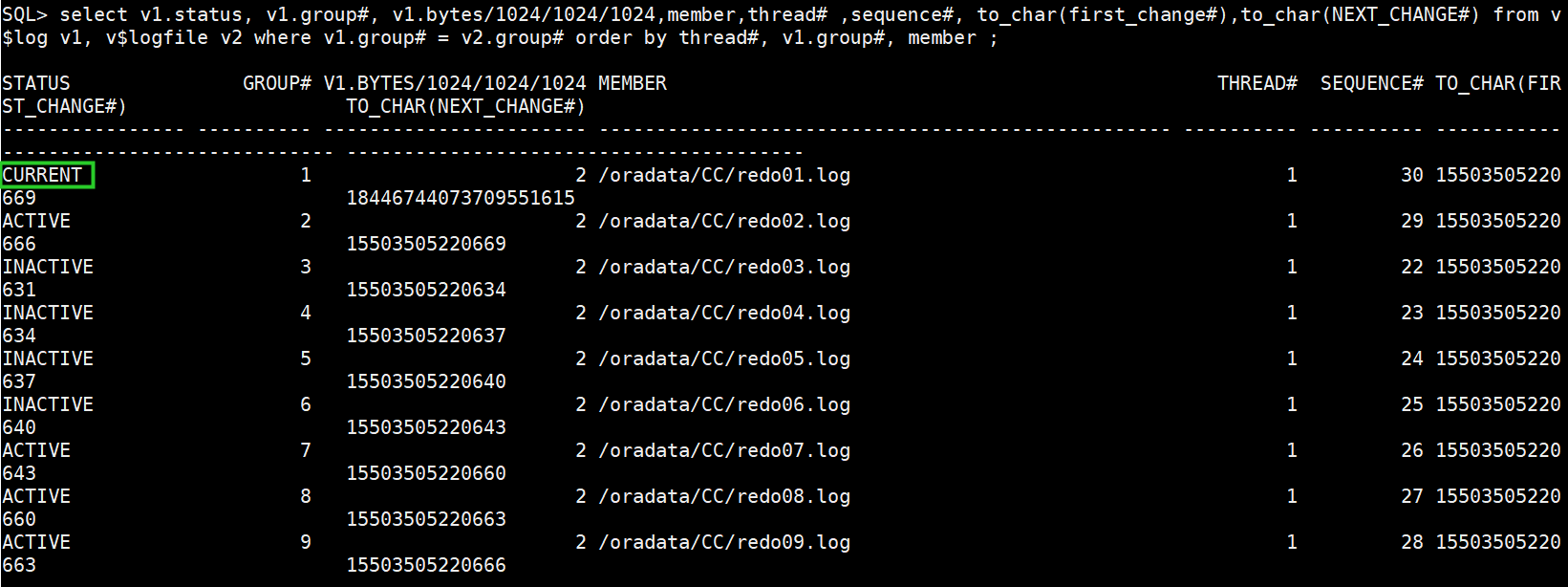
(1)查看当前redo配置
set lines 400 pages 9999
col MEMBER for a50
select v1.status, v1.group#, v1.bytes/1024/1024/1024,member,thread# ,sequence#, to_char(first_change#),to_char(NEXT_CHANGE#) from v$log v1, v$logfile v2 where v1.group# = v2.group# order by thread#, v1.group#, member ;

(2)删除INACTIVE的redo组对应的redo文件
rm -f /oradata/CC/redo01.log
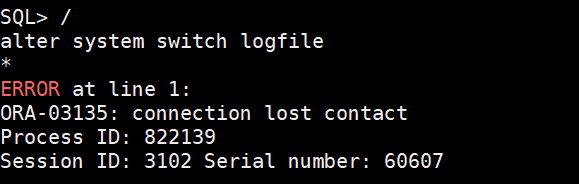
(3)切归档直到被删的redo组为current
alter system switch logfile;
此时会导致数据库崩溃
2、解决思路
分为两种情况:
情况1:
删除INACTIVE的redo后立马处理,执行alter database clear unarchived logfile group 1即可恢复
情况2:
删除INACTIVE的redo后没有即时干预,一旦被切为CURRENT会导致实例崩溃,此时就要按照CURRENT REDO被删的场景来解决
3、解决步骤
情况1:
alter database clear unarchived logfile group 1;
重新生成redo,alert日志报错如下(但是成功将redo01生成)
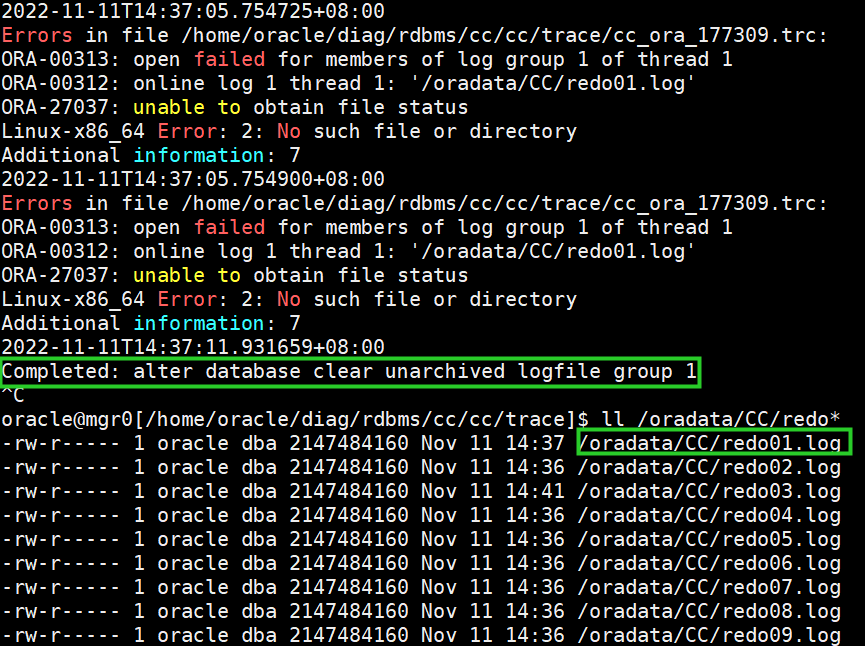
且alert日志不再报错
情况2:
类似场景3的解决步骤
(1)startup mount
(2)查询redo情况
set lines 400 pages 9999
col MEMBER for a50
select v1.status, v1.group#, v1.bytes/1024/1024/1024,member,thread# ,sequence#, to_char(first_change#),to_char(NEXT_CHANGE#) from v$log v1, v$logfile v2 where v1.group# = v2.group# order by thread#, v1.group#, member ;
(3)recover database until cancel;
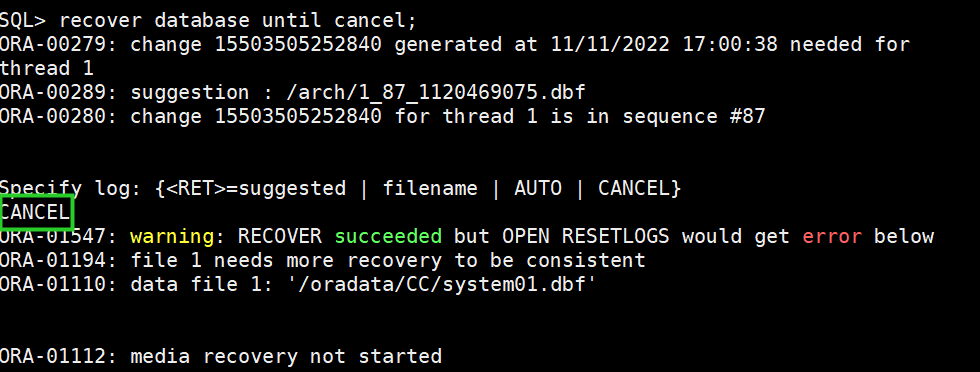
(4)alter database open RESETLOGS;
可能会报 ORA-01194: file 1 needs more recovery to be consistent错
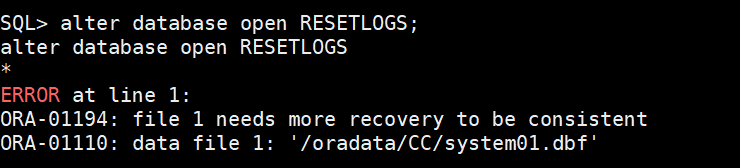
(5)配置隐含参数推scn和跳过redo
alter system set event="21307096 trace name context forever, level 3" scope=spfile;
alter system set "_allow_resetlogs_corruption" = true scope=spfile;
(6)重启到mount
shutdown immediate
startup mount
(7)alter database open RESETLOGS;
此时open成功且alert日志没有报错

4、风险评估
情况1:
此种情况下,并不会造成数据丢失的风险
情况2:
可能有redo未落盘的情况,导致数据丢失
场景3:被删的redo组无冗余(CURRENT/ACTIVE的redo组)
1、构造故障场景
(1)查看当前redo配置
set lines 400 pages 9999
col MEMBER for a50
select v1.status, v1.group#, v1.bytes/1024/1024/1024,member,thread# ,sequence#, to_char(first_change#),to_char(NEXT_CHANGE#) from v$log v1, v$logfile v2 where v1.group# = v2.group# order by thread#, v1.group#, member ;
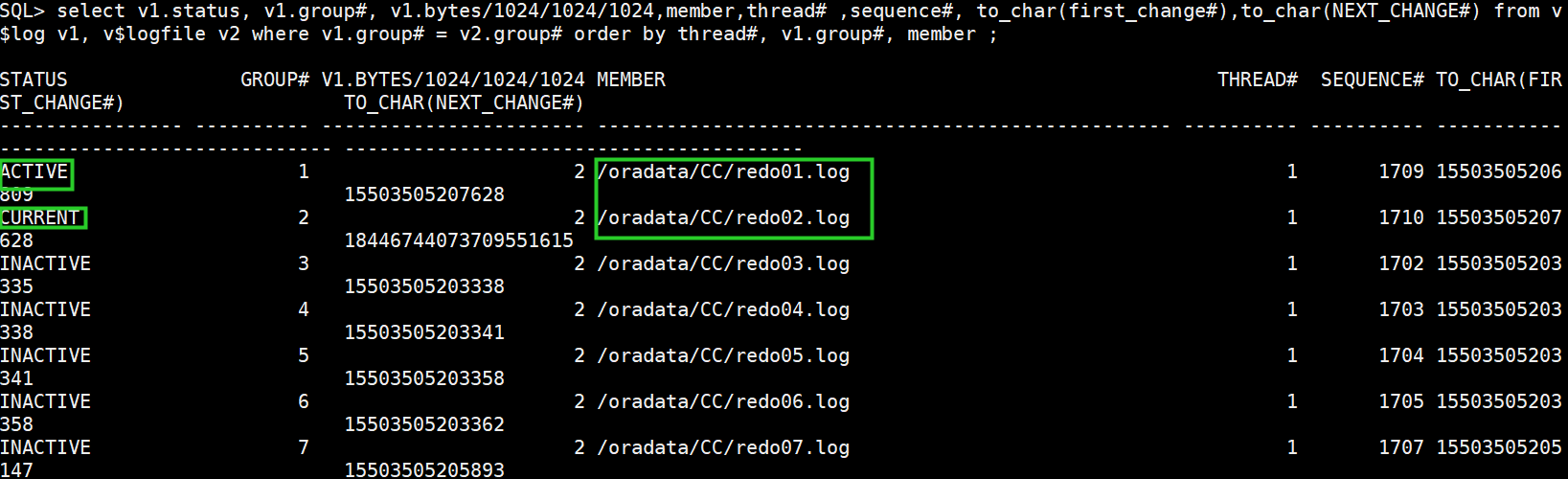
(2)将ACTIVE和CURRENT redo组对应的logfile删除



(3)多切几次归档,数据库会自动terminate
alter system switch logfile;
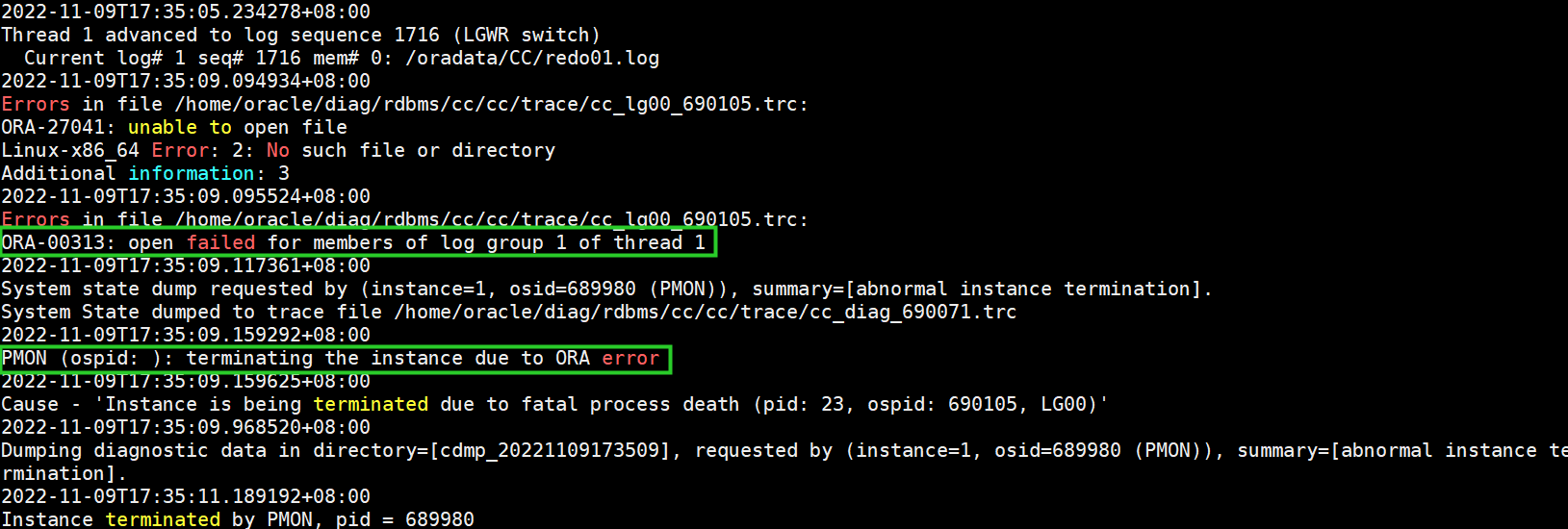
2、解决步骤
(1)将数据库起到mount,并查询redo组状态
startup mount
set lines 400 pages 9999
col MEMBER for a50
select v1.status, v1.group#, v1.bytes/1024/1024/1024,member,thread# ,sequence#, to_char(first_change#),to_char(NEXT_CHANGE#) from v$log v1, v$logfile v2 where v1.group# = v2.group# order by thread#, v1.group#, member ;
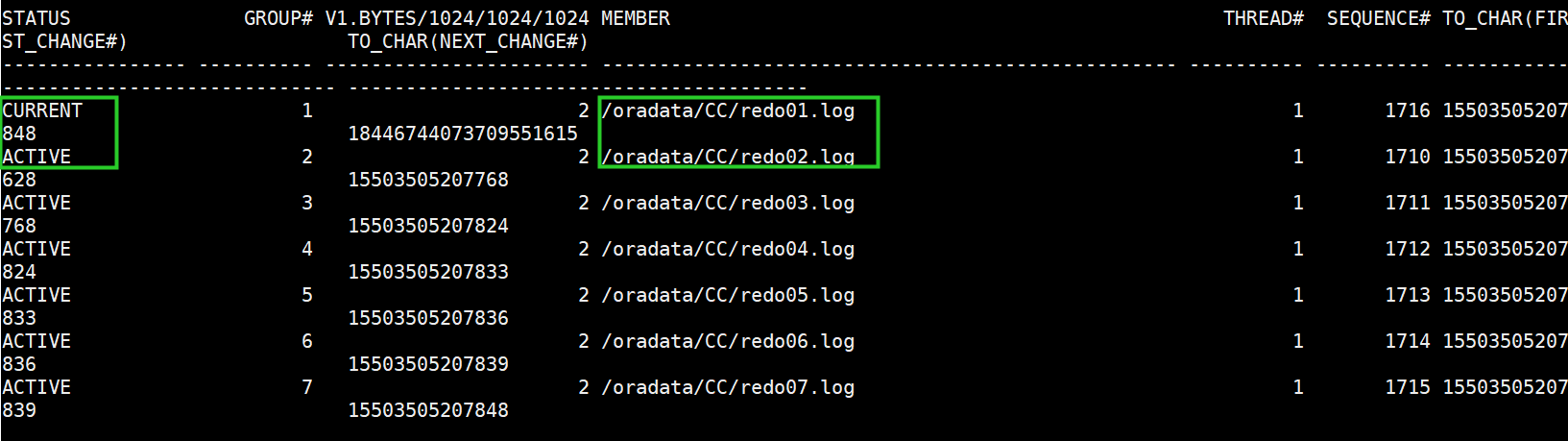
发现缺
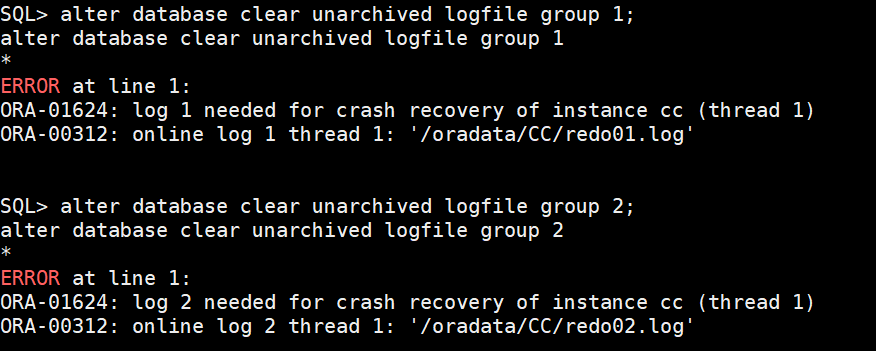
(2)尝试clear CURRENT/ACTIVE的日志组
alter database clear unarchived logfile group 1;
alter database clear unarchived logfile group 2;
报错如下:
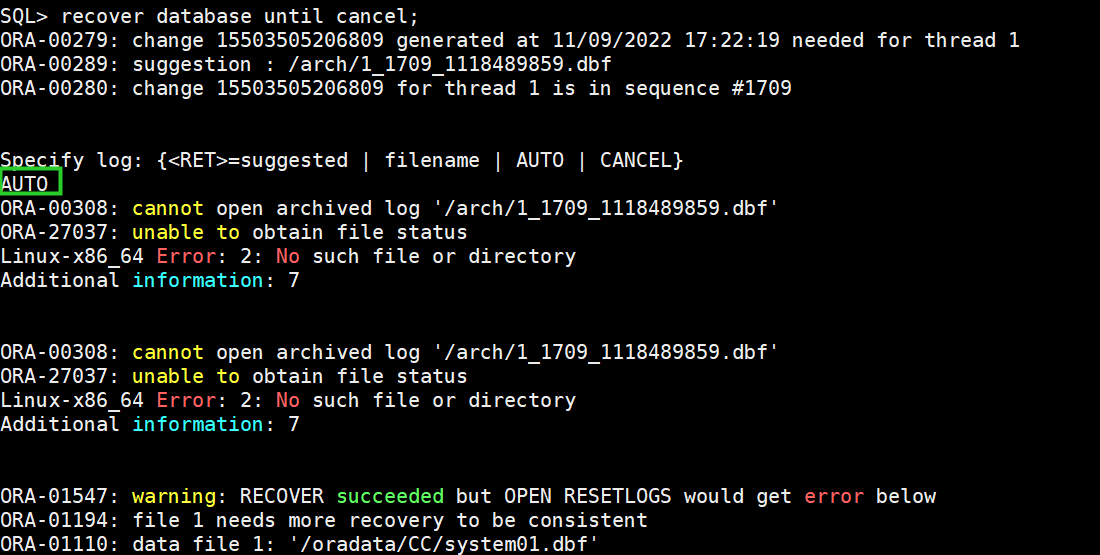
(3)recover数据库
recover database until cancel;
选择AUTO
(4)resetlogs启动数据库
alter database open resetlogs;
可能的报错
ORA-00600: internal error code, arguments: [kcbzib_kcrsds_1], [], [], [], [],[], [], [], [], [], [], []
--scn不一致,需要推进scn
ORA-01194: file 1 needs more recovery to be consistent
--scn不一致,需要推进scn
ORA-00600: internal error code, arguments: [4194], [7], [6], [], [], [], [], [], [], [], [], []
--undo回滚段与redo不一致,需要重建undo
(5)处理方法
ORA-00600: internal error code, arguments: [kcbzib_kcrsds_1], [], [], [], [],[], [], [], [], [], [], []
或
ORA-01194: file 1 needs more recovery to be consistent
通过设置隐含参数推scn:
startup nomount
alter system set event="21307096 trace name context forever, level 3" scope=spfile;
alter system set "_allow_resetlogs_corruption" = true scope=spfile;
重启数据库
shutdown immediate
startup mount
alter database open
若还报kcbzib_kcrsds_1或ORA-01194错误,多次重启直到不报kcbzib_kcrsds_1或ORA-01194错,再次报错可能是ORA-00600: internal error code, arguments: [4194]
或
ORA-00600: internal error code, arguments:[4195]
或
ORA-00600: internal error code, arguments:[4193]
按照下面的方法处理
ORA-00600: internal error code, arguments: [4194], [7], [6], [], [], [], [], [], [], [], [], []
回滚段不一致通常会导致数据库open几秒钟,然后down,我们可以在open的几秒钟同时执行建新undo表空间,并将undo_tablespace参数设为新建的undo表空间
startup mount
alter database open
create undo tablespace undotbs2 datafile '/oracle/oradata/SH3/undotbs2.dbf' size 100m;
alter system set undo_tablespace=undotbs2 scope=spfile;
shutdown immediate
startup mount
alter database open
(6)后续操作
drop tablespace UNDOTBS4 including contents and datafiles;
如果在drop过程中报如下错误:
ORA-01548: active rollback segment '_SYSSMU6_3592678216$' found, terminate dropping tablespace
查看当前异常的回滚段:
select segment_name, status, tablespace_name from dba_rollback_segs where status not in ('ONLINE', 'OFFLINE');

需要设置隐含参数,_offline_rollback_segments,强制offline异常的回滚段
create pfile='/oracle/pfile.ora' from spfile;
修改/oracle/pfile.ora,添加
*._offline_rollback_segments=(_SYSSMU6_3592678216$,_SYSSMU7_1736514206$)
startup pfile='/oracle/pfile.ora'
drop tablespace UNDOTBS4 including contents and datafiles;
(7)恢复原参数
shutdown immediate
startup
alter system reset event;
alter system reset "_allow_resetlogs_corruption";
将新建undo数据文件改成原来的大小(如果原来的undo表空间大,就要添加数据文件)
alter database datafile '/oracle/oradata/SH3/undotbs2.dbf' resize 30G;
shutdown immediate
startup
其他可能的情况:
情况1:
recover database until cancel时,报ORA-16433: The database or pluggable database must be opened in read/write mode错
需要重建控制文件
CREATE CONTROLFILE REUSE DATABASE "SH1" RESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 8192
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/oracle/oradata/SH1/redo01.log' SIZE 1024M BLOCKSIZE 512,
GROUP 2 '/oracle/oradata/SH1/redo02.log' SIZE 1024M BLOCKSIZE 512,
GROUP 3 '/oracle/oradata/SH1/redo03.log' SIZE 1024M BLOCKSIZE 512
-- STANDBY LOGFILE
DATAFILE
'/oracle/oradata/SH1/system01.dbf',
'/oracle/oradata/SH1/sysaux01.dbf',
'/oracle/oradata/SH1/sysaux02.dbf',
'/oracle/oradata/SH1/sysaux03.dbf',
'/oracle/oradata/SH1/undotbs04.dbf',
'/oracle/oradata/SH1/users01.dbf',
'/oracle/oradata/SH1/datafile/o1_mf_ceshi_jrcs6jhz_.dbf',
'/oracle/oradata/SH1/datafile/o1_mf_idx_cc_jrctcw1o_.dbf',
'/oracle/oradata/SH1/datafile/o1_mf_sys_shar_jrcs3zdr_.dbf',
'/oracle/oradata/SH1/datafile/o1_mf_tab_cc_jrct5r0q_.dbf',
'/oracle/oradata/SH1/datafile/o2_mf_tab_cc_jrct5r0q_.dbf'
CHARACTER SET AL32UTF8
;
然后
recover database using backup controlfile until cancel;
CANCEL
alter database open resetlogs;
ALTER TABLESPACE TEMP ADD TEMPFILE '/oracle/oradata/SH1/temp01.dbf' REUSE;
ALTER TABLESPACE TEMP ADD TEMPFILE '/oracle/oradata/SH1/temp02.dbf' REUSE;
ALTER TABLESPACE TEMP ADD TEMPFILE '/oracle/oradata/SH1/temp03.dbf' REUSE;
情况2:
处理完成后有些索引块损坏

select object_name,owner,object_type from dba_objects where object_id=1139870;
将索引drop掉重建即可解决(rebuild online不要用,有时无效)
4、风险评估
此种情况会导致数据丢失或者可能坏块,生产环境最好恢复之后重建数据库
-
相关阅读:
C++入门
web:[ACTF2020 新生赛]Include
1.2 三维场景动态生成正射纹理-人机交互实现区域框选
视频编解码 — 帧内预测
promise返回值多层嵌套
java毕业生设计中医药科普网站计算机源码+系统+mysql+调试部署+lw
【QandA C++】sizeof、strlen、static、extern、typedef、const、#define、内联函数等重点知识汇总
JavaEE(系列17) -- 线程安全的集合类
logcat 只打印符合包名的log
第8集丨流氓皇帝,贬谪之路,险象环生
- 原文地址:https://blog.csdn.net/du18020126395/article/details/127810578