-
什么是FD.IO/VPP?
作者介绍:
张帅 腾讯 WeChat:yorkszhang
个人公众号:Flowlet,专注于网络、云计算领域知识分享;
一、什么是http://FD.io?
FD.io (Fast data – Input/Output):是Linux基金会下的开源项目,其成立于2016年2月11日。该项目在通用硬件平台上提供了具有灵活性、可扩展、组件化等特点的高性能IO服务框架。该框架支持高吞吐量、低延迟、高资源利用率的user space IO服务,并可适用于多种硬件架构(x86,ARM,and PowerPC)和部署环境(bare metal(裸机), 虚拟机(VM),容器(container))。
http://FD.io开源项目的关键组件是由Cisco捐赠的已商用的VPP(Vector Packet Processing )库,VPP高度模块化,允许在不更改底层代码库的情况下轻松“插入”新的图节点。这使开发人员可以通过不同的转发图轻松构建任意数量的数据包处理解决方案。
http://FD.io利用DPDK的功能来支持其他子项目如NSH_ SFC, Honeycomb和ONE,这些子项目和VPP一起加速NFV的数据平面。http://FD.io项目与其他支持NFV和SDN的关键开源计划(如OPNFV)保持一致。请参阅OPNFV内的FastDataStacks(FTS)项目提案,了解项目的总体目标;该提案被称作为可选虚拟化数据平面并被集成在OpenStack和OpenDaylight(请参阅FastDataStacks)中。
二、什么是VPP?
1、介绍
VPP平台是一个可扩展的架构,提供开箱即用的交换机/路由器功能。它是思科矢量数据包处理(VPP)技术的开源版本:一种可在商用CPU上运行的高性能数据包处理协议栈。
使用VPP的好处在于其高性能,成熟的技术,模块化和灵活性以及丰富的功能集。
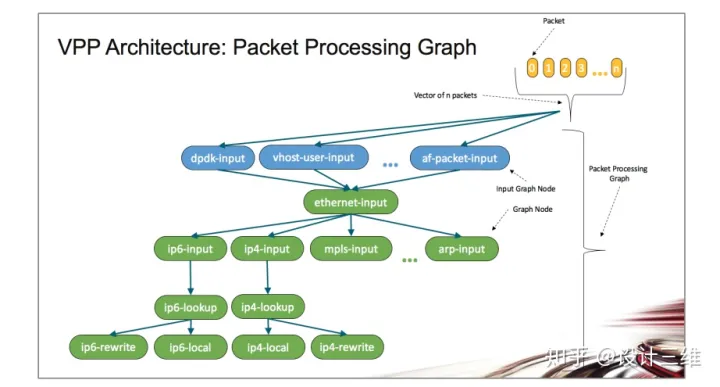
2、模块化,灵活,可扩展
VPP平台建立在“数据包处理图”之上。这种模块化的处理方法意味着任何人都可以“插入”新的图形节点。这使得VPP非常容易扩展,意味着可以为特定目的定制插件。
插件如何工作?
在运行时,VPP平台从RX环中获取所有可用数据包以形成数据包向量。将数据包处理图的节点(包括插件)逐个应用于整个数据包矢量。图节点很小且模块化,图节点之间松散耦合,这使得引入新的图节点,重新连接现有图节点变得相对容易。
插件可以引入新的图节点或重新排列数据包处理图。您还可以独立于VPP源代码树构建插件 - 这意味着您可以将其视为独立组件,可以通过将插件添加到插件目录来安装插件。
VPP平台可用于构建任何类型的数据包处理应用程序。它可以用作负载均衡器,防火墙,IDS或主机协议栈的基础架构,您还可以创建应用程序的组合。例如,您可以向vSwitch添加负载平衡功能。
VPP在用户空间运行,这意味着插件不需要更改核心代码 - 您可以扩展数据包处理引擎的功能,而无需更改在内核级别运行的代码。通过创建插件,任何人都可以通过以下方式扩展功能:
- 新的自定义图节点
- 图节点的重新排列
- 新的低级别的API
3、功能丰富
全套图节点允许构建各种各种的网络设备工作模型。在较高的层次上,该平台提供:
- 路由,桥接的快速查找表
- 任意n元组的分类器
- 开箱即用的交换/路由器功能
以下是VPP平台提供的功能摘要:

4、为什么称为矢量处理?
顾名思义,VPP使用矢量报文处理而不是标量报文处理。
在数据平面开发工具包(DPDK:data plane development kit’s)的轮询模式驱动程序(PMD:poll mode drivers)和环形缓冲区库的支持下,VPP旨在通过减少数据流/转发表缓存的未命中数来增加转发平面吞吐量,同时使用并行方法替换标准串行数据报文查找。
短时间存活的数据流或高熵数据报文字段(那些在数据包之间具有不同值的数据包)会使缓存失效。我们从设备启动开始:首先设备启动缓存是空的被称为缓存是“冷”的,这将导致所有查询都失败。未命中的数据报文随后用于填充缓存,缓存“预热”,此时缓存被称为是“温暖”的。热缓存应该导致适当数量的查询“命中”(使用简单的先进先出(FIFO),或者最近最少使用(LRU)或最不常用(LFU)算法决定是否用新的缓存替换旧的缓存。这个替换策略很重要,因为高速缓存流失可能是由于不良的替换算法造成的。然而,更可能的原因是那些讨厌的短时间存活的数据流,每次新添加短时间存活的数据流缓存都会导致后续查询miss,并且可能会替换缓存中的长期数据流缓存)。缓存中的有用数据不断被替换称为“缓存抖动”。
学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,久学习,或点击这里加qun免费
领取,关注我持续更新哦! !时间局部性:就数据包处理而言,这种现象注意到在短时间内采样的数据报文分组它们本质上相似,即使不相同相似性也很强。具有此类属性的数据包将重用相同的资源,并将访问相同(缓存)的内存位置。
标量报文处理:是指一次处理一个报文。即:报文是按照到达先后顺序来处理,第一个报文处理完,处理第二个,依次类推;较旧的传统方法还需要处理中断,并遍历调用栈(A calls B calls C….return return return...然后从中断返回),函数会频繁嵌套调用。然后,该过程执行以下三种操作之一:不作处理,丢弃或重写/转发报文。
传统标量报文处理有如下缺陷:
- I-cache(CPU指令缓存) 抖动(cache时间局限性和空间局限性特点)
- 每个报文都会产生一组相同的I-cache未命中
- 除了提供更大的cache之外,没有解决方法
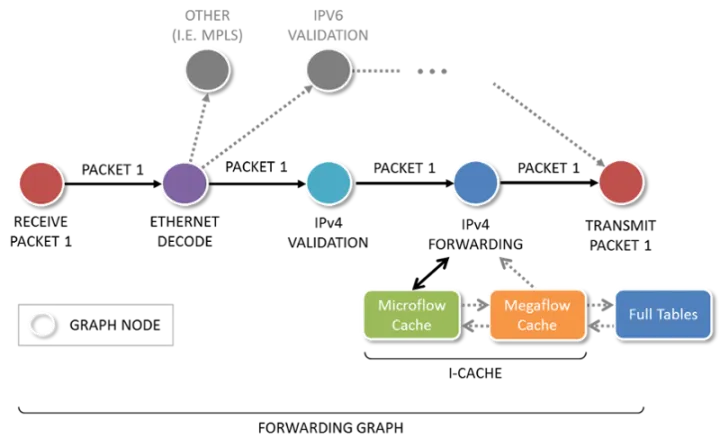
Classic scalar processing of an IPv4 packet
矢量报文处理:把一批底层硬件队列Rx ring收到的一组包,组成一个Packet Vector,借助于报文处理图(Packet Processing graph)来实现处理流程。
矢量报文处理利用了数据报文流时间局限性的特点,将一批报文分为一组,如果cache命中,则这一批报文都命中;否则这一批报文都未命中。未命中时,使用矢量报文中的第一个数据包来加热高速缓存,然后可以针对矢量报文中后续数据包重复执行缓存中所得到的指令,从而在整个报文分组中分摊一个报文的高速缓存未命中时间。
矢量报文报文处理有如下优点:
- 修复了I-cache抖动的问题。
- 矢量报文进行预提取缓解了读时延问题。
-
原文链接:https://zhuanlan.zhihu.com/p/40049446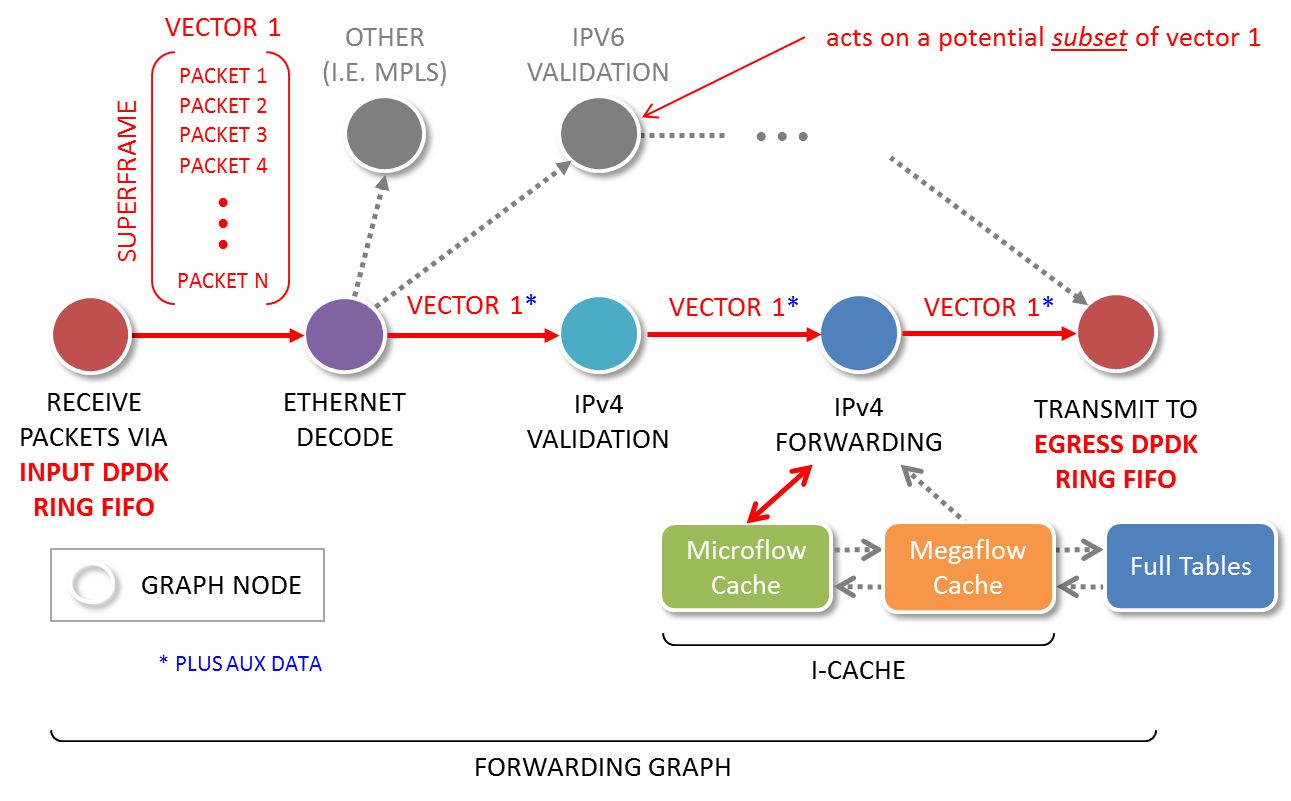
-
相关阅读:
Fucoidan-PLGA 岩藻多糖-聚乳酸-羟基乙酸共聚物 PLGA-PEG-Fucoidan
Xilinx 7系列 FPGA硬件知识系列(八)——Xilinx FPGA的复位
用 Python 写的摸鱼监控进程,千万别让老板知道
移动测试Appium安装
使用 PyTorch FSDP 微调 Llama 2 70B
SpringBoot_11_整合MyBatis
计算机网络 | 第三章 数据链路层 | 王道考研自用笔记
c语言系统编程十四:Linux进程间的同步与互斥
基于JAVA社区智能化管理计算机毕业设计源码+数据库+lw文档+系统+部署
极智AI | 讲解 TensoRT Activation 算子
- 原文地址:https://blog.csdn.net/lingshengxiyou/article/details/127805487