-
LeetCode链表练习(中)
前言
上篇博客介绍了部分力扣经典链表题,本文还是继续接着介绍链表相关练习,只有多写多练才能熟练运用知识。
1.剑指 Offer 25. 合并两个排序的链表
1.题目分析
题目链接直接点击
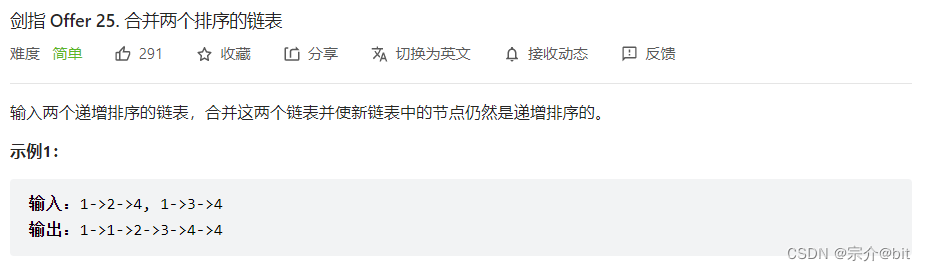
这道题我们简单分析一下,我们可以像处理移除链表元素那样尾插节点组成一条新链表,将链表每个节点挨个比较,将val较小的节点拿下来尾插即可。当其中某个链表的节点已经全部拿下来了,直接将另一个链表的后续节点和这个链表的尾部相连起来即可。这样就组成了一条好序的新链表。
2.代码示例
尾插法
struct ListNode* mergeTwoLists (struct ListNode* l1,struct ListNode* l2) { struct ListNode* tail= (struct ListNode*) malloc(sizeof(struct ListNode)); //尾节点 struct ListNode* guard=tail; guard->next=NULL;//哨兵位 while(l1&&l2) { if(l1->val<l2->val) { tail->next=l1; tail=l1; l1=l1->next; } else { tail->next=l2; tail=l2; l2=l2->next; } } if(l1) { tail->next=l1; } if(l2) { tail->next=l2; } struct ListNode* new_head=guard->next; free(guard); return new_head; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
先前的博客种提到了如果需要用到尾插的处理方式可以适当用哨兵位尾插处理。我们如果不带哨兵位在处理节点为空时,就得判断两次,链表1处理一次,链表2处理一次,因为你不知道两个链表的的头节点谁大谁小。这样显得稍微麻烦了一点,如果带了哨兵位就不用判断,直接尾插节点即可。遍历完后直接将非空链表和新链表的尾节点相连,如果两个链表都是空,返回是也是空,符合情理。
2.回文链表
1.题目分析
题目链接直接点击

这道题介绍两种做法。第一种我们将链表每个节点的val值按顺序保存到数组中,在将链表反转,将反转之后的链表每个节点val和数组中的val进行比对判断即可。反转链表之前的博客就讲解了处理方式,头插处理。
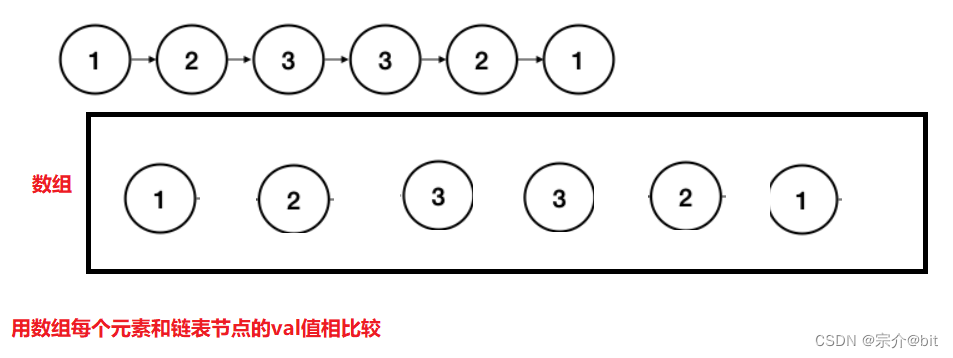
第二种方法:我们之前做过找中间节点的题,现在我们找到这个链表的中间节点,从中间节点开始将后续链表节点拿下头插来组成一条新链表,然后在和原链表相比较。等于是后半部分逆序和前半部分比较。
2.代码示例
利用数组存储val值
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ bool isPalindrome(struct ListNode* head){ struct ListNode* list=NULL;//头插 struct ListNode*cur=head; int arr[100000];//保存原链表的val int i=0; while(cur) { arr[i]= cur->val; i++; cur=cur->next; } cur=head; while(cur)//头插 { struct ListNode*tem=cur->next; cur->next=list; list=cur; cur=tem; } int j=0; while(list&&i) { if(list->val!=arr[j]) { return false; } list=list->next; j++; i--; } return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
因为题目给了节点的个数0到100000,所以数组大小就定的是100000
快慢指针处理
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ bool isPalindrome(struct ListNode* head){ struct ListNode* fast=head; struct ListNode* slow=head; while(fast&&fast->next) { slow=slow->next; fast=fast->next->next; } struct ListNode* mid=slow; struct ListNode*list =NULL; while(mid) { struct ListNode* tem=mid->next; mid->next=list; list=mid; mid=tem; } struct ListNode* newhead=head; while(list) { if(newhead->val!=list->val) { return false; } newhead=newhead->next; list=list->next; } return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
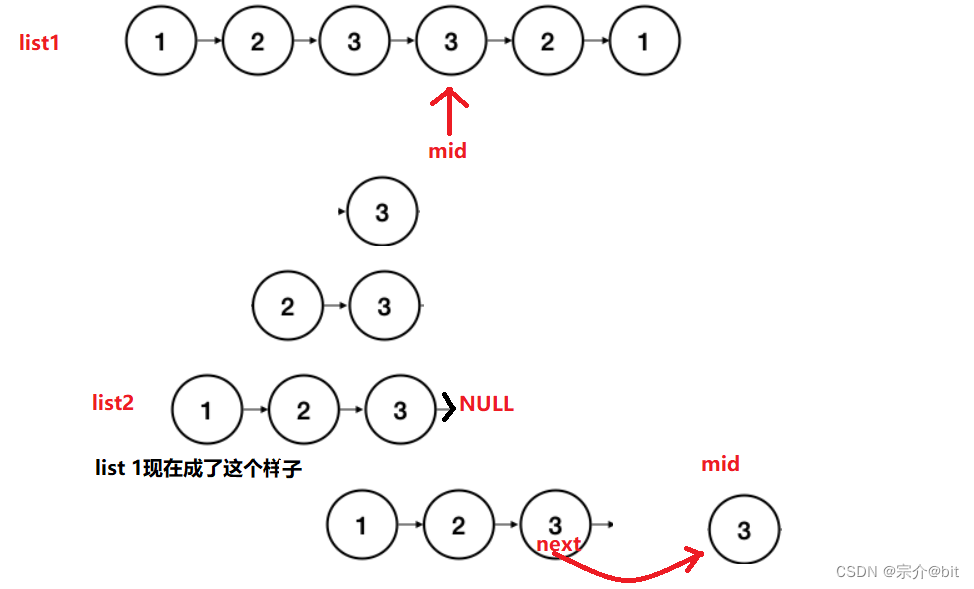
上面画图分析只是节点数是刚好是偶数,可以分一半,那如果是奇数呢?画图分析一下。
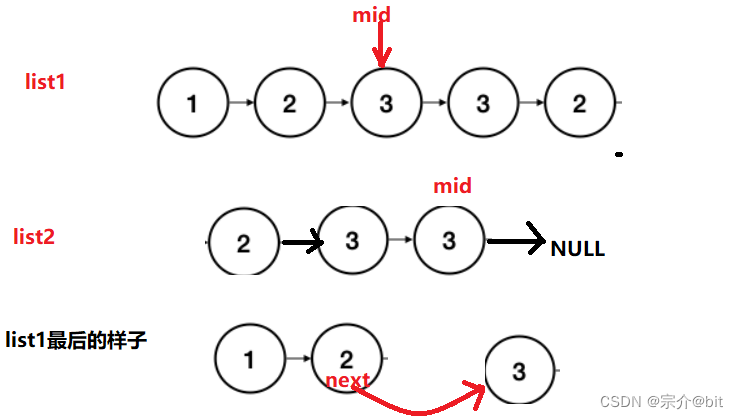
我们看到不管偶数节点还是奇数节点,旧链表中的中间节点前一个节点的next指向是始终都没有改变的,所以在与新链表比较的时候,遍历完新链表即可。在找中间节点的有个小细节就是快指针走的比较快,所以while循环里写成(fast&&fast->next)写成fast->next&&fast会引发程序报错,但是在牛客里就不会这样,细节注意一下就好了。
3.剑指 Offer 52. 两个链表的第一个公共节点
1.题目分析
题目链接直接点击
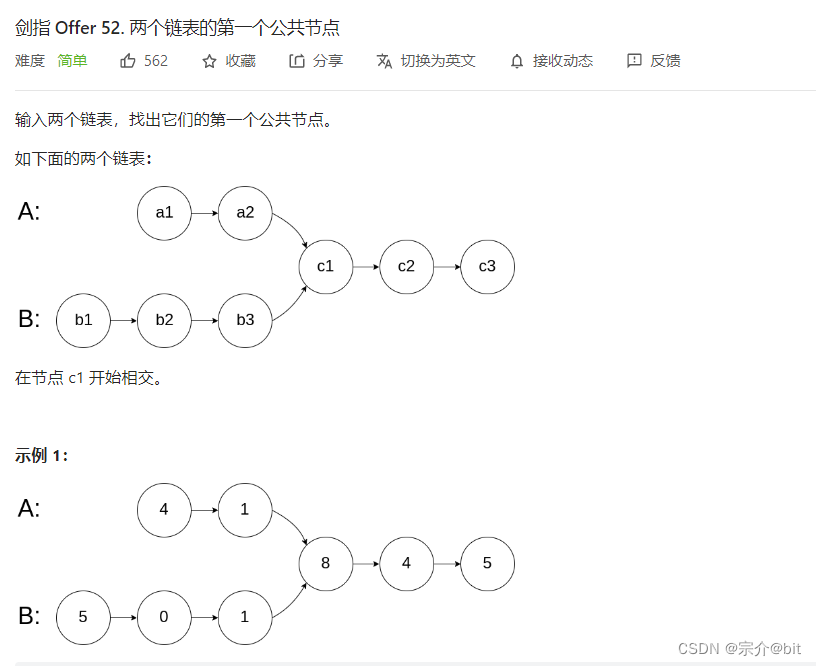
这道题也介绍两种做法:第一种就是暴力求解,用其中的一个链表的每个节点去挨个比较另一个链表的每个节点,挨个遍历寻找。这种方法时间复杂度较高了,不太可取。
第二种方法:之所以两个链表不能同时遍历比较,是因为两个链表不能确保是一样长的,我们可以采取之前快慢指针的思路,先求出两个链表的节点个数差值,让较长的链表先遍历,遍历次数就是差值数,然后两个链表再一起遍历比较。就是相当于让两个链表处再同一起跑线。
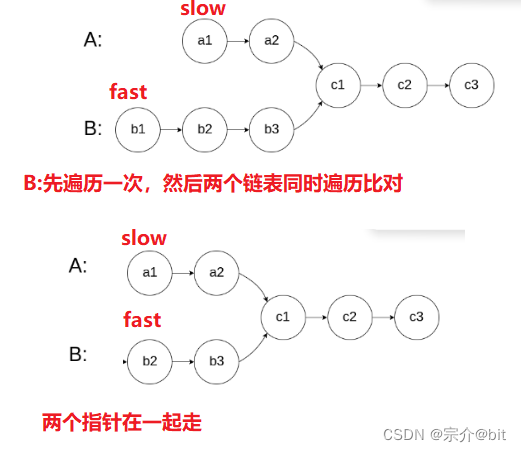
2.代码示例
暴力求解
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { struct ListNode* list1=headA; while(list1) { struct ListNode* list2=headB; while(list2) { if(list1==list2) { return list2; } list2=list2->next; } list1=list1->next; } return NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
因为是找节点直接比对节点即可
双指针解法
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { struct ListNode* curA=headA; int lenA=0; int lenB=0; while(curA) { ++lenA; curA=curA->next; } struct ListNode*curB=headB; while(curB) { ++lenB; curB=curB->next; } if(curB!=curA) { return NULL; } int gap=abs(lenA-lenB); struct ListNode* longlist=headA; struct ListNode* shortlist=headB; if(lenA<lenB) { longlist=headB; shortlist=headA; } while(gap--) { longlist=longlist->next; } while(longlist!=shortlist) { longlist=longlist->next; shortlist=shortlist->next; } return longlist; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
因为两个链表都是单链表,如果两个链表有公共节点,那就说明两个链表最后的尾节点一定是相同的,每个节点的next都只有唯一的指向。取两个链表节点个数差值的绝对值当作快指针先走的步数。在不知道两个链表哪个长时,先假设某个链表长,如果不是在交换即可。这样就不用写两次判断了,最后挨个比对即可。
4.1290. 二进制链表转整数
1.题目分析
题目链接直接点击
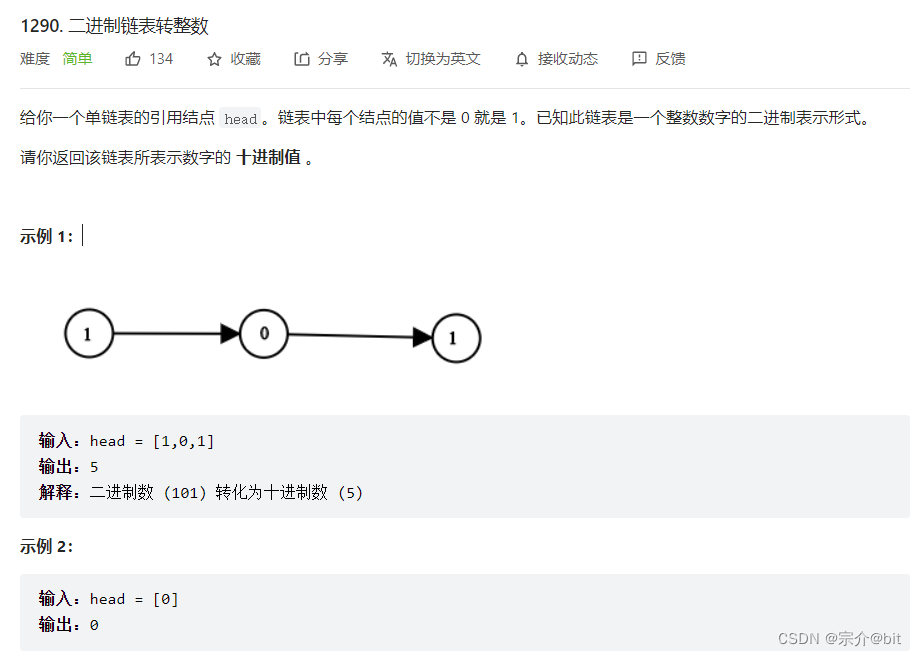
这道题的解法也很多,我介绍一种解法:我们将整条链表反转成一条新链表,在将每个节点的val按照2进制数转10进制的方法,依次将节点val值累加即可。原来的链表第一个节点是最高位,反转处理后从低位开始挨个处理节点val值。累加最终结果就是转化的10进制数。
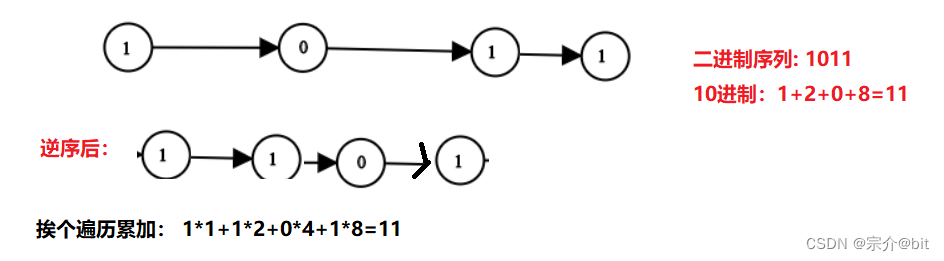
2.代码示例
逆序累加
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ int getDecimalValue(struct ListNode* head){ struct ListNode* cur=head; struct ListNode* list=NULL; while(cur) { struct ListNode* tem=cur->next; cur->next=list; list=cur; cur=tem; } int sum=0; int n=0; while(list) { int ret=list->val; sum+=(ret*pow(2,n)); n++; list=list->next; } return sum; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
逆序链表常规做法就是头插处理
5.83. 删除排序链表中的重复元素
1.题目分析
题目链接直接点击
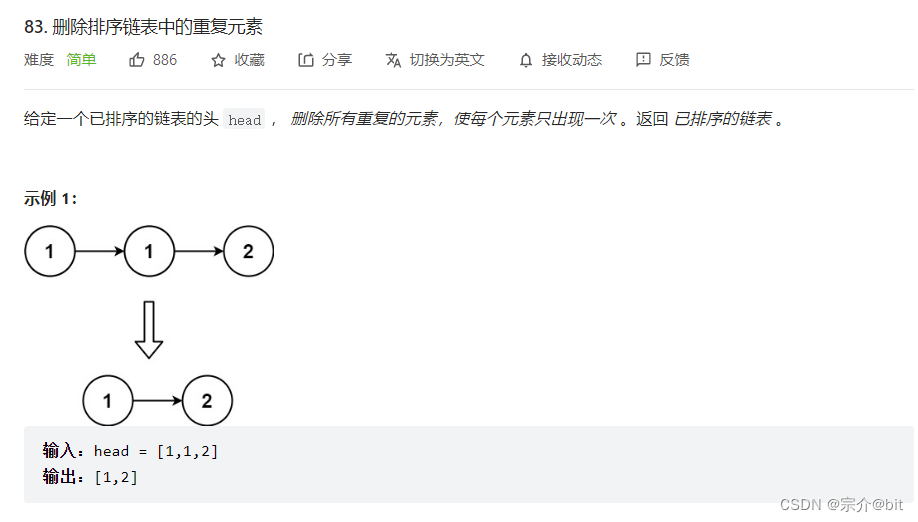
这道题和之前讲过的一道移除数组中重复元素的题很像。那道题是用两个变量来表示数组下标一前一后移动遍历。其实本质也是双指针思路,这道题也可以用相似的处理方式。一个指针在前一个指针在后挨个遍历比对即可。如果后一个指针指向的节点的val和前一个指针指向的节点的val不相等,就让后一个节点的next指向前一个节点,然后两个指针同时往前走,如果相等,前一个指针向前遍历,后一个指针不移动。直到前一个指针遍历完整个链表结束遍历。
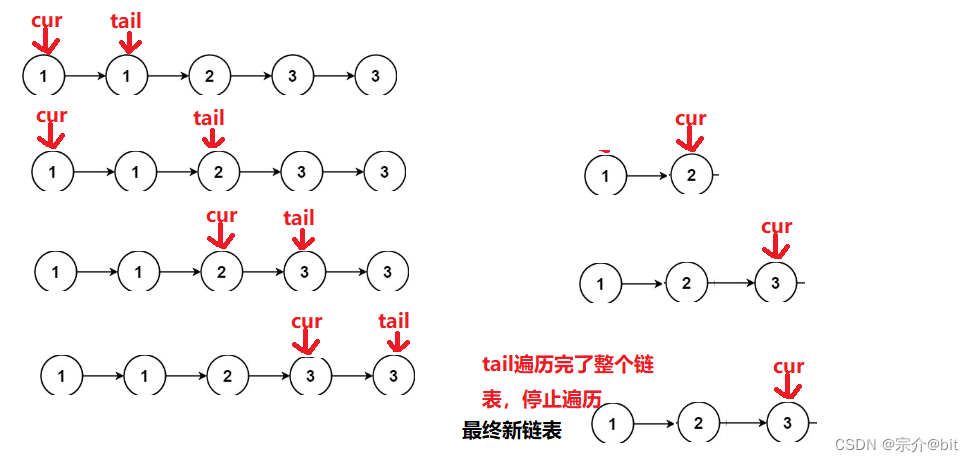
2.代码示例
双指针解法
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ struct ListNode* deleteDuplicates(struct ListNode* head){ if(head==NULL) { return NULL; } struct ListNode* ptail=head->next; struct ListNode* cur=head; while(ptail) { if(cur->val!=ptail->val) { cur->next=ptail; cur=ptail; ptail=ptail->next; } else { struct ListNode* tem=ptail->next; free(ptail); ptail=tem; } } cur->next=NULL; return head; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这道题还有个细节就是,当最后一个重复元素的节点被移除后,此时新链表的尾节点的next的指向可能不是空,可能是被删除的节点,这就需要在循环遍历结束后,手动将新链表的尾节点手动置为空,也就是将cur的next置为空。
6.总结
- 1.本文主要接着介绍部分链表题,其实我们看有些题都是同一种类型或者处理方式都是相同的,知识都是相通的,需要灵活应用。
- 2.只有多做题才能得心应手,同时在初学链表做题时一定要多画图理清节点之间的关系。
- 3.以上内容如有错误,欢迎指正!
-
相关阅读:
【嵌入式数据库之sqlite3】
说一下JVM创建对象的流程?
基于javaweb+mysql的教务选课管理系统(管理员、教师、学生)
上周热点回顾(6.10-6.16)
Hana SQL Format 的希望
Windows系统安装
第三章 内存管理 六、基本分页存储管理
基于Python对豆瓣电影数据爬虫的设计与实现
RK3568 CAN驱动更新说明
C#面:请解释ASP.NET中的web页面与其隐藏类之间的关系
- 原文地址:https://blog.csdn.net/m0_61894055/article/details/127795588
