-
分布式追踪与监控:Skywalking
1.APM介绍
APM(Application Performance Management)应用性能管理,通过各种探针采集并上报数据,收集关键指标,同时搭配数据展示以实现对应用程序性能管理和故障管理的系统化解决方案。
目前主要的一些 APM 工具有: Cat、Zipkin、Pinpoint、SkyWalking,这里主要介绍 SkyWalking ,它是一款优秀的国产 APM 工具,包括了分布式追踪、性能指标分析、应用和服务依赖分析等。
Zabbix、Premetheus、open-falcon等监控系统主要关注服务器硬件指标与系统服务运行状态等,而APM系统则更重视程序内部执行过程指标和服务之间链路调用情况的监控,APM更有利于深入代码找到请求响应“慢”的根本问题,与Zabbix之类的监控是互补关系。
像SpringCloud提供zipkin+seleuth链路追踪解决方案只能追踪到服务请求到路由到微服务模块之间的链路,当涉及到分布式缓存,数据库时,则无法显示其追踪的链路。
2.分布式链路追踪
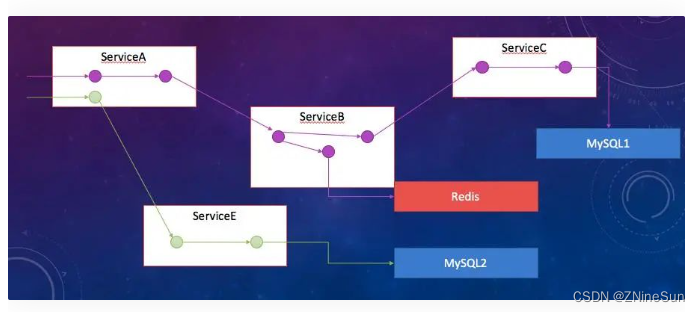
下图是常见的微服务的框架,4个实例,2个MySQL、1个Redis。
实际上它有两次完全不同的请求进来:有一次的一个请求会访问 Redis,再去访问 MySQL;
另外一个可能走到另外的服务上,然后直接去 MySQL。
整个分布式追踪的目的是什么?
是为了让我们最终在页面上、UI上、和数据上能够复现这个过程。
我们要拿到整个完整的链路,包括精确的响应时间,访问的方法、访问的 circle,访问的 Redis 的 key等,这些是我们在做分布式追踪的时候需要展现的一个完整的信息。
3.Apache Skywalking(Incubator)简介
分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。
Apache Skywalking(Incubator)专门为微服务架构和云原生架构系统而设计并且支持分布式链路追踪的APM系统。
Apache Skywalking(Incubator)通过加载探针-非侵入式的方式收集应用调用链路信息,并对采集的调用链路信息进行分析,生成应用间关系和服务间关系以及服务指标。
Apache Skywalking (Incubating)目前支持多种语言,其中包括Java,.Net Core,Node.js和Go语言。另外社区还发展出了一个叫OpenTracing的组织,旨在推进调用链监控的一些规范和标准工作。
Skywalking支持从6个可视化维度剖析分布式系统的运行情况。
- 总览视图(Global view)是应用和组件的全局视图,其中包括组件和应用数量,应用的告警波动,慢服务列表以及应用吞吐量;
- 拓扑图(topology view)从应用依赖关系出发,展现整个应用的拓扑关系;
- 应用视图从单个应用的角度,展现应用的上下游关系,TopN的服务和服务器,JVM的相关信息以及对应的主机信息。
- 服务视图关注单个服务入口的运行情况以及此服务的上下游依赖关系,依赖度,帮助用户针对单个服务的优化和监控;
- 追踪(trace)展现了调用的单次请求经过的所有埋点以及每个埋点的执行时长;
- 告警视图(alarm)根据配置阈值针对应用、服务器、服务进行实时告警。
4.SkyWalking 原理架构图
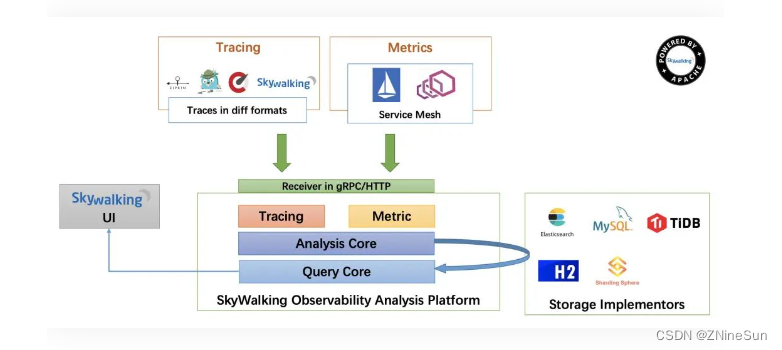
5.SkyWalking 核心模块
SkyWalking采用组件式开发,易于扩展,主要组件作用如下:
- Skywalking Agent(探针):链路数据采集tracing(调用链数据)和metric(指标)信息并上报,上报通过HTTP或者gRPC方式发送数据到Skywalking Collector。
- Skywalking Collector(平台后端) :链路数据收集器,对agent传过来的tracing和metric数据进行整合分析通过Analysis Core模块处理并落入相关的数据存储中,同时会通过Query Core模块进行二次统计和监控告警。
- Storage(存储):Skywalking的存储,支持以ElasticSearch、Mysql、TiDB、H2等主流存储作为存储介质进行数据存储,H2仅作为临时演示单机用。
- SkyWalking UI(用户界面):Web可视化平台,用来展示落地的数据,目前官方采纳了RocketBot作为SkyWalking的主UI。
本文接下来通过Docker容器安装Skywalking,并示例整合apisix网关、Spring Boot微服务项目进行APM(Application Performance Management)应用性能管理,检测从接口网关到微服务实例、再到数据库、缓存等存储层之间的链路追踪。
6.Skywalking Agent安装
下载agent包,原地址可能需要vpn才能下载
解压下载后的文件,解压后的目录结构如下:
接下来我们需要部署探针。部署探针的方式有很多:
- IDEA 部署探针
- Java 命令行启动方式
- 脚本启动
我下面演示一下Java命令行的方式进行启动
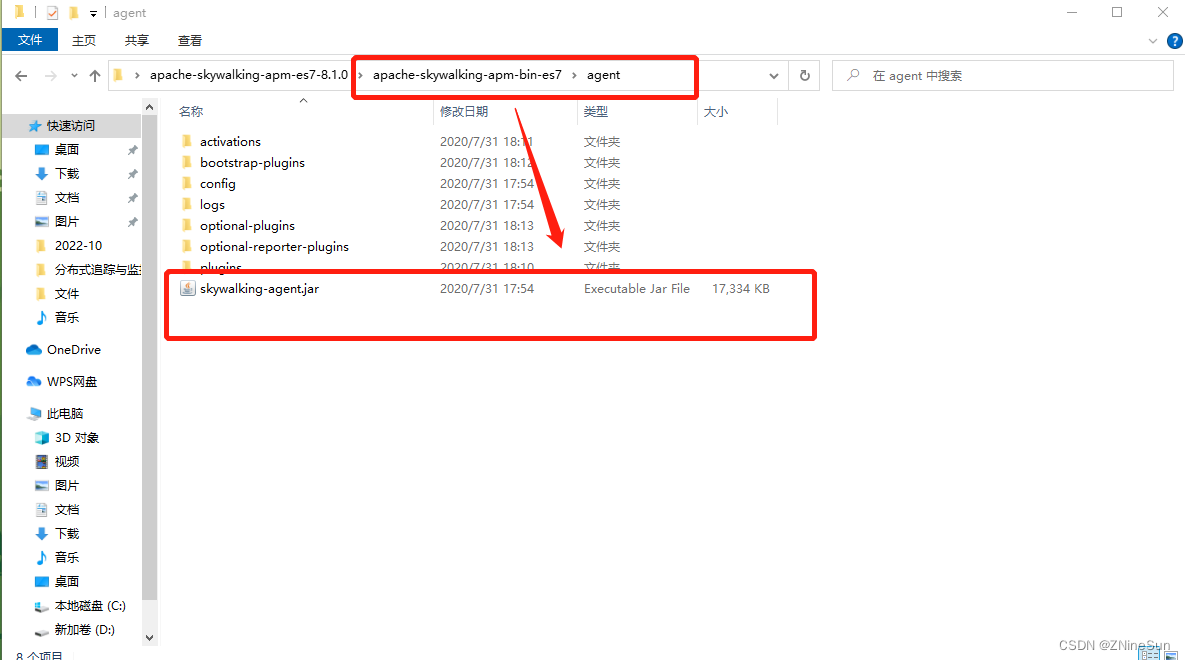
首先我们创建一个SpringBoot的web项目,随便写一个接口,然后打包成jar包,在cmd下运行以下指令:java -javaagent:C:\Users\ADMIN\Desktop\apache-skywalking-apm-es7-8.1.0\apache-skywalking-apm-bin-es7\agent\skywalking -agent.jar=-Dskywalking.agent.service_name=test-service,-Dskywalking.collector.backend_service=192.168.1.2:11800 -jar test.jar- 1
-
第一个jar包是我们的agent
-
第二个jar包则是我们项目打包之后的jar包
-
service_name:为要注册到skywalking的服务名称,会在skywalking的ui界面上显示该服务的名称
-
collector.backend_service为skywalking grpc注册地址,如果是本地启动的可以改为localhost:11800
在执行上面的命令之前,我们需要先启动skywalking,启动方式也很简单,双击stat.bat即可
如果是linux系统下,直接执行./startup.sh即可
执行完以上操作后,就可以运行我们上面的java -javaagent命令了。
我们看一下效果:
因为我就一个服务,只是为了给大家演示一下,如果是分布式的项目架构,则需要每个微服务模块都加入探针,才能构成完整的链路。
7.Skywalking UI 管理后台介绍
本章可以作为手册使用,等后面自己需要哪些功能,可以来此处对照使用
7.1 首页
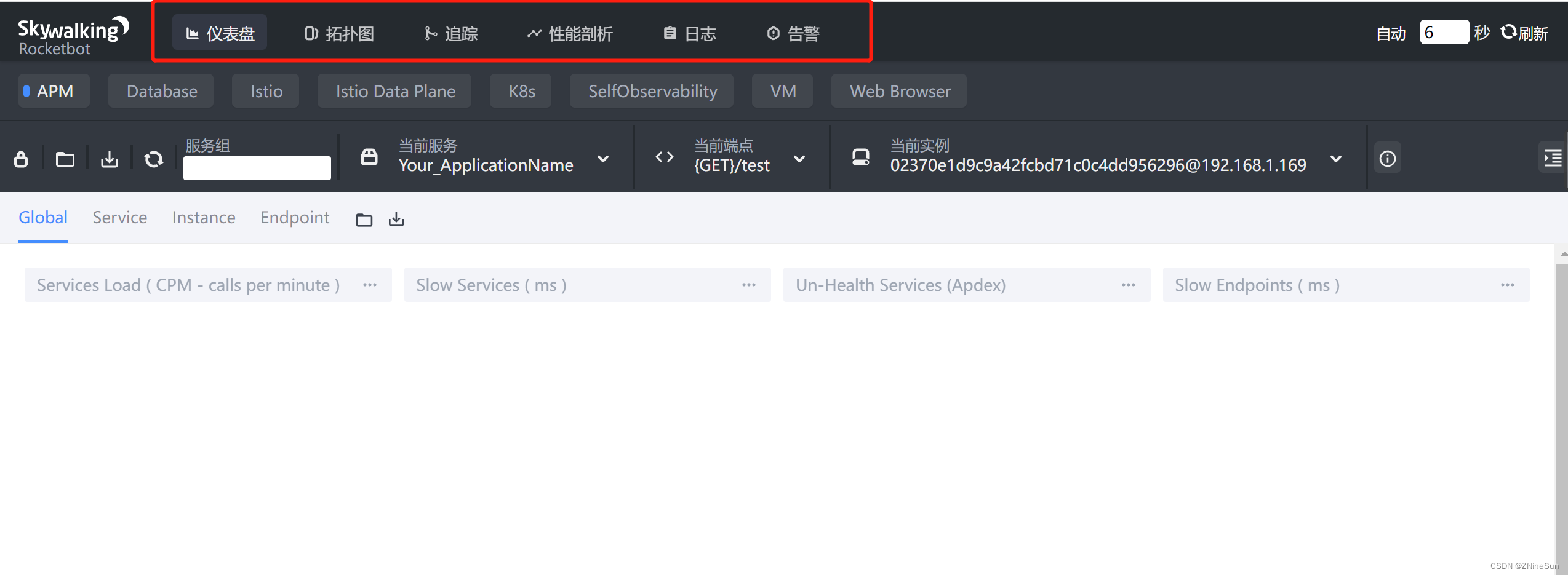
- 仪表盘:查看被监控服务的运行状态
- 拓扑图:以拓扑图的方式展现服务直接的关系,并以此为入口查看相关信息
- 追踪:以接口列表的方式展现,追踪接口内部调用过程
- 性能剖析:单独端点进行采样分析,并可查看堆栈信息
- 告警:触发告警的告警列表,包括实例,请求超时等。
- 自动刷新:自动刷新当前数据内容
7.2 仪表盘

查看全局服务基本性能指标
- 第一栏:不同内容主题的监控面板,应用/数据库/容器等
- 第二栏:操作,包括编辑/导出当前数据/导入展示数据/不同服务端点筛选展示
- 第三栏:不同纬度展示,服务/实例/端点
7.2.1 参数说明
Global全局维度
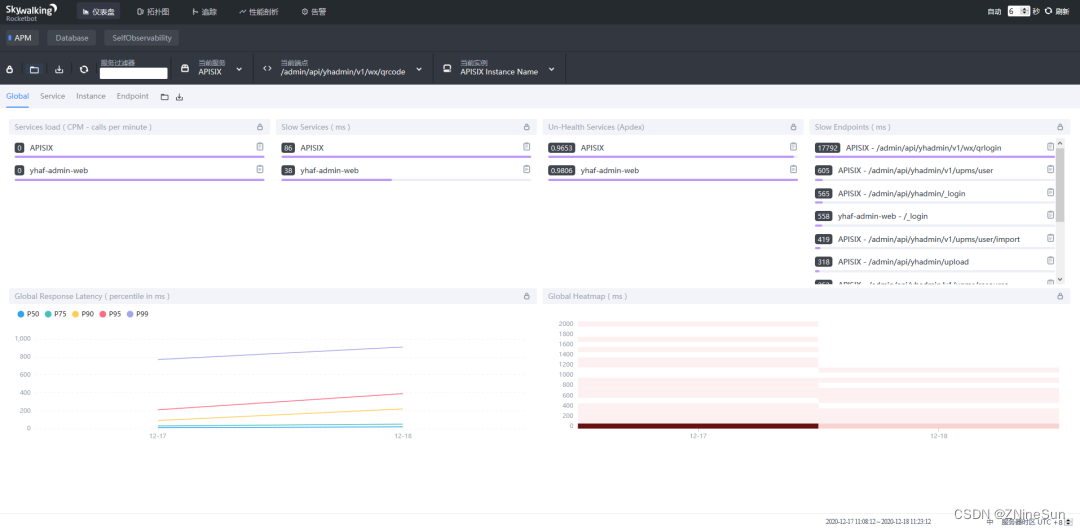
- 第一栏:Global、Server、Instance、Endpoint不同展示面板,可以调整内部内容
- Services load:服务每分钟请求数
- Slow Services:慢响应服务,单位ms
- Un-Health services(Apdex):Apdex性能指标,1为满分。
- Global Response Latency:百分比响应延时,不同百分比的延时时间,单位ms
- Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度
- 底部栏:展示数据的时间区间,点击可以调整。
Service实例维度
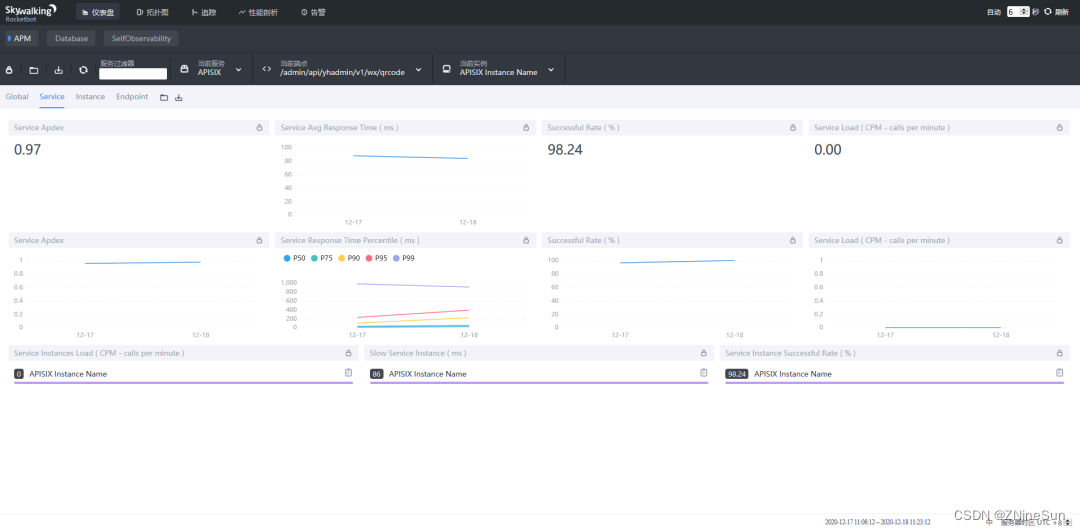
- Service Apdex(数字):当前服务的评分
- Service Apdex(折线图):不同时间的Apdex评分
- Successful Rate(数字):请求成功率
- Successful Rate(折线图):不同时间的请求成功率
- Servce Load(数字):每分钟请求数
- Servce Load(折线图):不同时间的每分钟请求数
- Service Avg Response Times:平均响应延时,单位ms
- Global Response Time Percentile:百分比响应延时
- Servce Instances Load:每个服务实例的每分钟请求数
- Show Service Instance:每个服务实例的最大延时
- Service Instance Successful Rate:每个服务实例的请求成功率
Instance实例维度
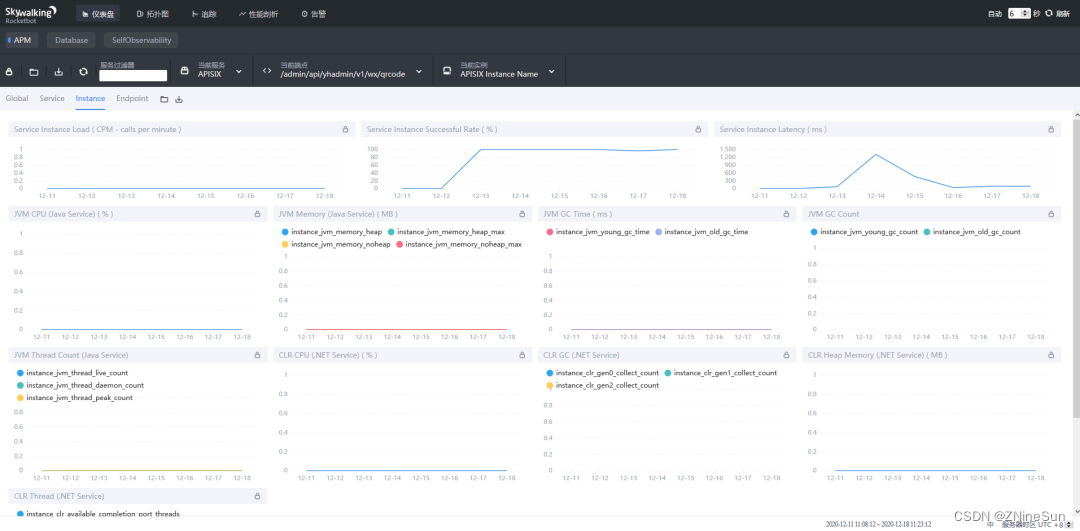
- Service Instance Load:当前实例的每分钟请求数
- Service Instance Successful Rate:当前实例的请求成功率
- Service Instance Latency:当前实例的响应延时
- JVM CPU:jvm占用CPU的百分比
- JVM Memory(Java Service):JVM内存占用大小,单位MB
- JVM GC Time:JVM垃圾回收时间,包含YGC和OGC
- JVM GC Count:JVM垃圾回收次数,包含YGC和OGC
- JVM Thread Count(Java Service):JVM生成的线程数
- CLR XX:类似JVM虚拟机参数
Endpoint端点维度
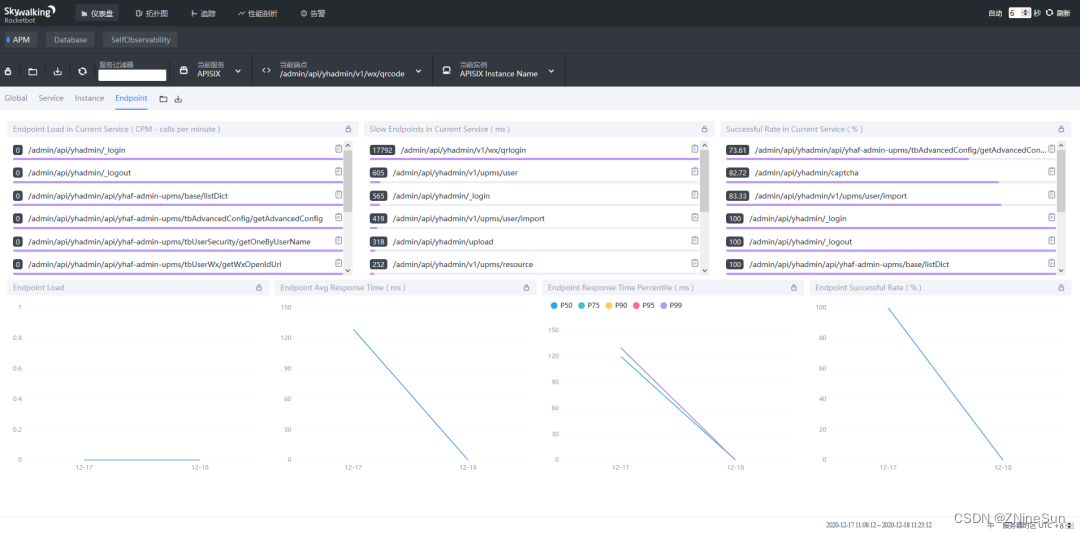
- Endpoint Load in Current Service:每个端点的每分钟请求数
- low Endpoints in Current Service:每个端点的最慢请求时间,单位ms
- Successful Rate in Current Service:每个端点的请求成功率
- Endpoint Load:当前端点每个时间段的请求数据
- Endpoint Avg Response Time:当前端点每个时间段的请求行响应时间
- Endpoint Response Time Percentile:当前端点每个时间段的响应时间占比
- Endpoint Successful Rate:当前端点每个时间段的请求成功率
拓扑图
SkyWalking能够根据获取的数据自动绘制服务之间的调用关系图,并能识别常见的服务显示在图标上。每条连线的颜色反应了服务之间的调用延迟情况,可以非常直观的看到服务与服务之间的调用状态,连线中间的点能点击,可显示两个服务之间链路的平均响应时间、吞吐率以及SLA等信息。
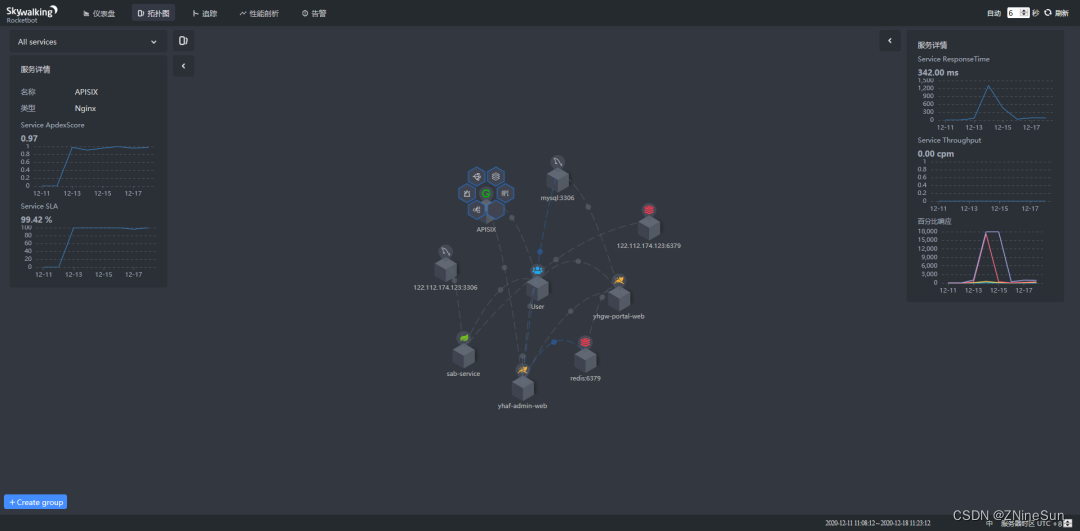
- 1:选择不同的服务关联拓扑
- 2:查看单个服务相关内容
- 3:服务间连接情况
- 4:分组展示服务拓扑
追踪
显示请求的响应内部执行情况,一个完整的请求都经过了哪些服务、执行了哪些代码方法、每个方法的执行时间、执行状态等详细信息,快速定位代码问题。
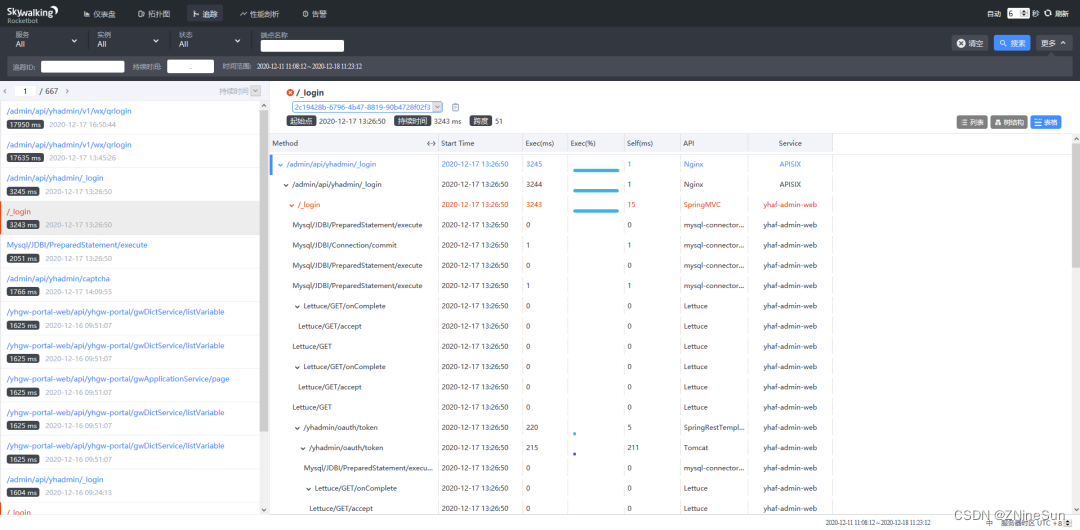
可通过选择服务、实例、状态和端点名称来搜索调用链路,
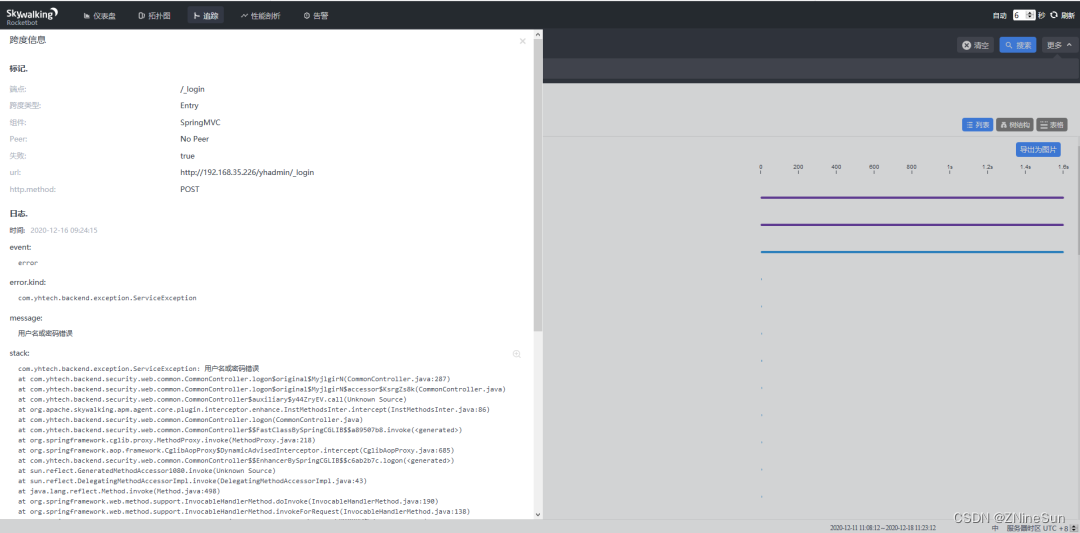
可以点击标记红色的端点,查看异常信息
性能剖析
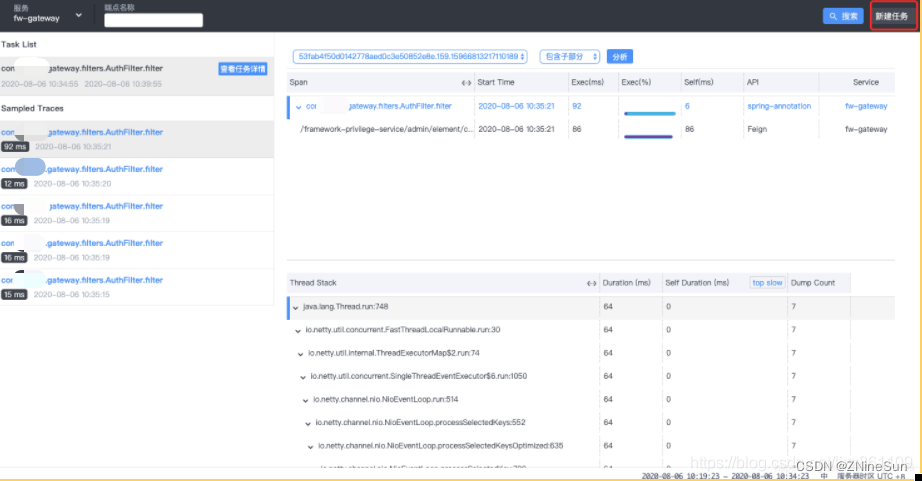
新建需要分析的端点,在左侧列表显示任务及对应的采样请求,右侧显示端点链路及每个端点的堆栈信息。
告警
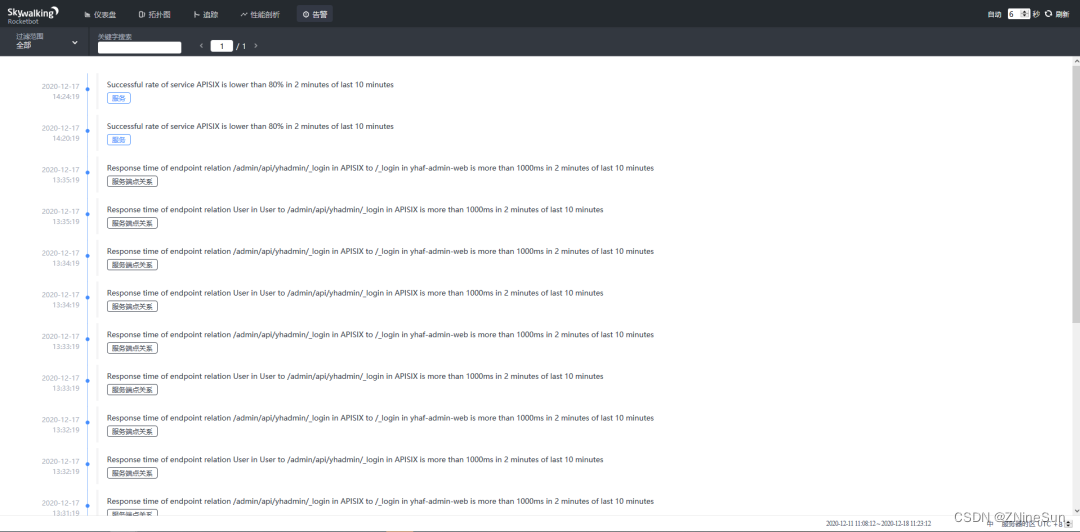
不同维度告警列表,可分为服务、端点和实例。
-
相关阅读:
MySQL Explain性能调优详解
数据治理:数据治理框架(第一篇)
滑动窗口:最长不含重复字符的子字符串
代码随想录第36天 | 1049. 最后一块石头的重量 II ● 494. 目标和 ● 474.一和零
day11-SpringBoot中注入Servlet&Filter&Listener
Excel VLOOKUP 使用记录
使用RabbitMQ异步执行业务
第二章第十二节:set集合
VS2015过期怎么办
前端导出Excel并下载到本地
- 原文地址:https://blog.csdn.net/zhiyikeji/article/details/127808084