-
Python爬虫
Urllib🚀
urllib库的使用
urllib.request.urlopen() 模拟浏览器向服务器发送请求 response 服务器返回的数据 字节-->字符串 解码decode 字符串-->字节 编码code read() 字节形式读取二进制 扩展:rede(5)返回前几个字节 readline 读取一行 readlines 一行一行读取 直至结束 getcode() 读取状态码 geturl() 获取url getheaders()获取headers urllib.request.urlretrieve() 请求网页 请求图片 请求视频- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
urllib基本使用
#使用urllib来获取百度首页的源码 import urllib.request #1.定义一个url 就是你要访问的地址 url='http://www.baidu.com' #2.模拟浏览器向服务器服务器发送请求 #既然请求了,就有反馈,我们用response来接收反馈数据 response=urllib.request.urlopen(url) #3.获取响应中的页面源码 #read方法 返回的是字节形式的二进制数据 #我们要将二进制的数据转换为字符串 #二进制-->字符串 解码 decode('编码的格式') content=response.read().decode('utf-8') #4.打印数据 print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
一个类型和六个方法
import urllib.request url='http://www.baidu.com' #模拟浏览器向服务器发送请求 response=urllib.request.urlopen(url) #一个类型和六个方法 #response是HTTPResponse的类型 print(type(response)) #按照一个字节一个字节的去读 content=response.read() #返回多少个字节 content=response.read(5) #读取一行 content=response.readline() #一行一行的去读,直到读完 content=response.readlines() #返回状态码 如果是200,就证明我们的逻辑没有错 print(response.getcode()) #返回的url地址 print(response.geturl()) #获取的是一个状态信息 print(response.getheaders()) #一个类型HTTPResponse #六个方法 read、readline、getcode、geturl、getheaders- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
urllib下载
import urllib.request #下载网页 url_page='http://www.baidu.com' #url代表的是下载的路径 filename文件的名字 #在python中 可以变量的名字 也可以直接写值 urllib.request.urlretrieve(url_page,'baidu.html') #下载图片 url_img='图片连接' urllib.request.urlretrieve(url_img,'guimiezhiren.png') #下载 url_video='视频地址' urllib.request.urlretrieve(url_video,'shipin.mp4')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
请求对象定制
UA介绍:User Agent中文为用户代理,简称UA,它是一个特殊字符串头,使得服务器能够识别用户使用的操作系统及版本、cpu类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
语法:request=urllib.request.Request()
import urllib.request url='https://www.baidu.com' #url的组成 #协议:http/https #主机:www.baidu.com #端口号:http-80、https-443、mysql-3306、oracle-6379 #路径 #参数 #锚点 #https://www.baidu.com/s?wd=周杰伦 #https www.baidu.com 443 s wd=周杰伦 # #协议 主机 端口号 路径 参数 锚点 headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } #因为urlopen方法中不能存储字典,所以headers不能传递进去 #请求对象的定制 request=urllib.request.Request(url=url,headers=headers)#加上变量的名字,因为Request方法中有多个变量 response=urllib.request.urlopen(request) content=response.read().decode() print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
编解码
get请求方式:urllib.parse.quote( )
#https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 #需求 获取https://www.baidu.com/s?wd=周杰伦的网页源码 import urllib.request import urllib.parse url='https://www.baidu.com/s?wd=' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } #将周杰伦三个字变成unicode编码格式,我们需要依赖于urllib.parse name=urllib.parse.quote('周杰伦') url=url+name request=urllib.request.Request(url=url,headers=headers)#加上变量的名字,因为Request方法中有多个变量 #模拟浏览器向服务器发送请求 response=urllib.request.urlopen(request) content=response.read().decode() print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
get请求方式:urllib.parse.urlencode( )
#urlencode应用场景:多个参数的时候 #https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81 #https://www.baidu.com/s?wd=周杰伦&sex=男&location=中国台湾省 import urllib.request import urllib.parse base_url='https://www.baidu.com/s?' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } data={ 'wd':'周杰伦', 'sex':'男', 'location':'中国台湾省' } new_data=urllib.parse.urlencode(data) name=urllib.parse.quote('周杰伦') #请求资源路径 url=base_url+new_data request=urllib.request.Request(url=url,headers=headers) #模拟浏览器向服务器发送请求 response=urllib.request.urlopen(request) content=response.read().decode() print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
post请求方式(百度翻译)
import urllib.request url='https://fanyi.baidu.com/sug' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } data={ 'kw' : 'spider' } #post请求必须进行编码 data=urllib.parse.urlencode(data).encode('utf-8') #post的请求参数是不会拼接在url的后面的 request=urllib.request.Request(url=url, data=data, headers=headers) #模拟浏览器向服务器发送请求 response= urllib.request.urlopen(request) #获取响应的数据 content=response.read().decode('utf-8') import json obj=json.loads(content) print(obj)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
结果:{'errno': 0, 'data': [{'k': 'spider', 'v': 'n. 蜘蛛; 星形轮,十字叉; 带柄三脚平底锅; 三脚架'}, {'k': 'Spider', 'v': '[电影]蜘蛛'}, {'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {'k': 'spiders', 'v': 'n. 蜘蛛( spider的名词复数 )'}, {'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般细长的; 象蜘蛛网的,十分精致的'}]}- 1
#详细翻译 import urllib.request import urllib.parse #https://fanyi.baidu.com/v2transapi?from=en&to=zh url='https://fanyi.baidu.com/v2transapi?from=en&to=zh' headers={ 'Accept': '*/*', # 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Acs-Token': '1667977391114_1667989371070_KvQ+dbkRvZAAMQyW7YddNOTbB+KTlgwFzV5KKHukMve3nmKXmz3t+xuOr9lu9SEve1CFlg7V3wwVMPyYFYshZ3jHh/SlFWcYUevs3Vpq586hiQUSFYvvbE5jIIGExKMTOX6X+CFtBEgGcBi51pOAnhHzH7/UPj+hq3ATZkAgfOSKJPZa2ivFzm7prFUJoh5978lD4DlvqAtZfC9WPL/g+TO9xDYypuF4mX6q7e5nXArKih+ribVNgc6A8zAJsTsfQ5RCm4Ja9RTs18pVqKGMbtsrOD5Sda+ovvp7XDicIVLSPIqwDzfY0JrYO/rSiKNIR2NQ0i1n1yFE07yRM/8gCA==', 'Connection': 'keep-alive', 'Content-Length': '143', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'ZFY=7j5cldRsMb4t3JcsgevsrD29mR5Sgo:BKvXcnMXOud1U:C; BIDUPSID=7F3B7FD8A05C113B0FE49766690F9F88; PSTM=1667978617; BAIDUID=7F3B7FD8A05C113BDA559C44047CC71A:FG=1; BAIDUID_BFESS=7F3B7FD8A05C113BDA559C44047CC71A:FG=1; BA_HECTOR=ak2l8001000ga42k8185ac2i1hmmlbr1e; APPGUIDE_10_0_2=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; H_PS_PSSID=36556_34813_37486_37624_37727_37663_37540_37717_37743_26350_37488; delPer=0; PSINO=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1667983821,1667989355; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1667989355; ab_sr=1.0.1_NTRmNTc0ZDc2YTQyMDdiZjkxNTIzOWFkMjQ1ZDdjYTY3YzU4YThjOGVmYjJjNmFjYjk5YmUxZDYwNWRlMDUwN2M0ODJmOWQ1NmE5ZjIwM2YzNDUzNmI5YmY4N2MxMmY3OWJhYjU5NDcyZmE0ZTQyYzAxOGM1OWQwNzhlM2M2ZmVlNTJmZTIxYzRiMTM2ODgwMDk0NTViODIyM2RhMjgyNw==', 'Host': 'fanyi.baidu.com', 'Origin: https':'//fanyi.baidu.com', 'Referer': 'https://fanyi.baidu.com/?aldtype=16047', 'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'same-origin', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', } data={ 'from':'slo', 'to':'zh', 'query':'spriderman', 'transtype':'realtime', 'simple_means_flag':'768943.1005726', 'token':'46f256e64385c952e5299a6794f0458a', 'domain':'common', } #post请求的参数 必须进行编码 并且要调用encode方法 data=urllib.parse.urlencode(data).encode('utf-8') #请求对象定制 request=urllib.request.Request(url=url, data=data, headers=headers) #模拟浏览器向服务器发送请求 response=urllib.request.urlopen(request) #获取响应的数据 content=response.read().decode('utf-8') import json obj=json.loads(content) print(obj)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
Ajax的get请求
豆瓣电影首页电影数据
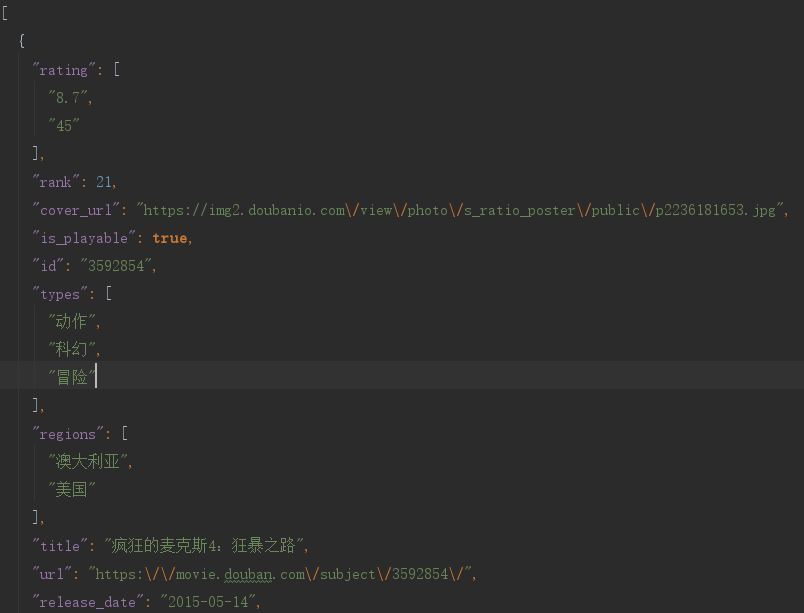
#https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20 #get请求 #获取豆瓣电影第一页的数据,并且保存起来 import urllib.request url='https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20' header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } #请求对象的定制 request=urllib.request.Request(url=url,headers=header) #获取响应的数据 response=urllib.request.urlopen(request) content=response.read().decode('utf-8') #将数据下载到本地 #open方法默认情况下使用的是gbk的编码 如果我们要保存中文 需要在open方法中指定编码格式为utf-8 fp=open('douban.json','w',encoding='utf-8') fp.write(content) with open('douban1.json','w',encoding='utf-8') as fp: fp.write(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
豆瓣电影前十页数据
#https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=& # start=0&limit=20 #https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=& # start=20&limit=20 #https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=& # start=40&limit=20 import urllib.request import urllib.parse def creat_request(page): base_url='https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&' data={ 'start':(page-1)*20, 'limit':20 } data=urllib.parse.urlencode(data) url=base_url+data headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request = urllib.request.Request(url=url, headers=headers) return request def get_content(request): # 获取响应的数据 response = urllib.request.urlopen(request) content = response.read().decode('utf-8') return content def down_load(page,content): # 将数据下载到本地 # open方法默认情况下使用的是gbk的编码 如果我们要保存中文 需要在open方法中指定编码格式为utf-8 #字符串拼接+号的两边都得是字符串 with open('douban_'+str(page)+'.json', 'w', encoding='utf-8') as fp: fp.write(content) #程序的入口 if __name__=='__main__': start_page=int(input('请输入起始的页码')) end_page=int(input('请输入结束的页码')) for page in range(start_page,end_page+1): request=creat_request(page) #获取响应的数据 content=get_content(request) #下载 down_load(page,content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53

Ajax的post请求
post请求KFC官网
#http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname #cname:郑州 #pid: #pageIndex:1 #pageSize:10 #http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname #cname:郑州 #pid: #pageIndex:2 #pageSize:10 import urllib.request import urllib.parse def creat_request(page): base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname' data={ 'cname':'郑州', 'pid':'', 'pageIndex':page, 'pageSize':10 } data=urllib.parse.urlencode(data).encode('utf-8') headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=base_url,headers=headers,data=data) return request def get_content(request): response=urllib.request.urlopen(request) content=response.read().decode('utf-8') return content def down_load(content): with open('kfc_'+str(page)+'.json','w',encoding='utf-8')as fp: fp.write(content) #程序的入口 if __name__=='__main__': start_page=int(input('请输入起始的页码')) end_page=int(input('请输入结束的页码')) for page in range(start_page,end_page+1): request=creat_request(page) #获取网页源码 content=get_content(request) #下载 down_load(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51

URLError/HTTPError
简介:1.URLError类是URLError的子类
2.导入的包urllib.error.HTTPError urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误显示。引导并告诉浏览器该页面是哪里出了问题
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果你想让你的代码更健壮,可以通过try-except进行捕获异常,异常有两类,URLError/HTTPErrorcookie登录
适用场景:数据采集的时候,需要绕过登录然后进入到某个页面
Handler处理器
🔥为什么要学习Handler?
urllib.request.urlopen(url) 不能定制请求头
urllib.request.Request(url,header,data) 可以定制请求头
Handler 定制更高级的请求头(随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)#使用handler来访问百度 import urllib.request url='http://www.baidu.com' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=url,headers=headers) #获取handler对象 handler=urllib.request.HTTPHandler() #获取opener对象 opener=urllib.request.build_opener(handler) #调用open方法 response=opener.open(request) content=response.read().decode('utf-8') print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代理服务器
🔥代理服务器的功能
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
拓展:某大学FTP(前提是该代理地址在该资源的允许范围之内),使用教育网内地址段免费代理服务器,就可以对教育网开放各类FTP上传下载,以及各类资料查询共享等服务。
3.提高访问速度
拓展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度
4.隐藏真实IP
拓展上网者也可以通过这种方法隐藏自己的IP,免受攻击🔥代码配置代理
创建Request对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求import urllib #https://www.baidu.com/s?&wd=ip url='https://www.baidu.com/s?&wd=ip' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=url,headers=headers) #模拟浏览器访问服务器 #response=urllib.request.urlopen(request) proxies={ 'http':'112.14.47.6:52024' } #获取handler对象 handler=urllib.request.ProxyHandler(proxies=proxies) #获取opener对象 opener=urllib.request.build_opener(handler) #调用open方法 response=opener.open(request) #获取响应的信息 content=response.read().decode('utf-8') print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
代理池
import urllib import random #https://www.baidu.com/s?&wd=ip url='https://www.baidu.com/s?&wd=ip' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=url,headers=headers) proxies_pool=[ {'http': '112.14.47.6:52024'}, {'http': '27.42.168.46:55481'} ] proxies=random.choice(proxies_pool) request=urllib.request.Request(url=url,headers=headers) #获取handler对象 handler=urllib.request.ProxyHandler(proxies=proxies) #获取opener对象 opener=urllib.request.build_opener(handler) #调用open方法 response=opener.open(request) #获取响应的信息 content=response.read().decode('utf-8') print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
解析🚀
XPath
🔥xpath使用:
注意:提前安装xpath插件 ctrl+shift+x打开
1.安装lxml库
pip install lxml ‐i https://pypi.douban.com/simple
2.导入lxml.etree
from lxml import etree
3.etree.parse() 解析本地文件
html_tree = etree.parse(‘XX.html’)
4.etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode(‘utf‐8’)
5.html_tree.xpath(xpath路径)🔥xpath基本语法: 1.路径查询 //:查找所有子孙节点,不考虑层级关系 / :找直接子节点 2.谓词查询 //div[@id] //div[@id="maincontent"] 3.属性查询 //@class 4.模糊查询 //div[contains(@id, "he")] //div[starts‐with(@id, "he")] 5.内容查询 //div/h1/text() 6.逻辑运算 //div[@id="head" and @class="s_down"] //title | //price- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
百度搜索中获取“百度一下”
import urllib.request url='https://www.baidu.com/' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=url,headers=headers) #模拟浏览器访问 response=urllib.request.urlopen(request) content=response.read().decode('utf-8') #解析网页源码来获取想要的数据 from lxml import etree tree=etree.HTML(content) #获取想要的数据 result=tree.xpath('//input[@id="su"]/@value') print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23


站长素材
#https://a2put.chinaz.com/slot/callback?id=s1694629161422034&fromUrl=https://sc.chinaz.com/tupian/chouxiangtupian.html #https://a2put.chinaz.com/slot/callback?id=s1694629161422034&fromUrl=https://sc.chinaz.com/tupian/chouxiangtupian_2.html import urllib.request from lxml import etree def creat_request(page): if(page==1): url='https://a2put.chinaz.com/slot/callback?id=s1694629161422034&fromUrl=https://sc.chinaz.com/tupian/chouxiangtupian.html' else: url='https://a2put.chinaz.com/slot/callback?id=s1694629161422034&fromUrl=https://sc.chinaz.com/tupian/chouxiangtupian_'+str(page)+'.html' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } request=urllib.request.Request(url=url,headers=headers) return request def get_content(request): response=urllib.request.urlopen(request) content=response.read().decode('utf-8') return content def down_load(content): tree=etree.HTML(content) name_list=tree.xpath('//div[@id="container"]//a/img/@alt') src_list = tree.xpath('//div[@id="container"]//a/img/@src') for i in range(len(name_list)): name = name_list[i] src = src_list[i] url='https:'+src urllib.request.urlretrieve(url=url,filename='./img/'+name+'.jpg') if __name__=='__main__': start_page=int(input('请输入起始页码')) end_page=int(input('请输入结束页码')) for page in range(start_page,end_page+1): #请求对象的定制 request=creat_request(page) #获取网页的源代码 content=get_content(request) #下载 down_load(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
JsonPath
json测试数据
{ "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
XPath JsonPath 结果 /store/book/author $.store.book[*].author 书点所有书的作者 //author $…author 所有的作者 /store/* $.store.* store的所有元素。所有的bookst和bicycle /store//price $.store…price store里面所有东西的price //book[3] $…book[2] 第三个书 //book[last()] $…book[(@.length-1)] 最后一本书 //book[position()< 3] . . b o o k [ 0 , 1 ] < b r / > ..book[0,1]
..book[0,1]<br/>…book[:2]前面的两本书 //book[isbn] $…book[?(@.isbn)] 过滤出所有的包含isbn的书。 //book[price<10] $…book[?(@.price<10)] 过滤出价格低于10的书 //* $…* 所有元素 import json import jsonpath obj=json.load(open('test.json','r',encoding='utf-8')) #书店的所有作者 author_list=jsonpath.jsonpath(obj,'$.store.book[*].author') #print(author_list) #store下面的所有元素 tag_list=jsonpath.jsonpath(obj,'$.store.*') #print(tag_list) #store下面的所有price price_list=jsonpath.jsonpath(obj,'$.store..price') #print(price_list) #第三个书 book=jsonpath.jsonpath(obj,'$..book[2]') #print(book) #前两本书 book2=jsonpath.jsonpath(obj,'$..book[(@.length-1)]') #print(book2) #最后一本书 book_list=jsonpath.jsonpath(obj,'$..book[0,1]') #print(book_list) #过滤出所有的包含isbn的书 #条件过滤,需要在圆括号的前面添加?号 book_list=jsonpath.jsonpath(obj,'$..book[?(@.isbn)]') #print(book_list) #那本书超过了10块钱 booklist=jsonpath.jsonpath(obj,'$..book[?(@.price<10)]') print(booklist)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
BeautifulSoup
1.BeautifulSoup简称:
bs4
2.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?
缺点:效率没有lxml的效率高 优点:接口设计人性化,使用方便节点定位 1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span') 节点信息 (1).获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text()【推荐】 (2).节点的属性 tag.name 获取标签名 eg:tag = find('li) print(tag.name) tag.attrs将属性值作为一个字典返回 (3).获取节点属性 obj.attrs.get('title')【常用】 obj.get('title') obj['title']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
Selenium🚀
Requests🚀
🔥response的属性以及类型 类型 :models.Response r.text : 获取网站源码 r.encoding :访问或定制编码方式 r.url :获取请求的url r.content :响应的字节类型 r.status_code :响应的状态码 r.headers :响应的头信息- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
import requests url='http://www.baidu.com' response=requests.get(url=url) #一个类型六个属性 #response类型 #print(type(response)) ##设置响应的编码格式 response.encoding='utf-8' #以字符串形式来返回网页的源码 #print(response.text) #返回一个url地址 print(response.url) #返回一个二进制的数据 print(response.content) #返回响应的状态码 print(response.status_code) #返回的是响应头 print(response.headers) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
get请求
requests.get() eg: import requests url = 'http://www.baidu.com/s?' headers = { 'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } data = { 'wd':'北京' } response = requests.get(url,params=data,headers=headers) 定制参数 参数使用params传递 参数无需urlencode编码 不需要请求对象的定制 请求资源路径中?可加可不加- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
import requests url='https://www.baidu.com/s?' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } data={ 'wd':'北京' } #url 请求资源路径 #params 参数 #kwargs 字典 #参数使用params传递,无需urlcaode编码,不需要请求对象定制 response=requests.get(url=url,params=data,headers=headers) content=response.text print(content)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
post请求
🔥get和post区别? 1: get请求的参数名字是params post请求的参数的名字是data 2: 请求资源路径后面可以不加? 3: 不需要手动编解码 4: 不需要做请求对象的定制- 1
- 2
- 3
- 4
- 5
#百度翻译: import requests post_url = 'https://fanyi.baidu.com/sug' headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } data = { 'kw': 'eye' } response = requests.post(url = post_url,headers=headers,data=data) content=response.text import json obj=json.loads(content,encoding='utf-8') print(obj)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
{'errno': 0, 'data': [{'k': 'eye', 'v': 'n. 眼睛; 视力; 眼状物; 风纪扣扣眼 vt. 定睛地看; 注视; 审视; 细看'}, {'k': 'Eye', 'v': '[人名] 艾; [地名] [英国] 艾伊'}, {'k': 'EYE', 'v': 'abbr. European Year of the Environment 欧洲环境年; Iwas'}, {'k': 'eyed', 'v': 'adj. 有眼的'}, {'k': 'eyer', 'v': 'n. 注视的人'}]}- 1
代理
import requests url = 'http://www.baidu.com/s?' headers = { 'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome / 65.0.3325.181Safari / 537.36' } data = { 'wd': 'ip' } proxy = { 'http': '219.149.59.250:9797' } r = requests.get(url=url, params=data, headers=headers, proxies=proxy) with open('proxy.html', 'w', encoding='utf‐8') as fp: fp.write(r.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
cookie登录
#通过登录进入到主页面 #https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx #https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx #__VIEWSTATE: 8/fAX5GnPl1iyjSjQZ+0JIUyD+MNnRRbheG9PCqmGjdQ6c2SkVhzW4pB0Wz25WRa29TXIKysfJoMtzSCIx83KUpD7ZQjo9Ipk7bgfmLm5SFjullt4gBBONXMfgRIkzdAaOJI4vQFA/RRLwwtpzvkp/JlLJk= #__VIEWSTATEGENERATOR: C93BE1AE #from: http://so.gushiwen.cn/user/collect.aspx #email: 13939995748 #pwd: SQtlfzHSptmft01 #code: asda #denglu: 登录 #__VIEWSTATE、__VIEWSTATEGENERATOR、code是变量 import requests #登录界面 url='https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35' } response=requests.get(url=url,headers=headers) content=response.text #解析页面源码 获取__VIEWSTATE、__VIEWSTATEGENERATOR from bs4 import BeautifulSoup soup=BeautifulSoup(content,'lxml') #获取__VIEWSTATE viewstate=soup.select('#__VIEWSTATE')[0].attrs.get('value') #__VIEWSTATEGENERATOR viewstategenerator=soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value') #print(viewstate) #print(viewstategenerator) #获取验证码图片 code=soup.select('#imgCode')[0].attrs.get('src') code_url='https://so.gushiwen.cn'+code #print(code_url) #import urllib.request #urllib.request.urlretrieve(url=code_url,filename='code.jpg') #request中有一个方法 session()通过session的返回值就能使请求变成一个对象 session=requests.session() #验证码url的内容 response_code=session.get(url=code_url) #注意此时要使用二进制 因为我们要使用的是图片下载 content_code=response_code.content #wb模式就是将二进制数据写入到文件 with open('code.jpg','wb') as fp: fp.write(content_code) #获取了验证码图片之后 下载到本地 然后观察验证码 之后在控制台输入验证码,把值给code的参数,就可以登录了 code_name=input('请输入验证码') #点击登录 url='https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' data_post={ '__VIEWSTATE': viewstate, '__VIEWSTATEGENERATOR': viewstategenerator, 'from': 'http://so.gushiwen.cn/user/collect.aspx', 'email': '123456@qq.com', 'pwd': '123456', 'code': code_name, 'denglu': '登录' } response_post=session.post(url=url,headers=headers,data=data_post) content_post=response_post.text with open('gushiwen.html','w',encoding='utf-8')as fp: fp.write(content_post)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
Scrapy🚀
-
相关阅读:
java八大包装类
外滩大会观察|重估蚂蚁!
数组的用法
机器学习-概述与贝叶斯算法
C之(10)CMocka-单元测试框架使用
宠物赛道意外火了,行业龙头们相继奔赴IPO
算法系列九:十大经典排序算法之——快速排序
【项目问题定位】近来几个数据库相关问题定位与知识点总结
梯度下降法总是在同一点收敛吗?
vue - Vue路由(扩展)
- 原文地址:https://blog.csdn.net/m0_59598325/article/details/127807040