-
3. 查询处理
目录
一、 主要流程

- 解析器:词法、语法检查,生成语法解析树
- 分析器:语义分析,生成查询树
- 重写器:基于规则系统改写查询树
- 计划器:根据表的统计信息,基于代价生成一棵执行效率最高的计划树
- 执行器:执行计划树
以上这些“器”都是使用工作内存
视图是基于规则系统实现的。参见视图与规则系统
二、单表查询
1.计划器-扫描与排序成本估计
explain显示命令的计划树,每个节点表示执行器需要的信息,计划树从终端节点往根节点执行。
代价系数为相对性能指标。
总代价=启动代价+运行代价,expain显示的计划树cost=0.00..145.00表示启动代价为0.00,运行代价为145.00。
1.1 顺序扫描
只有运行代价:cost=系数*元组数,系数默认为1,pg假设所有的页面来自存储介质而不是缓冲区。
1.2 索引扫描
所有索引结构使用同一个代价函数:cost_index()=启动代价函数+运行代价
1.2.1 启动代价函数:
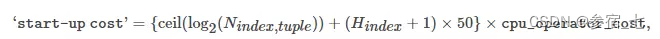
其中Hindex为索引高度,ceil函数是二分法查找指定值,hindex是走树的高度。
1.2.2 运行代价:
表和索引的CPU代价和IO代价之和,这四个值与要读取的索引元组和表元祖的数量有关。
如何知道要读取多少元组?有一个选择率(估值),将总的*选择率即可。(所以explain并不是根据历史数据估算的,而是根据选择率来估算的?)
选择率:选择率根据某一值在列中出现的频率决定,并在一开始就存储在pg_stat表中,当一列的可选值太多,就会将列的元组均分为100个直方图,并存储每个直方图的边界值,并以线性插值的方式计算出目标值的选择率。
索引相关性:在计算表元组的IO代价时,涉及一个索引相关性系数,就是在BRIN索引(提取每个范围的最大最小值,来加快顺序扫描)中也提到的那个系数,表示列值的物理顺序与逻辑顺序的统计相关性,越接近0越不相关,接近±1越相关。它会影响元组的随机访问性能。
访问谓词:一般就是where条件,表示扫描索引的起止条件。
random_page_cost:在SSD中最好将其设置为1(默认为4)(所以对于SSD来说随机存取与顺序存取速度是一样的)。
1.3 排序
如果能在工作内存中放下所有元组,则用快排,否则创建临时文件,使用归并排序。
代价函数:cost_sort()=O(N)+log2(N)+O(N)
对于一个查询并排序的语句,总的启动代价=索引代价+排序的启动代价
2.计划器—生成计划树
2.1 预处理
简单替换一些写法,将多个and/or表达式压平为多元表达式:
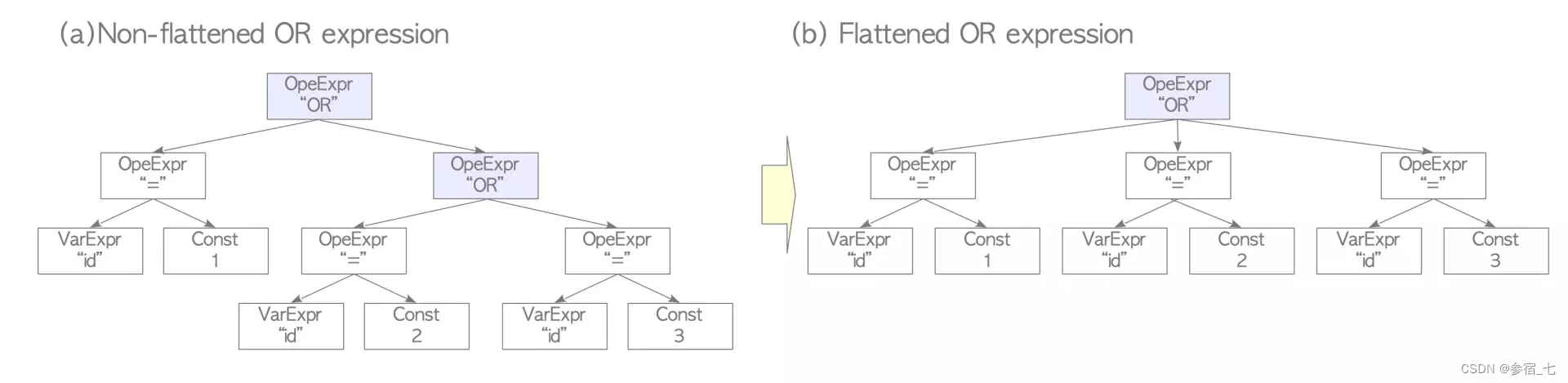
2.2 找出代价最小的访问路径
将可能的顺序扫描路径及成本、索引扫描路径及成本、位图扫描路径及成本都放在RelOptInfo结构的pathList变量中,其他Limit、orderby、aggregate成本等放在RelOptInfo结构的其他变量中。
where子句、排序,甚至扫描的路径与成本(可能包含多个路径与成本)都在其他脚本中执行成本估算,并将路径与代价放在RelOptInfo结构中,然后需要比较各类扫描的成本值,选择最小的,放在新的RelOptInfo结构中,并根据新的RelOptInfo生成一棵成本最小的计划树。
3.执行器
同样树也是从叶节点往根节点执行的。对应着explain的计划树。
因为计划树的每个节点还存储了目标表、以及相应操作,执行器调用每个节点的函数(这些函数都在src/beckend/executor中)
执行器在处理查询时会用到工作内存与临时缓存区,如果内存分配不出来,就会在base/pg_tmp下使用临时文件。在执行explain analyse命令时,可能会看到占用临时文件的信息。
三、多表查询
1.计划器—连接成本估计
下面提到的三类连接均可用于内连接、外连接、左连接、右连接等。
哪个是内表,哪个是外表是由计划器在遍历各种可能之后,根据连接成本定的,与写的顺序无关。
1.1 嵌套循环连接
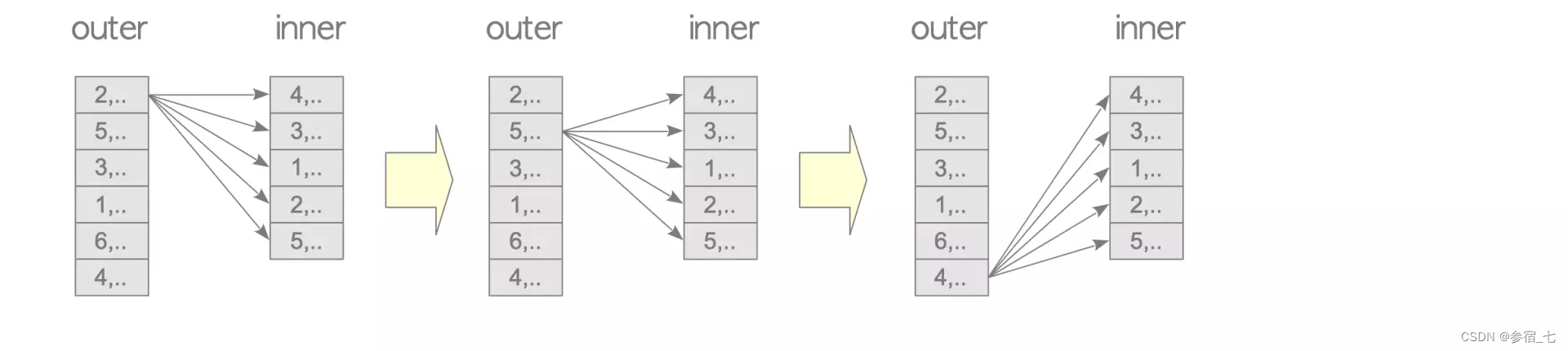
这个连接中外表只需扫描一遍,内表要扫描很多遍,就是两层的嵌套循环以找到内外表上相同的列值。外表的行越少越好:https://severalnines.com/database-blog/overview-join-methods-postgresql
只有运行代价,与内外表的元组数乘积成正比,虽然多表查询一定会估计该成本,但很少使用它,而是使用它的变体。
(考虑连接条件的话,A表总的元组数决定了A表扫描一遍的代价,A表匹配条件的元组数(这些元组构成了外表)决定了扫描内表的次数,B表的总元组数决定了B表扫描一遍的代价,B表匹配条件的元组数(这些元组构成了内表)决定了内表扫描的代价。)
变体1—物化内表
将内表扫描一遍加载到工作内存中以加快内表的扫描速度,(即物化过程,所以物化不一定要落盘?如果内存不够,就使用临时文件),再执行循环连接,对内表的多次扫描称为重扫描。之所以加载内表,是因为内表在连接过程中会被扫描很多次。

变体2—内表连接列上有索引
内表目标列上有索引的话,可以将两层循环缩短到一层,通过索引找到内表上和外表一样的列值。
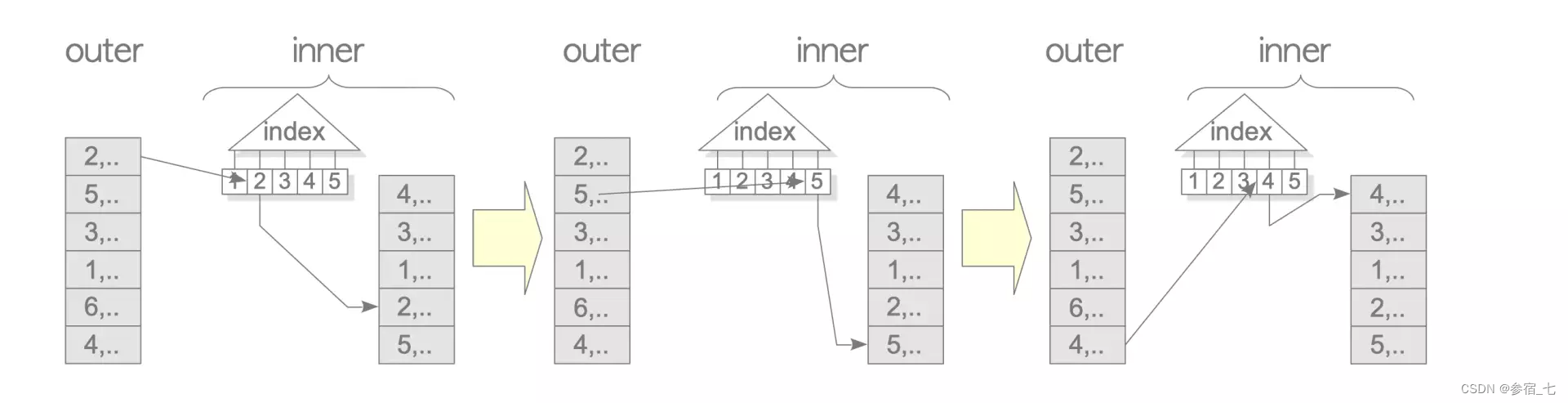
变体3—外表连接列上有索引
外部循环会产生一个数据集(也就是外表)来驱动连接条件。这个数据集可以通过使用索引范围扫描,全表扫描等方式从表里生成。如果表中的该列有索引,那么使用索引扫描来确定外表是更快的。
在连接阶段,也可以使用索引来扫描外表。(在连接阶段,因为都是要扫描所有行的,所以我没有看出来这个阶段中的索引扫描比顺序扫描更有优势,但在生成外表阶段,索引扫描有优势)
变体三可以和前面提到的基础版、变体一、变体二组合使用,形成三种情况的嵌套循环连接:
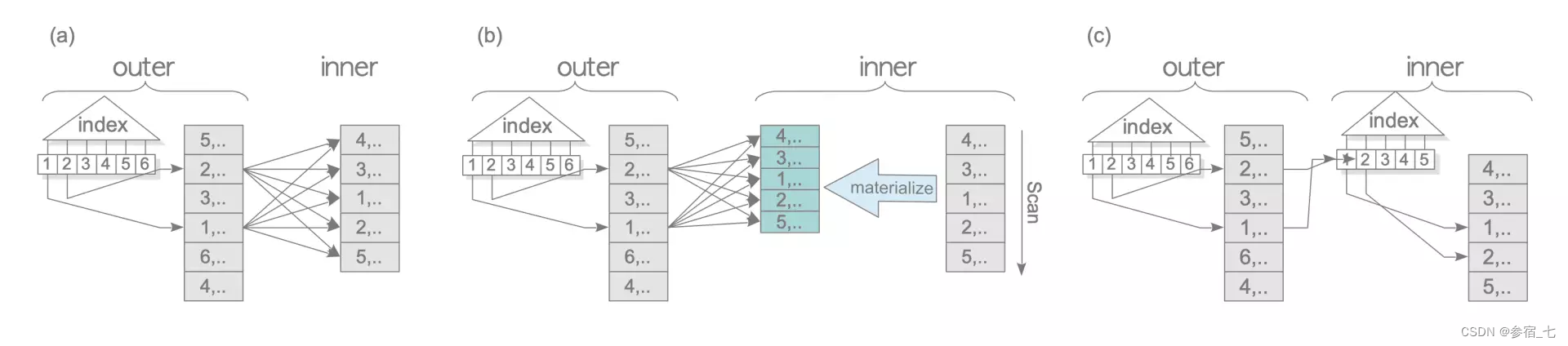
1.2 归并接连
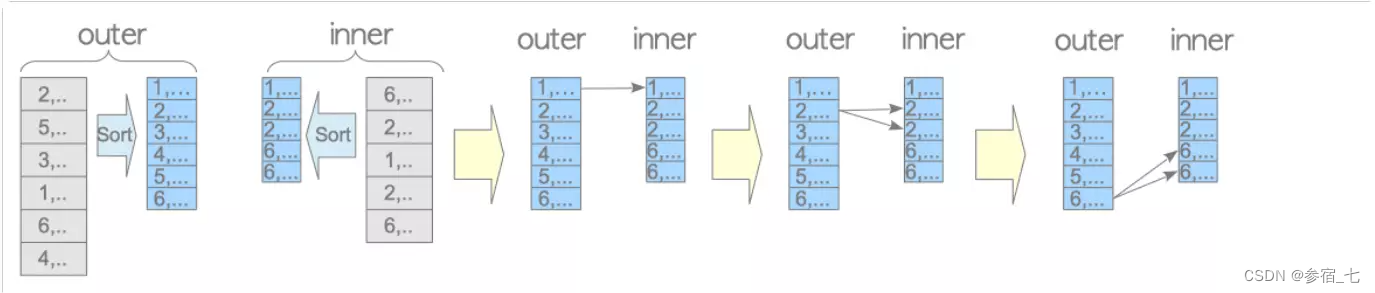
归并连接只能用于自然连接与等值连接,系统是否使用归并连接与数据的排序成本很相关,两个表的连接列会先排序,连接的过程如下:
For each tuple r in A For each tuple s in B If (r.ID = s.ID) Emit output tuple (r,s) Break; If (r.ID > s.ID) Continue; Else Break;归并连接的启动成本为内外表的排序成本之和。
归并连接的排序是将内外表都加载到内存中操作的,如果内存不够,则使用临时文件。
除了前面多了个排序操作,它的变体与嵌套循环连接类似,就是分为内表物化、内表索引、外表索引+基本、外表索引+内表物化、外表索引+内表索引等。
(什么是物化,如果物化是指将元组从磁盘中加载到内存或临时文件的话,那这里的排序就已经物化了,为什么内表还能再物化?)
1.3 散列连接
散列连接先对内表的连接字段创建散列表,将散列的桶与内表对应上,再对外表逐条扫描,并对连接字段进行散列,找到相应的桶,在桶里面与已有的内表连接字段进行等值比较(因为桶的编号只会取散列值的后几位,所以很可能同一个桶里的值是不一样的),如果找到了,则进行连接。其实就相当于先对内表创建索引,散列表就是一种索引。
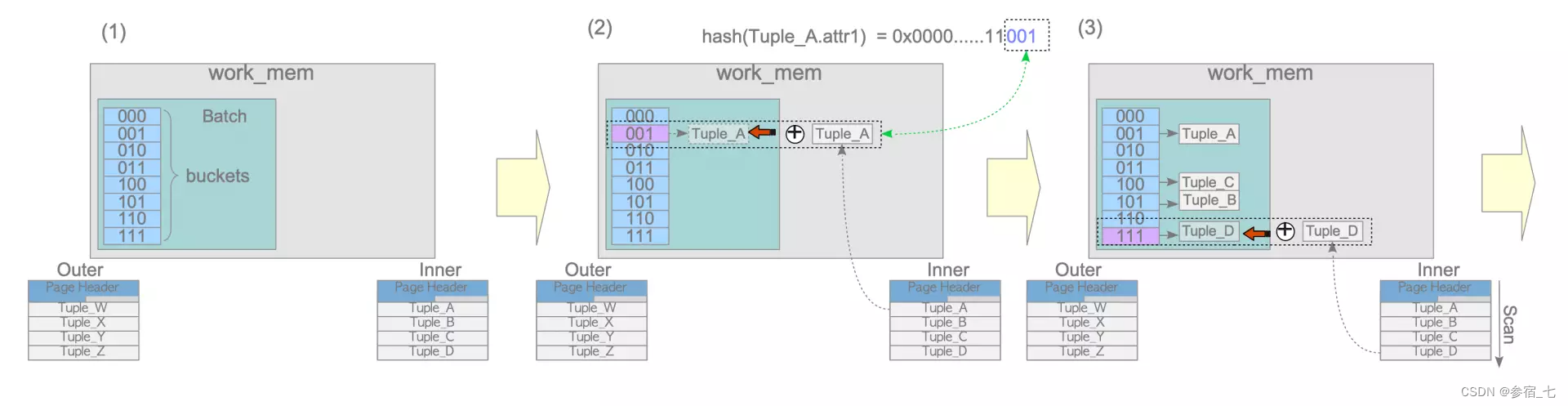

不考虑创建散列表的冲突的话,启动成本与运行成本都是O(N(内表)+N(外表))。
内存散列连接
当内表大小不超过工作内存的1/4的话,就会使用内存散列连接。
带倾斜的混合散列连接
分批构建与探测:
当内表很大,不能完全装入散列表中时,PG将操作分为 2的幂 个批次,第一个批次在工作内存中分配,其余的在临时文件中。以4批次,每批次8个桶为例,需要取散列值的后5位,前两位决定在哪个批次,后三位决定在哪个桶。
批次是一下子全分配的,但构建散列表与探测是分批的,只能一批一批地轮流进内存进行构建与探测。
倾斜批次:
第一个批次因为一开始就在内存中,所以速度较快,PG使用倾斜批次尽量让数据在第一批次中连接。比如10%的用户买了70%的东西,pg会将10%的客户存在第一批次中,以和尽量多的已售东西连接。pg通过已售东西表中的买家出现频率(高频的被标记为MCV(most common values),(前面提到的选择率大部分就是这个),是一直存在pg_stats上的)来确定哪些买家属于10%。倾斜批次也在内存中。
第一次构建与探测:
在第一次构建阶段,pg先判断内表元组是否属于倾斜批次,如果不属于,再进行散列决定元组去哪个批次。如果是第1批次,则会构建进相应的桶,如果是临时文件中,就进临时文件,但不会进相应的桶。

在第一次探测阶段,先分配3个与批次对应的临时文件用于存储外表。先判断外表元组的连接字段是否被标记为MVC,是的话在倾斜批次上探测。否则计算其所在批次,如果为第一批次,则进行探测,如果为临时文件中的批次,则将其存在刚刚分配的对应批次的临时文件中。
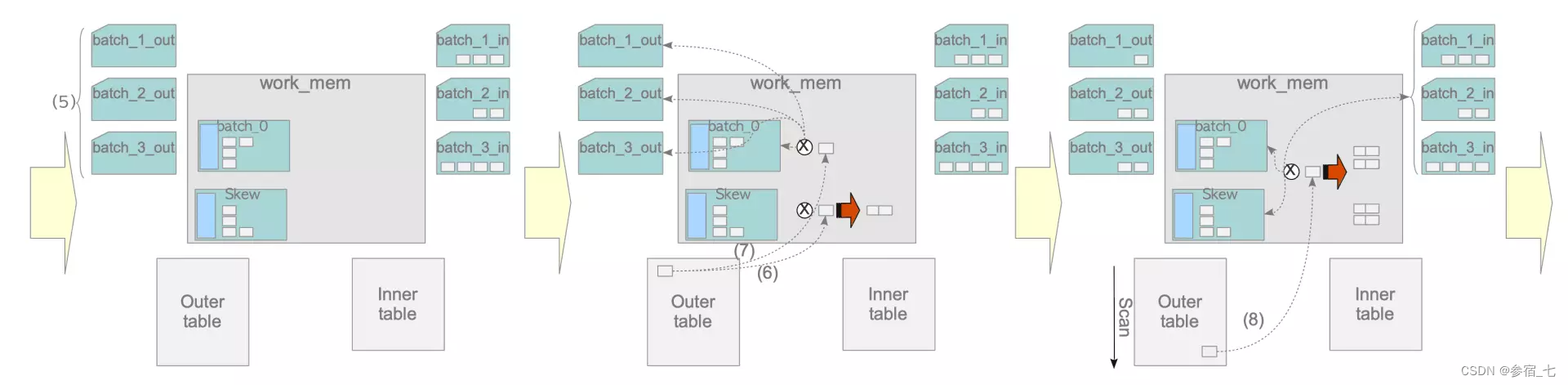
第n次构建与探测:
扫描一遍外表后,对倾斜批次与第一批次的连接已经该连的都连完了。将倾斜批次与第一批次移出,加载内表存在第二批次并构建,然后加载外表存的第二批次并探测。以此类推。

注意,处于第二批次的外表只可能与处于第二批次的内表连接,这是哈希值的作用。
2. 计划器—连接访问路径与连接节点
连接访问路径都基于joinpath实现
所有连接访问路径:

连接节点 NestedLoopNode, MergeJoinNode and HashJoinNode都基于joinnode实现
3. 计划器—创建多表查询计划树
3.1 预处理
- 处理with查询
- 上拉子查询:如果有一个FROM子查询,并且没有GROUP BY、HAVING、ORDER BY、LIMIT和DISTINCT子句,并且没有使用INTERSECT或EXCEPT,则planner会通过pull_up_subquerys()函数将其转换为连接形式。例如,下面可以转换为自然连接查询。不用说,这种转换是在查询树中完成的。
testdb=# SELECT * FROM tbl_a AS a, (SELECT * FROM tbl_b) as b WHERE a.id = b.id; ↓ testdb=# SELECT * FROM tbl_a AS a, tbl_b as b WHERE a.id = b.id;
- 如果可以的话,将外连接转换为内连接
3.2 获取代价最小的路径
因为各个索引与各种连接方法的组合非常多,当表小于12张时,计划器使用动态规划来获取最佳计划,否则使用遗传算法(基因查询优化器,使优化器能快速找到一个近似最优的路径)。
动态规划:
- 先根据单表查询章节中的找出单表的各种索引扫描的代价最小的访问路径
- 再根据连接成本估计章节中找出两张表间各种连接方法的最小代价访问路径
- 将两表的最小连接结果视为一张表,与第三张表进行连接,通过两张表间各种连接方法找出最小代价访问路径,以此类推。(需要注意的是,动态规划的局部最优不一定是全局最优,但是一个比较优的)

上图是个例子,先顺序扫描表a(内表,行11),对其进行散列(行10),在顺序扫描表b(外表,行9),将a与b进行哈希连接(行7),索引扫描表3(内表,行13),框框中a与b的散列连接结果视为外表,通过索引与表3进行嵌套循环连接(行5,内表索引循环连接的话,内外表都只需循环1次)。
-
相关阅读:
JDBC中的Connection的sql语句
查询中一些字段的用法
mybatis-plus(insertBatchSomeColumn批量添加)
Qt 样式设置
24.java- File类的常用方法:遍历目录里的文件
8年思科C语言程序员转web独立开发者年收入超10万美元
理解Hash表
课堂笔记| 第九章:容器和迭代器
对近期的学习内容进行一个梳理总结
【Linux笔记】Linux基础权限
- 原文地址:https://blog.csdn.net/Michaelia_hu/article/details/127804087