-
【C++学习第三讲】C++语句
一、引入
C++程序是一组函数,而每个函数又是一组语句。C++有好几种语句,下面介绍其中的一些。下面提供了一些新的语句,
声明语句创建变量,赋值语句给该变量提供一个值。另外,该程序还演示了
cout的新功能。#includeint main(){ using namespace std; int carrots; carrots = 25; cout << "I have "; cout << carrots; cout << " carrots "; cout << endl; carrots = carrots - 1; cout << "I have " << carrots << " carrots" << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
空行将声明语句与程序的其他部分分开。
这是C常用的方法,但在C++中不那么常见。下面是该程序的输出:
I have 25 carrots I have 24 carrots D:\C++Project\Project1\x64\Debug\Project1.exe (进程 39700)已退出,代码为 0。 要在调试停止时自动关闭控制台,请启用“工具”->“选项”->“调试”->“调试停止时自动关闭控制台”。 按任意键关闭此窗口. . .- 1
- 2
- 3
- 4
- 5
- 6
下面探讨这个程序。
二、声明语句和变量
计算机是一种精确的、有条理的机器。
要将信息项存储在计算机中,必须指出信息的存储位置和所需的内存空间。
在C++中,完成这种任务的一种相对简便的方法,是使用声明语句来指出存储类型并提供位置标签。
int carrots;- 1
这条语句提供了两项信息:
-
需要的内存
-
该内存单元的名称。
具体地说,这条语句指出程序需要足够的存储空间来存储一个整数,在C++中用int表示整数。
编译器负责分配和标记内存的细节。
C++可以处理多种类型的数据,而int是最基本的数据类型。它表示整数—没有小数部分的数字。
C++的int类型可以为正,也可以为负,但是大小范围取决于实现。
完成的第二项任务是给存储单元指定名称。
在这里,该声明语句指出,此后程序将使用名称carrots来标识存储在该内存单元中的值。
Carrots被称为变量,因为它的值可以修改。
在C++中,所有变量都必须声明。
如果省略了声明,则当程序试图使用carrots时,编译器将指出错误。
事实上,程序员尝试省略声明,可能只是为了看看编译器的反应。这样,以后看到这样的反应时,便知道应检查是否省略了声明。
1. 为什么变量必须声明?
有些语言(最典型的是BASIC)在使用新名称时创建新的变量,而不用显式地进行声明。这看上去对用户比较友好,事实上从短期上说确实如此。问题是,如果错误地拼写了变量名,将在不知情的情况下创建一个新的变量。在BASIC中,ss程序员可能编写如下语句:

由于CastleDank是拼写错误(将r拼成了n),因此所作的修改实际上并没有修改CastleDark。这种错误很难发现,因为它没有违反BASIC中的任何规则。
然而,在C++中,将声明CastleDark,但不会声明被错误拼写的CastleDank,因此对应的C++代码将违反“使用变量前必须声明它”的规则,因此编译器将捕获这种错误,发现潜在的问题。
因此,声明通常指出了要存储的数据类型和程序对存储在这里的数据使用的名称。
对上一个程序例子中,创建一个名为carrots的变量,它可以存储整数:
程序中的声明语句叫做定义声明(defining declaration)语句,简称为定义(definition)。这意味着它将导致编译器为变量分配内存空间。在较为复杂的情况下,还可能有引用声明(reference declaration)。这些声明命令计算机使用在其他地方定义的变量。
通常,声明不一定是定义,但在这个例子中,声明是定义。
对于声明变量,C++的做法是尽可能在首次使用变量前声明它。
三、赋值语句
赋值语句将值赋给存储单元。例如,下面的语句将整数25赋给变量carrots表示的内存单元:
carrots = 25;- 1
符号
=叫做赋值运算符。C++(和C)有一项不寻常的特性—可以连续使用赋值运算符。例如,下面的代码是合法的:

赋值将从右向左进行。首先,88被赋给steinway;然后,steinway的值(现在是88)被赋给baldwin;然后baldwin的值88被赋给yamaha(C++遵循C的爱好,允许外观奇怪的代码)。
第二条赋值语句表明,可以对变量的值进行修改:
carrots = carrots - 1;- 1
赋值运算符右边的表达式carrots – 1是一个算术表达式。计算机将变量carrots的值25减去1,得到24。然后,赋值运算符将这个新值存储到变量carrots对应的内存单元中。
四、cout新花样
到目前为止,学习的示例都使用cout来打印字符串,上述程序使用cout来打印变量,该变量的值是一个整数:
cout << carrots;- 1
程序没有打印“carrots”,而是打印存储在carrots中的整数值,即25。实际上,这将两个操作合而为一了。首先,cout将carrots替换为其当前值25;然后,把值转换为合适的输出字符。
如上所示,cout可用于数字和字符串。这似乎没有什么不同寻常的地方,但别忘了,整数25与字符串“25”有天壤之别。
该字符串存储的是书写该数字时使用的字符,即字符3和8。程序在内部存储的是字符3和字符8的编码。要打印字符串,cout只需打印字符串中各个字符即可。
但整数25被存储为数值,计算机不是单独存储每个数字,而是将25存储为二进制数。
这里的要点是,在打印之前,cout必须将整数形式的数字转换为字符串形式。另外,cout很聪明,知道carrots是一个需要转换的整数。
与老式C语言的区别在于cout的聪明程度。在C语言中,要打印字符串“25”和整数25,可以使用C语言的多功能输出函数
printf( ):
撇开printf( )的复杂性不说,
必须用特殊代码(%s和%d)来指出是要打印字符串还是整数。如果让printf( )打印字符串,但又错误地提供了一个整数,由于printf( )不够精密,因此根本发现不了错误。它将继续处理,显示一堆乱码。
cout的智能行为源自C++的面向对象特性。实际上,C++插入运算符(<<)将根据其后的数据类型相应地调整其行为,这是一个运算符重载的例子。
五、cout和printf( )
如果已经习惯了C语言和printf( ),可能觉得cout看起来很奇怪。
程序员甚至可能固执地坚持使用printf( )。但与使用所有转换说明的printf( )相比,cout的外观一点也不奇怪。更重要的是,cout还有明显的优点。它能够识别类型的功能表明,其设计更灵活、更好用。
另外,它是可扩展的(extensible)。也就是说,可以重新定义<<运算符,使cout能够识别和显示所开发的新数据类型。如果喜欢printf( )提供的细致的控制功能,可以使用更高级的cout来获得相同的效果。
六、其他C++语句
再来看几个C++语句的例子。
程序对前一个程序进行了扩展,要求在程序运行时输入一个值。
为实现这项任务,它使用了
cin,这是与cout对应的用于输入的对象。另外,该程序还演示了cout对象的多功能性。
#includeint main(){ using namespace std; int carrots; cout << "How many carrots do you have ?"; cout << endl; cin >> carrots; cout << "Here are two more !"; carrots = carrots + 2; cout << "Now you have " << carrots << "carrots" << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
下面是该程序的运行情况:
How many carrots do you have ? 10 Here are two more !Now you have 12carrots D:\C++Project\Project1\x64\Debug\Project1.exe (进程 41100)已退出,代码为 0。 要在调试停止时自动关闭控制台,请启用“工具”->“选项”->“调试”->“调试停止时自动关闭控制台”。 按任意键关闭此窗口. . .- 1
- 2
- 3
- 4
- 5
- 6
- 7
该程序包含两项新特性:用cin来读取键盘输入以及将四条输出语句组合成一条。下面分别介绍它们:
1. 使用cin
上面的输出表明,从键盘输入的值(10)最终被赋给变量carrots。下面就是执行这项功能的语句:
cin >> carrots;- 1
从这条语句可知,信息从cin流向carrots。
显然,对这一过程有更为正式的描述。就像C++将输出看作是流出程序的字符流一样,它也将输
入看作是流入程序的字符流。iostream文件将cin定义为一个表示这种流的对象。
输出时,
<<运算符将字符串插入到输出流中;输入时,cin使用
>>运算符从输入流中抽取字符。通常,需要在运算符右侧提供一个变量,以接收抽取的信息(符号<<和>>被选择用来指示信息流的方向)。
与cout一样,cin也是一个智能对象。它可以将通过键盘输入的一系列字符(即输入)转换为接收信息的变量能够接受的形式。在这个例子中,程序将carrots声明为一个整型变量,因此输入被转换为计算机用来存储整数的数字形式。
2. 使用cout进行拼接
上面程序将4条输出语句合并为一条。
iostream文件定义了<<运算符,以便可以像下面这样合并(拼接)输出:
cout << "Now you have " << carrots << "carrots" << endl;- 1
这样能够将字符串输出和整数输出合并为一条语句。得到的输出与下述代码生成的相似:
cout << "Now you have "; cout << carrots; cout << "carrots"; cout << endl;- 1
- 2
- 3
- 4
根据有关cout的建议,也可以按照这样的方式重写拼接版本,即将一条语句放在4行上:
cout << "Now you have "; << carrots; << "carrots"; << endl;- 1
- 2
- 3
- 4
这是由于C++的自由格式规则将标记间的换行符和空格看作是可相互替换的。
当代码行很长,限制输出的显示风格时,最后一种技术很方便。
需要注意的另一点是:
Now you have 12carrots- 1
Here are two more !- 1
在同一行中。
这是因为前面指出过的,cout语句的输出紧跟在前一条cout语句的输出后面。即使两条cout语句之前有其他语句,情况也将如此。
七、类简介
看了足够多的cin和cout示例后,可以学习有关对象的知识了。
具体地说,本节将进一步介绍有关类的知识。
类是C++中面向对象编程(OOP)的核心概念之一。
类是用户定义的一种数据类型。
要定义类,需要描述它能够表示什么信息和可对数据执行哪些操作。
类之于对象就像类型之于变量。也就是说,类定义描述的是数据格式及其用法,而对象则是根据数据格式规范创建的实体。
换句话说,如果说类就好比所有著名演员,则对象就好比某个著名的演员。
下面更具体一些。前文讲述过下面的变量声明:
int carrots;- 1
上面的代码将创建一个类型为int的变量(carrots)。也就是说,carrots可以存储整数,可以按特定的方式使用—例如,用于加和减。
现在来看cout。它是一个ostream类对象。ostream类定义(iostream文件的另一个成员)描述了ostream对象表示的数据以及可以对它执行的操作,如将数字或字符串插入到输出流中。同样,cin是一个istream类对象,也是在iostream中定义的。
类描述了一种数据类型的全部属性(包括可使用它执行的操作),对象是根据这些描述创建的实体。- 1
知道类是用户定义的类型,但作为用户,并没有设计ostream和istream类。就像函数可以来自函数库一样,类也可以来自类库。ostream和istream类就属于这种情况。
从技术上说,它们没有被内置到C++语言中,而是语言标准指定的类。
这些类定义位于iostream文件中,没有被内置到编译器中。
类描述指定了可对类对象执行的所有操作。
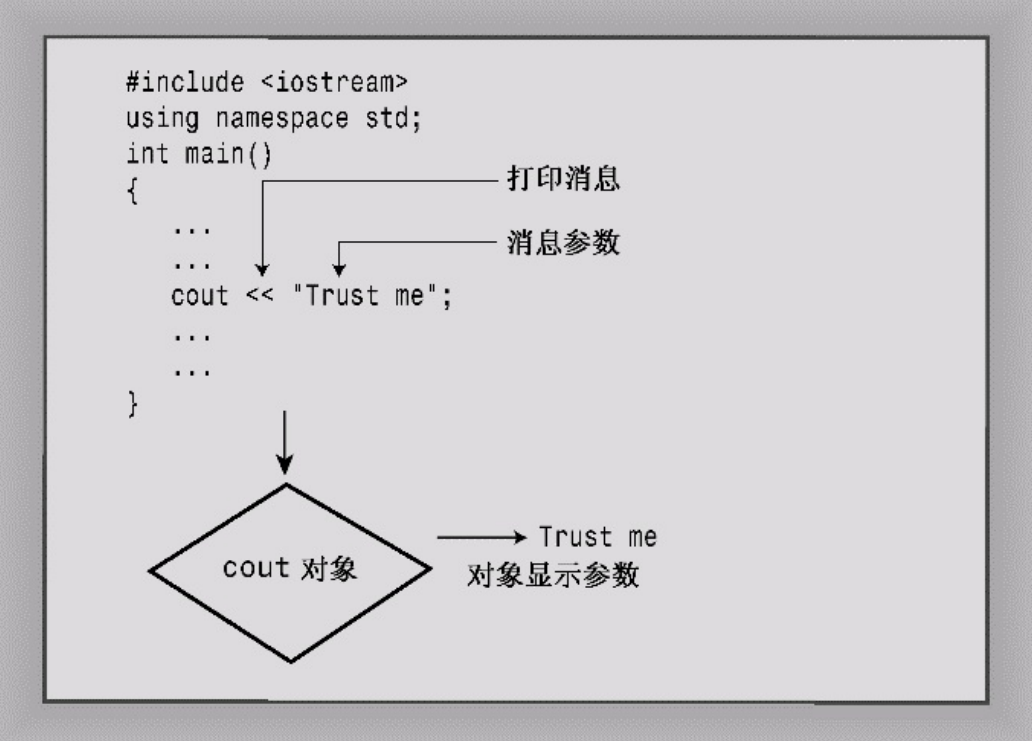
要对特定对象执行这些允许的操作,需要给该对象发送一条消息。
例如,如果希望cout对象显示一个字符串,应向它发送一条消息,告诉它,“对象!显示这些内
容!”C++提供了两种发送消息的方式:
- 一种方式是使用类方法(本质上就是稍后将介绍的函数调用);
- 另一种方式是重新定义运算符,cin和cout采用的就是这种方式。
因此,下面的语句使用重新定义的<<运算符将“显示消息”发送给cout:
cout << "I am not a crock"- 1
在这个例子中,消息带一个参数—要显示的字符串:
-
相关阅读:
VMware vcenter/ESXI系列漏洞总结
面试不到10分钟就被赶出来了,问的实在是太变态了...
【剧前爆米花--爪哇岛寻宝】面向对象的三大特性——封装、继承以及多态的详细剖析(中——多态)。
Java MyBatis查询数据库&结果映射 之ResultMap的使用
发布自己的 npm 插件包:步骤与最佳实践
基于SpringBoot的仿小米商城系统
【期望+状压DP】 2021 CCPC G
23个react常见问题
tinymce 一键排版功能 tpLayout
flutter 二维数组赋值问题
- 原文地址:https://blog.csdn.net/wzk4869/article/details/127803776