-
进程间通讯(匿名管道,命名管道,共享空间)
1.进程间通讯
1.为什么要通讯
1.进程是具有独立性的(写时拷贝),这样子带来了一个问题进程想交互数据,成本会非常高(要做很多准备工作),因为我们需要多进程进行协同处理一件事情
2.进程独立了不代表时完全独立,有时候需要双方一定的信息交互2.进程间通信目的
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
3.匿名管道
创建进程时,大概像下面图片一样生成一系列的结构体,因为之前博客文件描述符详细说过,所以就不细说
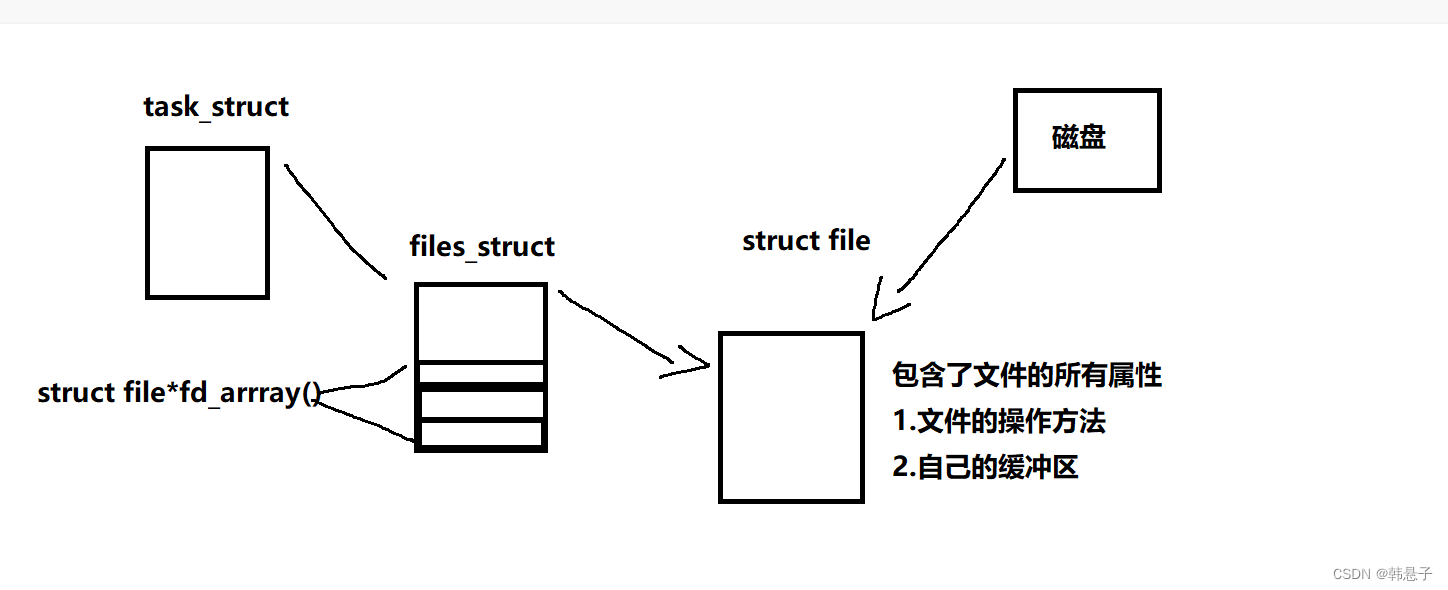
fork之后子进程会以父进程为模板发生写时拷贝,那么struct file子进程要不要发生拷贝,答案时不用的,因为struct file是一个被打开的文件,而我们是创建子进程,而我们发生拷贝的时候要拷贝 看下图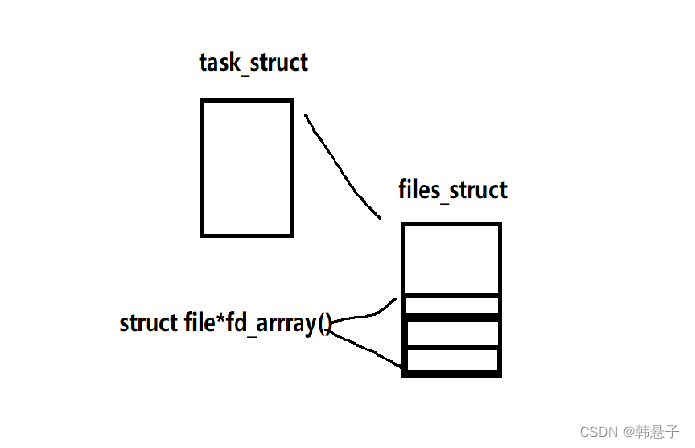
而他也会对应着父进程做映射,比如fd数组 的0 1 2 等等,因为打开了一个文件,分配给了文件描述3,所以sruct file*fdarray()也有那个struct file的地址 ,所以它们能在同一个终端打印时因为它们指向的时同一个文件,而这个打开sturct file文件就是二个进程看到的同一份资源
那么他设置成如果是普通文件就写入磁盘是管道文件他也往缓冲区写但他就不在磁盘里面刷新了,而子进程通过读取缓冲区的方式来读,而这就完成了通信的方式了
而我们从文件里面通过缓冲区来读取的文件我们称呼为管道1.那么为什么,父进程要分别打开读和写?因为管道是继承父进程,让子进程不用在打开了,如果二人进程都读那么就没有写了
2.为什么父子要关闭对应的读写
因为管道必须是单向通信的!
3.谁决定,父子进程关闭什么读写?
不是由管道本身决定的,是由我们自己的需要决定的因为管道是由fork的所以要打开或者关闭二次,关闭还是close(1)二次打开就太麻烦了,所以有个接口pipe,用piepe打开你会获得二个文件描述符,而且同时是系统调用,它对应者内核对应的类型,所以也不会写到磁盘里面
4.管道实现
#include#include #include #include #include #include #include #include #include using namespace std; #define NUM 1024 int main() { int pipefd[2] = {0}; if(pipe(pipefd) != 0) { cerr << "pope error" << endl; return 1; } pid_t id = fork(); if(id < 0) { cerr<< "fork errror" << endl; return 2; } else if(id == 0)//子进程读取,子进程应该关掉写端 { close(pipefd[1]); char buffer[NUM]; while(true) { memset(buffer,0,sizeof(buffer)); ssize_t s = read(pipefd[0],buffer,sizeof(buffer)-1); if( s > 0) { buffer[s] = '\0'; cout<< "子进程以收到消息 : " << buffer <<endl; } else if(s == 0) { cout<< "父进程写完了,子进程也退出了"<<endl; break; } else { } } close(pipefd[0]); exit(0); } else//父进程写入,就应该关掉读端 0是读 1是写 { close(pipefd[0]); const char *msg = "你好子进程,我是父进程, 这次发送的信息编号是: "; int cnt = 0; while(cnt < 5) { char sendBuffer[1024]; sprintf(sendBuffer, "%s : %d", msg, cnt); write(pipefd[1], sendBuffer, strlen(sendBuffer)); sleep(1); cnt++; } close(pipefd[1]); cout << "父进程写完了"<<endl; } pid_t res = waitpid(id,nullptr,0); if(res>0) { cout <<"等待子进程成功"<<endl; } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
上面代码管道了,父进程负责写,子进程负责读
运行结果
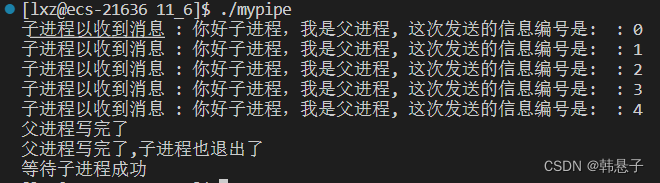
上面代码子进程是没有关于sleep,但是子进程的读取节奏是和父进程的sleep是一样的按sleep(1)的节奏来读
也就是说父进程没有写入数据,子进程在等,所以父进程写完后,子进程才能读取数据,也是父子进程读取的时候具有一定顺序性,但是父子进程各自printf的时候向显示器输入是没有顺序的总结:
1.管道里面父子进程具有一定顺序性
2.读取管道内部如果没有数据,readerr就必须堵塞等待,哪怕是管道被写满了一样5.进程控制
下面代码是父进程派发任务指令,子进程通过任务编码,调用对应的功能
#include#include #include #include #include #include #include #include #include #include #include using namespace std; typedef void (*functor)(); vector<functor> functors; // 方法集合 // for debug unordered_map<uint32_t, string> info; void f1() { cout << "这是一个处理日志的任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; // } void f2() { cout << "这是一个备份数据任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; } void f3() { cout << "这是一个处理网络连接的任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; } void loadFunctor() { info.insert({functors.size(), "处理日志的任务"}); functors.push_back(f1); info.insert({functors.size(), "备份数据任务"}); functors.push_back(f2); info.insert({functors.size(), "处理网络连接的任务"}); functors.push_back(f3); } int main() { // 0. 加载任务列表 loadFunctor(); // 1.创建管道 int pipefd[2] = {0}; if (pipe(pipefd) != 0) { cerr << "pipe error" << endl; return 1; } // 2.创建子进程 pid_t id = fork(); if (id < 0) { cerr << "fork error" << endl; return 2; } else if (id == 0) { close(pipefd[1]); int cnt = 0; while (cnt < 10) { uint32_t operatorType = 0; ssize_t s = read(pipefd[0], &operatorType, sizeof(uint32_t)); if (s == 0) { cout << "我要退出啦,我是给人打工的,老板都走了...." << endl; break; } assert(s == sizeof(uint32_t)); // assert断言,是编译有效 debug 模式 // release 模式,断言就没有了. // 一旦断言没有了,s变量就是只被定义了,没有被使用。release模式中,可能会有warning (void)s; if (operatorType < functors.size()) { functors[operatorType](); } else { cerr << "bug? operatorType = " << operatorType << std::endl; } } close(pipefd[0]); exit(0); } else { srand((long long)time(nullptr)); // parent,write - 操作 // 3. 关闭不需要的文件fd close(pipefd[0]); // 4. 指派任务 int num = functors.size(); int cnt = 10; while (cnt--) { // 5. 形成任务码 uint32_t commandCode = rand() % num; cout << "父进程指派任务完成,任务是: " << info[commandCode] << " 任务的编号是: " << cnt << endl; // 向指定的进程下达执行任务的操作 write(pipefd[1], &commandCode, sizeof(uint32_t)); sleep(1); } close(pipefd[1]); pid_t res = waitpid(id, nullptr, 0); if (res) { cout << "wait success" << endl; } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
运行结果

但是如果想控制一批进程呢?
那么就父进程和所有的进程进行管道关系,而这个就叫做进程池
下面代码和上面那个代码不一样的是,这个是能控制一批进程,分别给不同的进程分发任务
processNum代表着子进程的个数work(pipefd[0]);这个函数代表着实现分发任务的办法#include#include #include #include #include #include #include #include #include #include #include using namespace std; typedef void (*functor)(); vector<functor> functors; // 方法集合 // for debug unordered_map<uint32_t, string> info; void f1() { cout << "这是一个处理日志的任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; } void f2() { cout << "这是一个备份数据任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; } void f3() { cout << "这是一个处理网络连接的任务, 执行的进程 ID [" << getpid() << "]" << "执行时间是[" << time(nullptr) << "]\n" << endl; } void loadFunctor() { info.insert({functors.size(), "处理日志的任务"}); functors.push_back(f1); info.insert({functors.size(), "备份数据任务"}); functors.push_back(f2); info.insert({functors.size(), "处理网络连接的任务"}); functors.push_back(f3); } // int32_t: 进程pid, int32_t: 该进程对应的管道写端fd typedef pair<int32_t, int32_t> elem; int processNum = 5; void work(int blockFd) { cout << "进程[" << getpid() << "]" << " 开始工作" << endl; // 子进程核心工作的代码 while (true) { // a.阻塞等待 b. 获取任务信息 uint32_t operatorCode = 0; ssize_t s = read(blockFd, &operatorCode, sizeof(uint32_t)); if(s == 0) break; assert(s == sizeof(uint32_t)); (void)s; // c. 处理任务 if(operatorCode < functors.size()) { functors[operatorCode](); } } cout << "进程[" << getpid() << "]" << " 结束工作" << endl; } // [子进程的pid, 子进程的管道fd] void blanceSendTask(const vector<elem> &processFds) { srand((long long)time(nullptr)); while(true) { sleep(1); // 选择一个进程, 选择进程是随机的,没有压着一个进程给任务 // 较为均匀的将任务给所有的子进程 --- 负载均衡 uint32_t pick = rand() % processFds.size(); // 选择一个任务 uint32_t task = rand() % functors.size(); // 把任务给一个指定的进程 write(processFds[pick].second, &task, sizeof(task)); // 打印对应的提示信息 cout << "父进程指派任务->" << info[task] << "给进程: " << processFds[pick].first << " 编号: " << pick << endl; } } int main() { loadFunctor(); vector<elem> assignMap; // 创建processNum个进程 for (int i = 0; i < processNum; i++) { // 定义保存管道fd的对象 int pipefd[2] = {0}; // 创建管道 pipe(pipefd); // 创建子进程 pid_t id = fork(); if (id == 0) { // 子进程读取, r -> pipefd[0] close(pipefd[1]); // 子进程执行 work(pipefd[0]); close(pipefd[0]); exit(0); } //父进程做的事情, pipefd[1] close(pipefd[0]); elem e(id, pipefd[1]); assignMap.push_back(e); } cout << "create all process success!" << std::endl; // 父进程, 派发任务 blanceSendTask(assignMap); // 回收资源 for (int i = 0; i < processNum; i++) { if (waitpid(assignMap[i].first, nullptr, 0) > 0) cout << "wait for: pid=" << assignMap[i].first << " wait success!" << "number: " << i << "\n"; close(assignMap[i].second); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
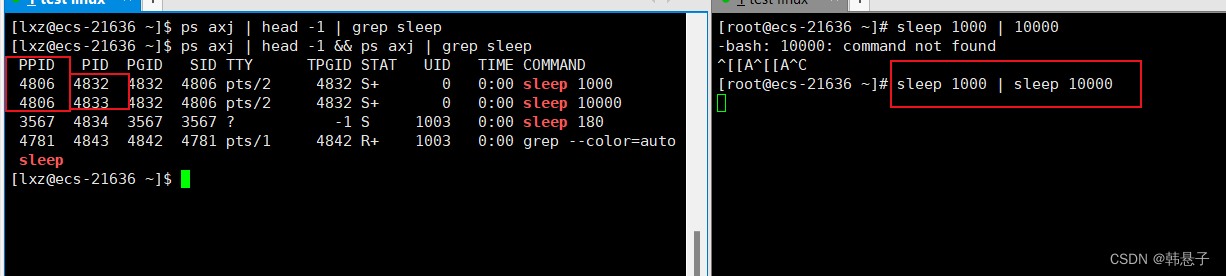
6.管道符号的理解
下面图片的右边sleep 1000 | sleep 10000 左边可以看到它们的ppid相同,但是pid不相同,它们这种关系叫做兄弟关系,而这种,兄弟关系的子进程指向了管道的读写关系,父进程取消了对管道的读写,这样子就等于取消了父子通信,变成了兄弟通信
7.管道特点总结
1.管道只能用来进程具有血缘关系的进程之间,进行进程间通信,常用于父子通信
2.管道只能单向通信(内核决定的),半双工的一种特殊情况
3.管道自带同步机制(pipe满,writer等。pipe空reader等)自带访问控制
4.管道是面向字节流的,先写的字符,一定是先被读取的,没有格式边界,需要用户来定义区分内容的边界,上面的代码我们就实现过了
5.管道的声明周期,管道是文件,进程退出了,曾经打开的文件也会随进程退出8.命名管道
匿名管道只能和有血缘关系的进程通信,如果是毫无关系的就不能通信,而命名管道就可以解决这个问题,他继承了管道的所有特征,区别在于命名管道可以能让毫无关系的进程通信,而匿名管道不行
匿名管道原理实现是通过子进程继承父进程的关系来看到同一份资源,
命名管道原理,命名管道是你要打开文件struct file只有一份,你打开了就计时加1,再打开了一份就再记时加1并把文件的地址发过去,也就是说有一个管道文件,他有路径,他具有唯一性,那么二个进程都通过管道路径找到这个文件,它们就能打开同一个stuct file文件,那么在同一个缓冲区读取同一份资源命名管道的使用mkfifo函数是创建管道文件
serverFifo.cpp#include "comme.h" using namespace std; int main() { umask(0); if(mkfifo(IPC_PATH,0666) != 0) { cerr<<"mkfifo error"<<endl; return 1; } cout<<"hello server"<<endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
makefile
.PHONY:all all:clientFifo serverFifo clientFifo:clientFifo.cpp g++ -o $@ $^ -std=c++11 serverFifo:serverFifo.cpp g++ -o $@ $^ -std=c++11 .PHONY:clean clean: rm -rf clientFifo serverFifo- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
comme.h
#pragma once #include#include #include #include #include #include #include #include #include #define IPC_PATH "./fifo" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
clientFifo.cpp
#include "comme.h" using namespace std; int main() { cout<<"hello client"<<endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们make一下 ./serrverFifo 可以看到通过mkfifo函数创建了一个管道文件,因为p开头的文件就是管道文件
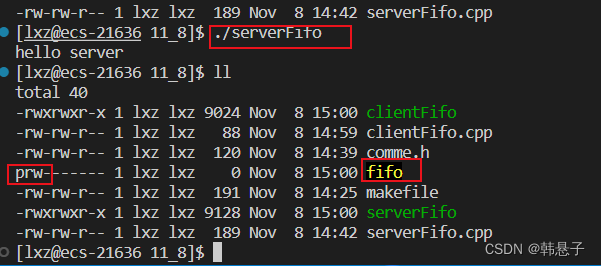
如果我们想要serverFifo.cpp读取,clientFifo.cpp负责写入
下面代码是运行clientFifo.cpp文件,输入消息,serverFifo.cpp能接收到消息clientFifo.cpp
#include "comme.h" using namespace std; int main() { int pipeFd = open(IPC_PATH, O_WRONLY); if(pipeFd < 0) { cerr << "open: " << strerror(errno) << endl; return 1; } #define NUM 1024 char line[NUM]; while(true) { printf("请输入你的消息# "); fflush(stdout); memset(line, 0, sizeof(line)); // fgets -> C -> line结尾自动添加\0 if(fgets(line, sizeof(line), stdin) != nullptr) { //abcd\n\0 line[strlen(line) - 1] = '\0'; write(pipeFd, line, strlen(line)); } else { break; } } close(pipeFd); cout << "客户端退出啦" << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
serverFifo.cpp
#include "comme.h" using namespace std; int main() { umask(0); if(mkfifo(IPC_PATH,0600) != 0) { cerr<<"mkfifo error"<<endl; return 1; } int pipeFd = open(IPC_PATH, O_RDONLY); if(pipeFd < 0) { cerr << "open fifo error" << endl; return 2; } #define NUM 1024 //正常的通信过程 char buffer[NUM]; while(true) { ssize_t s = read(pipeFd, buffer, sizeof(buffer)-1); if(s > 0) { buffer[s] = '\0'; cout << "客户端->服务器# " << buffer << endl; } else if(s == 0) { cout << "客户退出,我也退出"; break; } else { //do nothing cout << "read: " << strerror(errno) << endl; break; } } close(pipeFd); cout << "服务端退出啦" << endl; unlink(IPC_PATH);//删除文件用的 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
我们先运行serverFifo.cpp,生成管道fifo,在运行负责写的clientFifo.cpp,我们在clientFifo.cpp哪里发消息,那么负责读serverFifo.cpp的窗口也可以收到消息
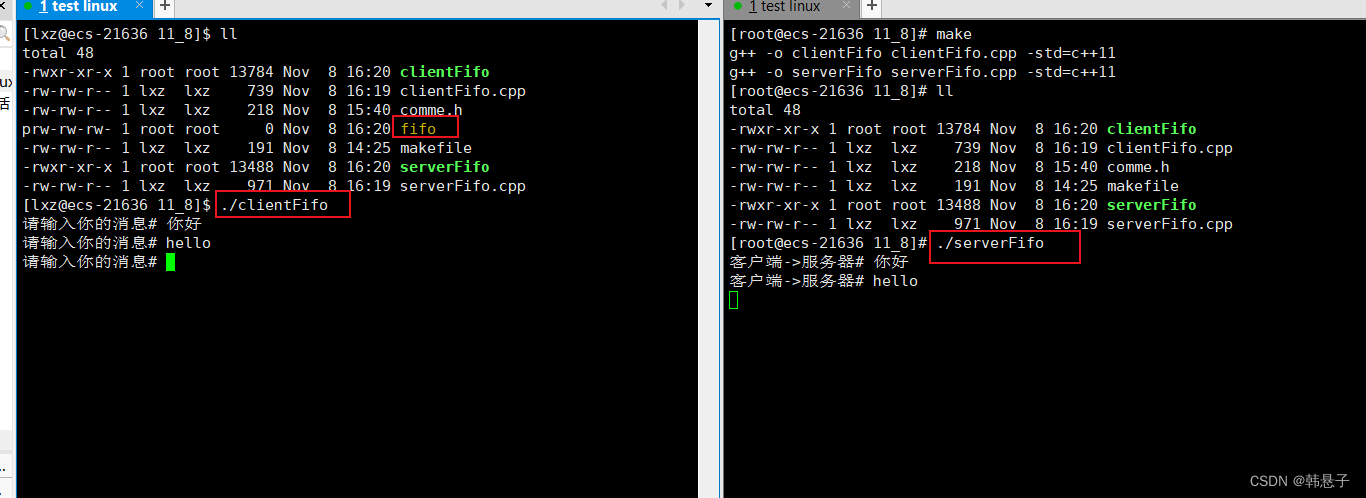
close(pipeFd); cout << "服务端退出啦" << endl; unlink(IPC_PATH);//删除文件用的- 1
- 2
- 3
这串代码用来删除文件的,删除fifo
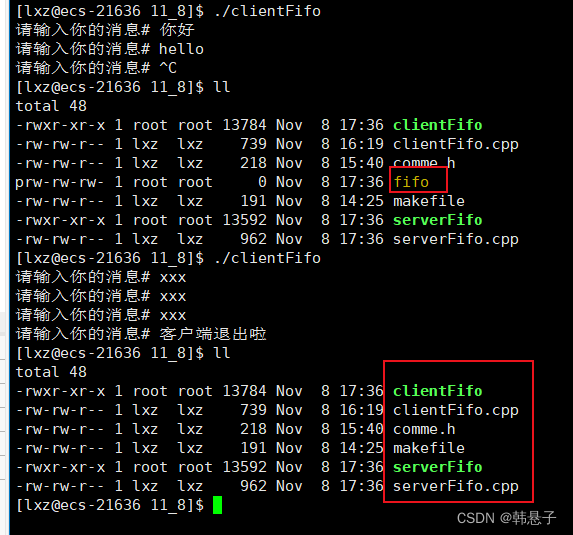
9.共享空间
1.共享空间原理
下面的图就是二个不同的进程创建二个不同的数据结构通过页表,分别占据到物理内存的空间,这个就是进程的独立性了

但是如果我们今天有特定的一种接口,第一步,可以在物理内存创建一个空间,第二步再把这个地址空间通过二个进程调用特别的接口通过页表映射到自己的进程地址空间,那么我们就可以用代码来访问它的地址了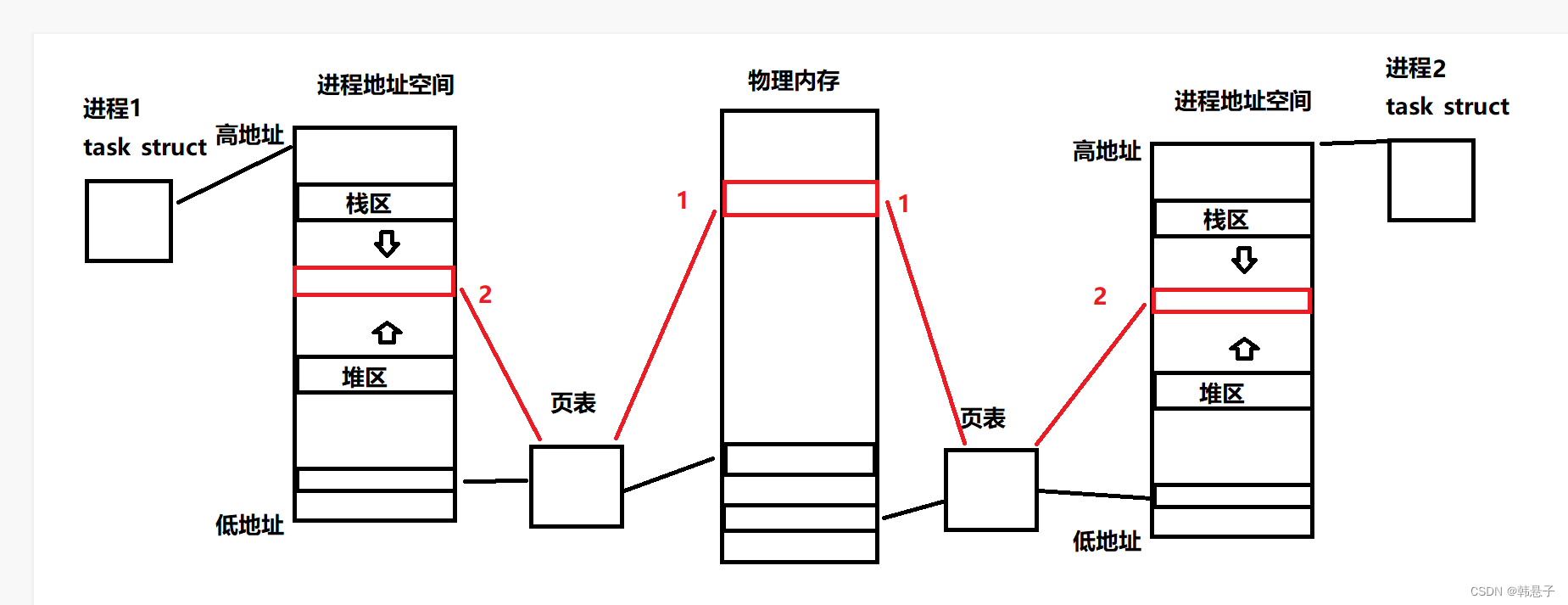

这个函数就是创建共享内存的函数,里面的的size,就是共享内存的大小,建议设置成页(4kb)的整数倍,操作系统和磁盘io的基本单位是4kb,创建共享内存就是在物理内存里面创建一个空间,4G=1,048,576页~=2^20次方那么我们要不要把这些页给管理起来,肯定是要的,先描述,在组织,所以他里面由一个struct page结构体结构体有数组struct page mem[2 ~ 20];
shmflg,他这个作用是,你要创建空间,那么你就要判断创建会不会失败,谁来创建等等下面是shmflg的几个使用宏
IPC_CREAT:创建共享内存,如果已经存在,就获取,不存在,就创建
IPC_EXCL:不单独使用,必须IPC_CREAT配合用按位或来使用,如果不存在指定的共享内存,就创建,如果已经存在了,就出错返回,它的这个作用:是可以保证你,如果shmget函数调用成功,一定是一个全新的share memorry!
那么我们能怎么确定这个共享内存的唯一性没那就是key值一般由用户提供那个的,因为进程间通信的前提是:先让不同的进程看到,同一份资源,他是用自己设定唯一key值,让二个进程约定好同时使用这个key值,他这个和匿名管道差不多,一样是约定好用同一份资源
生成唯一的key函数

它通过算法,让你二个值结合算出一个唯一值,成功返回key值,失败返回-12.怎么建立共享内存
makefile
.PHONY:all all: IpcShmCli IpcShmSer IpcShmCli:IpcShmCli.cc g++ -o $@ $^ -std=c++11 IpcShmSer:IpcShmSer.cc g++ -o $@ $^ -std=c++11 .PHONY:clean clean: rm -f IpcShmCli IpcShmSer- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Comme.hpp文件 用来获取key值 PATH_NAME你可以改成其他目录或者文件
#pragma once #include#include #include #include #include #include #define PATH_NAME "/home/lxz" #define PROJ_ID 0x14 key_t Creatakey() { key_t key =ftok(PATH_NAME,PROJ_ID); if(key<0) { std::cerr<<"ftok:" <<strerror(errno)<<std::endl; exit(1); } return key; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
IpcShmCli.cc负责使用共享内存
#include"Comme.hpp" using namespace std; int main() { key_t key = Creatakey(); cout<<"key: "<<key << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
IpcShmSer.cc负责建立共享内存
#include"Comme.hpp" using namespace std; int main() { key_t key = Creatakey(); cout<<"key: "<<key << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行一下看看是不是同一个key值

创建共享内存开始
Comme.hpp 用来获得的key值和包头文件的hpp文件#pragma once #include#include #include #include #include #include #include #define PATH_NAME "/home/lxz" #define PROJ_ID 0x14 #define MEM_SIZE 4096 key_t Creatakey() { key_t key =ftok(PATH_NAME,PROJ_ID); if(key<0) { std::cerr<<"ftok:" <<strerror(errno)<<std::endl; exit(1); } return key; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Log.hpp 用来打印的函数
#pragma once #include#include std::ostream &Log() { std::cout << "Fot Debug |" << " timestamp: " << (uint64_t)time(nullptr) << " | "; return std::cout; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
IpcShmSer.cc 下面代码写的是创建一个共享内存,但这个共享内存只能有一个
#include"Comme.hpp" #include"Log.hpp" using namespace std; // 我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; // 充当使用共享内存的角色 int main() { key_t key = Creatakey(); Log() << "key: " << key <<"\n"; int shmid = shmget(key,MEM_SIZE,flags); if(shmid<0) { Log() << "shmget: " << strerror(errno) << "\n"; return 2; } Log() << "create shm success, shmid:" << shmid <<endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行结果
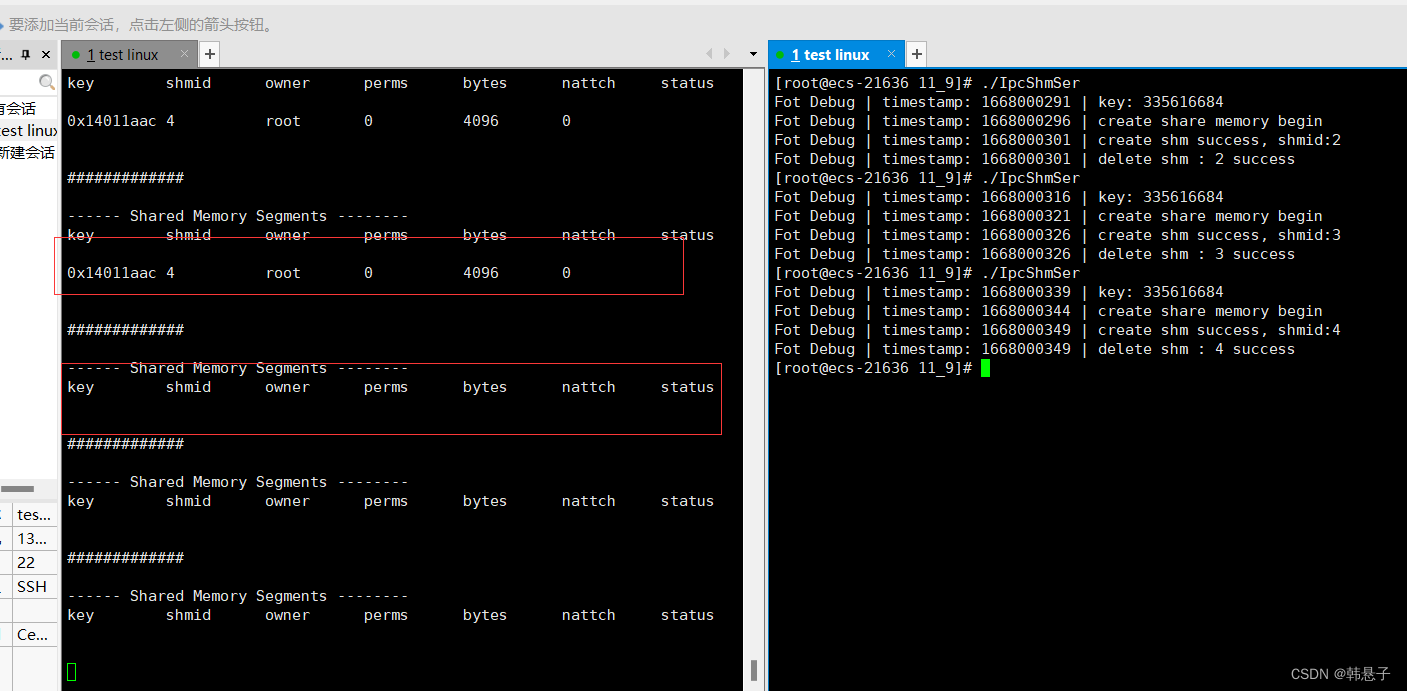
可以看到除了第一次创建成功,后面全都失败了
当我们运行完毕创建全新额共享内存代码后(进程退出),第二次(n)次打的时候,该代码无法运行,告许我们file的存在,也就是告许我们共享内存存在,system V下的共享内存是随内核的,如果不显示删除,就只能靠重启系统来解决,如果不显示删除,我怎么知道有那些资源ipcs -m- 1
可以看得到我们打的共享内存,而key不一样是因为进制不一样,我们打印的是十进制,系统的是十六进制

而删除共享内存
ipcrm -m 加上你要删除的shmid号

指令能删除,代码也能删除

shmidI 你想操作额共享内存 PC_RMID删除共享内存while :; do ipcs -m;sleep 1; echo “#############”; done监视窗口命令
代码
下面代码是五秒后创建共享进程,10秒后再删除共享进程#include"Comme.hpp" #include"Log.hpp" #includeusing namespace std; // 我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; // 充当使用共享内存的角色 int main() { key_t key = Creatakey(); Log() << "key: " << key <<"\n"; sleep(5); Log() << "create share memory begin\n"; int shmid = shmget(key,MEM_SIZE,flags); if(shmid<0) { Log() << "shmget: " << strerror(errno) << "\n"; return 2; } sleep(5); Log() << "create shm success, shmid:" << shmid <<endl; // 删它 shmctl(shmid, IPC_RMID, nullptr); Log() << "delete shm : " << shmid << " success\n"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行结果
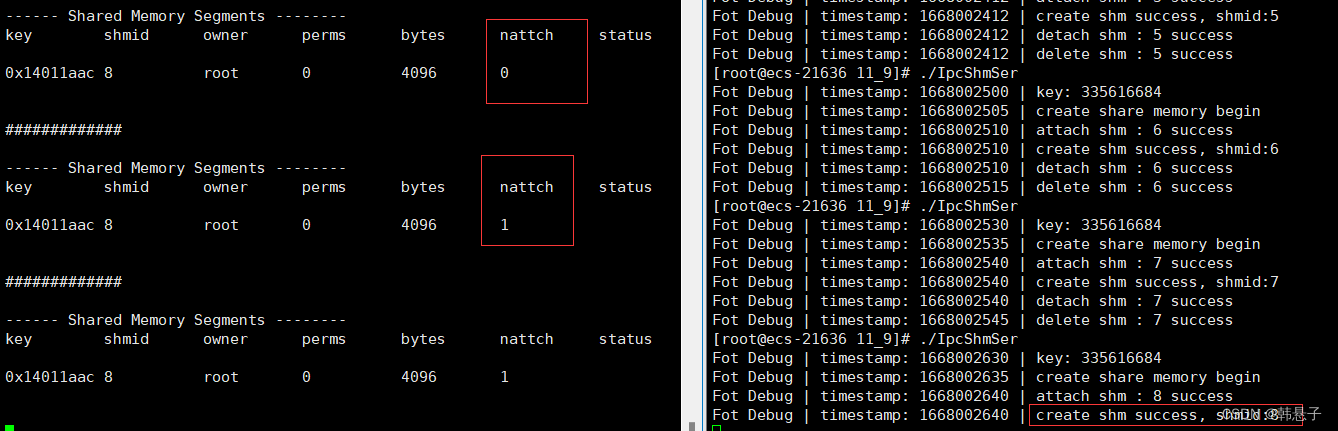
除了上面的那些还要关联,关联了过后我们就能使用这块内存了
// 1. 将共享内存和自己的进程产生关联attach char *str = (char *)shmat(shmid, nullptr, 0); Log() << "attach shm : " << shmid << " success\n";//关联提示信息- 1
- 2
- 3
除了关联还有去关联
// 2. 去关联 shmdt(str); Log() << "detach shm : " << shmid << " success\n";//去关联提示信息- 1
- 2
- 3
运行结果
nattch从0变成了1表示了关联成功,后面运行了去关联代码从1变会0,我下面就不截图了
3.怎么使用
IpcShmCli.cc文件负责使用共享内存
#include"Comme.hpp" #include"Log.hpp" #include#include using namespace std; int main() { key_t key = Creatakey(); Log() << "key: " << key << "\n"; // 获取共享内存 int shmid = shmget(key, MEM_SIZE, IPC_CREAT); if (shmid < 0) { Log() << "shmget: " << strerror(errno) << "\n"; return 2; } // 挂接 char *str = (char*)shmat(shmid, nullptr, 0); int cnt = 0; while(cnt <= 26) { str[cnt] = 'A' + cnt; ++cnt; str[cnt] = '\0'; sleep(5); } // 去关联 shmdt(str); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
上面我们是直接调用了str,没有通过任何的接口来写入,所以我们是把共享内存挂接映射到我们的进程地址空间(堆和栈之间),对每一个进程而言,挂接到自己额上下文中的共享内存,属于自己的空间,类似于栈空间或者是堆空间,可以直接被用户使用,所以我们不需要调用系统接口
那么因为他是创建在类似于栈空间或者是堆空间的地方,那么其他的文件建立挂接,一样能直接调用
在IpcShmSer.cc这个负责创建共享进程的文件里,建立挂接关系后加上这串代码
while(true) { printf("%s\n",str); sleep(1); }- 1
- 2
- 3
- 4
- 5
- 6
运行过后就可以看到,IpcShmSer.cc在打印IpcShmCli.cc发出的消息
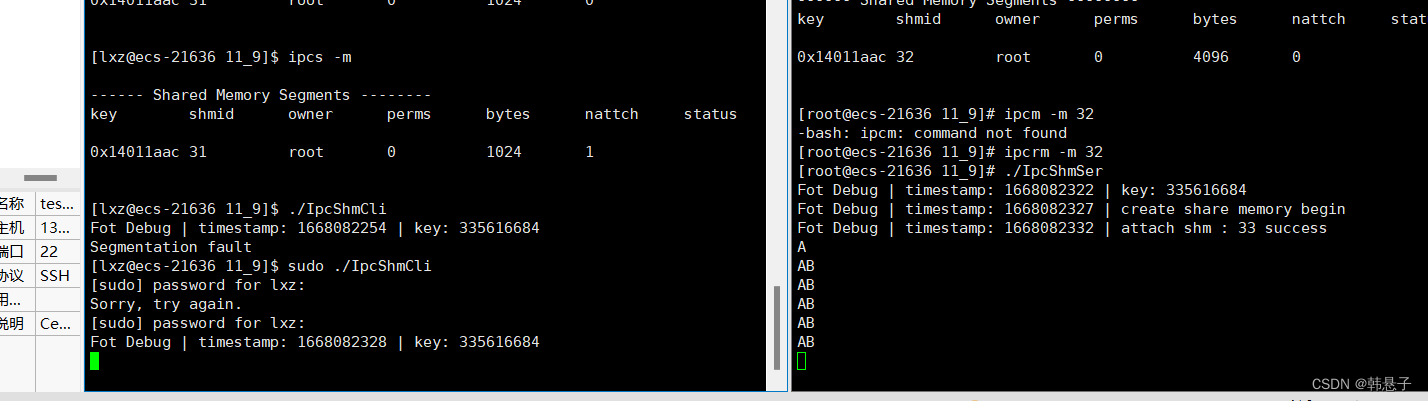
4.共享内存优缺点
优点:就是非常快,因为它可以通过系统接口把共享空间映射到我们的用户空间,一边做修改,另一边能看到这就是共享空间,是操作系统给我们提供的通信策略
缺点:就是没有访问控制 -
相关阅读:
移动端App应用
【PyTorchVideo教程01】快速实现视频动作识别
872. 最大公约数(史上最详细讲解 7种算法,STL+算法标准实现)
通过text-generation-webui部署Llama2-Chinese-7b-Chat模型时报错
Linux C/C++ 学习笔记(九):百万并发的服务器实现
Selenium 高级定位 Xpath
【牛客网刷题】VL5-VL7位拆分与运算、数据处理器、求差值
加法器:如何像搭乐高一样搭电路(上)?
Mysql 中的性能调优方法
抖 X-Bongus 参数逆向 python案例实战
- 原文地址:https://blog.csdn.net/li1829146612/article/details/127716405
