-
Active Visual Information Gathering for Vision-Language Navigation
之前的方法是不确定的(现在也有好多方法也是),也就是说,对于未知环境,agent不知道具体应该往哪走,事实上即使是人类也不知道,但是人们可以去试,获取更多的环境信息然后决定正确的导航行为。
这是我目前最欣赏的VLN论文之一,这是一篇长文,全文共24页。Active Visual Information Gathering for Vision-Language Navigation
Vision-Language Navigation)摘要: 视觉语言导航(VLN)是一项任务,要求代理在照片逼真的环境中执行导航指令。VLN中的一个关键挑战是如何通过减轻指令模糊和对环境观察不足造成的不确定性来进行稳健导航。通过当前方法训练的代理通常会遭受这种情况,因此在每一步都会努力避免随机和低效的操作。相反,当人类面临这样的挑战时,他们仍然可以通过积极探索周围环境来收集更多信息,从而做出更自信的导航决策,从而保持稳健的导航。这项工作从人类的导航行为中获得灵感,并赋予代理主动的信息收集能力,以实现更智能的视觉语言导航策略。为了实现这一点,
我们提出了一个学习探测策略的端到端框架,该框架决定i)何时何地探测,ii)在探测期间哪些信息值得收集,以及iii)探测后如何调整导航决策。实验结果表明,训练中出现了很有前途的探索策略,从而显著提高了导航性能。在R2R挑战排行榜上,我们的代理人在所有三种VLN设置(即单次运行、预探索和波束搜索)中都获得了令人满意的结果。
当遵循指令时,由于当前有限的视觉感知、指令中不可避免的模糊性以及环境的复杂性,人类并不期望每一步都是“完美”的导航决策。相反,当我们对未来的步骤不确定时,我们倾向于先探索周围的环境,收集更多的信息来缓解歧义,然后做出更明智的决定。因此,我们的核心理念是为代理人配备这种积极的探索/学习能力。
为了便于理解,我们从一个带有最简单探索功能的天真模型开始(§3.1)。然后,我们完成了§3.2和§3.3中的初始模型,并展示了学习到的主动勘探政策如何大大提高导航性能。
A Naive Model with A Simple Exploration Ability
- 每个step中,浏览所有可导航视图,然后从某个方向开始探测,收集这个方向的导航视图后返回原始的导航位置,类似地遍历所有的可导航位置并收集视觉信息。
假设在 t t h t^{th} tth step ,有K个可导航点,每个导航点又有 K ′ K^{'} K′个导航视图,表示为 O t , k = { o t , k , 1 , o t , k , 2 , … , o t , k , K ′ } \mathbf{O}_{t,k} = \{ \mathbf{o}_{t,k,1}, \mathbf{o}_{t,k,2}, \dots,\mathbf{o}_{t,k,K^{'}} \} Ot,k={ot,k,1,ot,k,2,…,ot,k,K′},
按照惯例,这个动态导航过程是以recurrent形式表示的

agent通过注意力操作收集视觉信息

用 o ^ t , k \hat{\mathbf{o}}_{t,k} o^t,k更新每个可导航视图的视觉表示,

v t , k \mathcal{v}_{t,k} vt,k之前可能只是一张图片,更新后就会包括这个节点(t,k)能探索的视觉内容。
至此,完成one-step探测,然后做出 k t h k^{th} kth导航行为的预测:

这种naive的想法显然能够有效提高准确率,但是也导致了Trajectory Length (TL)过长。Where to Explore
上面的navie的方法,更新后的 v ^ t , k \hat{\mathcal{v}}_{t,k} v^t,k太复杂,作者通过下面的方法探索(筛选)一个最valuable的方向去探索,而不是探索所有方向。


但是我觉得这违反它的本意了,因为筛选的时候没有探索 k t h k^{th} kth导航点的内容,而是原本在t点就能观察到的图。(举个栗子,在原本的位置上有两个门agent可以选择,原来的naive方法是分别进入这两个门看看,然后选择,人类也是这样做的。现在就变成了没有进门里面看,直接看门哪个更像自己要走的路.)
但是作者又说,这样不仅降低了轨迹长度,甚至还因为agent关注所谓的最valuable的方向,提高了成功率。我认为能提高的原因在于筛选了(进行了公式6),实际上我们可以将这一步改进:筛选的时候使用naive的方法,然后预测的时候还是公式7,这样筛选的才可能是更有价值的。(好吧,我大意了,后面有更深层的学习)Deeper Exploration
- 如下图,agent首先在原点选择一个探索方向,
- 然后沿着这个方向进行深度探索(multi-step)。直到找到足够的信息或者遍历完该方向的所有可导航点后,返回原点,决定是否继续选择一个新的方向探索(如果之前探索的的信息已经足够则不找新的方向了,
- 如果没找到groundtruth导航位置,则换个方向继续(换个方向属于next round))。
- 这样就能更新知识做出nextaction决策了,然后在下一个导航位置再进行类似的多步多轮探索。
- 当然,这样肯定有些节点信息重复被访问(回起点的时候,交叉节点,t+1步还会访问), 为此,作者将探索(访问)过的节点放在外部memory graph中,代理不需要真正离开他所在的位置而是根据graph想象是否需要探索,直到必要时访问没探索过的节点。

前面的探测只能够探测当前的位置的相邻导航视图,而大多的必要情况,我们可能需要更深度地多探测几步。
作者设计了一个基于循环网络的探测模块,在探索步骤s,从 K ′ K^{'} K′处收集信息 Y t , k , s = { y t , k , s , 1 , y t , k , s , 1 , … , y t , k , s , 1 , } \mathbf{Y}_{t,k,s} = \{\mathbf{y}_{t,k,s,1}, \mathbf{y}_{t,k,s,1},\dots, \mathbf{y}_{t,k,s,1},\} Yt,k,s={yt,k,s,1,yt,k,s,1,…,yt,k,s,1,} .因此 Y t , k , 0 = V t \mathbf{Y}_{t,k,0}= \mathbf{V}_t Yt,k,0=Vt, O t , k = Y t , k , 1 \mathbf{O}_{t,k}=\mathbf{Y}_{t,k,1} Ot,k=Yt,k,1。也就是说,s=0是在t步能够看到的可导航节点(深度第一层,把当前位置看为第0层的话,同理,s=1表示第二层深度),
- Knowledge Collection During Exploration
代理通过注意力机制主动收集周围环境信息 Y s \mathbf{Y}_s Ys:
y ^ s = a t t ( Y s , h v e p ) \hat{y}_s=att(\mathbf{Y}_s, \mathbf{h}^{ep}_{v}) y^s=att(Ys,hvep),
回顾一下,其中 h t e p = L S T M ( [ X , V t − 1 , a t − 1 e p ] , h t − 1 e p ) h^{ep}_t = LSTM([\mathbf{X, \mathbf{V}_{t-1}}, \mathbf{a}^{ep}_{t-1}], \mathbf{h}^{ep}_{t-1}) htep=LSTM([X,Vt−1,at−1ep],ht−1ep)
- Knowledge Storage During Exploration:
学习到的视觉知识 y ^ s \hat{\mathbf{y}}_s y^s 存储在记忆网络中: h s k w = L S T M k w ( y ^ s , h s − 1 k w ) \mathbf{h}^{kw}_{s} = LSTM^{kw}(\hat{\mathbf{y}}_s, \mathbf{h}^{kw}_{s-1}) hskw=LSTMkw(y^s,hs−1kw) 用来支持做出导航决策
- Sequential Exploration-Decision Making for Multi-Step Exploration:
接下来,代理人需要决定是否选择新的方向进行进一步探索。
在探索动作空间中,代理人从当前K0可到达的视图中选择一个方向进行探索,或者停止当前探索情节并返回第t个导航步骤的原始位置。Y s = { y s , 1 , y s , 2 , … , y s , K ′ } \mathbf{Y}_s = \{\mathbf{y}_{s,1}, \mathbf{y}_{s,2}, \dots,\mathbf{y}_{s,K^{'}} \} Ys={ys,1,ys,2,…,ys,K′}, stop编码为 y s , K ′ + 1 = 0 \mathbf{y}_{s, K^{'}+1} = \mathbf{0} ys,K′+1=0. $\mathbf{y}_{s,K^{'}} $也就是第s-1层的第 K ′ K^{'} K′个导航点的环境信息。
当前的探索状态 h s e p = L S T M e p ( [ h t n v , Y s − 1 , a s − 1 e p ] , h s − 1 e p ) \mathbf{h}^{ep}_{s} = LSTM^{ep}([\mathbf{h}^{nv}_{t},\mathbf{Y}_{s-1},\mathbf{a}^{ep}_{s-1}], \mathbf{h}^{ep}_{s-1}) hsep=LSTMep([htnv,Ys−1,as−1ep],hs−1ep)
对于第 k ′ t h k^{'th} k′th个探索动作候选(可到达的view),其概率为

- Multi-Round Exploration-Decision Making for Multi-Direction Exploration:
S步之后,当agent认为在某个方向k收集足够的信息时,应stop。 回到第t个导航step的起点,更新第k个方向上的视觉知识:

然后做出第二轮的探索决定,

k u k^{u} ku表示还没选择的探索动作,新的一轮将在另一个方向上探索直到选择 s t o p stop stop- Exploration-Assisted Navigation-Decision Making:
经过多轮多步探索,利用关于周围环境的最新知识~Vt,代理做出更可靠的导航决策(等式5): p t , k n v = s o f t m a x k ( v ^ t , k T W n v h t n v ) p^{nv}_{t,k} = softmax_k(\hat{\mathbf{v}}_{t,k}^{T} \mathbf{W}^{nv}\mathbf{h}^{nv}_{t}) pt,knv=softmaxk(v^t,kTWnvhtnv)。
然后,在第(t+1)个导航步骤,代理在多个方向上进行多步探索(甚至可以省略探索),然后选择新的导航动作
- Memory based Late Action-Taking Strategy:
当agent在某个方向探索结束时,如果
Training
Imitation Learning (IL)


Reinforcement Learning (RL)
3米内停止则

纳入行动对未来的影响,并解释局部贪婪的搜索
R t n v = ∑ t ′ = t T γ t ′ − t r n v ( v t ′ , a t ′ n v ) R^{nv}_t = \sum^T_{t^{'}=t} \gamma^{t^{'}-t} r^{nv}(v_{t^{'}},a^{nv}_{t^{'}}) Rtnv=∑t′=tTγt′−trnv(vt′,at′nv),
其中,discounted factor γ \gamma γ=0.9

r e p ( v t , { a t , k , s e p } ) = 1 S t , k r e p ( v t , { a t , k , s e p } s ) r^{ep}(v_t,\{a^{ep}_{t,k,s}\})= \frac{1}{S_{t,k}} r^{ep}(v_t,\{a^{ep}_{t,k,s}\}_s) rep(vt,{at,k,sep})=St,k1rep(vt,{at,k,sep}s)
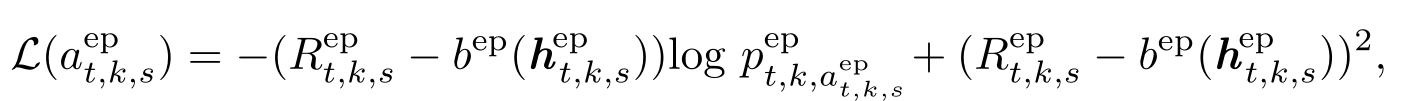

Curriculum Learning for Multi-Step Exploration
在训练过程中,我们发现,一旦更新了探索策略,模型很容易受到所收集信息的极端变化的影响,特别是对于长期探索,这使得训练变得不稳定。为了避免这种情况,我们采用课程学习[4]来训练我们的代理人,并逐步提高探索长度。具体地说,在开始时,最大探索长度被设置为1。在训练损失收敛后,我们使用当前参数以最多两步探索来初始化代理的训练。通过这种方式,我们训练一个代理,最多进行6步探索(由于GPU内存和时间有限)。该策略Active
Vision Language Navigation 11大大提高了收敛速度(大约快8×Back Translation Based Training Data Augmentation
我们使用反向翻译来增加训练数据。基本思想是,除了训练根据给定指令在环境中找到正确路线的导航员之外,还训练辅助说话者生成给定环境内路线的指令。通过这种方式,我们为房间到房间[1]训练环境中的176k条未标记路线生成了额外的指令。在从Room to Room训练集中对代理进行标记样本训练后,我们使用反向翻译增强数据进行微调。

实验
仅R2R数据集上的结果
- Single Run Setting:
这是R2R中的基本设置,代理通过以循序渐进、贪婪的方式选择操作来进行导航。代理不允许:1)运行多个测试,2)在开始之前探索或映射测试环境。表1报告了在这种设置下的比较结果。以下是一些基本观察结果。i) 我们的代理商在主要指标SR和一些其他标准(如NE和OR)方面优于其他竞争对手。例如,在SR方面,我们的模型分别在验证未发现集和测试未发现集上提高了AuxRN[28]3%和5%,证明了我们的强泛化性。ii)我们没有数据增强的代理已经在SR和NE上优于许多现有方法
-
Pre-Explore Setting
允许代理在进行导航之前预先探索看不见的环境 -
Beam Search Setting:
Beam search 最初在[7]中用于优化SR度量。给定一条指令,允许代理收集多条候选路线进行评分并选择最佳路线[11]。在[7,20]之后,我们使用演讲者来估计候选路线,并选择最佳路线作为最终结果。如表2所示,我们的性能优于以前的方法




-
相关阅读:
SpringBoot介绍
信息时代下,法律行业如何进行互联网推广
u盘无法复制过大文件怎么解决?揭秘!
C++后台面试题汇总---持续更新中
Android 蓝牙 OPP文件传输-Obex协议连接-socket连接 从framework到协议栈btif层 --- 全网最详细(一)
java 工程管理系统源码+项目说明+功能描述+前后端分离 + 二次开发
全网最全!!Qt实现图片旋转及图片旋转动画的几种方式
大数据技术之Zookeeper总结Ⅰ
Apache HTTPD (CVE-2017-15715)换行解析漏洞复现
SystemVerilog Assertions应用指南 Chapter 11.5SVA检验器的时序窗口
- 原文地址:https://blog.csdn.net/weixin_45347379/article/details/127784017