-
trick1-注意力机制使用
前言
使用注意力机制:se_block, cbam_block, eca_block, CA_Block
一、注意力机制attention.py构建
在YOLO系列nets里面创建一个注意力机制模块,即attention.py,包括四种注意力,分别是:se_block, cbam_block, eca_block, CA_Block
import torch import torch.nn as nn import math # 定义SE类(SE的全局平均池化是对宽高进行1x1xc) class se_block(nn.Module): # 传入输入通道数 比例因子ratio(第一次比例因子比较小) def __init__(self, channel, ratio=16): # 初始化 super(se_block, self).__init__() # 在高宽上进行全局平均池化 把输出高宽设置为1 self.avg_pool = nn.AdaptiveAvgPool2d(1) # 通过nn.Sequential把两次全连接+激活函数完成 # 第一次神经元个数较少的全连接 输入通道数是channel->channel/ratio # 激活函数 # 第二次全连接 输入通道数是channel/ratio->channel # 激活函数 把值固定在0-1之间 self.fc = nn.Sequential( nn.Linear(channel, channel // ratio, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // ratio, channel, bias=False), nn.Sigmoid() ) # 前向传播 def forward(self, x): # batchsize channel height width b, c, _, _ = x.size() # 通过全局平均池化 b c h w->b c 1 1 # 再通过.view变成 b c # 即由 b c h w->b c 1 1->b c y = self.avg_pool(x).view(b, c) # 最后进行两次全连接 # 再次通过.view变成b c 1 1 # 即由 b c->b c/ratio->b c 1 1 y = self.fc(y).view(b, c, 1, 1) # 将全连接的结构乘上输入特征层 return x * y # 定义CBAM类的通道注意力(CBAM的通道注意力的全局平均池化和全局最大平均池化是对宽高进行1x1xc) class ChannelAttention(nn.Module): # 传入输入通道数 比例因子ratio(第一次比例因子比较小) def __init__(self, in_planes, ratio=8): # 初始化 super(ChannelAttention, self).__init__() # 在高宽上进行全局平均池化 把输出高宽设置为1 # 在高宽上进行全局最大池化 把输出高宽设置为1 self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) # 通过两次全连接 第一次输出通道较少 第二层较多 利用1x1卷积代替全连接,类似于SE模块 self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) self.relu1 = nn.ReLU() self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, x): # 先进行全局平均池化和全局最大池化 # 再对池化后的结果使用共享的2次全连接层进行处理 # 再对共享之后的结果进行相加最后再通过sigmoid激活函数 avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x)))) max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x)))) out = avg_out + max_out return self.sigmoid(out) # 定义CBAM类的空间注意力(CBAM的空间注意力的全局平均池化和全局最大平均池化是对通道进行hxwx1 hxwx1) class SpatialAttention(nn.Module): # 传入卷积核大小 def __init__(self, kernel_size=7): # 初始化 super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 # 通过7x7卷积 # 再通过sigmoid激活函数 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, x): # 在通道上进行最大池化和平均池化 # 再进行堆叠(通道上) # 堆叠后的结果卷积最后进行sigmoid avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x) # 定义CBAM类的注意力+空间注意力 class cbam_block(nn.Module): # 传入输入通道数 比例因子ratio(第一次比例因子比较小) 传入卷积核大小 def __init__(self, channel, ratio=8, kernel_size=7): # 初始化 super(cbam_block, self).__init__() # 定义通道注意力机制和空间注意力机制 self.channelattention = ChannelAttention(channel, ratio=ratio) self.spatialattention = SpatialAttention(kernel_size=kernel_size) # 前向传播 def forward(self, x): x = x*self.channelattention(x) x = x*self.spatialattention(x) return x # 定义ECA类 class eca_block(nn.Module): # 传入通道数 参数 def __init__(self, channel, b=1, gamma=2): # 初始化 super(eca_block, self).__init__() # 根据输入通道数自适应的进行卷积核大小计算 kernel_size = int(abs((math.log(channel, 2) + b) / gamma)) kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1 # 在高宽上进行全局平均池化 把输出高宽设置为1 self.avg_pool = nn.AdaptiveAvgPool2d(1) # 输入 输出通道是1 self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False) # 激活函数 self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, x): # 先进性全局平局池化 # 再进行卷积和激活函数 y = self.avg_pool(x) y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) y = self.sigmoid(y) return x * y.expand_as(x) class CA_Block(nn.Module): def __init__(self, channel, reduction=16): super(CA_Block, self).__init__() self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel//reduction, kernel_size=1, stride=1, bias=False) self.relu = nn.ReLU() self.bn = nn.BatchNorm2d(channel//reduction) self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False) self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False) self.sigmoid_h = nn.Sigmoid() self.sigmoid_w = nn.Sigmoid() def forward(self, x): _, _, h, w = x.size() x_h = torch.mean(x, dim = 3, keepdim = True).permute(0, 1, 3, 2) x_w = torch.mean(x, dim = 2, keepdim = True) x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3)))) x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3) s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2))) s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w)) out = x * s_h.expand_as(x) * s_w.expand_as(x) return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
二、在yolo.py中使用注意力机制
1.引入库
代码如下(示例):
from nets.attention import cbam_block, eca_block, se_block, CA_Block attention_block = [se_block, cbam_block, eca_block, CA_Block]- 1
- 2
- 3
2.在YoloBody中传入参数,具体使用哪一个注意力机制(phi=0默认不使用注意力机制)
代码如下(示例):
def __init__(self, anchors_mask, num_classes, phi=0, pretrained=False):- 1
3.添加注意力机制
class YoloBody(nn.Module): def __init__(self, anchors_mask, num_classes, phi=0, pretrained=False): super(YoloBody, self).__init__() self.phi = phi#定义phi变量 self.backbone = darknet53_tiny(pretrained) self.conv_for_P5 = BasicConv(512,256,1) self.yolo_headP5 = yolo_head([512, len(anchors_mask[0]) * (5 + num_classes)],256) self.upsample = Upsample(256,128) self.yolo_headP4 = yolo_head([256, len(anchors_mask[1]) * (5 + num_classes)],384) if 1 <= self.phi and self.phi <= 4: self.feat1_att = attention_block[self.phi - 1](256)#phi=1,senet(括号里面是通道数) self.feat2_att = attention_block[self.phi - 1](512)#phi=2,cbam self.upsample_att = attention_block[self.phi - 1](128)#phi=3,eca def forward(self, x): #---------------------------------------------------# # 生成CSPdarknet53_tiny的主干模型 # feat1的shape为26,26,256 # feat2的shape为13,13,512 #---------------------------------------------------# feat1, feat2 = self.backbone(x) if 1 <= self.phi and self.phi <= 4:添加注意力机制 feat1 = self.feat1_att(feat1) feat2 = self.feat2_att(feat2) # 13,13,512 -> 13,13,256 P5 = self.conv_for_P5(feat2) # 13,13,256 -> 13,13,512 -> 13,13,255 out0 = self.yolo_headP5(P5) # 13,13,256 -> 13,13,128 -> 26,26,128 P5_Upsample = self.upsample(P5) # 26,26,256 + 26,26,128 -> 26,26,384 if 1 <= self.phi and self.phi <= 4:#添加注意力机制 P5_Upsample = self.upsample_att(P5_Upsample) P4 = torch.cat([P5_Upsample,feat1],axis=1) # 26,26,384 -> 26,26,256 -> 26,26,255 out1 = self.yolo_headP4(P4) return out0, out1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
总结
注意力机制即插即用,导入库函数,然后定义变量并且传入注意力变量(默认不使用注意力机制),最后在需要传入的地方传入注意力机制即可,只需要知道使用注意力机制的通道数即可,博主建议不要把注意力机制添加到主干当中,添加到主干之后的加强特征提取网络部分会比在主干效果好一点,另外,使用上述方法添加注意力机制之后,比如在使用get_map.py,训练train.py,yolo.py,或者在看网络结构summary.py之前,也需要在yolo.py(nets文件夹之外的)里面添加phi选项进行选择。
1.train.py:
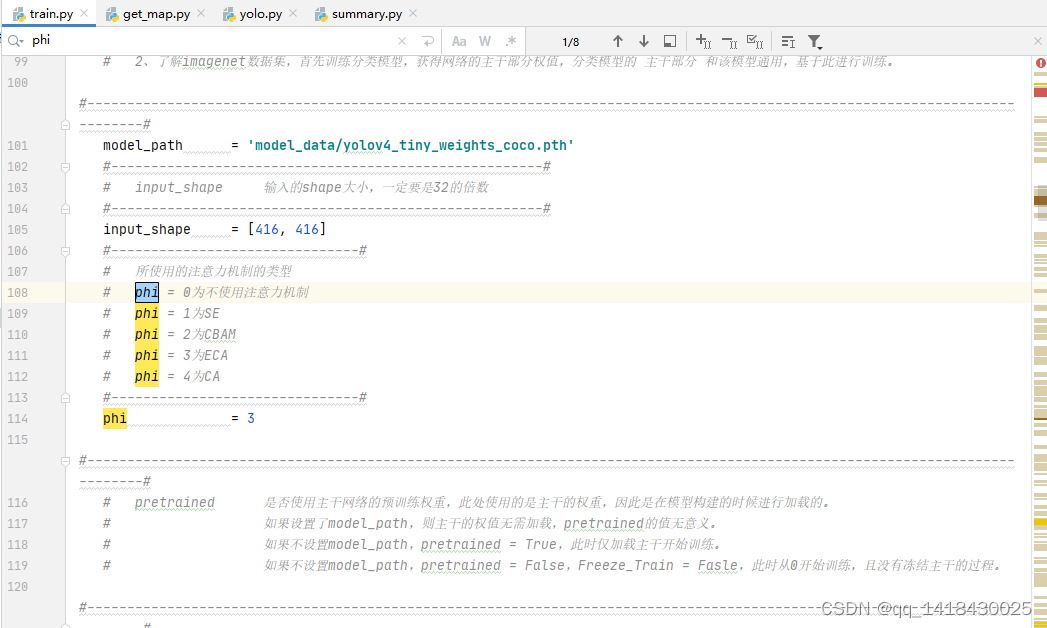
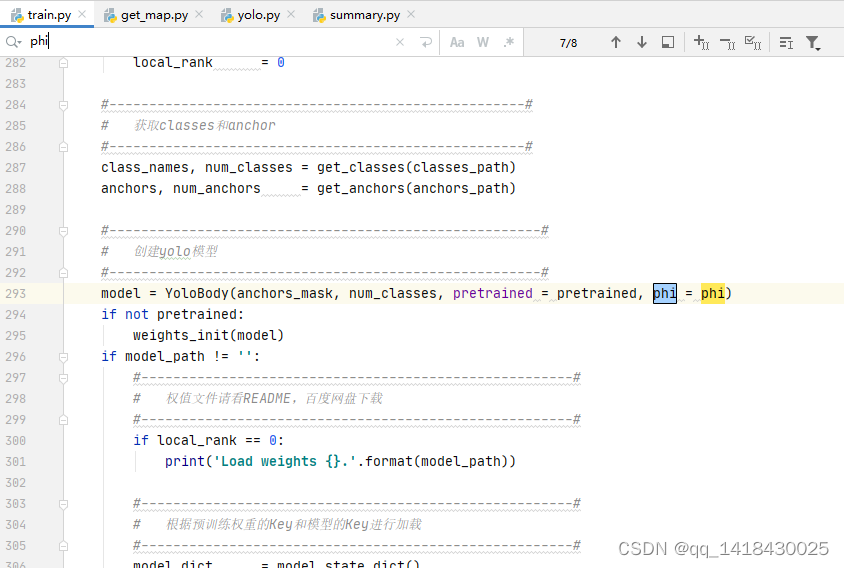
2.yolo.py:
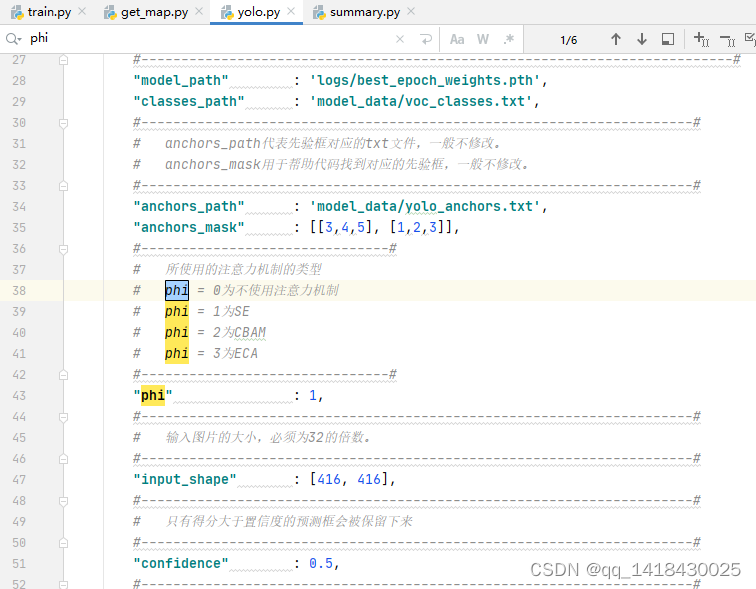
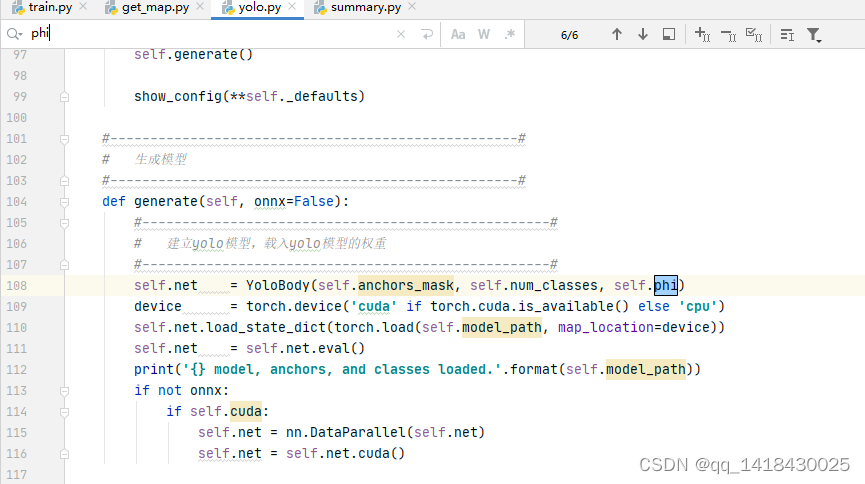
3.summary.py:
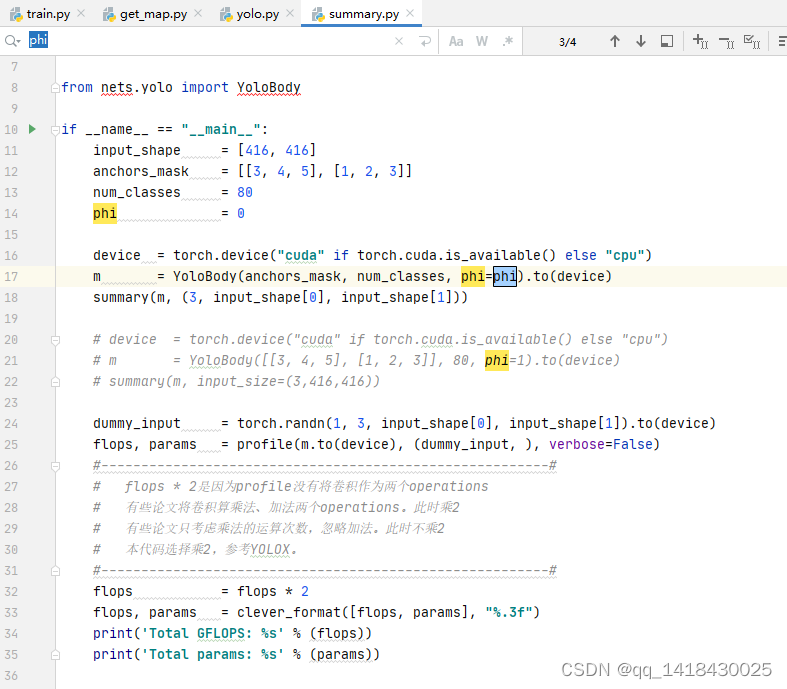
-
相关阅读:
Flutter笔记:序列化与反序列化
Linux上安装jdk 1.8
SQL语言概述与SQL语言的数据定义
Android泛型详解
【虚幻引擎UE】UE4/UE5 环境构建插件推荐及使用介绍
构建网站遇到的一些问题(浏览器缓存问题)
【介绍下WebStorm开发插件】
Spring Boot异步请求处理框架
SQL中的字符串截取函数
java计算机毕业设计医院病历管理系统源程序+mysql+系统+lw文档+远程调试
- 原文地址:https://blog.csdn.net/qq_45825952/article/details/127792534