-
Karmada大规模测试报告发布:突破100倍集群规模
成员集群中的 karmada-agent 消耗了 40m CPU(cores)和 266Mi Memory(bytes)。
摘要:在本文中,我们将介绍用于测试的相关指标,如何进行大规模测试,以及我们如何实现大规模的集群接入。本文分享自华为云社区《突破100倍集群规模!Karmada大规模测试报告发布》,作者:华为云云原生团队。
摘要
随着云原生技术在越来越多的企业和组织中的大规模落地,如何高效、可靠地管理大规模资源池以应对不断增长的业务挑战成为了当下云原生技术的关键挑战。在过去的很长一段时间内,不同厂商尝试通过定制Kubernetes原生组件的方式扩展单集群的规模,这在提高规模的同时也引入了复杂的单集群运维、不清晰的集群升级路径等问题。而多集群技术能在不侵入修改Kubernetes单集群的基础上横向扩展资源池的规模,在扩展资源池的同时降低了企业的运维管理等成本。
在Karmada的大规模落地进程中,Karmada的可扩展性和大规模逐渐成为社区用户的新关注点。因此,我们对Karmada开展了大规模环境下的测试工作,以获取Karmada管理多个Kubernetes集群的性能基线指标。对于以Karmada为代表的多集群系统而言,单集群的规模不是制约它的资源池规模的限制因素。因此,我们参考了Kubernetes的大规模集群的标准配置和用户的生产落地实践,测试了Karmada同时管理100个5k节点和2wPod的Kubernetes集群的用户场景。受限于测试环境和测试工具,本次测试并未追求测试到Karmada多集群系统的上限,而是希望能覆盖到在生产中大规模使用多集群技术的典型场景。根据测试结果分析,以Karmada为核心的集群联邦可以稳定支持100个大规模集群,管理超过50万个节点和200万个Pod,可以满足用户在大规模生产落地的需要。
在本文中,我们将介绍用于测试的相关指标,如何进行大规模测试,以及我们如何实现大规模的集群接入。
背景
随着云原生技术的不断发展和使用场景的不断丰富,多云、分布式云逐渐成为引领云计算发展的趋势。著名分析公司 Flexera 在 2021 的调查报告显示,超过 93%的企业正同时使用多个云厂商的服务,一方面受限于 Kubernetes 单集群的业务承载能力和故障恢复能力,单一的集群无法适应现有的企业业务,另一方面,在全球化的当下,企业出于避免被单家厂商垄断的目的,或是出于成本等因素考虑,更倾向于选择混合云或者多公有云的架构。与此同时,Karmada 社区的用户在落地的进程中也提出了多集群下大规模节点和应用管理的诉求。
Karmada 介绍
Karmada(Kubernetes Armada)是一个 Kubernetes 管理系统,它能够使你在无需修改应用的情况下跨集群和跨云运行你的云原生应用。通过使用 Kubernetes 原生 API 并在其上提供高级调度功能,Karmada 实现了真正开放的多云 Kubernetes。
Karmada 旨在为多云和混合云场景中的多集群应用管理提供完全的自动化。它具备集中式多云管理、高可用性、故障恢复和流量调度等关键特性。
Karmada 控制面包括以下组件:
- Karmada API Server
- Karmada Controller Manager
- Karmada Scheduler
ETCD 存储了 Karmada 的 API 对象, karmada-apiserver 提供了与所有其他组件通信的 REST 端口, 之后由 karmada-controller-manager 对你向 karmada-apiserver 提交的 API 对象进行对应的调和操作。
karmada-controller-manager 运行着各种控制器,这些控制器 watch 着 Karmada 的对象,然后发送请求至成员集群的 apiserver 来创建常规的 Kubernetes 资源。
多集群系统资源池规模的维度和阈值
一个多集群系统的资源池规模不单指集群数量,即Scalability!=#Num of Clusters, 实际上多集群资源池规模包含很多维度的测量,在不考虑其他维度的情况下只考虑集群数量是毫无意义的。
我们将一个多集群的资源池规模按优先级描述为以下所示的三个维度:
- Num of Clusters: 集群数量是衡量一个多集群系统资源池规模和承载能力最直接且最重要的维度,在其余维度不变的情况下系统能接入的集群数量越多,说明系统的资源池规模越大,承载能力越强。
- Num of Resources(API Objects): 对于一个多集群系统的控制面来说,存储并不是无限制的,而在控制面创建的资源对象的数量和总体大小受限于系统控制面的存储,也是制约多集群系统资源池规模的重要维度。这里的资源对象不仅指下发到成员集群的资源模板,而且还包括集群的调度策略、多集群服务等资源。
- Cluster Size: 集群规模是衡量一个多集群系统资源池规模不可忽视的维度。一方面,集群数量相等的情况下,单个集群的规模越大,整个多集群系统的资源池越大。另一方面,多集群系统的上层能力依赖系统对集群的资源画像,例如在多集群应用的调度过程中,集群资源是不可或缺的一个因素。综上所述,单集群的规模与整个多集群系统息息相关,但单集群的规模同样不是制约多集群系统的限制因素。用户可以通过优化原生的Kubernetes组件的方式来提升单集群的集群规模,达到扩大整个多集群系统的资源池的目的,但这不是衡量多集群系统性能的关注点。本次测试中,社区参考了kubernetes的大规模集群的标准配置以及测试工具的性能,制定了测试集群的规模,以贴切实际生产环境中的单集群配置。在集群的标准配置中,Node与Pod毫无疑问是其中最重要的两个资源,Node是计算、存储等资源的最小载体,而Pod数量则代表着一个集群的应用承载能力。事实上,单集群的资源对象也包括像service,configmap,secret这样的常见资源。这些变量的引入会使得测试过程变得更复杂,所以这次测试不会过多关注这些变量。
- Num of Nodes
- Num of Pods
对于多集群系统而言想要无限制地扩展各个维度而且又满足 SLIs/SLOs 各项指标显然是不可能实现的。各个维度不是完全独立的,某个维度被拉伸相应的其他维度就要被压缩,可以根据使用场景进行调整。以 Clusters 和 Nodes 两个维度举例,在 100 集群下将单集群的 5k 节点拉伸到 10k node 的场景或者在单集群规格不变的同时扩展集群数量到 200 集群,其他维度的规格势必会受到影响。如果各种场景都进行测试分析工作量是非常巨大的,在本次测试中,我们会重点选取典型场景配置进行测试分析。在满足 SLIs/SLOs 的基础上,实现单集群支持 5k 节点,20k pod规模的100数量的集群接入和管理。
SLIs/SLOs
可扩展性和性能是多集群联邦的重要特性。作为多集群联邦的用户,我们期望在以上两方面有服务质量的保证。在进行大规模性能测试之前,我们需要定义测量指标。在参考了 Kubernetes 社区的 SLI(Service Level Indicator)/SLO(Service Level Objectives)和多集群的典型应用,Karmada 社区定义了以下 SLI/SLO 来衡量多集群联邦的服务质量。
- API Call Latency

- Resource Distribution Latency

- Cluster Registration Latency

- Resource usage

Note:
- 上述指标不考虑控制面和成员集群的网络波动。同时,单集群内的 SLO 不会考虑在内。
- 资源使用量是一个对于多集群系统非常重要的指标,但是不同多集群系统提供的上层服务不同,所以对各个系统来说资源的要求也会不同。我们不对这个指标进行强制的限制。
- 集群注册时延是从集群注册到控制面到集群在联邦侧可用的时延。它在某种程度上取决于控制面如何收集成员集群的状态。
测试工具
ClusterLoader2
ClusterLoader2 是一款开源 Kubernetes 集群负载测试工具,该工具能够针对 Kubernetes 定义的 SLIs/SLOs 指标进行测试,检验集群是否符合各项服务质量标准。此外 ClusterLoader2 为集群问题定位和集群性能优化提供可视化数据。ClusterLoader2 最终会输出一份 Kubernetes 集群性能报告,展示一系列性能指标测试结果。然而,在 Karmada 性能测试的过程中,由于 ClusterLoader2 是一个为 Kubernetes 单集群定制的测试工具,且在多集群场景下它不能获取到所有集群的资源, 因此我们只用 ClusterLoader2 来分发被 Karmada 管理的资源。
Prometheus
Prometheus 是一个开源的用于监控和告警的工具, 它包含数据收集、数据报告、数据可视化等功能。在分析了 Clusterloader2 对各种监控指标的处理后,我们使用 Prometheus 根据具体的查询语句对控制面的指标进行监控。
Kind
Kind 是一个是用容器来运行 Kubernetes 本地集群的工具。为了测试 Karmada 的应用分发能力,我们需要一个真实的单集群控制面来管理被联邦控制面分发的应用。Kind 能够在节约资源的同时模拟一个真实的集群。
Fake-kubelet
Fake-kubelet 是一个能模拟节点且能维护虚拟节点上的 Pod 的工具。与 Kubemark 相比,fake-kubelet 只做维护节点和 Pod 的必要工作。它非常适合模拟大规模的节点和 Pod 来测试控制面的在大规模环境下的性能。
测试集群部署方案
Kubernetes 控制面部署在单 master 的节点上。etcd,kube-apiserver,kube-scheduler 和 kube-controller 以单实例的形式部署。Karmada 的控制面组件部署在这个 master 节点上。他们同样以单实例的形式部署。所有的 Kubernetes 组件和 Karmada 组件运行在高性能的节点上,且我们不对他们限制资源。我们通过 kind 来模拟单 master 节点的集群,通过 fake-kubelet 来模拟集群中的工作节点。
测试环境信息
控制面操作系统版本
Ubuntu 18.04.6 LTS (Bionic Beaver)
Kubernetes 版本
Kubernetes v1.23.10
Karmada 版本
Karmada v1.3.0-4-g1f13ad97
Karmada 控制面所在的节点配置
- CPU
- Architecture: x86_64
- CPU op-mode(s): 32-bit, 64-bit
- Byte Order: Little Endian
- CPU(s): 64
- On-line CPU(s) list: 0-63
- Thread(s) per core: 2
- Core(s) per socket: 16
- Socket(s): 2
- NUMA node(s): 2
- Vendor ID: GenuineIntel
- CPU family: 6
- Model: 85
- Model name: Intel(R) Xeon(R) Gold 6266C CPU @ 3.00GHz
- Stepping: 7
- CPU MHz: 3000.000
- BogoMIPS: 6000.00
- Hypervisor vendor: KVM
- Virtualization type: full
- L1d cache: 32K
- L1i cache: 32K
- L2 cache: 1024K
- L3 cache: 30976K
- NUMA node0 CPU(s): 0-31
- NUMA node1 CPU(s): 32-63
- 内存
Maximum Capacity: 512 GB- 磁盘
Disk /dev/vda: 200 GiB, 214748364800 bytes, 419430400 sectors组件参数配置
- karmada-apiserver
- --max-requests-inflight=2000
- --max-mutating-requests-inflight=1000
- karmada-aggregated-server
- --kube-api-qps=200
- --kube-api-burst=400
- karmada-scheduler
- --kube-api-qps=200
- --kube-api-burst=400
- karmada-controller-manager
- --kube-api-qps=200
- --kube-api-burst=400
- karmada-agent
- --kube-api-qps=40
- --kube-api-burst=60
- karmada-etcd
--quota-backend-bytes=8G测试执行
在使用 Clusterloader2 进行性能测试之前,我们需要自己通过配置文件定义性能测试策略。我们使用的配置文件如下:
unfold me to see the yaml
- name: test
- namespace:
- number: 10
- tuningSets:
- - name: Uniformtinyqps
- qpsLoad:
- qps: 0.1
- - name: Uniform1qps
- qpsLoad:
- qps: 1
- steps:
- - name: Create deployment
- phases:
- - namespaceRange:
- min: 1
- max: 10
- replicasPerNamespace: 20
- tuningSet: Uniformtinyqps
- objectBundle:
- - basename: test-deployment
- objectTemplatePath: "deployment.yaml"
- templateFillMap:
- Replicas: 1000
- - namespaceRange:
- min: 1
- max: 10
- replicasPerNamespace: 1
- tuningSet: Uniform1qps
- objectBundle:
- - basename: test-policy
- objectTemplatePath: "policy.yaml"
- # deployment.yaml
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: {{.Name}}
- labels:
- group: test-deployment
- spec:
- replicas: {{.Replicas}}
- selector:
- matchLabels:
- app: fake-pod
- template:
- metadata:
- labels:
- app: fake-pod
- spec:
- affinity:
- nodeAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- nodeSelectorTerms:
- - matchExpressions:
- - key: type
- operator: In
- values:
- - fake-kubelet
- tolerations:
- - key: "fake-kubelet/provider"
- operator: "Exists"
- effect: "NoSchedule"
- containers:
- - image: fake-pod
- name: {{.Name}}
- # policy.yaml
- apiVersion: policy.karmada.io/v1alpha1
- kind: PropagationPolicy
- metadata:
- name: test
- spec:
- resourceSelectors:
- - apiVersion: apps/v1
- kind: Deployment
- placement:
- replicaScheduling:
- replicaDivisionPreference: Weighted
- replicaSchedulingType: Divided
Kubernetes 资源详细的配置如下表所示:

详细的测试方法和过程,可以参考
https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md[1]
测试结果
APIResponsivenessPrometheus:

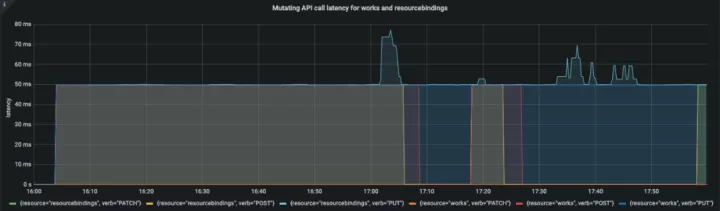
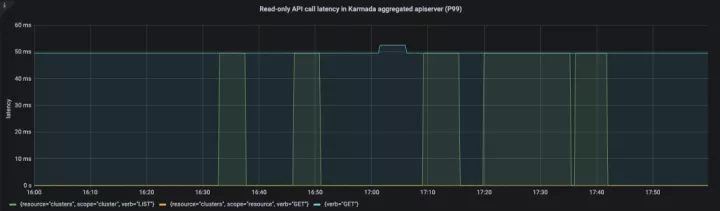

Cluster Registration Latency:

Note: Karmada 的 Pull 模式适合用于私有云的场景。与 Push 模式相比,成员集群会运行一个名为 karmada-agent 的组件。它会从控制面拉取用户提交的应用,并运行在成员集群中。在 Pull 模式集群注册的过程中,它会包含安装 karmada-agent 的时间。如果 karmada-agent 的镜像已经准备完毕的话,它很大程度上取决于单集群内 Pod 启动的时延。这里不过多讨论 Pull 模式的注册时延。
Resource Distribution Latency:

Push Mode
Etcd latency:

Resource Usage:



Pull Mode
Etcd latency:

Resource Usage:



成员集群中的 karmada-agent 消耗了 40m CPU(cores)和 266Mi Memory(bytes)。
结论与分析
在以上的测试结果中,API调用时延和资源分发时延均符合上述定义的SLIs/SLOs。在整个过程中,系统消耗的资源在一个可控制的范围。因此,Karmada能稳定支撑100个大规模集群,并且管理超过500,000个节点和2,000,000个的pods。在生产中,Karmada能有效支持数以百计的大规模的集群。接下来,我们会具体分析每个测试指标的数据。
关注点分离:资源模板和策略
Karmada 使用 Kubernetes 原生 API 来表达集群联邦资源模板,使用可复用的策略 API 来表达集群的调度策略。它不仅可以让 Karmada 能够轻松集成 Kubernetes 的生态, 同时也大大减少了控制面的资源数量。基于此,控制面的资源数量不取决于整个多集群系统集群的数量,而是取决于多集群应用的数量。
Karmada 的架构集成了 Kubernetes 架构的简洁性和扩展性。Karmada-apiserver 作为控制面的入口与 Kubernetes 的 kube-apiserver 类似。你可以使用单集群配置中所需的参数优化这些组件。
在整个资源分发过程中,API 调用时延在一个合理的范围。
集群注册与资源分发
在 Karmada 1.3 版本中,我们提供了基于 Bootstrap tokens 注册 Pull 模式集群的能力。这种方式不仅可以简化集群注册的流程,也增强了集群注册的安全性。现在无论是 Pull 模式还是 Push 模式,我们都可以使用 karmadactl 工具来完成集群注册。与 Push 模式相比,Pull 模式会在成员集群运行一个名为 karmada-agent 的组件。
集群注册时延包含了控制面收集成员集群状态所需的时间。在集群生命周期管理的过程中,Karmada 会收集成员集群的版本,支持的 API 列表以及集群是否健康的状态信息。此外,Karmada 会收集成员集群的资源使用量,并基于此对成员集群进行建模,这样调度器可以更好地为应用选择目标集群。在这种情况下,集群注册时延与集群的规模息息相关。上述指标展示了加入一个 5,000 节点的集群直至它可用所需的时延。你可以通过关闭集群资源建模[2]来使集群注册时延与集群的大小无关,在这种情况下,集群注册时延这个指标将小于 2s。
不论是 Push 模式还是 Pull 模式,Karmada 都以一个很快的速度来下发资源到成员集群中。唯一的区别在于 karmada-controller-manager 负责所有 Push 模式集群的资源分发,而 karmada-agent 只负责它所在那一个 Pull 模式集群。因此, 在高并发条件下发资源的过程中,Pull 在相同配置条件下会比 Push 模式更快。你也可以通过调整 karmada-controller-manager 的--concurrent-work-syncs的参数来调整同一时间段内并发 work 的数量来提升性能。
Push 模式和 Pull 模式的资源使用量对比
在 Karmada 1.3 版本中,我们做了许多工作来减少 Karmada 管理大型集群的资源使用量。现在我们很高兴宣布,相比于 1.2 版本,Karmada 1.3 在大规模场景下减少了 85% 的内存消耗和 32% 的 CPU 消耗。总的来说, Pull 模式在内存使用上有明显的优势,而在其他资源上相差的不大。
在 Push 模式中,控制面的资源消耗主要集中在 karmada-controller-manager,而 karmada-apiserver 的压力不大。
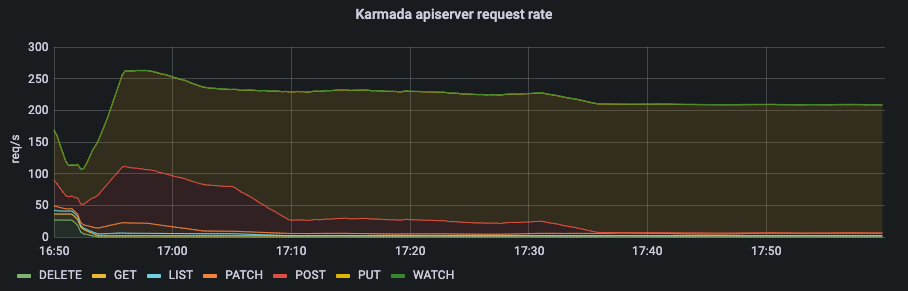
从 karmada-apiserver 的 qps 以及 karmada-etcd 的请求时延我们可以看出 karmada-apiserver 的请求量保持在一个较低的水平。在 Push 模式中,绝大多数的请求来自 karmada-controller-manager。你可以配置--kube-api-qps and --kube-api-burst这两个参数来控制请求数在一个确定的范围内。
在 Pull 模式中,控制面的资源消耗主要集中在 karmada-apiserver,而不是 karmada-controller-manager。

从 karmada-apiserver 的 qps 以及 karmada-etcd 的请求时延我们可以看出 karmada-apiserver 的请求量保持在一个较高的水平。在 Pull 模式中,每个成员集群的 karmada-agent 需要维持一个与 karmada-apiserver 通信的长连接。我们很容易得出:在下发应用至所有集群的过程中 karmada-apiserver 的请求总量是是 karmada-agent 中配置的 N 倍(N=#Num of clusters)。因此,在大规模 Pull 模式集群的场景下,我们建议增加 karmada-apiserver 的--max-requests-inflight以及--max-mutating-requests-inflight参数的值,和 karmada-etcd 的--quota-backend-bytes参数的值来提升控制面的吞吐量。
现在 Karmada 提供了集群资源模型[3]的能力来基于集群空闲资源做调度决策。在资源建模的过程中,它会收集所有集群的节点与 Pod 的信息。这在大规模场景下会有一定的内存消耗。如果你不使用这个能力,你可以关闭集群资源建模[4]来进一步减少资源消耗。
总结与展望
根据测试结果分析,Karmada可以稳定支持100个大规模集群,管理超过50万个节点和200万个Pod。
在使用场景方面,Push模式适用于管理公有云上的Kubernetes集群,而Pull模式相对于Push模式涵盖了私有云和边缘相关的场景。在性能和安全性方面,Pull模式的整体性能要优于Push模式。每个集群由集群中的karmada-agent组件管理,且完全隔离。但是,Pull模式在提升性能的同时,也需要相应提升karmada-apiserver和karmada-etcd的性能,以应对大流量、高并发场景下的挑战。具体方法请参考kubernetes对大规模集群的优化。一般来说,用户可以根据使用场景选择不同的部署模式,通过参数调优等手段来提升整个多集群系统的性能。
由于测试环境和测试工具的限制,本次测试尚未测试到Karmada多集群系统的上限,同时多集群系统的性能测试仍处于方兴未艾的阶段,下一步我们将继续优化多集群系统的测试工具,系统性地整理测试方法,以覆盖更大的规模和更多的场景。
参考资料
[1]https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md: https://github.com/kubernetes/perf-tests/blob/master/clusterloader2/docs/GETTING_STARTED.md
[2]关闭集群资源建模: https://karmada.io/docs/next/userguide/scheduling/cluster-resources#disable-cluster-resource-modeling
[3]集群资源模型: https://karmada.io/docs/next/userguide/scheduling/cluster-resources
[4]关闭集群资源建模: https://karmada.io/docs/next/userguide/scheduling/cluster-resources#disable-cluster-resource-modeling
-
相关阅读:
如何用matlab搭建激光器
Java-内部类
当快手打开想象力,钱多了,路也更广阔!
Android——解决BottomNavigationView+Fragment重建与重叠问题
Struct模块到底有多实用?一个知识点立马学习
Java -- 每日一问:谈谈 Spring Bean 的生命周期和作用域?
服务器连接时间长了,忘记密码,解密密码
面试系列 - Redis持久化机制详解
分享电脑便捷妙招,电脑小白们快码住
VMware16虚拟机安装及配置(保姆级教程),这一篇就够了
- 原文地址:https://blog.csdn.net/devcloud/article/details/127789891
