-
擎创技术流 | ClickHouse管理工具—ckman教程(2)ClickHouse集群
本期来自B站的教程:ClickHouse管理工具—ckman教程(2)——ClickHouse集群。
演讲者:B站UP主-禹鼎侯(擎创科技研发工程师)
前言:
上期我们讲到了ClickHouse的概念、特点以及初步引入了ClickHouse管理工具,这期我们来说一说ClickHouse集群的准备工作。
一、什么是ClickHouse集群?
上期我们谈到ClickHouse是一个基于OLAP场景的数据库,所以对于集群的支持也是理所当然的。我们通常所说的ClickHouse集群,指的是物理集群。即集群各节点之间被同一个zookeeper集群管理,数据的各种DDL操作都是针对整个集群有效的。
与物理集群相对应的,还有一类集群,我们叫它逻辑集群。它是指在物理上没有一定的必然关系的物理集群,彼此又组成了一个逻辑集群。可以用下面这幅图形象地表达物理集群和逻辑集群的关系。
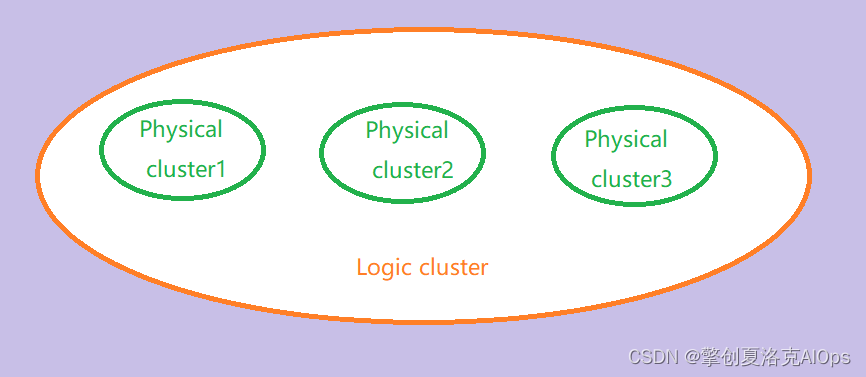
如上图所示,三个物理集群各自是相互独立的,对cluster1的各种数据操作,cluster2和cluster3并无法感知,但是对于logic集群来说,任何一个物理集群的数据变化,逻辑集群都能通过查询获取到。
二、为什么需要逻辑集群
那么,既然有了物理集群,为什么还要逻辑集群呢?它能解决用户什么痛点?又能带来哪些好处?
首先,逻辑集群能解决zookeeper压力问题
我们知道,ClickHouse集群的数据一致性是通过Zookeeper集群来保证的。当集群的数据量特别大或者操作特别频繁的时候,带来的就是zookeeper的znode节点数量多,更新频繁。而zookeeper的压力是有上限的,如果集群过大,或者一个zookeeper集群管理的clickhouse集群过多的话,很容易造成zookeeper崩溃或者卡死。
正是因为“天下苦zookeeper久矣”,逻辑集群的出现正好能解决这一问题。
比如,某个物理集群的数据量特别庞大, 庞大到单一的zookeeper集群无法支撑其元数据管理,这时候我们可以将这个物理集群拆分成多个物理集群,分别使用不同的zookeeper集群去管理,然后通过逻辑集群去查询数据。这样既分担了zookeeper的压力,也保留了各个物理集群之间的业务关联性,不影响业务数据的查询。
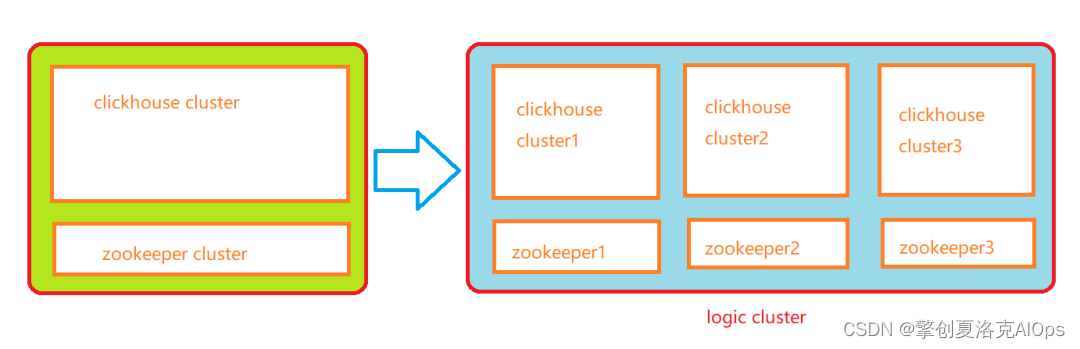
其次,逻辑集群解决了多数据中心问题
还有一种比较常见的场景是多数据中心。随着企业数据规模的扩张,不可能把所有的数据都存放在一个数据中心,面对这样的多数据中心的场景,如果只建立一个物理集群,那么首先面临的是网络的延迟问题,其次还有高昂的流量费用,这都是需要考虑的问题。
那么比较好的做法是在每一个数据中心都分别建立各自的物理集群,这样无论是数据的插入还是查询,都极大减少了网络上的限制,从而把延迟做到最小。
但是我们考虑这样一个场景:某银行机构在上海和合肥各有一个数据中心,分别建立了两个物理集群,叫做bench_shanghai和bench_hefei, 现在总行机构需要综合上海和合肥的两个数据中心的数据做数据分析。那么我们还必须分别查询上海的集群和合肥的集群,然后再进行汇总。如果数据中心比较多,那么查询的次数也就特别多,这样显然是事倍功半的。
如果我们建立一个逻辑集群,将上海的集群和合肥的集群包含在内,我们就叫它bench集群,这样我们只需要查询bench集群,就能一次将数据全部查出来,如下图所示:

- 再次,逻辑集群能节约成本
逻辑集群节约成本是肯定的。当然主要是网络流量方面的成本。尤其是云上的服务器,流量贵得惊人。设想一下,如果上海和合肥两个数据中心只有一个物理集群,而恰好一个shard中的不同副本又分别位于不同的数据中心,当每天数TB级别的数据写入数据库,在做副本之间数据同步的时候,产生的流量当有多么可怕。
三、部署ClickHouse集群的准备(文末附带详细讲解视频)
1. 准备几个节点服务器用来安装clickhouse-server
要求:centos7 以上,可以使用systemctl来管理服务。2. zookeeper集群(要求zk版本大于或等于3.6.0)
- 需要的配置:
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvidermetricsProvider.httpPort=7000 admin.enableServer=trueadmin.serverPort=8080访问:localhost:7000/metrics或: localhost:8080/commands/mntr
3. 提前下载好clickhouse的安装包:
https://repo.yandex.ru/clickhouse/rpm/lts/x86_64/四、部署ClickHouse集群注意事项:
- 认证方式:
1. 密码认证(保存密码):使用密码登录,密码加密保存在本地,后续运维动作无需输入密码2. 密码认证(不保存密码):使用密码登录,但是密码不保存,后续运维动作(增删节点、启停等),需要输入密码3. 公钥认证:使用公钥登录,无需保存密码,后续运维操作可直接操作,是默认的认证方式
- 公钥认证需要注意:
(1)需要提前配置ckman所在服务器到clickhouse各节点之间的互信(使用哪个用户去部署就配置哪个用户的) ssh-copy-id。(2)需要将公钥文件 ~/.ssh/id_rsa 拷贝到ckman/conf目录下,并保证ckman用户有权限访问该文件。(3)如果是使用普通用户,公钥方式认证,那么该普通用户需要具有sudo权限,且在/etc/sudoers 文件中配置了NOPASSWD。
系列教程02

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
▼行业龙头客户的共同选择

-
相关阅读:
日志平台搭建第五章:Linux安装Kafka
springboot进行微信公众号相关开发:(一)编写接口激活配置信息用,用以实现公众号与配置信息接口的绑定
你的数据库到底应该如何存储密码?
MQ - 39 Serverless : 基于MQ和Serverless设计事件驱动架构
python基础知识入门
探索 Linux Namespace:Docker 隔离的神奇背后
WIN10系统禁止自动更新设置(二)
Red Eye Camera开发日记之API 移植I2C 和关键接口函数
最长非递减子序列,Python实现
C现代方法(第8章)笔记——数组
- 原文地址:https://blog.csdn.net/qq_37641528/article/details/127736415