-
Java I/O(一)I/O概述
Java I/O
1 I/O概述
I/O有内存I/O,磁盘I/O,网络I/O三种,通常我们说的I/O指的是后两者。
1.1 I/O的过程
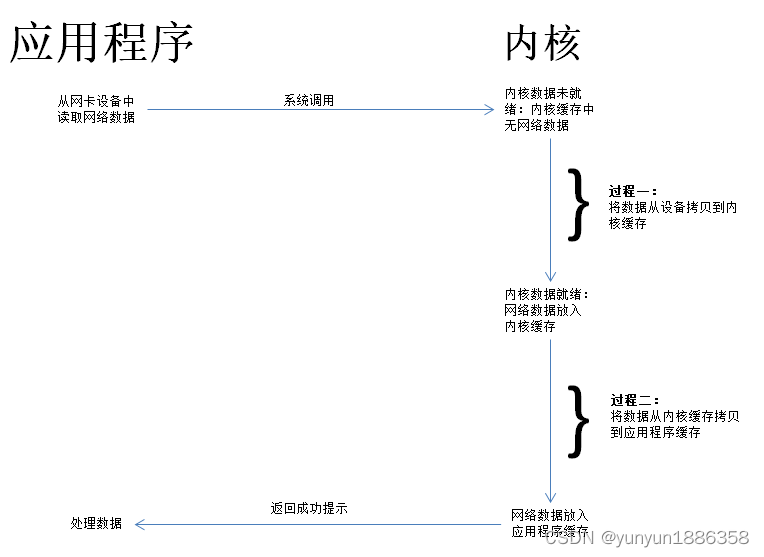
磁盘/网络I/O总体上可以分为两个过程:
以网络I/O为例:- 设备数据拷贝到内核缓存:应用程序为了读取网卡数据,发起一条系统调用,然后等待操作系统准备数据;接下来操作系统切换为
内核态,从网卡读取数据,拷贝到内核缓存。 - 内核缓存拷贝到应用程序缓存:将数据从内核空间拷贝到用户空间,操作系统切换回
用户态,开始处理数据包。
内核态和用户态
DOS时代,应用程序和操作系统一样的运行权限,可以随意访问设备,更改操作系统数,造成病毒泛滥,操作系统崩溃。为了解决以上这些问题,安全,稳定的运行操作系统,现代操作系统已经不允许应用程序直接访问设备。
那改怎么办呢?答案调用操作系统库函数,库函数切换操作系统运行级别,执行读取设备的指令,让操作系统代为访问设备,而用户态和内核态就是操作系统的运行级别。
Java程序在操作系统上执行时,会映射为调用一条条的CPU指令。指令根据对操作系统的影响程度被分为多个级别,在不同状态下,相同指令会产生不同的结果。
例如 Intel X86 中将 CPU 指令权限划分为了 4 个等级:Ring0,ring1,ring2, ring3,权限由高到低为:Ring0 > Ring1 > Ring2 > Ring3。
在 Linux 系统中,由于只有 Ring0 和 Ring3 级别的指令,所以我们可以对用户态、内核态给一个更细节的区别描述:运行 Ring0 级别指令的操作系统状态叫内核态,运行 Ring3 级别指令的叫用户态。
存取设备的指令属于Ring0,就必须在内核态执行。1.2 I/O的通信模型
可以从2个维度描述I/O的模式:
- 同步和异步
同步和异步其实是指CPU时间片的利用,主要是看请求发起方(应用程序)对消息结果(IO数据从设备传输到应用程序缓存)的获取是主动发起(同步)的还是被动通知(异步)的。 - 阻塞和非阻塞
阻塞和非阻塞主要是指线调用了一个函数(例如IO读写)之后,等待函数返回之前,当前线程是出于挂起状态(阻塞)和运行状态(非阻塞)。
这两组概念从不同的角度描述了IO的整个过程。
理解了以上的概念,I/O可以有4种组合模式:同步阻塞I/O,同步非阻塞I/O,异步阻塞I/O,异步非阻塞I/O。
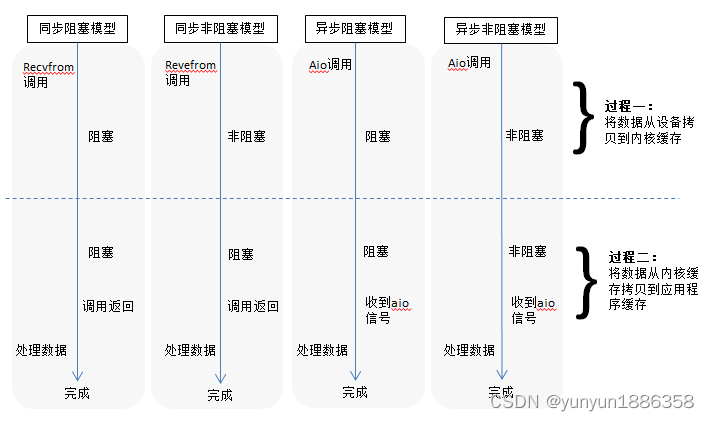
基于以上的组合,目前实现了以下五种I/O通信模型:
1.2.1 阻塞I/O模型
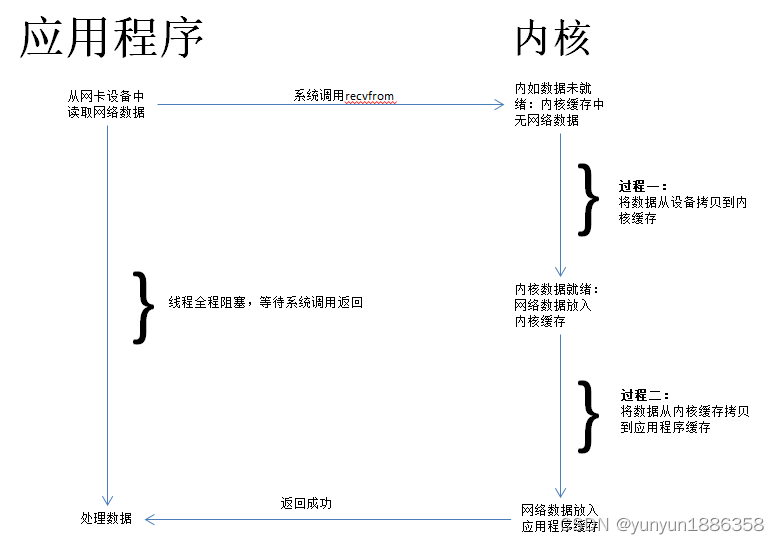
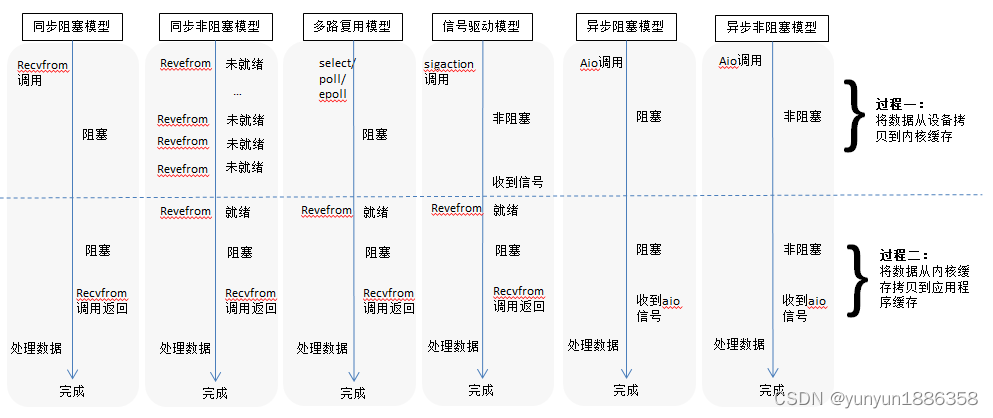
这种模型中,用户线程主动调用recvfrom这个系统调用,直到系统调用返回,所以是同步模型;调用后线程一直阻塞,所以是阻塞模型。这种模型每一个线程只能处理一个连接,所以资源利用率低,系统开销大。
典型应用:Java BIO,NIO的阻塞模式
示例:
Java BIO 基于TCP协议的服务端,客户端通信(单线程)
Java BIO 基于TCP协议的服务端,客户端通信(多线程)
Java BIO 基于UDP协议的服务端,客户端通信
Java NIO 基于TCP协议的服务端,客户端通信(阻塞)1.2.2 非阻塞I/O模型
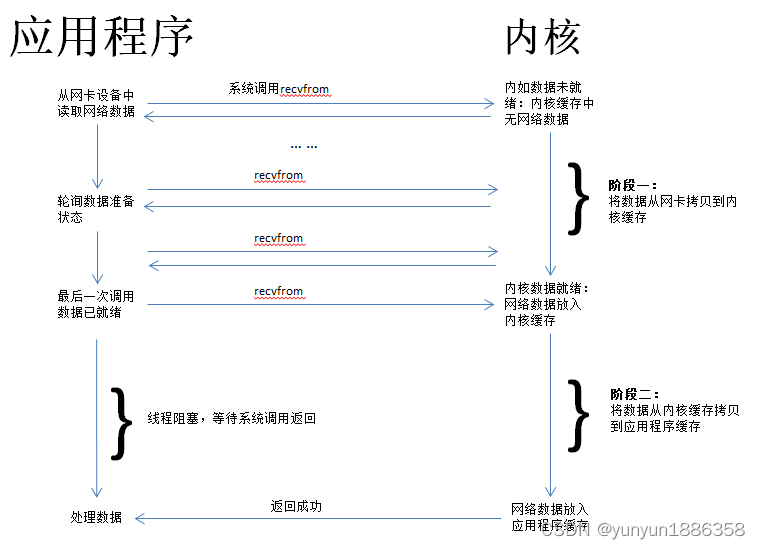
在这种模型中,用户线程也是主动,轮询调用recvfrom,只是调用有可能立刻返回,所以是同步模型;在内核准备数据的阶段,虽然用户线程不阻塞,但是在数据准备就绪之后,进入第二阶段,用户线程还是会阻塞,等待数据拷贝,整体属于非阻塞模型。
典型应用:NIO的非阻塞模式
示例:
Java NIO 基于TCP协议的服务端,客户端通信(非阻塞)1.2.3 多路复用I/O模型
上面两种模型,无论线程是否阻塞,总体上看都是单个线程对应单个连接,线程的浪费比较大。虽然非阻塞模式不会阻塞线程,但是依旧需要线程轮询系统调用,线程依旧只能处理一个连接。
如果要建设一个并发链接数达到10w的系统,如果系统用10w个线程来处理,再加上系统本身运行需要的线程数,那对服务器硬件资源的要求是非常高的,很难满足。
多路复用就是为了提高线程的利用率,使用一个线程来处理多条连接。
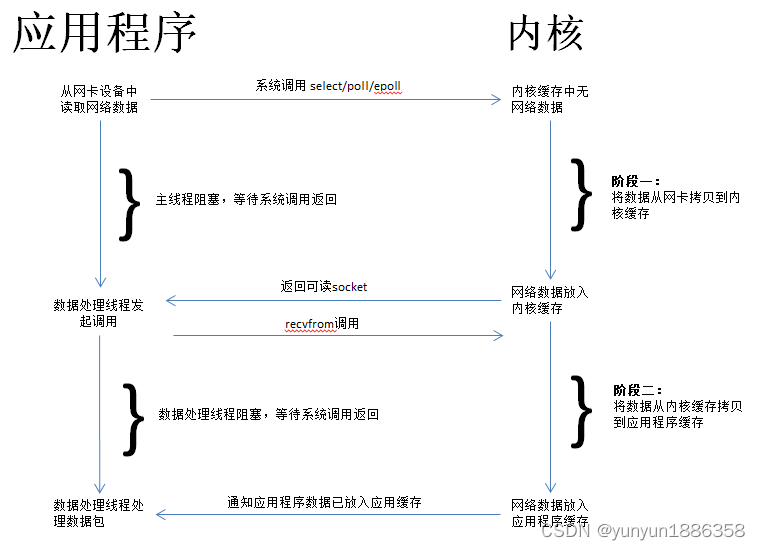
而select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。- select:
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的 - poll:
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。 - epoll:
epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是 O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
典型应用:Java NIO Reactor模式, Netty, Memcache, Ngix,Redis
示例:
Java NIO 基于多路复用的服务端,客户端通信(非阻塞,单线程)
Java NIO 基于多路复用的服务端,客户端通信(非阻塞,多线程)1.2.4 信号驱动I/O模型
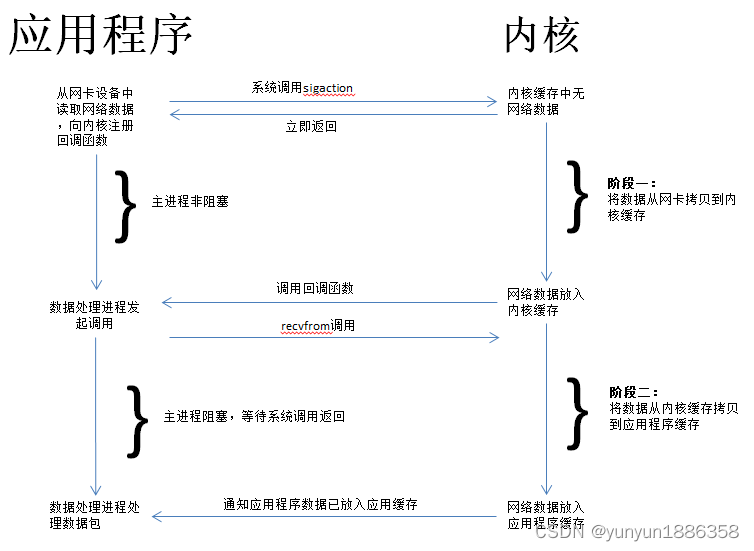
在这种模型中,用户线程向内核注册一个回调函数,当内核数据就绪后,内核调用回调函数通知用户线程,用户线程启动第二个处理过程:将数据从内核缓存拷贝到引用程序缓存。
这种模型在过程一实际上做到了异步,但是过程二还是同步阻塞的。所以其实只是做到了半异步。
典型应用:1.2.5 异步I/O模型
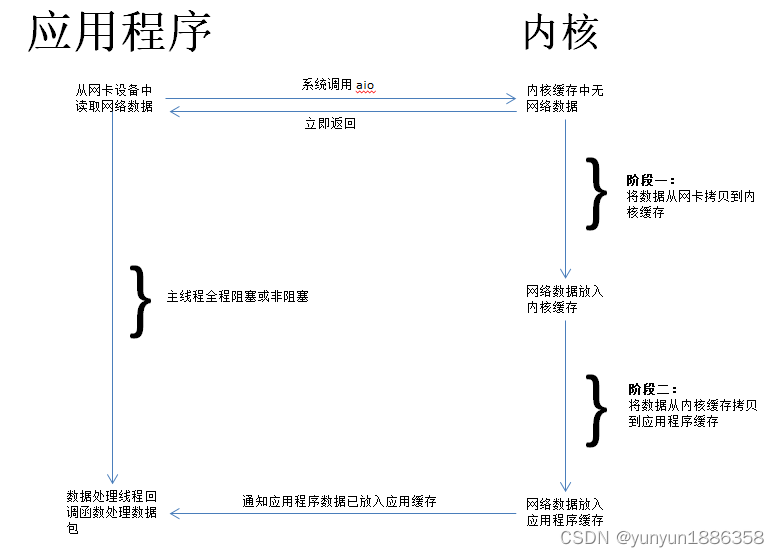
用户线程发起异步I/O系统调用,告诉内核应用程序缓冲区的信息,系统调用立即返回。用户线程不会阻塞也不用轮询调用,直到内核完成I/O的两个过程之后,通知用户线程,I/O已完成,数据拷贝到应用程序缓冲区,可以读取数据了。
真正的异步I/O是需要操作系统支持才能实现的。
典型应用:Java AIO Proactor模式1.2.5.1 异步非阻塞I/O
典型应用:Java AIO的回调模式
Java NIO 基于AIO的服务端,客户端通信(非阻塞)1.2.5.2 异步阻塞I/O
典型应用:Java AIO的Future 模式
Java NIO 基于AIO的服务端,客户端通信(阻塞)几种模型的比较:
- 设备数据拷贝到内核缓存:应用程序为了读取网卡数据,发起一条系统调用,然后等待操作系统准备数据;接下来操作系统切换为
-
相关阅读:
WindTerm 开源的高性能终端模拟器 最酷
Machine learning week 9(Andrew Ng)
【vue设计与实现】挂载和更新 6-事件冒泡与更新时机问题
DB-GPT介绍
HCIP之BGP的选路原则
如何备战Shopee大促活动?有什么技巧?
在线电子表格spreadjs
追求极致性能,RocketMQ 消息通信详解
顾客点餐系统-----后端代码编写(基于SSM)
【ZooKeeper】zookeeper源码6-FastLeaderElection选举算法
- 原文地址:https://blog.csdn.net/yunyun1886358/article/details/127345157