-
CUDA By Example(二)——CUDA C简介
本章开始编写第一段CUDA C代码,了解为主机(Host)编写的代码与为设备(Device)编写的代码之间的区别。了解如何从主机上运行设备代码。了解如何在支持CUDA的设备上使用设备内存。了解如何查询系统中支持CUDA的设备的信息。
第一个程序
Hello, World!
正常用C语言实现一个 Hello World 的代码如下
#includeint main(void) { printf( "Hello, World!\n" ); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
下面我们要在原始的 Hello World 代码中加一些特殊的东西。
#include#include "cuda_runtime.h" __global__ void kernel( void ) { } int main( void ) { kernel<<<1, 1>>>(); printf( "Hello, World!\n" ); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个程序与最初的 “Hello, World!” 相比,多了两个值得注意的地方:
- 一个空的函数
kernel(),并且带有修饰符__global__。 - 对这个空函数的调用,并且带有修饰字符
<<<1,1>>>。
__global__是 CUDA C为标准C增加的修饰符。这个修饰符将告诉编译器,函数应该编译为在设备(比如GPU)而不是主机上运行。在这个简单的示例中,函数kernel()将被交给编译设备代码的编译器,而main()函数将交给主机编译器。那么,
kernel()的调用究竟代表着什么含义,并且为什么必须加上尖括号和两个数值?注意,这正是使用CUDA C的地方。我们已经看到,CUDA C需要通过某种语法方法将一个函数标记为 “设备代码(Device Code)”。这并没有什么特别之处,而只是一种简单的表示方法,表示将主机代码发送到一个编译器,而将设备代码发送到另一个编译器。事实上,这里的关键在于如何在主机代码中调用设备代码。CUDA C的优势之一在于,它提供了与C在语言级别上的集成,因此这个设备函数调用看上去非常像主机函数调用。在后面将详细介绍背后发生的动作,但就目前而言,只需知道CUDA编译器在运行时将负责实现从主机代码中调用设备代码。
这里尖括号表示要将一些参数传递给运行时系统。这些参数并不是传递给设备代码的参数,而是告诉运行时如何启动设备代码。传递给设备代码本身的参数是放在圆括号中传递的,就像标准的函数调用一样。
传递参数
下面的示例就展示了如何将参数传递给核函数
#include#include "../common/book.h" #include "cuda_runtime.h" __global__ void add(int a, int b, int *c) { *c = a + b; } int main() { int c; int *dev_c; HANDLE_ERROR(cudaMalloc((void **) & dev_c, sizeof(int))); add << <1, 1 >> > (2, 7, dev_c); HANDLE_ERROR(cudaMemcpy(&c, dev_c, sizeof(int), cudaMemcpyDeviceToHost)); printf("2 + 7=%d\n", c); cudaFree(dev_c); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
注意这里增加了多行代码,在这些代码中包含两个概念:
- 可以像调用C函数那样将参数传递给核函数。
- 当设备执行任何有用的操作时,都需要分配内存,例如将计算值返回给主机。
在将参数传递给核函数的过程中没有任何特别之处。除了尖括号语法之外,核函数的外表和行为看上去与标准C中的任何函数调用一样。运行时系统负责处理将参数从主机传递给设备的过程中的所有复杂操作。
更需要注意的地方在于通过
cudaMalloc()来分配内存。这个函数调用的行为非常类似于标准的C函数malloc(),但该函数的作用是告诉 CUDA 运行时在设备上分配内存。第一个参数是一个指针,指向用于保存新分配内存地址的变量,第二个参数是分配内存的大小。除了分配内存的指针不是作为函数的返回值外,这个函数的行为与malloc()是相同的,并且返回类型为void*。函数调用外层的HANDLE_ERROR()是我们定义的一个宏,作为辅助代码的一部分。这个宏只是判断函数调用是否返回了一个错误值,如果是的话,那么将输出相应的错误信息,退出应用程序并将退出码设置为EXIT_FAILURE。虽然你也可以在自己的应用程序中使用这个错误处理码,但这种做法在产品级的代码中很可能是不够的。需要注意的是一定不能在主机代码中对
cudaMalloc()返回的指针进行解引用(Dereference)。主机代码可以将这个指针作为参数传递,对其执行算术运算,甚至可以将其转换为另一种不同的类型。但是,绝对不可以使用这个指针来读取或者写入内存。可以将设备指针的使用限制总结如下:
- 可以将
cudaMalloc()分配的指针传递给在设备上执行的函数 - 可以在设备代码中使用
cudaMalloc()分配的指针进行内存读/写操作 - 可以将
cudaMalloc()分配的指针传递给在主机上执行的函数 - 不能在主机代码中使用
cudaMalloc()分配的指针进行内存读/写操作
此外,释放在GPU上分配的内存也需要使用
cudaFree(),这个函数的行为与free()的行为非常相似如果我们需要在主机代码中访问设备上的内存,需要使用
cudaMemcpy()。这个函数调用的行为类似与标准C中的memcpy(),只不过多了一个参数来指定设备内存指针究竟是源指针还是目标指针。比如上面例子中的最后一个参数cudaMemcpyDeviceToHost,告诉运行时源指针是一个设备指针,而目标指针是一个主机指针。显然
cudaMemcpyHostToDevice告诉运行时源指针位于主机上,而目标指针是位于设备上。当然还有cudaMemcpyDeviceToDevice表示运行时两个指针都在设备上。
查询设备
CUDA C提供了简单的接口让我们能够知道设备拥有多个内存以及具备哪些功能,除此以外如果一台计算机上拥有多个支持CUDA的设备,CUDA C也提供了接口来查询有多少支持CUDA的设备。
查询有多少支持CUDA的设备
要获取CUDA设备的数量,可以调用
cudaGetDeviceCount()。#include "cuda_runtime.h" #include "device_launch_parameters.h" #includeint main() { int count; cudaGetDeviceCount(&count); printf("%d\n", count); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下图可以看到本机只有一个支持CUDA的设备
查询设备相关属性
在调用
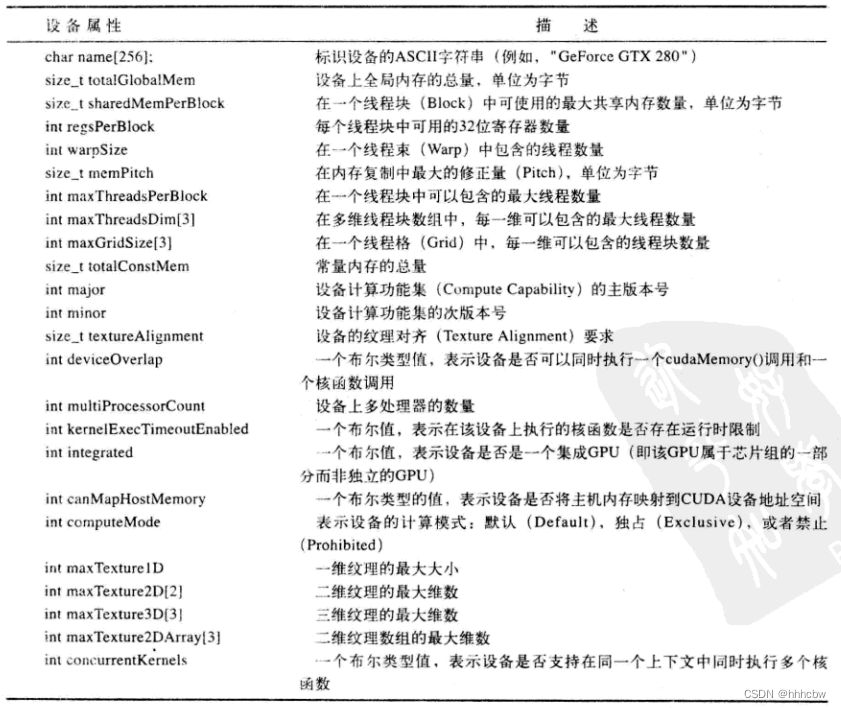
cudaGetDeviceCount()后,可以对每个设备进行迭代,并查询每个设备的相关信息。CUDA 运行时将返回一个cudaDeviceProp类型的结构,其中包含了设备的相关属性,如下表所示
CUDA C 使用cudaGetDeviceProperties()获取设备的相应属性#include "../common/book.h" #include "cuda_runtime.h" #include "device_launch_parameters.h" #includeint main(void) { cudaDeviceProp prop; int count; HANDLE_ERROR(cudaGetDeviceCount(&count)); for (int i = 0; i < count; i++) { HANDLE_ERROR(cudaGetDeviceProperties(&prop, i)); printf(" --- General Information for device %d ---\n", i); printf("Name: %s\n", prop.name); printf("Compute capability: %d.%d\n", prop.major, prop.minor); printf("Clock rate: %d\n", prop.clockRate); printf("Device copy overlap: "); if (prop.deviceOverlap) printf("Enabled\n"); else printf("Disabled\n"); printf("Kernel execution timeout : "); if (prop.kernelExecTimeoutEnabled) printf("Enabled\n"); else printf("Disabled\n"); printf(" --- Memory Information for device %d ---\n", i); printf("Total global mem: %ld\n", prop.totalGlobalMem); printf("Total constant Mem: %ld\n", prop.totalConstMem); printf("Max mem pitch: %ld\n", prop.memPitch); printf("Texture Alignment: %ld\n", prop.textureAlignment); printf(" --- MP Information for device %d ---\n", i); printf("Multiprocessor count: %d\n", prop.multiProcessorCount); printf("Shared mem per mp: %ld\n", prop.sharedMemPerBlock); printf("Registers per mp: %d\n", prop.regsPerBlock); printf("Threads in warp: %d\n", prop.warpSize); printf("Max threads per block: %d\n", prop.maxThreadsPerBlock); printf("Max thread dimensions: (%d, %d, %d)\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]); printf("Max grid dimensions: (%d, %d, %d)\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]); printf("\n"); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
运行结果如下

查找所需设备并设置应用运行设备
根据在
cudaGetDeviceCount()和cudaGetDeviceProperties()中返回的结果,我们可以对每个设备进行迭代,并且查找主版本号大于 1,或者主版本号为1且次版本号大于等于3的设备。但是这种迭代操作执行起来有些繁琐,因此CUDA运行时提供了一种自动方式来执行这个迭代操作。首先,找出我们希望设备拥有的属性并将这些属性填充到一个cudaDeviceProp结构。cudaDeviceProp prop; memset(&prop, 0, sizeof(cudaDeviceProp)); prop.major = 1; prop.minor = 3;- 1
- 2
- 3
- 4
在填充完
cudaDeviceProp结构后,将其传递给cudaChooseDevice(),这样CUDA运行时将查找是否存在某个设备满足这些条件。cudaChooseDevice()函数将返回一个设备ID,然后我们可以将这个ID传递给cudaSetDevice()。随后,所有的设备操作都将在这个设备上执行。#include "../common/book.h" int main(void) { cudaDeviceProp prop; int dev; HANDLE_ERROR( cudaGetDevice(&dev) ); printf("ID of current CUDA device: %d\n", dev); memset(&prop, 0, sizeof(cudaDeviceProp) ); prop.major = 1; prop.minor = 3; HANDLE_ERROR(cudaChooseDevice(&dev, &prop)); printf("ID of CUDA device closest to revision 1.3: %d\n", dev); HANDLE_ERROR( cudaSetDevice(dev) ); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
相关阅读:
如何进行销售漏斗管理?
长短期负荷预测(Matlab代码实现)
重磅出击,20张图带你彻底了解ReentrantLock加锁解锁的原理
SAP UI5 应用开发教程之一百零三 - 如何在 SAP UI5 应用中消费第三方库
ceph 13版本:ceph-deploy(2.0.1) 部署mimic(13.2.10)版本
字节跳动五面都过了,结果被刷了,问了hr原因竟说是...
如何抑制开关电源的启动浪涌电流?看这一文,6种方法总结,秒懂
picoCTF - Day 1 - Warm up
【区块链 | ENS】ENS源码分析
面试官:你确定 Redis 是单线程的进程吗?
- 原文地址:https://blog.csdn.net/weixin_44491423/article/details/127739202
