-
KeeWiDB的高性能修炼之路:架构篇
数据也有冷热之分,你知道吗?
根据访问的频率的高低可将数据分为热数据和冷数据,访问频率高的则为热数据,低为冷数据。如果热、冷数据不区分,一并存储,显然不科学。将冷数据也存储在昂贵的内存中,那么你想,成本得多高呢?
有趣的是,根据我们实际的观察,目前很多使用 Redis 的业务就是这样操作的。
得益于高性能以及丰富的数据结构命令,Redis 成为目前最受欢迎的 KV 内存数据库。但随着业务数据量的爆炸增长,Redis 的内存消耗也会随之爆炸。无论客户是自建服务器还是云服务器,内存都是一个必须考虑的成本问题,它不仅贵还要持续购买。
此外 Redis 虽然提供了 AOF 和 RDB 两种方案来实现数据的持久化,但是使用不当可能会对性能造成影响甚至引发丢数据的问题。
好在,随着科技的发展,持久化硬件的发展速度也在提升,持久内存的出现进一步缩小了与内存的性能差距。或许,合理利用新型持久化技术会成为一个好的成本解决方案。
基于这一思路,为解决 Redis 可能带来的内存成本、容量限制以及持久化等一系列问题,腾讯云数据库团队推出了新一代分布式KV存储数据库 KeeWiDB。本文将详细介绍KeeWiDB 的架构设计思路、实现路径及成效。先简单总结一下 KeeWiDB 的特性:
- 友好:完全兼容 Redis 协议,原先使用 Redis 的业务无需修改任何代码便可以迁移到 KeeWiDB 上;
- 高性能低延迟:通过创新性的分级存储架构设计,单节点读写能力超过 18 万 QPS,访问延迟达到毫秒级;
- 更低的成本:内核自动区分冷热数据,冷数据存储在相对低价的 SSD 上;
- 更大的容量:节点支持 TB 级别的数据存储,集群支持 PB 级别的数据存储;
- 保证了事务的 ACID (原子性 Atomicity、一致性 Consitency、隔离性 Isolation、持久性 Durability)四大特性;
一、整体架构
KeeWiDB 的架构由代理层和服务层两个部分构成: 代理层:由多个无状态的Proxy节点组成,主要功能是负责与客户端进行交互; 服务层:由多个Server节点组成的集群,负责数据的存储以及在机器发生故障时可以自动进行故障切换。

图:KeeWiDB整体架构图
代理层
客户端通过 Proxy 连接来进行访问,由于 Proxy 内部维护了后端集群的路由信息,所以 Proxy 可以将客户端的请求转发到正确的节点进行处理,从而客户端无需关心集群的路由变化,用户可以像使用 Redis 单机版一样来使用 KeeWiDB。
Proxy 的引入,还带来了诸多优势:
- 客户端直接和 Proxy 进行交互,后端集群在扩缩容场景不会影响客户端请求;
- Proxy 内部有自己的连接池和后端 KeeWiDB 进行交互,可大大减少 KeeWiDB 上的连接数量,同时有效避免业务短连接场景下反复建连断连对内核造成性能的影响;
- 支持读写分离,针对读多写少的场景,通过添加副本数量可以有效分摊 KeeWiDB 的访问压力;
- 支持命令拦截和审计功能,针对高危命令进行拦截和日志审计,大幅度提高系统的安全性;
- 由于 Proxy 是无状态的,负载较高场景下可以通过增加 Proxy 数量来缓解压力,此外我们的 Proxy 支持热升级功能,后续 Proxy 添加了新功能或者性能优化,存量 KeeWiDB 实例的 Proxy 都可以进行对客户端无感知的平滑升级;
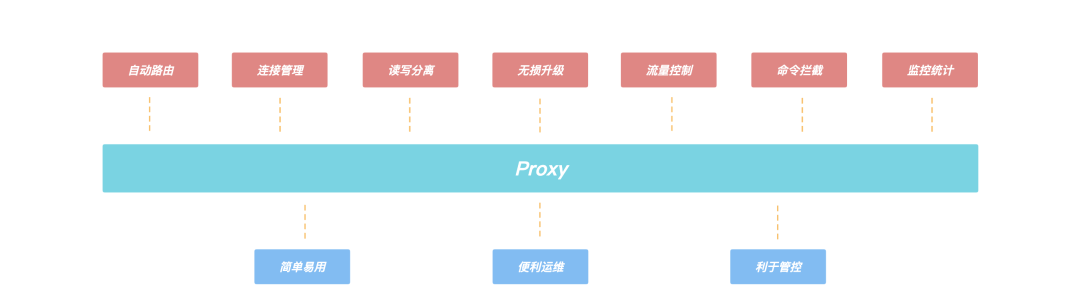
图:Proxy上的功能
服务层
-
相关阅读:
爬虫机试题-爬取新闻网站
linux常用网址
ID生成器代码重构问题
金仓数据库KingbaseES数据库开发指南(2. 开发基础)
电脑硬件——CPU散热器
开关电源测试解决方案之浪涌电流测试 -纳米软件
Springboot整合轻量级反爬虫组件kk-anti-reptile
The 2022 ICPC Asia Xian Regional Contest--C. Clone Ranran
2022年IEEE Fellow名单正式公布,清华教授、阿里云李飞飞等73位华人上榜
大数据----Hadoop与数据仓库
- 原文地址:https://blog.csdn.net/weixin_43872058/article/details/127770873