-
Java经典面试题
MyBatis#和$区别
#是相当于?占位符,会进行preparedstatement预编译处理,可以防止SQL注入
$ 是动态参数,在传递参数的时候,相当于直接把参数拼接到原始SQL语句里面,mybatis不会做特殊处理
对于字符串类型,#相当于对数据 加上引号,$ 相当于直接显示数据, 一般都是用 #,只有动态传递表名和排序字段的时候用$、
MyBatis原理
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
MyBatis的基本工作原理就是:先封装SQL,接着调用JDBC操作数据库,最后把数据库返回的表结果封装成Java类。
mybatis应用程序通过SqlSessionFactoryBuilder从mybatis-config.xml配置文件中构建出SqlSessionFactory,然后,SqlSessionFactory的实例直接开启一个SqlSession,再通过SqlSession实例获得Mapper对象并运行Mapper映射的SQL语句,完成对数据库的CRUD和事务提交,之后关闭SqlSession。
MyBatis中的四大核心对象:
(1)SqlSession对象,该对象中包含了执行SQL语句的所有方法【1】。类似于JDBC里面的Connection 【2】。
(2)Executor接口,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。类似于JDBC里面的Statement/PrepareStatement。
(3)MappedStatement对象,该对象是对映射SQL的封装,用于存储要映射的SQL语句的id、参数等信息。
(4)ResultHandler对象,用于对返回的结果进行处理,最终得到自己想要的数据格式或类型。可以自定义返回类型。MySQL优化
-
查询SQL尽量不要使用select *,而是select具体字段。
- 只取需要的字段,节省资源、减少网络开销。
- select * 进行查询时,很可能就不会使用到覆盖索引了,就会造成回表查询。
-
应尽量避免在where子句中使用or来连接条件
使用or可能会使索引失效,从而全表扫描。
-
优化你的like语句,把%放后面走索引,把%放前面,并不走索引
-
尽量避免在索引列上使用mysql的内置函数(例如单行函数和聚合函数),索引列上使用mysql的内置函数,索引失效
-
应尽量避免在where子句中对字段进行表达式操作(例where age-1 =10),这将导致系统放弃使用索引而进行全表扫描
-
Inner join 、left join、right join,优先使用Inner join,如果是left join,左边表结果尽量小,
-
exist&in的合理利用,以小表驱动大表
-
应尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
-
在适当的时候,使用覆盖索引。
-
当在SQL语句中连接多个表时,请使用表的别名,并把别名前缀于每一列上,这样语义更加清晰。
-
where子句中考虑使用默认值代替null。
-
如果字段类型是字符串,where时一定用引号括起来,否则索引失效
-
如果知道查询结果只有一条或者只要最大/最小一条记录,建议用limit 1
- 加上limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高。
- 当然,如果name是唯一索引的话,是不必要加上limit 1了,因为limit的存在主要就是为了防止全表扫描,从而提高性能,如果一个语句本身可以预知不用全表扫描,有没有limit ,性能的差别并不大。
-
如果插入数据过多,考虑批量插入。
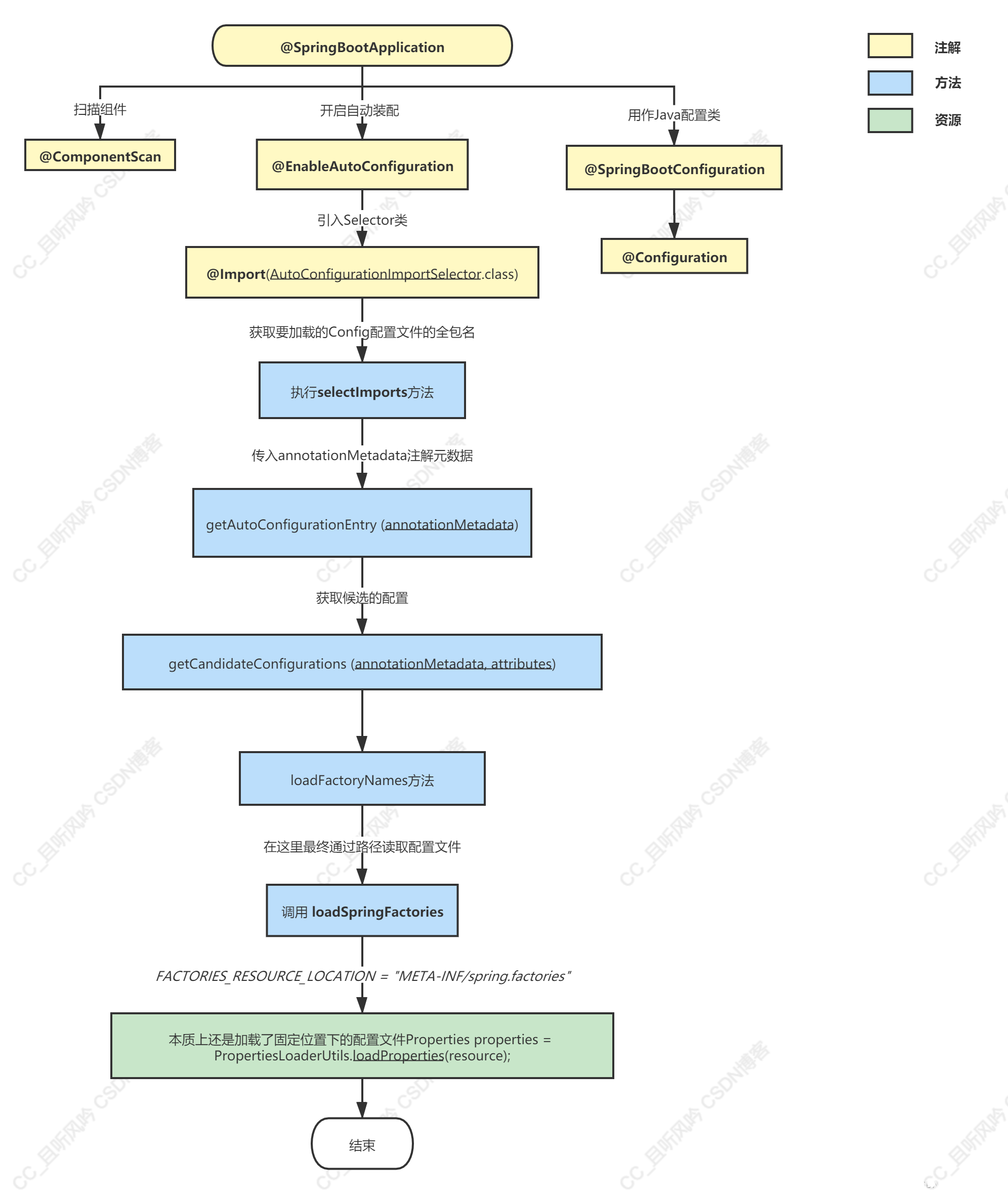
SpringBoot自动化原理
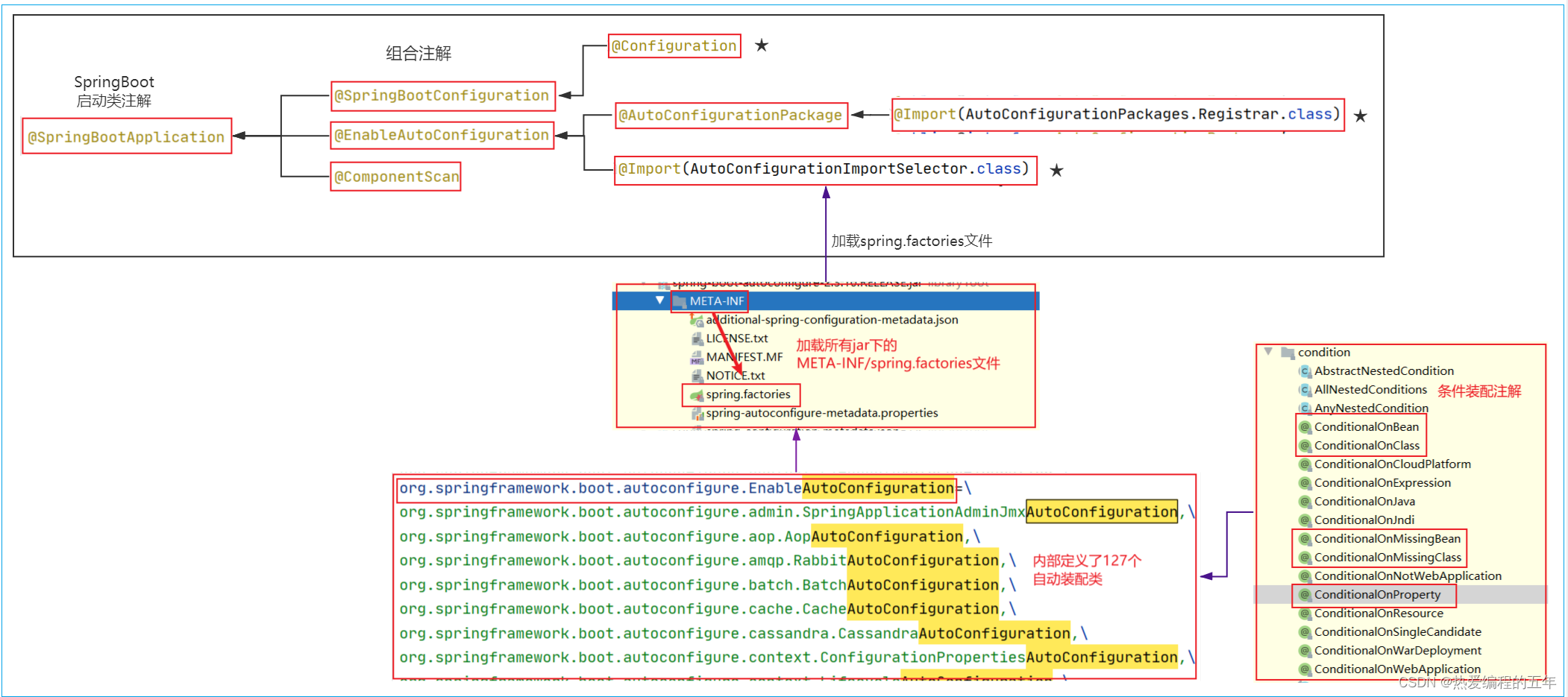

@SpringBootApplication 是一个组合注解,主要有@SpringBootConfiguration ,@EnableAutoConfiguration自动化配置核心实现注解,@ComponentScan 组件扫描,包扫描引导类所在的包及其子包所有带Spring注解的类
总之SpringBoot加载所有META-INF/spring.factories文件下的自动装配类(类似Spring的Javaconfig),然后@Conditional条件过滤(exclude配排除的类,重复的类),获取最终自动装配类,然后配置类被spring加载到IOC容器中;
Spring的两种配置方式:基于XML的配置(applicationContext.xml,构造器注入 constructor-arg,set注入 property)和基于JavaConfig类的配置方式
<bean id="person" class="pojo.Person"> <property name="name" value="dzzhyk"/> <property name="age" value="20"/> <property name="sex" value="true"/> bean>- 1
- 2
- 3
- 4
- 5
- 6
- 7
基于JavaConfig 类(建一个config 类,使用注解@Configuration)
@Configuration @ComponentScan public class PersonConfig { @Bean public Person person(Dog dog, Car car){ return new Person("dzzhyk", 20, true, dog, car); } @Bean public Dog dog(){ return new Dog("旺财", 5); } @Bean public Car car(){ return new Car("奥迪双钻", 100000); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
此时我们的XML配置文件可以完全为空了,此时应该使用AnnotationConfigApplicationContext来获取注解配置
/** * 使用JavaConfig配置 */ public class TestVersion2 { @Test public void test(){ AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(PersonConfig.class); Person person = ac.getBean("person", Person.class); System.out.println(person); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Bean 的生命周期
所有未实例化的 BeanDefinition bean定义,当bean.class被JVM类加载到内存中时,会被Spring扫描到一个map容器中:BeanDefinitionMap
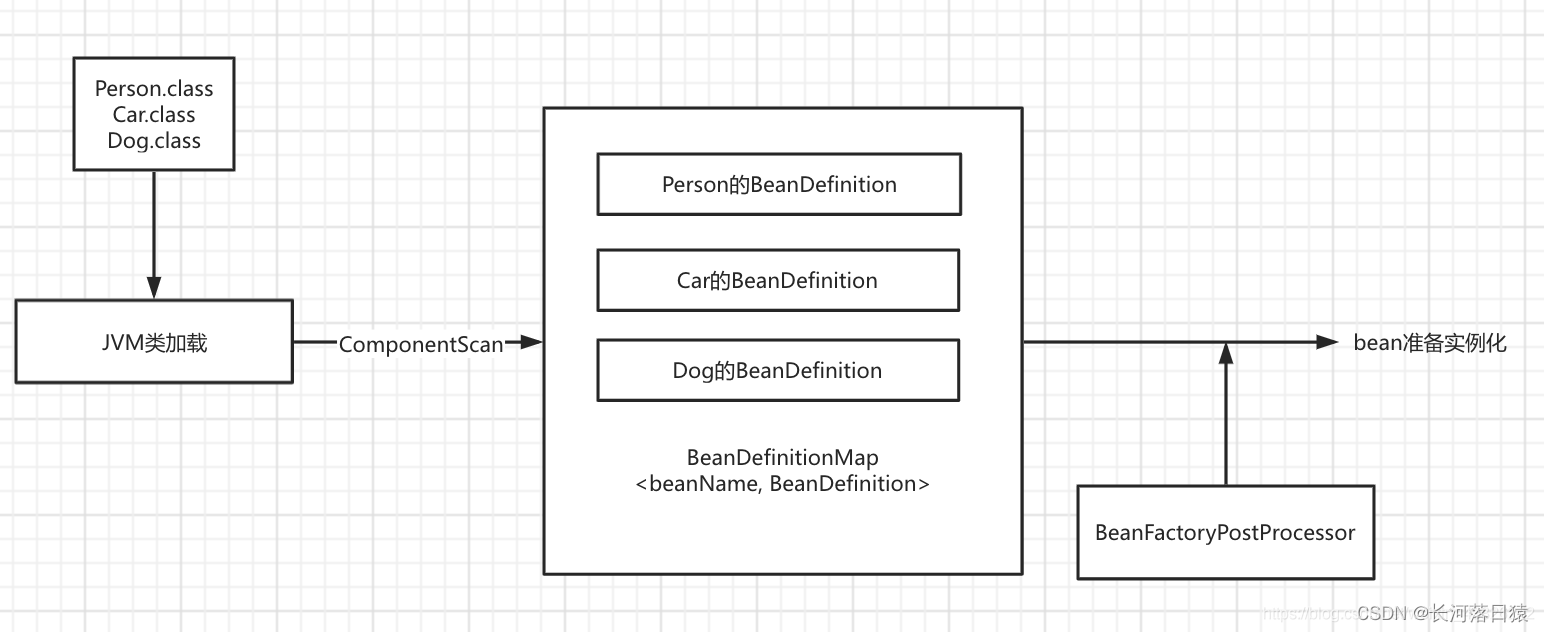
这就是SpringIOC容器的实现的过程,可以将BeanDefinitionMap到bean实例化的过程封装为一个类,这个就是常说的spring 容器(spring 工厂)
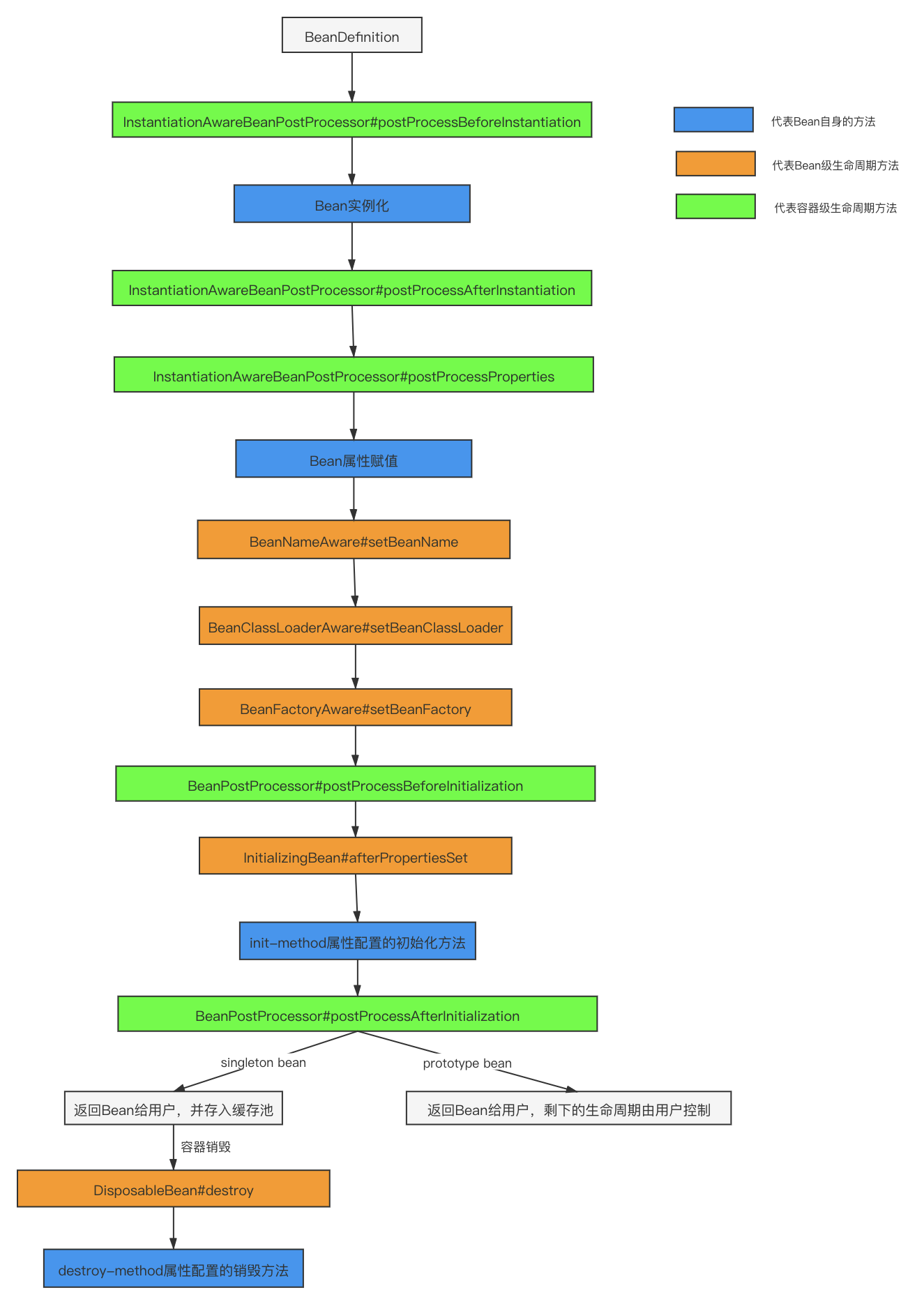
我们知道对于普通的 Java 对象来说,它们的生命周期就是:
实例化
该对象不再被使用时通过垃圾回收机制进行回收
而对于 Spring Bean 的生命周期来说:
实例化 Instantiation (执行构造方法)
属性赋值 Populate (执行set,get方法)
初始化 Initialization (执行init方法)
销毁 Destruction (执行destory 方法)
首先bean的类型不同生命周期不同,主要是单例和多例的创建和销毁区别
单例类型: singleton
随工厂启动创建 ==》 构造方法 ==》 set方法(注入值) ==》 init(初始化) ==》 构建完成 ==》随工厂关闭销毁
多例类型: prototype
被使用时创建 ==》 构造方法 ==》 set方法(注入值) ==》 init(初始化) ==》 构建完成 ==》JVM垃圾回收销毁
Spring IoC 容器初始化方法,AbstractApplicationContext#refresh() ,也是bean定义创建的开始
执行实例化之前会工厂后处理器BeanFactoryPostProcessor等一系列接口进行aop代理,生成代理类替换原本的 Bean
spring-boot-starter-web依赖导入了很多工程需要的资源,提供spring环境,mvc核心依赖,内嵌tomcat等
SpringBoot 自动装配流程如下:-
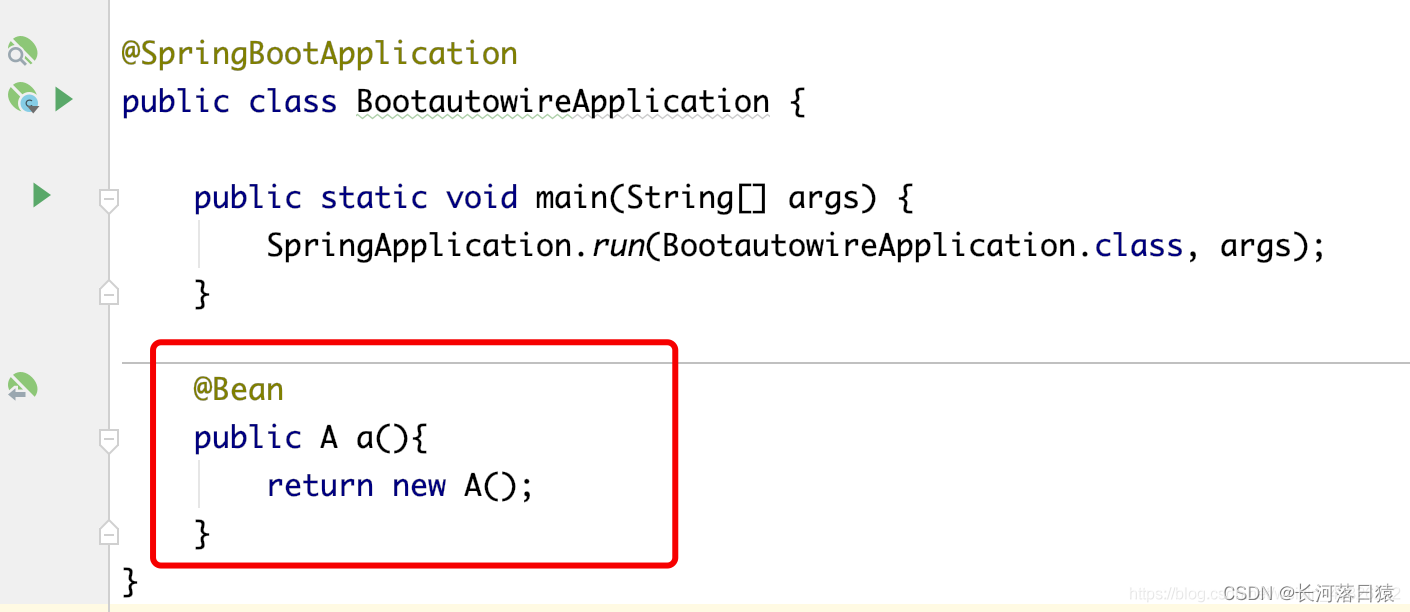
启动类添加了@SpringBootApplication注解,主要有@SpringBootConfiguration 配置类注解,@EnableAutoConfiguration自动化配置核心实现注解,@ComponentScan 包扫描注解,@SpringBootConfiguration中包含@Configuration,即一个JavaConfig配置类,可以在在SpringBoot启动类类中使用@Bean标签来配置类
-
SpringBoot主启动类的同级路径及子路径,扫描到特定的@Component、@Service、@Controler、@Repository、@Configuration等等注解后,会做相应的bean注册和配置文件bean注册工作。

-
@EnableAutoConfiguration 主要由注解@AutoConfiggurationPackage 负责项目中类的扫描和注册(不重要)和@Import 注解(关键)
-
@EnableAutoConfiguration 通过@Import 导入AutoConfigurationImportSelector 类,将扫描到的配置类进行自动装配
-
AutoConfigurationImportSelector 类实现了ImportSelector 接口,重写了selectImports()方法,这个方法返回的是要加载的Config配置文件的全包名列表,String数组,用于实现配置类的批量导入
-
方法selectImports() 通过loadFactoryNames方法加载扫描classpath(包目录) 下的META-INF/spring.factories 文件(这个就是记录的各种JavaConfig配置类名称,不过是properties文件且用键值对写法记录,然后选取需要的加载对应的配置类),读取需要实现的装配类,loadFactoryNames方法会先读取cache缓存中的,没有在读取磁盘的,减少磁盘IO

(先获取properties 对应的对象pro,然后调用pro.getProperty(“org.springframework.context.ApplicationListener” 即可得到对应的值,这里都是String)) -
通过条件筛选,把不符合条件的配置类剔除,最终返回需要的配置类,加载对应的bean 定义到bean定义Map中,实现自动化配置
Mysql索引在什么情况下会失效
查询条件包含or,可能导致索引失效
like通配符可能导致索引失效
联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
在索引列上使用mysql的内置函数,索引失效。
对索引列运算(如,+、-、*、/),索引失效。
索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
索引字段上使用is null, is not null,可能导致索引失效。
当整张表的数据很少的时候,或查询结果的数量很多的时候(大于10%),全表扫描比用索引快
MySql的存储引擎InnoDB与MyISAM的区别
- InnoDB支持事务,MyISAM不支持事务
- InnoDB支持外键,MyISAM不支持外键
- InnoDB 支持 MVCC(多版本并发控制),MyISAM 不支持
- Innodb不支持全文索引,而MyISAM支持全文索引(5.7以后的InnoDB也支持全文索引)
- InnoDB支持表、行级锁,而MyISAM支持表级锁。
- InnoDB表必须有主键,而MyISAM可以没有主键
- Innodb按主键大小有序插入,MyISAM记录插入顺序是,按记录插入顺序保存。
悲观锁和乐观锁
悲观锁就是 当前事务修改数据时,其他事务不能修改该数据,只能等当前事务结束
乐观锁 当前事务修改数据时,其他事务可以修改该数据,但只能有一个事务修改成功,其他都回滚
乐观锁实现: 版本号控制,修改数据时先查看版本号,在更改数据,如果版本号不一样就修改失败
sql语句:update a set name=lisi,version=version+1 where id=#{id} and version=#{version}
cas算法,内存存有原来的值,CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值
Redis 缓存和数据库 双写一致性问题
读数据都是先读redis缓存,缓存没有再读数据库,并将数据库的数据存入redis缓存。读不会有问题,只有更新时会出问题
问题: 数据库的数据和缓存的数据不一致
先更新数据库,再更新(删除)缓存
问题:先更新数据库,在删除缓存,若删除失败,缓存时旧数据,就会出现不一致
先删除缓存,再更新数据库,若更新失败,数据库是旧数据,缓存为空,数据就一致了(读到数据库数据更新到缓存中)
应用场景:并发量不高的情况下,可以先删缓存,再更细数据库
如果高并发出现这个问题解决很复杂,这里暂不讨论redis 为什么读写效率会更快
redis 数据存在内存中,大部分请求都是内存操作,不受硬盘I/O速度限制,所以快
数据结构是专门设计的,简单跨域问题
一个请求,其url的协议,域名,端口 三者任意一个与 当前url不同即为跨域,反向代理解决集合 HashMap 和HashTable
HashMap 线程不安全,允许使用null 作为key或是value
HashTable: key和value 都不能为null,线程安全,properties 的底层就是hashtable
如果需要线程安全,建议使用ConcurrentHashMap
HashTable的所有操作都会锁住整个对象,虽然能够保证线程安全,但是性能较差
ConcurrentHashMap是将Map 分成16 份(默认的),当“写”操作时只锁住操作的部分,其他线程还能操作其他部分HashMap存储结构:在jdk 1.8 之前是数组 +链表,jdk1.8之后是数组+链表+红黑树
存储时:使用key 的hashcode取模(以数组长度)决定元素存储在数组的什么位置,hashcode取模相同的key会存储在数组的同一个 位置上,形成链表
当链表长度大于8时,就会调用treeifyBin 函数将链表转为红黑树,当红黑树节点减少到6 时退化为链表HashMap扩容:
HashMap 的默认初始数组容量为16,加载因子为0.75
当数组的存储量大于容量的75%,HashMap 会进行一次扩容操作,一次扩容流程可划分为两个步骤:- resize: 创建一个新的Entry 空数组,长度为原数组的2倍
- rehash : 遍历原Entry数组,把所有的Entry的key重新计算在新数组中存储的位置,这个过程相对消耗性能
-
-
相关阅读:
初始 Java 集合框架
TwineCompile高级编译系统
《Spring Security 简易速速上手小册》第1章 Spring Security 概述(2024 最新版)
机器学习-特征映射方法
js JSON.stringify 对象转字符串
Socket网络编程(一)——网络通信入门&基本概念
【无标题】
TCP/IP_第八章_静态路由_实验案例一
激光位移传感器的原理及信号处理方式
【阿旭机器学习实战】【26】逻辑斯蒂回归----糖尿病预测实战
- 原文地址:https://blog.csdn.net/Xs943/article/details/127655518
