-
mysql索引常见问题
一、MyISAM与InnoDB之间区别
1、全表扫描
mysql没有建索引的话,则查询时间复杂度为O(N)2、InnoDB默认会有一个主键索引
自己没有指定主键的话,则会默认使用mysql自带rowid3、B+树
使用二叉树做索引:
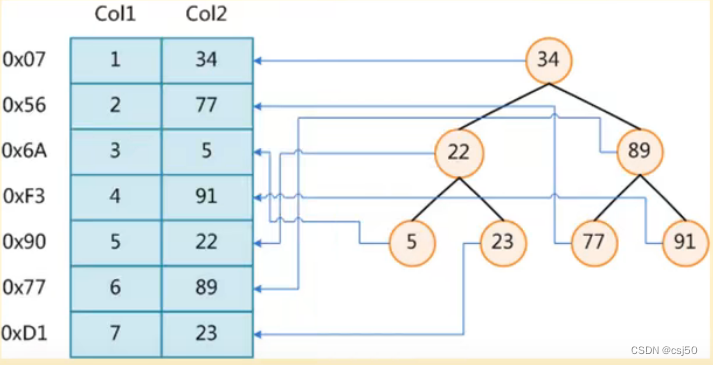
以34作为根,比它小的放左边,比它大的放右边。如果要查询Col2=89,全表扫描要查询6次,使用二叉树只要查询2次。
为什么变成B+树:
目的主要是减少磁盘io次数。
mysql底层读取数据,磁盘io操作的时候读取一个节点16k。
上面两行是非叶子节点,下面一块是叶子节点,聚集索引叶子节点包含了完整的数据记录。
二、为什么InnoDB引擎表必须有主键,并且推荐使用整型的自增方式
1、不建议使用uuid作为数据库主键,不支持范围查询
UUID当索引在建立b+树的时候,他会对字符串进行一个比较,而且在插入的时候,他并不是有序的。
而且UUID当作主键的时候,他占的存储空间肯定是比自增主键的大,所以在同一页空间中所存储的数据就可能小一些。2、B+树底层搜索的时候可能会发生值比较判断
比如id是主键,我要查询id>15的,自增序列一下子就能查到。3、为什么InnoDB非主键索引结构叶子节点存放主键值
(1)保持一致性
当数据库表进行DML操作时,同一行记录的页地址会发生改变,因非主键索引保存的是主键的值,无需进行更改。(2)节省存储空间
InnoDB数据本身就已经汇聚到主键索引所在的B+树上了, 如果普通索引还继续再保存一份数据,就会导致有多少索引就要存多少份数据。三、云数据库如何定位慢查询
1、定位慢查询
配置my.cnf参数2、explain定位查询该语句索引是否生效
四、执行计划explain如何使用
explain sql语句

1、explain中的id列
id列的编号是select的序列号,有几个select就有几个id,并且id的顺序是按select出现的顺序增长的。
mysql将select查询分为简单查询(simple)和复杂查询(primary)。
复杂查询分为三类:简单子查询、派生表(from语句中的子查询)、union查询。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。2、type列
这一列表示关联类型或访问类型,即mysql如何查找表中的行,查找数据行记录的大概范围。3、type列优先级
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > all
一般来说,得保证查询达到range级别,最好达到ref4、type级别说明
(1)all:全表扫描
Full Table Scan,mysql将遍历全表以找到匹配的行。(2)index:全表扫描索引文件(接近全表扫描)
Full Index Scan,index与all的区别为index类型遍历索引树。(3)range:索引范围扫描
只检索给定范围的行,使用一个索引来选择行。(4)ref:使用非唯一性索引或者唯一索引的前缀扫描
查询索引列上的值。(5)eq_ref:使用的是唯一索引
类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配。简单来说,就是多表连接中使用primary key或者union key作为关联条件。(6)const、system:使用的是主键
当mysql对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,mysql就能将该查询转换为一个常量。
system是const类型的特例,当查询的表只有一行的情况下,使用system。(7)null:mysql不用访问表或者索引就直接能到结果
mysql在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。五、explain type需要达到什么级别
1、起码要满足range级别
六、mysql索引什么是回表查询
1、InnoDB有两大索引
聚集索引(clustered index)
普通索引(secondary index)2、聚集索引
InnoDB聚集索引的叶子节点存储行记录,因此,InnoDB必须要有,且只有一个聚集索引。
如果没有创建主键,则InnoDB会创建一个隐藏的rowid作为聚集索引。3、普通索引
InnoDB普通索引的叶子节点存储主键值。4、回表查询
如果根据普通索引查询,普通索引叶子节点的data只存放了主键的id。
如果查询返回列表需要返回不在联合索引的字段,则会回表根据主键id查询到内容。需要扫描两遍索引树:
(1)先通过普通索引定位到主键值
(2)如果表定义了PK,则PK就是聚集索引
(3)再通过聚集索引定位到行记录这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
5、用联合索引查主键id不会回表查询,查非主键id、非联合索引内字段,要回表查询
七、mysql索引为什么需要遵循最佳左前缀法则
1、左前缀法则和联合索引有关
比如name, age, position建了联合索引:
张三,18,技术员
李四,16,学生
如果where后面没有出现name字段条件,则不会走到联合索引上。
where条件必须出现联合索引最左边的字段。八、超过多少张表需要禁止join
1、超过三个表禁止join
join查询效率非常低。需要join的字段,数据类型保持绝对一致。多表关联查询时,保证被关联的字段需要有索引。
多少张表join,就要发多少次select语句做查询。九、为什么不推荐存储过程
1、业务和数据库绑定
2、debug排错困难
十、一张表达到多少级别需要分表分库
1、mysql到千万级
十一、例子
建了4个字段的索引,为什么第一个语句3s内完成,第二个跑了3分钟都没结果?

根据索引查出来230万条数据,这时候是很快的。
但是后面又要根据type判断,你的索引没这个字段,所以它得回表查一遍这个字段。
这时候导致的速度慢。 -
相关阅读:
洛谷P3327 莫比乌斯反演,约数函数结论
Spring——Bean注入几种方式(放入容器)
面试官:Java中缓冲流真的性能很好吗?我看未必
My English grammar notes
【C++】C++11 包装器
【直播精彩回顾】数据改变社会,BI助力发展!
大麦 Android 选座场景性能优化全解析
【javaEE】网络原理(传输层Part2)
Collection集合体系(ArrayList,LinekdList,HashSet,LinkedHashSet,TreeSet,Collections)
多级CMakeLists.txt调用
- 原文地址:https://blog.csdn.net/csj50/article/details/127765099