-
多模态学习(一) 初识
一、博文推荐
多模态学习综述及最新方向
链接:
- 1. https://zhuanlan.zhihu.com/p/389287751 (简略版)
- 2. https://zhuanlan.zhihu.com/p/353681958 (详细版)
- 3. https://bbs.huaweicloud.com/blogs/264134 (归纳总结版本-推荐!)
- 4. https://zhuanlan.zhihu.com/p/475734302 (知乎)
来源文章:TPAMI综述文献
Multimodal machine learning: A survey and taxonomy.二、综述论文推荐
国内:
- 何俊,张彩庆,李小珍,张德海.面向深度学习的多模态融合技术研究综述[J].计算机工程,2020,46(05):1-11.DOI:10.19678/j.issn.1000-3428.0057370.
- 孙影影,贾振堂,朱昊宇.多模态深度学习综述[J].计算机工程与应用,2020,56(21):1-10.
- 陈鹏,李擎,张德政,杨宇航,蔡铮,陆子怡.多模态学习方法综述[J].工程科学学报,2020,42(05):557-569.DOI:10.13374/j.issn2095-9389.2019.03.21.003.
- 牟智佳,符雅茹.多模态学习分析研究综述[J].现代教育技术,2021,31(06):23-31.
三、什么是多模态机器学习?
学习来源: https://blog.csdn.net/electech6/article/details/85142769
每一种信息的来源或者形式,都可以称为一种模态。例如:
- 人有触觉,听觉,视觉,嗅觉;
- 信息的媒介,有语音、视频、文字等;
- 多种多样的传感器,如雷达、红外、加速度计等。
以上的每一种都可以称为一种模态。
多模态机器学习,英文全称 MultiModal Machine Learning (MMML),旨在通过机器学习的方法实现处理和理解多源模态信息的能力。目前比较热门的研究方向是图像、视频、音频、语义之间的多模态学习。
该博文参考了https://www.cs.cmu.edu/~morency/MMML-Tutorial-ACL2017.pdf,主要从以下五个方向进行了介绍。

1. 多模态表示学习
- 联合表示 : 联合表示将多个模态的信息一起映射到一个统一的多模态向量空间;
- 协同表示 : 协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)。
- 利用多模态表示学习到的特征可以用来做信息检索,也可以用于的分类/回归任务。
- 两个例子
– 表示学习 : 学习图片和文本的联合概率分布 P(图片,文本)。在应用阶段,输入图片,利用条件概率 P(文本|图片),生成文本特征,可以得到图片相应的文本描述;而输入文本,利用条件概率 P(图片|文本),可以生成图片特征,通过检索出最靠近该特征向量的两个图片实例,可以得到符合文本描述的图片

– 协同学习:狗的图片特征向量 - 狗的文本特征向量 + 猫的文本特征向量 = 猫的图片特征向量 -> 在特征向量空间,根据最近邻距离,检索得到猫的图片
2. 转化 Translation / 映射 Mapping
转化也称为映射,负责将一个模态的信息转换为另一个模态的信息。常见的应用包括
- 机器翻译
- 图片描述 或者 视频描述(Video captioning)
- 语音合成(Speech Synthesis)
模态间的转换主要有两个难点:
- 一个是open-ended,即未知结束位
例如实时翻译中,在还未得到句尾的情况下,必须实时的对句子进行翻译
- 另一个是subjective,即主观评判性
是指很多模态转换问题的效果没有一个比较客观的评判标准,也就是说目标函数的确定是非常主观的。
3. 对齐 Alignment
多模态的对齐负责对来自同一个实例的不同模态信息的子分支/元素寻找对应关系。
-
时间维度
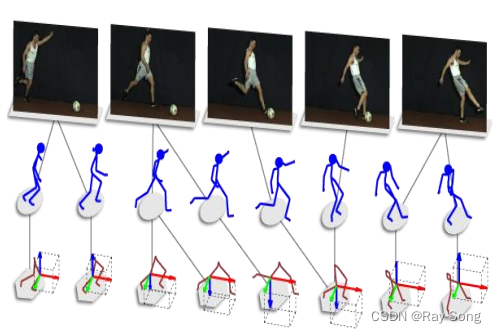
-
空间维度

4. 多模态融合 Multimodal Fusion
还存在其他常见的别名,
多源信息融合(Multi-source Information Fusion)
多传感器融合(Multi-sensor Fusion)。按照融合的层次,可以将多模态融合分为 pixel level,feature level 和 decision level 三类
难点:
- 主要包括如何判断每个模态的置信水平、
- 如何判断模态间的相关性、
- 如何对多模态的特征信息进行降维
- 如何对非同步采集的多模态数据进行配准等。
下面列举几个比较热门的研究方向。
1. 视觉-音频识别
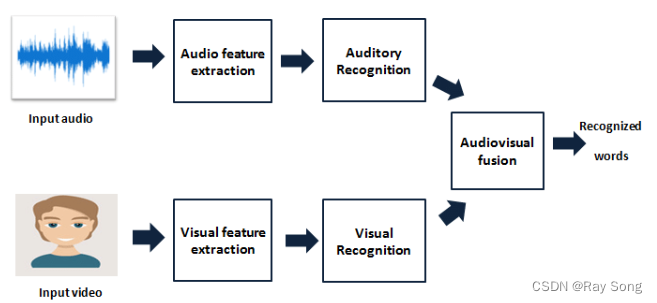
2. 多模态情感分析
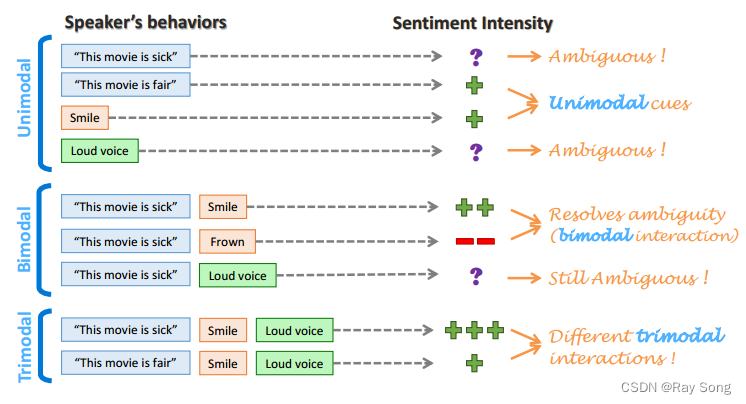
3.手机身份认证
综合利用手机的多传感器信息,认证手机使用者是否是注册用户。5. 协同学习 Co-learning
协同学习是指使用一个资源丰富的模态信息来辅助另一个资源相对贫瘠的模态进行学习。
- 迁移学习
迁移学习比较常探讨的方面目前集中在领域适应性问题上
还有zero-shot learning 与 one-shot learning. - 协同训练
负责研究如何在多模态数据中将少量的标注进行扩充,得到更多的标注信息。
-
相关阅读:
Spring Initializr私服搭建和定制化模板
java多线程之——停止线程多种方式
分析 java.util.LinkedHashMap
在Spring Boot中使用POI完成一个excel报表导入数据到MySQL的功能
20.Memento备忘录(行为型模式)
Redis数据类型——list类型数据的扩展操作
智能优化与机器学习结合算法实现数据分类matlab代码清单
ubuntn20.4安装git
springcache的使用详解(使用redis做分布式缓存)
Kafka 之 KRaft —— 配置、存储工具、部署注意事项、缺失的特性
- 原文地址:https://blog.csdn.net/rayso9898/article/details/127759469