-
mysql之order by工作原理
前言
order by相比大家都用过,它的用法我就不再多介绍了,今天我们主要是介绍order by在mysql 的中的工作原理,方便大家可以更加熟练的使用order by。
全字段排序
首先我们先创建一个表,下面是建表的sql语句
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后我们根据name排序,查出来前一千条,杭州的
select id,city,name,age,addr from t where city='杭州' order by name limit 1000 ;- 1
- 2
这里我们给city建一个索引,大家不要给city和name建一个联合索引(如果见了联合索引,这个直接就是有序的,他就不会再去排序了,我们就没法看到这个order by的执行过程了)。之后我们用explain语句看下这个sql 的执行过程。

这个extra中的using filesort,就是表示需要排序,然后mysql会给每一个线程分配一个sort buffer用来排序。然后这个排序过程大致分为一下几步
1.走索引查找到到city为杭州的城市的id
2.通过id将值取出来放到sortbuffer中
3.在sort buffer中,将数据按照name排序,取出前一千行,将结果返回上面就是order by在mysql中的大致执行过程
但是还有一个点就是,在使用sort buffer 排序的时候,可能会用到外部空间,当排序的数据大小大于sort buffer 的大小的时候,就会用到外部磁盘临时文件排序。下面是查看一个语句是否使用了磁盘临时文件排序
/* 打开optimizer_trace,只对本线程有效 */ SET optimizer_trace='enabled=on'; /* @a保存Innodb_rows_read的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 执行语句 */ select city, name,age from t where city='杭州' order by name limit 1000; /* 查看 OPTIMIZER_TRACE 输出 */ SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G /* @b保存Innodb_rows_read的当前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 计算Innodb_rows_read差值 */ select @b-@a;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
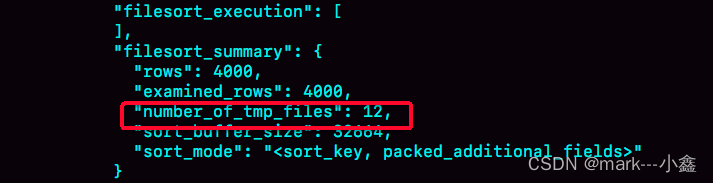
这个代表用了12快临时文件,外部排序使用的是归并排序。
select @b-@a 的返回结果是 4000,代表扫描了4000行
rowid排序
上面排序的时候,却将整行数据都放进去了,但是我只需要对name字段排序,那么其他字段是不是可以不要呢。答案当然是可以的。
SET max_length_for_sort_data = x;- 1
- 2
你可以将排序放入的每行记录设置一个大小,我就之放入name,那么sort buffer,就会存储的是city为杭州的4000行记录的name,然后排序得出前一千行name,再去主键索引树上取出对应的数据,返回给用户。
这样的话,确实放入sort buffer的数据变小了,但是却多了一次回表(这会增加时间损耗,那个外部临时时间排序也会增加时间损耗),而且扫描行数也会变成5000。
总结
如果可以的话,尽量将sort buffer 设置的大一点,能够将所有的排序数据放入其中,这样查询速度比较快,如果内存比较小的话,就可以使用rowid排序。总之就是,用空间换时间,或者用时间换空间(这是算法中常用的一种思想)。
-
相关阅读:
Redis功能实战篇之附近商户
PB从入坑到放弃(一)第一个HelloWorld程序
Centos7更新php7.2版本升级
USB插座外壳接地的处理和emi,esd考虑
【FPGA】verilog语法的学习与应用 —— 位操作 | 参数化设计
asio中的信号与定时器
this硬绑定
Nginx三大常用功能“反向代理,负载均衡,动静分离”
设计模式_命令模式
3D Web开发新篇章:threelab探索之旅
- 原文地址:https://blog.csdn.net/qq_41820066/article/details/127756708
