-
降水检验项目展示(工作机会/私活请私信我)
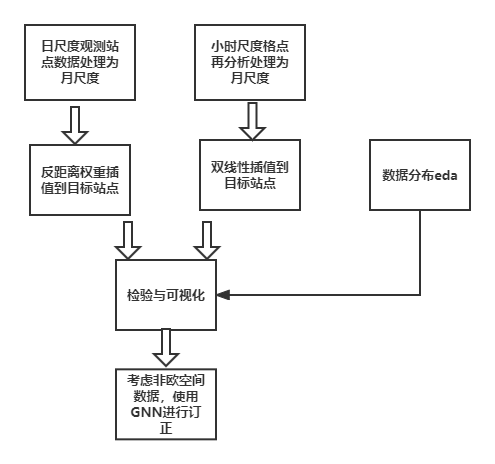
首先是工程思路设计考虑到数据是月尺度上的应用,那么在数据处理上可以不使用并行来节省时间,在计算过程中使用封装好的库来提高代码效率,优先使用矢量化计算
站点插值使用meteva库,格点使用常用的xarray
设计思路:
以2022年为例
step1 清洗目标台站数据
import glob as glob import numpy as np file_list = glob.glob('/home/mw/project/Y*.csv') file_list.sort() lon_lat = {'5173':[84.4249,43.3619],'5174':[84.4500,43.3249],'5175':[84.4402,43.2423],'5176':[84.2356,43.0849],'5177':[83.3329,42.3224],'5178':[83.2237,42.1153],'5179':[83.3007,42.1623]} #rint(file_list) import pandas as pd df_all = [] zhang = [] for num,dfname in enumerate(file_list): print(num,dfname) df = pd.read_csv(dfname,encoding='ISO-8859-1',sep=',',header=0) #print(df.shape) df.drop([0],inplace=True) if num==4: df.drop([len(df)],inplace=True) #print(df) df = df[['Station_Id_C','Year','Mon','Day','Hour','PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']] station_id = int(df.Station_Id_C.iloc[0][1:]) #print(station_id) #break df.rename(columns={'Mon':'Month'},inplace=True) df['datetime']=pd.to_datetime(df[['Year','Month','Day','Hour']]) #df['alldatetime']=pd.to_datetime(df[['Year','Month','Day','Hour']]) df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']] =df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']].astype('float') #df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_10mi','WIN_S_Max']][df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_10mi','WIN_S_Max']]>90000] = None def cahnge(var): if var>=90000: var = np.nan else: var = var return var df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']] = df[['PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']].applymap(cahnge) tempdf = df[['Station_Id_C','datetime','Hour','PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']] df = df[['datetime','Hour','PRS','TEM','TEM_Max','DPT','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max']] import datetime df = df[df.datetime>pd.to_datetime('20220101')] zhang.append(tempdf) finalldf = df.groupby(df.datetime.dt.month).agg({'PRS':'mean','TEM':'mean','TEM_Max':'max','DPT':'mean','RHU':'mean','PRE_1h':'sum','WIN_S_Avg_2mi':'mean','WIN_S_Max':'max'}) finalldf['id'] = station_id keyval = lon_lat.get(str(station_id)) lon,lat = keyval[0],keyval[1] #print(lon,lat) finalldf['lat'] = lat finalldf['lon'] = lon finalldf = finalldf.reset_index() #print(finalldf) #break df_all.append(finalldf) alldf = pd.concat(df_all)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
step2 清洗处理观测台站数据
import pandas as pd import numpy as np #Cleanse obs data obdf = pd.read_excel('/home/mw/project/独库20220101-20221004日资料.xlsx') timedf = obdf[['年','月','日']] timedf.columns = ['year', 'month', 'day'] obdf['datetime'] = pd.to_datetime(timedf[['year', 'month', 'day']]) obdf.columns obsta = obdf.iloc[:,[1,2,3,8,9,10,12,13,15,17,19]] obsta.replace(999999.0,np.nan,inplace=True) obsta.replace(999990.0,np.nan,inplace=True) obdff = obsta obdff.columns = ['id','lat','lon','PRS','TEM','TEM_Max','RHU','PRE_1h','WIN_S_Avg_2mi','WIN_S_Max','datetime'] len(obdff.id.unique()) obdff.lon.max() finalobdff = obdff.groupby([obdff.id,obdff.datetime.dt.month]).agg({'PRS':'mean','TEM':'mean','TEM_Max':'max','RHU':'mean','PRE_1h':'sum','WIN_S_Avg_2mi':'mean','WIN_S_Max':'max','lat':'mean','lon':'mean'}) finalobdff.reset_index(inplace=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
step3 使用meteva的接口统一格式
import meteva.base as meb obout = finalobdff length = len(finalobdff.columns) col = finalobdff.columns obout.columns = [i for i in range(length)] # change data format to meteva format obsta = meb.sta_data(obout,col) obsta['time'] = obsta['datetime'] obsta = obsta[obsta.time<=9] # interp_data is target 9 station target = alldf target['time'] = target['datetime'] length = len(target.columns) col = target.columns target.columns = [i for i in range(length)] targetsta = meb.sta_data(target,col) #targetsta.time.unique() tg = targetsta.drop(['level','dtime','datetime'],axis=1) obsta.id.unique() import copy org_tg = copy.deepcopy(tg) tg.iloc[:,4:] = np.nan obsta.level = 500 obsta.dtime = 24 tg['level'] = 500 tg['dtime'] = 24 obsta = obsta.drop('datetime',axis=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
step4 数据eda分析
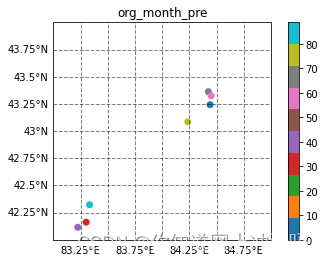
目标台站分布有明显的聚类
%matplotlib inline import matplotlib.pyplot as plt import cartopy.crs as ccrs import cmaps import numpy as np import cartopy.io.shapereader as shpreader from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER fig = plt.figure(figsize=(15, 12)) ax = plt.axes(projection=ccrs.PlateCarree()) ax.set_extent([82, 86 ,42 ,45]) sc = ax.scatter(obsta.lon, obsta.lat,c=[2]*len(obsta.lon) , marker='o',transform=ccrs.PlateCarree()) sc2 = ax.scatter(tg.lon, tg.lat,c=['g']*len(tg.lon) , s=100,marker='*',transform=ccrs.PlateCarree()) #province = shpreader.Reader('./work/province.shp') #nineline = shpreader.Reader('./work/nine_line.shp') #ax.add_geometries(province.geometries(), crs=ccrs.PlateCarree(), linewidths=0.5,edgecolor='k',facecolor='none') #3ax.add_geometries(nineline.geometries(), crs=ccrs.PlateCarree(),linewidths=0.5, color='k') gl = ax.gridlines(draw_labels=True, linewidth=1, color='k', alpha=0.5, linestyle='--') gl.xlabels_top = False #关闭顶端标签 gl.ylabels_right = False #关闭右侧标签 gl.xformatter = LONGITUDE_FORMATTER #x轴设为经度格式 gl.yformatter = LATITUDE_FORMATTER #y轴设为纬度格式 #ax.stock_img() plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

step5 台站反距离权重插值
# main progress var_namelist = list(tg.loc[:,'PRS':].columns) var_namelist.pop(-1) var_namelist.pop(-1) import copy #org_tg = copy.deepcopy(tg) tg[var_namelist]= np.nan interp_tg = tg.copy() interp_tg.loc[:,var_namelist] = np.nan for name in var_namelist: if name == 'DPT': continue print(name) for time in tg.time.unique(): obs_onetime = pd.concat([obsta.iloc[:,[0,1,2,3,4,5]],obsta.loc[:,name]],axis=1)[pd.concat([obsta.iloc[:,[0,1,2,3,4,5]],obsta.loc[:,name]],axis=1).time==time] tg_onetime = pd.concat([tg.iloc[:,[-2,0,-1,1,2,3]],tg.loc[:,name]],axis=1)[pd.concat([tg.iloc[:,[-2,0,-1,1,2,3]],tg.loc[:,name]],axis=1).time==time] obs_onetime = obs_onetime.dropna(axis=0,how='any') interpsta = meb.interp_ss_idw(obs_onetime,tg_onetime,effectR=50, nearNum=50) #print(obs_onetime) #print(tg_onetime) #print(interpsta[name]) interp_tg.update(interpsta)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
step6 格点再分析资料处理以及双线性插值
import warnings warnings.filterwarnings("ignore") import glob file = glob.glob(r'/home/mw/input/dukuall6680//duku/20220[0-9]') import numpy as np import xarray as xr import cfgrib all_list = [] for fil in file: #print(fil) name = fil+'/*' #print(name) dayfile = glob.glob(name) #print(dayfile) for day in dayfile: dayname = day+'/*-PRE-*20.GRB2' daydata = glob.glob(dayname) #print(daydata) for giao in daydata: #print(giao) try: data = xr.open_dataset(giao, engine='cfgrib') xjlon = data.longitude[(data.longitude>=70)&(data.longitude<=100)] xjlat = data.latitude[(data.latitude>=30)&(data.latitude<=50)] data = data.sel(latitude=xjlat,longitude=xjlon).unknown data = xr.where(data>1000,np.nan,data) except: data = None all_list.append(data) finalldata = xr.concat(all_list,'time')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
grid_tg = tg.copy() position = tg[tg.time==1] grid_interp = refinedata.interp(longitude= position.lon,latitude = position.lat) values = grid_interp.sel(longitude = position.lon[0],latitude = position.lat[0]) for n ,time in enumerate(tg.time.unique()): #print(time) values = grid_interp.sel(longitude = position.lon[0],latitude = position.lat[0],) val_list = [] for lon,lat in zip(position.lon,position.lat): #print(lon,lat) values = grid_interp.sel(longitude = lon,latitude = lat) #print(values) values = values[values.month==time].values[0] #print(values) val_list.append(values) grid_tg.loc[grid_tg.time==time,'PRE_1h'] = val_list- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
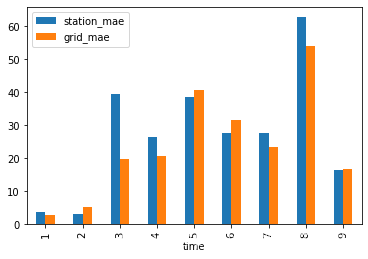
检验及可视化
newdf['org_pre'] = org_tg['PRE_1h'] newdf['station_interp'] = interp_tg['PRE_1h'] newdf['grid_interp'] = grid_tg['PRE_1h'] newdf['station_mae'] = np.abs(newdf['station_interp']-newdf['org_pre']) newdf['grid_mae'] = np.abs(newdf['grid_interp']-newdf['org_pre']) newdf['grid_relmae'] = newdf['grid_mae']/newdf['org_pre'] newdf['station_relmae'] = newdf['station_mae']/newdf['org_pre'] newdf.groupby(newdf.time).mean()[['station_mae','grid_mae']].plot.bar()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
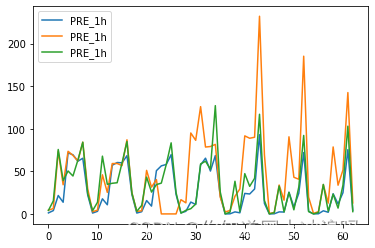
时间角度检验结果
空间分布检验
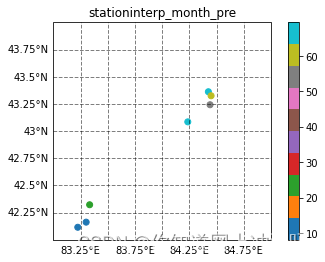
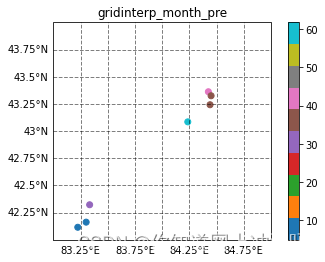
step7图网络订正数据demo


那么图上的卷积如何操作:
利用消息传递和邻居聚集操作完成一次hidden state的更新
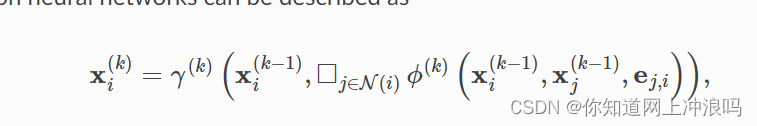
文档给出了构建的流程

edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))- 1
在聚合中边可以赋予权重
接下来是构建Dataset类
可以继承一个父类diy自己的数据集
但是鉴于demo我们可是使用一种更简单的方法

简单起见构造一个无向图边上无权重,降水值为tg,其他诸如湿度风向作为特征,所有节点之间都有边简单的特征工程
#min_max_zscore import numpy as np factor = df[['PRS','TEM','RHU','WIN_S_Max']] factor = factor.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x))) factor['pre'] = df['PRE_1h'] tg = ob['PRE_1h']- 1
- 2
- 3
- 4
- 5
- 6
首先我们构造节点和边矩阵
我们用这种方法可以扩充函数,加入判断逻辑,即多少km范围内才算邻域
node_id = df.id.unique() df[['id','lon','lat']] star_list = [] end_list = [] for star_n,star_node in enumerate (df.id.unique()): #print(star_n,star_node) for end_n,end_node in enumerate (df.id.unique()): if star_n != end_n: #自己不能跟自己练成边 if True: #这里可以判断距离逻辑从而选择领域节点 star_list.append(star_n) end_list.append(end_n) edge_list = [star_list,end_list] edge_index = torch.tensor(edge_list, dtype=torch.long)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
构造demo数据集
#demo按照月拆分,8个月训练一个与预测 shape = factor.values.shape xdata = factor.values.reshape(shape[0]//len(node_id ),len(node_id),-1) xall = torch.tensor(xdata, dtype=torch.float) dataset = [xall[i] for i in range(8)]- 1
- 2
- 3
- 4
- 5
构建简单的GCN网络,这里使用残差结构
这里有个问题就是如果每个节点都互有边的话,那么实际上就没有局部信息一说了
import torch import torch.nn.functional as F import torch.nn as nn from torch_geometric.nn import GCNConv class GCN(torch.nn.Module): def __init__(self): super().__init__() self.conv1 = GCNConv(5, 16) self.conv2 = GCNConv(16, 16) self.linear = Linear(16, 40) self.linear2 = Linear(40, 1) def forward(self, data): xorg = data.x.clone() xorg = xorg[:,-1].unsqueeze(1) x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) x = F.relu(x) #x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) #print(x.shape) x = self.linear(x) x = self.linear2(x) #print(x.shape) return x+xorg- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
训练
model = GCN() data = data optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4) lossf = nn.MSELoss() model.train() lossgiao = [] for epoch in range(200): temploss = [] for data,y in zip(dataset,ydataset): optimizer.zero_grad() data = Data(x=data, edge_index=edge_index) out = model(data) loss = lossf(out, y) #print(loss) temploss.append(loss.item()) loss.backward() optimizer.step() lossgiao.append(torch.mean(torch.Tensor(temploss)))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
loss图
inference
过拟合一个case效果plt.plot(out.squeeze().detach().numpy(),c='b') plt.plot(ydataset[0].squeeze().detach().numpy(),c='r') plt.plot(dataset[0][:,-1].squeeze().detach().numpy(),c='g')- 1
- 2
- 3

这效果只能一给我里giaogiao,寄寄寄
进阶分析
上述demo完成大约用了三天时间,可谓baseline中的baseline,糙之又糙,接下来进行优化思路
整体思路改进
模块处于整体哪个位置

显然本demo如果在一个完整的项目里处于第二个模块当然这是我自己yy的
那么根据结果进行原因分析:
-
在月数据上进行插值无论是站点-》站点还是格点-》站点误差都很大
-
在站点和格点数据预处理时没有eda和进一步分析
-
使用简单的图结构订正效果并不好,尽管是个小case但问题有两点:
(1)关于边的问题,7个站实在是太少了,没法利用卷积的局部提取信息,因为它本身就太局部了
(2)mse的原因导致过拟合一个例子都费劲
根据第一个思路,应该将月尺度的数据处理,转到精度更高的日尺度数据处理上甚至是小时尺度
思考理由:在月尺度上插值,简单的插值会忽略地形分布造成的局部不同地区的气候分布极大差异,如山迎风侧和背风气候态的不同
模型需要在局部地区找到居于地形分布条件下以及气候稳定背景(定长波,高低压系统)的观测与插值数据的偏差映射模式
首先是数据处理改进思路:

可视化和评估检验没有太多问题
- MAE,相对MAE
- 空间相关系数
- 各阶矩
- 日尺度数据上可以计算概率分布的距离如KL散度,JS散度等
如何改进订正思路

--------------------------后续将抽时间完善此项目----------------------------- -
相关阅读:
javaweb-响应字符数据
童年经典,任天堂switch红白机游戏
深入解析:批处理文件中EOF命令的妙用
这家公司因Log4j漏洞惨遭黑客攻击并勒索500万美元
路由查找原理
echarts柱状图上方的数值为0时设置不展示
Spring MVC 中文文档
前后端分离项目,vue+uni-app+php+mysql订座预约小程序系统设计与实现
备战2023秋招,应届生应做好哪些准备
TCP/IP网络江湖——数据链路层的协议与传承(数据链路层中篇:数据链路层的协议与帧)
- 原文地址:https://blog.csdn.net/weixin_44695861/article/details/127747995
