-
【每周研报复现】AI量化特征工程之alphalens:一套用于分析 alpha 因子的通用工具
原创文章第98篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
星球有一个活动,“每周研报复现”。
今天的主题正好是特征工程的框架alphalens,我找了一篇中文关于alphalens的研报,用python代码来复现一下。
Alphalens 是一款 Python 的工具包,是 Quantopian 公司旗下三大开包之一,另外两个分别是 Zipline 和 Pyfolio。
Alphalens 因其简单易用而又稳定科学的优势被广泛的量化分析师所青睐。本文主要介绍 Alphalens 的回测框架,提纲挈领地介绍了其中四个功能:因子收 益、因子 IC、因子换手以及事件研究。
运用 Alphalens,我们可以在做因子研究的过程中花更少的时间编写和运行回测 框架。因此,我们可以更快地进行思维风暴,而不必怀疑算法最终的结果。用 Alphalens 构建严谨的工作流程将使策略的稳定性提高并且不易过拟合。
alphalens是一套用于分析 alpha 因子的通用工具。
01 数据准备
我们今天使用标普500指数,tushare上国内指数与国际指数是两个不同的接口,但使用类似。具体可能参考前面的文章:
hdf5:兼容pandas的dataframe合适量化的存储格式
格式化后写入hdf5备用:

02 特征工程
我们使用最常见的动量因子来演示:mom_20。即过去20天指数的收益率。
首先,我们要做的就是数据的预处理。可以说,只要做好这一步几乎就完成了 95%的工作。而这一步其实也非常简单,只需要用一个函数实现即可。下面我们将 全面解读这个函数。我们先看一下这个函数 get_clean_factor_and_forward_returns,它的描述是“将 因子数据、价格数据以及行业分类按照索引对齐地格式化到一个数据表中,这个数 据表的索引是包含日期和资产的多重索引”,我们理解就是获取清洗后的因子及其 未来收益(可以包含行业,也可以不包含行业),并将它们的收益对齐。
到这个函数有 2 个输入变量:股票的因子值(factor), 股票的价格(prices),以及 7 个参数变量:股票的行业分组(groupby),是否按行 业分组(by_group),分组个数(quantiles),直方图个数(bins),因子换手周期(periods),异常值阀值设定(filter_zscore),行业分组标签(groupby_labels)。
import pandas as pd symbols = ['000905.SH', '000300.SH'] dfs = [] with pd.HDFStore('data/index.h5') as store: for symbol in symbols: df = store[symbol] df['factor'] = df['close'].pct_change(18) df = df[['close', 'code', 'factor']] df['close'] = df['close'] / df['close'].iloc[0] dfs.append(df) all = pd.concat(dfs) all.set_index([all.index, 'code'], inplace=True) all.dropna(inplace=True) all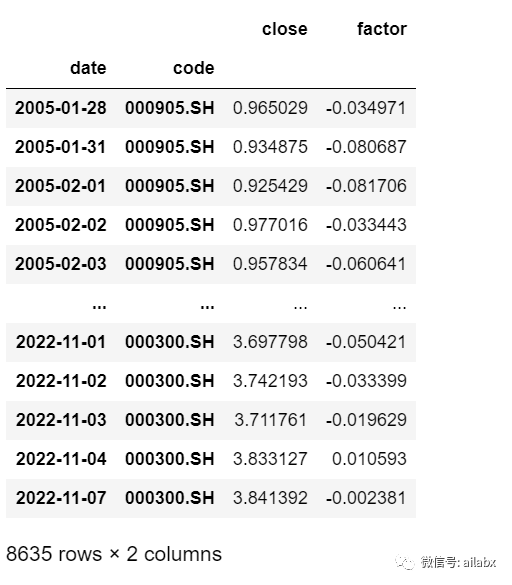
把收盘价使用pivot_table单独整体:
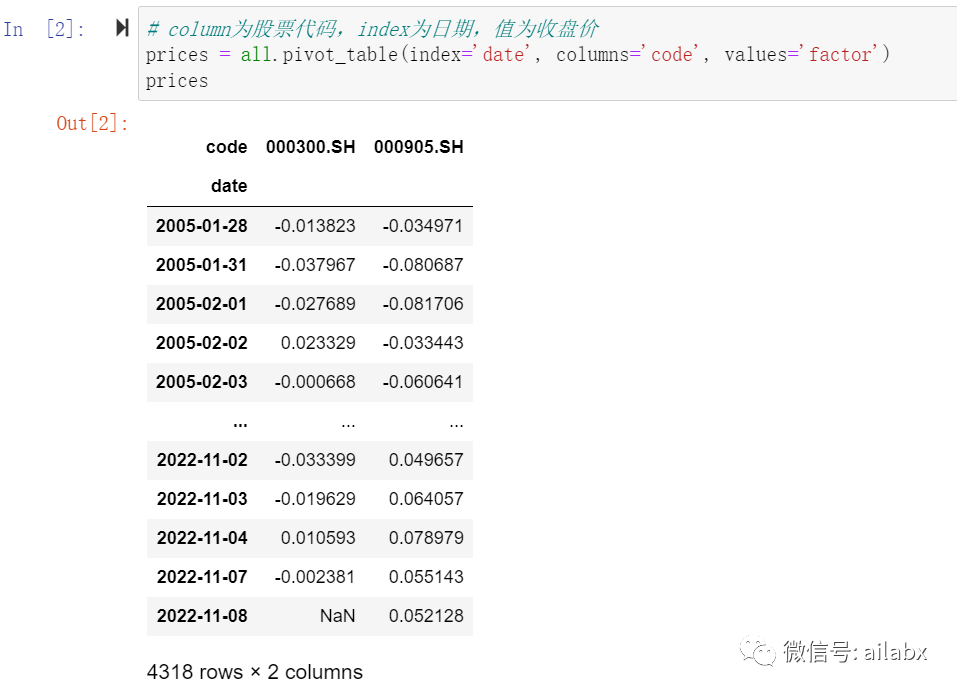
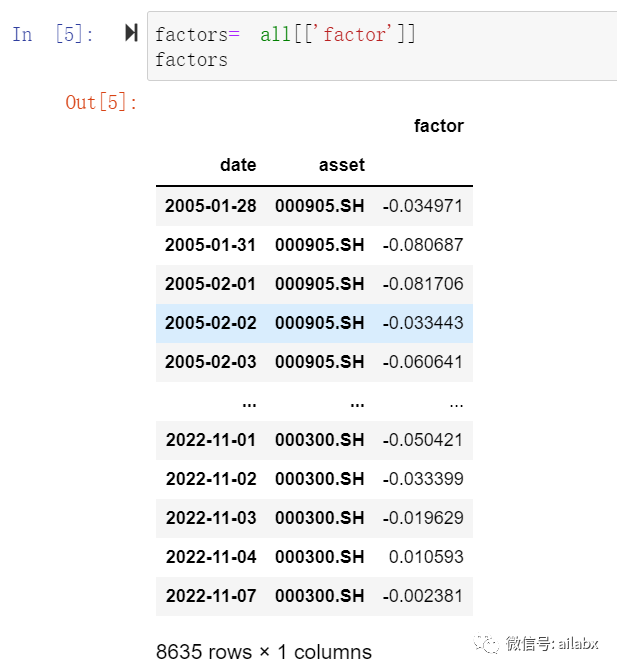
factors比较简单,直接取这一列即可。
把这两个数据整理完,alphalens的工作基本完成了90%以上!
from alphalens.utils import get_clean_factor_and_forward_returns #将tears.py中的get_values()函数改为to_numpy() ret = get_clean_factor_and_forward_returns(all[['factor']], prices) ret


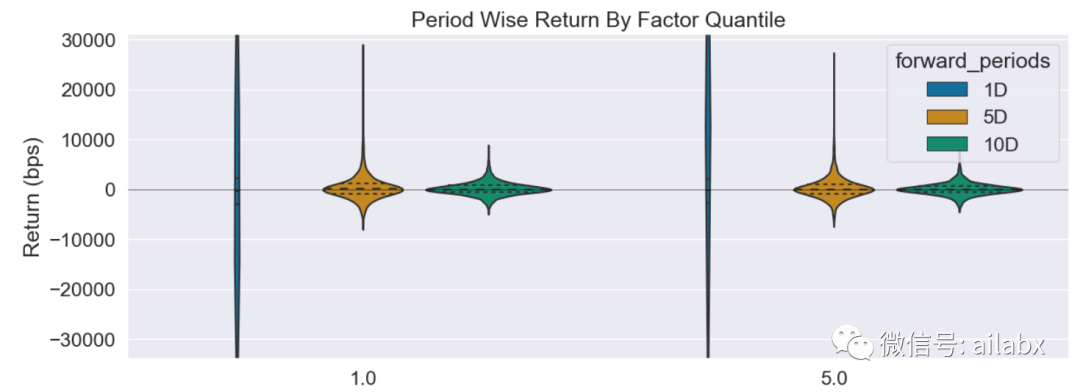
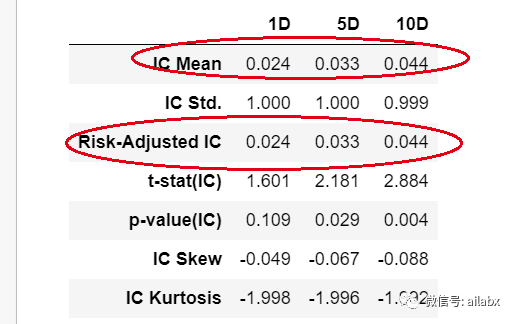
过去20天的动量值对于未来10天的收益是有正IC的,所以我们使用简单的20天动量的回测策略,着实收益还不错。
小结:
alphalen的使用比较简单,但数据整理需要小心,格式不对调不过去。需要对pandas的multiindex比较熟悉。
剩下的部分就是对结果的解读了,明天继续。
使用的代码、数据以及notebook在星球可下载。
最近文章:
hdf5:兼容pandas的dataframe合适量化的存储格式
-
相关阅读:
51单片机音乐闹钟秒表倒计时整点报时多功能电子钟万年历数码管显示( proteus仿真+程序+原理图+报告+讲解视频)
uniapp 解决跨域的问题
Triangle Attack: A Query-efficient Decision-based Adversarial Attack
git常用命令和开发常用场景
day007
JMeter + Ant + Jenkins持续集成-接口自动化测试
【每日一题】补档 CF1765N. Number Reduction | 单调栈 | 简单
【Ansible】02
docker 映射端口穿透内置防火墙
PTA 7-87 A±B
- 原文地址:https://blog.csdn.net/weixin_38175458/article/details/127755895