-
sklearn基础篇(四)-- k近邻算法
1 引言
K近邻法(k-nearest neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用。比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出了。这里就运用了KNN的思想。KNN方法既可以做分类,也可以做回归,这点和决策树算法相同。
KNN做回归和分类的主要区别在于最后做预测时候的决策方式不同。KNN做分类预测时,一般是选择多数表决法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。而KNN做回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。
2 算法模型
2.1 算法三要素
KNN算法我们主要要考虑三个重要的要素,对于固定的训练集,只要这三点确定了,算法的预测方式也就决定了。这三个最终的要素是k值的选取,距离度量的方式和分类决策规则。
1. 距离度量
特征空间中的两个实例点的距离是两个实例点相似程度的反映。距离越近(数值越小), 相似度越大。
这里用到了 L p L_p Lp距离, 可以参考前面的文章,矩阵篇(一)-- 向量范数与矩阵范数的认识
- p = 1 p=1 p=1 对应 曼哈顿距离
- p = 2 p=2 p=2 对应 欧氏距离
- 任意 p p p 对应 闵可夫斯基距离
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i, x_j)=\left(\sum_{l=1}^{n}{\left|x_{i}^{(l)}-x_{j}^{(l)}\right|^p}\right)^{\frac{1}{p}} Lp(xi,xj)=(l=1∑n∣ ∣xi(l)−xj(l)∣ ∣p)p1

考虑二维的情况,上图给出了不同的 p p p值情况下与原点距离为1的点的图形。这个图有几点理解下:
- 与原点距离为1的点
- 前一点换个表达方式,图中的点向量( x 1 x_1 x1, x 2 x_2 x2)的 p p p范数都为1
- 图中包含多条曲线,关于p=1并没有对称关系
- 定义中 p ⩾ 1 p\geqslant1 p⩾1,这一组曲线中刚好是凸的
2. k k k值选择
对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
二分类问题, k k k选择奇数有助于避免平票。
3. 分类决策规则
决策规则一般是采用“少数服从多数”的思想。对于分类问题,这 k 个最近的样本中分类最多的类型即为该新样本点的类型;对于回归问题,将这 k 个最近的样本对应的标签值进行平均即为该新样本点的预测值。
3 KD树
3.1 KD树的建立
kd树是一种对 k k k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。
kd树是二叉树,表示对 k k k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将 k k k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点对应于一个 k k k维超矩形区域。如下图所示:

构造kd树的方法如下:
构造根结点,使根结点对应于 k k k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对 k k k维空间进行切分,生成子结点。在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域;
(子结点);这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数
(median)为切分点,这样得到的kd树是平衡的。注意,平衡的kd树搜索时的效率未必是最优的。具体流程如下图:

1. 构造平衡kd树算法
输入: k k k维空间数据集 T = { x 1 , x 2 , … , x N } T=\{x_1,x_2,…,x_N\} T={x1,x2,…,xN},
其中 x i = ( x i ( 1 ) , x i ( 2 ) , ⋯ , x i ( k ) ) T x_{i}=\left(x_{i}^{(1)}, x_{i}^{(2)}, \cdots, x_{i}^{(k)}\right)^{\mathrm{T}} xi=(xi(1),xi(2),⋯,xi(k))T , i = 1 , 2 , … , N i=1,2,…,N i=1,2,…,N;
输出:kd树。
(1)开始:构造根结点,根结点对应于包含 T T T的 k k k维空间的超矩形区域。
选择 x ( 1 ) x^{(1)} x(1)为坐标轴,以T中所有实例的 x ( 1 ) x^{(1)} x(1)坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 x ( 1 ) x^{(1)} x(1)垂直的超平面实现。
由根结点生成深度为1的左、右子结点:左子结点对应坐标 x ( 1 ) x^{(1)} x(1)小于切分点的子区域, 右子结点对应于坐标 x ( 1 ) x^{(1)} x(1)大于切分点的子区域。
将落在切分超平面上的实例点保存在根结点。
(2)重复:对深度为 j j j的结点,选择 x ( 1 ) x^{(1)} x(1)为切分的坐标轴, l = j ( m o d k ) + 1 l=j(modk)+1 l=j(modk)+1,以该结点的区域中所有实例的 x ( 1 ) x^{(1)} x(1)坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴 x ( 1 ) x^{(1)} x(1)垂直的超平面实现。
由该结点生成深度为 j + 1 j+1 j+1的左、右子结点:左子结点对应坐标 x ( 1 ) x^{(1)} x(1)小于切分点的子区域,右子结点对应坐标 x ( 1 ) x^{(1)} x(1)大于切分点的子区域。
将落在切分超平面上的实例点保存在该结点。
(3)直到两个子区域没有实例存在时停止。从而形成kd树的区域划分。
3.2 KD树搜索最近邻
当我们生成KD树以后,就可以去预测测试集里面的样本目标点了。对于一个目标点,我们首先在KD树里面找到包含目标点的叶子节点。以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。如果不相交那就简单了,我们直接返回父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。

从上面的描述可以看出,KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
3.3 KD树预测
有了KD树搜索最近邻的办法,KD树的预测就很简单了,在KD树搜索最近邻的基础上,我们选择到了第一个最近邻样本,就把它置为已选。在第二轮中,我们忽略置为已选的样本,重新选择最近邻,这样跑k次,就得到了目标的K个最近邻,然后根据多数表决法,如果是KNN分类,预测为K个最近邻里面有最多类别数的类别。如果是KNN回归,用K个最近邻样本输出的平均值作为回归预测值。
4 球树
KD树算法虽然提高了KNN搜索的效率,但是在某些时候效率并不高,比如当处理不均匀分布的数据集时,不管是近似方形,还是矩形,甚至正方形,都不是最好的使用形状,因为他们都有角。一个例子如下图:
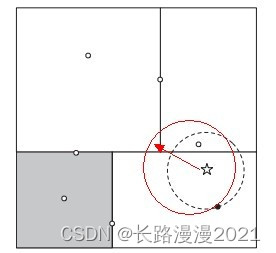
如果黑色的实例点离目标点星点再远一点,那么虚线圆会如红线所示那样扩大,导致与左上方矩形的右下角相交,既然相 交了,那么就要检查这个左上方矩形,而实际上,最近的点离星点的距离很近,检查左上方矩形区域已是多余。于此我们看见,KD树把二维平面划分成一个一个矩形,但矩形区域的角却是个难以处理的问题。
为了优化超矩形体导致的搜索效率的问题,牛人们引入了球树,这种结构可以优化上面的这种问题。
4.1 球树的建立
球树,顾名思义,就是每个分割块都是超球体,而不是KD树里面的超矩形体。

我们看看具体的建树流程:
-
- 先构建一个超球体,这个超球体是可以包含所有样本的最小球体。
-
- 从球中选择一个离球的中心最远的点,然后选择第二个点离第一个点最远,将球中所有的点分配到离这两个聚类中心最近的一个上,然后计算每个聚类的中心,以及聚类能够包含它所有数据点所需的最小半径。这样我们得到了两个子超球体,和KD树里面的左右子树对应。
- 3)对于这两个子超球体,递归执行步骤2). 最终得到了一个球树。
可以看出KD树和球树类似,主要区别在于球树得到的是节点样本组成的最小超球体,而KD得到的是节点样本组成的超矩形体,这个超球体要与对应的KD树的超矩形体小,这样在做最近邻搜索的时候,可以避免一些无谓的搜索。
4.2 球树搜索最近邻
使用球树找出给定目标点的最近邻方法是首先自上而下贯穿整棵树找出包含目标点所在的叶子,并在这个球里找出与目标点最邻近的点,这将确定出目标点距离它的最近邻点的一个上限值,然后跟KD树查找一样,检查兄弟结点,如果目标点到兄弟结点中心的距离超过兄弟结点的半径与当前的上限值之和,那么兄弟结点里不可能存在一个更近的点;否则的话,必须进一步检查位于兄弟结点以下的子树。
检查完兄弟节点后,我们向父节点回溯,继续搜索最小邻近值。当回溯到根节点时,此时的最小邻近值就是最终的搜索结果。
从上面的描述可以看出,KD树在搜索路径优化时使用的是两点之间的距离来判断,而球树使用的是两边之和大于第三边来判断,相对来说球树的判断更加复杂,但是却避免了更多的搜索,这是一个权衡。

5 代码实现
5.1 Python
import numpy as np def distance(X, b, p = 2): """ 计算距离 参数 ---------- X : 特征矩阵 b : 特征向量 p : 距离范数,默认为 2,即欧式距离 """ return np.linalg.norm(X - b, ord = p, axis = 1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1. 实现 kd 树
class KdNode: """ 功能:k-d 树结点 """ def __init__(self, feature, value, index, left = None, right = None): self.feature = feature # 结点对应特征的维度下标 self.value = value # 结点对应训练集的特征值;当结点为叶子结点时,为特征向量 self.index = index # 结点对应训练集的下标;当结点为叶子结点时,为下标向量 self.left = left # 左子树 self.right = right # 右子树 class KdTree: """ 功能:k-d 树算法实现 参数 ---------- X : 特征矩阵 leaf_size : 叶子节点包含的最大特征矩阵数量,默认为 10 """ def __init__(self, X, leaf_size = 10): def build_node(X, X_indexes, depth, leaf_size): """ 功能:构建结点 参数 ---------- X : 特征矩阵 X_indexes : 特征矩阵下标 depth : 深度 leaf_size : 叶子节点包含的最大特征矩阵数量 """ feature = np.mod(depth, X.shape[1]) # 当前特征的维度下标 # 当前特征矩阵的大小小于等于指定的叶子结点包含的特征矩阵数量时构建叶子结点并返回 if X.shape[0] <= leaf_size: return KdNode(feature, X, X_indexes) X_feature = X[:, feature] # 当前特征维度下的特征向量 X_sort_indexes = np.argsort(X_feature) # 按照当前特征维度排序后的下标向量 X_sort = X[X_sort_indexes] # 按照当前特征维度排序后的特征矩阵 median = X.shape[0] // 2 # 中间下标 X_left = X_sort[:median] # 左边的特征矩阵 X_left_index = X_indexes[X_sort_indexes[:median]] # 左边的特征矩阵对应排序后的下标 left = build_node(X_left, X_left_index, depth + 1, leaf_size) # 递归的构建左子树 X_right = X_sort[median + 1:] # 右边的特征矩阵 X_right_index = X_indexes[X_sort_indexes[median + 1:]] # 右边的特征矩阵对应排序后的下标 right = build_node(X_right, X_right_index, depth + 1, leaf_size) # 递归的构建右子树 return KdNode(feature, X_sort[median], X_indexes[X_sort_indexes[median]], left, right) # 构建当前结点并返回 self.root = build_node(X, np.array(range(X.shape[0])), 0, leaf_size) # 根结点 def query(self, X, k = 1, p = 2): """ 功能:查询距离最近 k 个特征向量 参数 ---------- X : 特征矩阵 k : 最近邻的数量,默认为 1 p : 距离范数,默认为 2,即欧式距离 """ nearests = -np.ones((len(X), k), dtype = np.int8) # 最近邻对应的下标向量 distances = -np.ones((len(X), k)) # 最近邻对应的距离向量 return self.search(X, self.root, nearests, distances, p) def search(self, X, node, nearests, distances, p = 2): """ 搜索距离最近 k 个特征向量 """ # 当前结点不是叶子结点时 if node.left is not None or node.right is not None: axis = X[:, node.feature] - node.value[node.feature] # 当前特征下的特征值与切分值之差 axis_left = axis < 0 # 切分点左边 if (axis_left).any(): # 递归的搜索左子树 nearests[axis_left, :], distances[axis_left, :] = self.search(X[axis_left, :], node.left, nearests[axis_left, :], distances[axis_left, :], p) # 切分点右边 axis_right = ~axis_left if (axis_right).any(): # 递归的搜索右子树 nearests[axis_right, :], distances[axis_right, :] = self.search(X[axis_right, :], node.right, nearests[axis_right, :], distances[axis_right, :], p) dist = distance(X, node.value, p) # 计算距离 all_cond = np.zeros((X.shape[0],), dtype=np.bool) # 是否所有特征点都处理过 for i in range(nearests.shape[1]): # 依次遍历 k 次 # 当前记录的距离为-1或者新的距离小于当前记录的距离 cond = (~all_cond) & ((distances[:, i] < 0) | (dist - distances[:, i] < 0)) if (~cond).all(): # 没有满足条件的特征点就跳过 continue ns = np.insert(nearests[cond, :], i, node.index, axis=1) # 插入最新的下标值 nearests[cond, :] = ns[:,:-1] ds = np.insert(distances[cond, :], i, dist[cond], axis=1) # 插入最新的距离 distances[cond, :] = ds[:,:-1] all_cond = all_cond | cond # 更新判断条件 if all_cond.all(): # 所有特征点都处理过则跳出 break # 距离记录中最大的距离大于切分轴(即另一边的子树可能包含更近的邻居) over = np.max(distances, axis=1) - np.abs(axis) > 0 if over.any(): over_left = over & axis_left # 递归的搜索右子树 if (over_left).any(): nearests[over_left, :], distances[over_left, :] = self.search(X[over_left, :], node.right, nearests[over_left, :], distances[over_left, :], p) over_right = over & axis_right # 递归的搜索左子树 if (over_right).any(): nearests[over_right, :], distances[over_right, :] = self.search(X[over_right, :], node.left, nearests[over_right, :], distances[over_right, :], p) else: for i in range(len(node.value)): # 依次遍历当前叶子结点包含的特征向量 dist = distance(X, node.value[i], p) # 更新下标与距离记录的方式同上 all_cond = np.zeros((X.shape[0],), dtype=np.bool) for j in range(nearests.shape[1]): cond = (~all_cond) & ((distances[:, j] < 0) | (dist - distances[:, j] < 0)) if (~cond).all(): continue ns = np.insert(nearests[cond, :], j, node.index[i], axis=1) nearests[cond, :] = ns[:,:-1] ds = np.insert(distances[cond, :], j, dist[cond], axis=1) distances[cond, :] = ds[:,:-1] all_cond = all_cond | cond if all_cond.all(): break return nearests, distances- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
2. 实现 Ball 树
class BallNode: """ ball 树结点 """ def __init__(self, value, index, radius, left = None, right = None): self.value = value # 结点对应训练集的特征值;当结点为叶子结点时,为特征向量 self.index = index # 结点对应训练集的下标;当结点为叶子结点时,为下标向量 self.radius = radius # 超球体的半径 self.left = left # 左子树 self.right = right # 右子树 class BallTree: """ ball 树算法实现 参数 ---------- X : 特征矩阵 leaf_size : 叶子节点包含的最大特征矩阵数量,默认为 10 p : 距离范数,默认为 2,即欧式距离 """ def __init__(self, X, leaf_size = 10, p = 2): def build_node(X, X_indexes, leaf_size): """ 构建结点 参数 ---------- X : 特征矩阵 X_indexes : 特征矩阵下标 leaf_size : 叶子节点包含的最大特征矩阵数量 """ # 当前特征矩阵的大小小于等于指定的叶子结点包含的特征矩阵数量时构建叶子结点并返回 if X.shape[0] <= leaf_size: return BallNode(X, X_indexes, None) # 距离最宽的维度(标准差越大,代表该维度下样本点之间差距有大) feature = np.argmax(np.std(X, axis=0)) X_feature_max = X[np.argmin(X[:, feature])] # 该维度下最大的样本点 X_feature_min = X[np.argmax(X[:, feature])] # 该维度下最小的样本点 X_feature_median = (X_feature_max + X_feature_min) / 2 # 中心点 radius = np.max(distance(X, X_feature_median, p)) # 每个样本点与中心点之间的最大距离 left_index = (distance(X, X_feature_max, p) - distance(X, X_feature_min, p)) < 0 # 将样本点分成两类 if left_index.any(): # 递归的构建左子树 left = build_node(X[left_index, :], X_indexes[left_index], leaf_size) right_index = ~left_index if right_index.any(): right = build_node(X[right_index, :], X_indexes[right_index], leaf_size) # 递归的构建右子树 return BallNode(X_feature_median, None, radius, left, right) # 构建当前结点并返回 self.root = build_node(X, np.array(range(X.shape[0])), leaf_size) # 根结点 def query(self, X, k = 1, p = 2): """ 查询距离最近 k 个特征向量 参数 ---------- X : 特征矩阵 k : 最近邻的数量,默认为 1 p : 距离范数,默认为 2,即欧式距离 """ nearests = -np.ones((len(X), k), dtype = np.int8) # 最近邻对应的下标向量 distances = -np.ones((len(X), k)) # 最近邻对应的距离向量 return self.search(X, self.root, nearests, distances, p) def search(self, X, node, nearests, distances, p = 2): """ 搜索距离最近 k 个特征向量 """ if node.left is not None or node.right is not None: # 当前结点不是叶子结点时 max_distance = np.max(distances, axis=1) # 最大的距离 # 样本点与当前结点对应的超球面最近的距离大于当前的最大距离时,其子结点不可能存在跟近的距离,直接跳过 over = ((distance(X, node.value, p) - node.radius - max_distance) >= 0) & (distances != -1).all() if over.all(): return nearests, distances unover = ~over # 递归搜索左子数 nearests[unover, :], distances[unover, :] = self.search(X[unover, :], node.left, nearests[unover, :], distances[unover, :], p) # 递归搜索右子数 nearests[unover, :], distances[unover, :] = self.search(X[unover, :], node.right, nearests[unover, :], distances[unover, :], p) else: # 依次遍历当前叶子结点包含的特征向量 for i in range(len(node.value)): # 更新下标与距离记录的方式 k-d 树 dist = distance(X, node.value[i], p) all_cond = np.zeros((X.shape[0],), dtype=np.bool) for j in range(nearests.shape[1]): cond = (~all_cond) & ((distances[:, j] < 0) | (dist - distances[:, j] < 0)) if (~cond).all(): continue ns = np.insert(nearests[cond, :], j, node.index[i], axis=1) nearests[cond, :] = ns[:,:-1] ds = np.insert(distances[cond, :], j, dist[cond], axis=1) distances[cond, :] = ds[:,:-1] all_cond = all_cond | cond if all_cond.all(): break return nearests, distances- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
3. 实现 k 近邻分类
class KnnClf: """ k近邻分类器(使用 k-d 树和 Ball 树实现) 参数 ---------- k : 最近邻的数量,默认为 5 leaf_size : 叶子节点包含的最大特征矩阵数量,默认为 10 p : 距离范数,默认为 2,即欧式距离 """ def __init__(self, k = 5, leaf_size = 10, p = 2, tree = "kdtree"): self.k = k self.leaf_size = leaf_size self.p = p self.tree = tree def fit(self, X, y): """ k近邻分类拟合 参数 ---------- X : 特征矩阵 y : 标签分类 """ if self.tree == "kdtree": self._tree = KdTree(X, leaf_size = self.leaf_size) else: self._tree = BallTree(X, leaf_size = self.leaf_size, p = self.p) self.y = np.array(y) self.y_classes = np.unique(y) def predict(self, X): """ k近邻分类预测 参数 ---------- X : 特征矩阵 """ nearests, distances = self._tree.query(X, k = self.k, p = self.p) predict_y = self.y[nearests] predict_y_count = np.zeros((len(predict_y), len(self.y_classes)), dtype=np.int8) for i, y_class in enumerate(self.y_classes): predict_y_count[:, i] = np.sum(predict_y == y_class, axis=1) return self.y_classes[np.argmax(predict_y_count, axis=1)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
4. 实现 k 近邻回归
class KnnReg: """ k近邻回归器(使用 k-d 树和 Ball 树实现) 参数 ---------- k : 最近邻的数量,默认为 5 leaf_size : 叶子节点包含的最大特征矩阵数量,默认为 10 p : 距离函数参数,默认为 2,即欧式距离 """ def __init__(self, k = 5, leaf_size = 10, p = 2, tree = "kdtree"): self.k = k self.leaf_size = leaf_size self.p = p self.tree = tree def fit(self, X, y): """ k近邻回归拟合 参数 ---------- X : 特征矩阵 y : 标签分类 """ if self.tree == "kdtree": self._tree = KdTree(X, leaf_size = self.leaf_size) else: self._tree = BallTree(X, leaf_size = self.leaf_size, p = self.p) self.y = np.array(y) def predict(self, X): """ k近邻回归预测 参数 ---------- X : 特征矩阵 """ nearests, distances = self._tree.query(X, k = self.k, p = self.p) predict_y = self.y[nearests] return np.average(predict_y, axis=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
5. 示例
from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score X, y = mglearn.datasets.make_forge() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) clf = KnnClf() clf.fit(X_train, y_train) y_predict = clf.predict(X_test) print("Test accuracy {:.3f}".format(accuracy_score(y_test, y_predict))) # Test accuracy 0.857- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
from sklearn.metrics import r2_score from sklearn.model_selection import train_test_split X, y = mglearn.datasets.make_wave(n_samples=40) # 将wave数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) reg = KnnReg(k=3, tree="balltree") reg.fit(X_train, y_train) y_predict = clf.predict(X_test) print("Test set R^2: {:.2f}".format(r2_score(X_test, y_test))) # Test set R^2: 0.54- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.2 Sklearn
1. k近邻分类
下面给出了这种分类方法在forge数据集上的应用:mglearn.plots.plot_knn_classification(n_neighbors=1)- 1

这里我们添加了3 个新数据点(用五角星表示)。对于每个新数据点,我们标记了训练集中与它最近的点。单一最近邻算法的预测结果就是那个点的标签(对应五角星的颜色)。除了仅考虑最近邻,我还可以考虑任意个(k 个)邻居。这也是k 近邻算法名字的来历。在考虑多于一个邻居的情况时,我们用“投票法”(voting)来指定标签。也就是说,对于每个测试点,我们数一数多少个邻居属于类别0,多少个邻居属于类别1。然后将出现次数更多的类别(也就是k 个近邻中占多数的类别)作为预测结果。下面的例子用到了3 个近邻:
mglearn.plots.plot_knn_classification(n_neighbors=3)- 1

预测结果可以从五角星的颜色看出。你可以发现,左上角新数据点的预测结果与只用一个邻居时的预测结果不同。虽然这张图对应的是一个二分类问题,但方法同样适用于多分类的数据集。对于多分类问题,我们数一数每个类别分别有多少个邻居,然后将最常见的类别作为预测结果。
下面演示如何通过
scikit-learn来应用 k 近邻算法。将数据分为训练集和测试集,以便评估泛化性能:from sklearn.model_selection import train_test_split X, y = mglearn.datasets.make_forge() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)- 1
- 2
- 3
- 4
然后,导入类并将其实例化。这时可以设定参数,比如邻居的个数。这里我们将其设为3:
from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=3)- 1
- 2
- 3
利用训练集对这个分类器进行拟合。对于KNeighborsClassifier 来说就是保存数据集,以便在预测时计算与邻居之间的距离:
clf.fit(X_train, y_train)- 1
调用
predict方法来对测试数据进行预测。对于测试集中的每个数据点,都要计算它在训练集的最近邻,然后找出其中出现次数最多的类别:print("Test set predictions: {}".format(clf.predict(X_test))) # Test set predictions: [1 0 1 0 1 0 0]- 1
为了评估模型的泛化能力好坏,我们可以对测试数据和测试标签调用
score方法:print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test))) # Test set accuracy: 0.86- 1
我们的模型精度约为86%,也就是说,在测试数据集中,模型对其中86%的样本预测的类别都是正确的。
对于二维数据集,我们还可以在xy 平面上画出所有可能的测试点的预测结果。我们根据平面中每个点所属的类别对平面进行着色。这样可以查看决策边界(decision boundary),即算法对类别0 和类别1 的分界线。
下列代码分别将1 个、3 个和9 个邻居三种情况的决策边界可视化,见下图:
fig, axes = plt.subplots(1, 3, figsize=(10, 3)) for n_neighbors, ax in zip([1, 3, 9], axes): clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y) mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4) mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax) ax.set_title("{} neighbor(s)".format(n_neighbors)) ax.set_xlabel("feature 0") ax.set_ylabel("feature 1") axes[0].legend(loc=3)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

从左图可以看出,使用单一邻居绘制的决策边界紧跟着训练数据。随着邻居个数越来越多,决策边界也越来越平滑。更平滑的边界对应更简单的模型。换句话说,使用更少的邻居对应更高的模型复杂度(如图右侧所示),而使用更多的邻居对应更低的模型复杂度(如图左侧所示)。假如考虑极端情况,即邻居个数等于训练集中所有数据点的个数,那么每个测试点的邻居都完全相同(即所有训练点),所有预测结果也完全相同(即训练集中出现次数最多的类别)。
我们来研究一下能否证实之前讨论过的模型复杂度和泛化能力之间的关系。我们将在现实世界的乳腺癌数据集上进行研究。先将数据集分成训练集和测试集,然后用不同的邻居个数对训练集和测试集的性能进行评估。输出结果见图:
from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target, random_state=66) # 保持测试集与整个数据集里result的数据分类比例一致 training_accuracy = [] test_accuracy = [] # n_neighbors取值从1到10 neighbors_settings = range(1, 11) for n_neighbors in neighbors_settings: # 构建模型 clf = KNeighborsClassifier(n_neighbors=n_neighbors) clf.fit(X_train, y_train) # 记录训练精度 training_accuracy.append(clf.score(X_train, y_train)) # 记录测试精度 test_accuracy.append(clf.score(X_test, y_test)) plt.plot(neighbors_settings, training_accuracy, label="train accuracy") plt.plot(neighbors_settings, test_accuracy, label="test accuracy") plt.xlabel("n_neighbors") plt.ylabel("Accuracy") plt.legend()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
图像的 x 轴是n_neighbors,y 轴是训练集精度和测试集精度。虽然现实世界的图像很少有非常平滑的,但我们仍可以看出过拟合与欠拟合的一些特征。仅考虑单一近邻时,训练集上的预测结果十分完美。但随着邻居个数的增多,模型变得更简单,训练集精度也随之下降。单一邻居时的测试集精度比使用更多邻居时要低,这表示单一近邻的模型过于复杂。与之相反,当考虑10个邻居时,模型又过于简单,性能甚至变得更差。最佳性能在中间的某处,邻居个数大约为6。不过最好记住这张图的坐标轴刻度。最差的性能约为88%的精度,这个结果仍然可以接受。

2. k近邻回归
k 近邻算法还可以用于回归。我们还是先从单一近邻开始,这次使用wave数据集。我们添加了3 个测试数据点,在x 轴上用绿色五角星表示。利用单一邻居的预测结果就是最近邻的目标值。在下图中用蓝色五角星表示:
mglearn.plots.plot_knn_regression(n_neighbors=1)- 1

同样,也可以用多个近邻进行回归。在使用多个近邻时,预测结果为这些邻居的平均值:
mglearn.plots.plot_knn_regression(n_neighbors=3)- 1

用于回归的k 近邻算法在scikit-learn 的
KNeighborsRegressor类中实现。其用法与
KNeighborsClassifier类似:from sklearn.neighbors import KNeighborsRegressor X, y = mglearn.datasets.make_wave(n_samples=40) # 将wave数据集分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) reg = KNeighborsRegressor(n_neighbors=3) reg.fit(X_train, y_train)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
print("Test set predictions: \n{}".format(reg.predict(X_test)))- 1
Test set predictions:
[-0.05396539 0.35686046 1.13671923 -1.89415682 -1.13881398 -1.63113382 0.35686046 0.91241374 -0.44680446 -1.13881398]还可以用
score方法来评估模型,对于回归问题,这一方法返回的是 R 2 R^2 R2分数。 R 2 R^2 R2分数也叫作决定系数,是回归模型预测的优度度量,位于0到1之间。 R 2 R^2 R2等于1 对应完美预测, R 2 R^2 R2等于0 对应常数模型,即总是预测训练集响应(y_train)的平均值:print("Test set R^2: {:.2f}".format(reg.score(X_test, y_test))) # Test set R^2: 0.83- 1
这里的分数是0.83,表示模型的拟合相对较好。
对于我们的一维数据集,可以查看所有特征取值对应的预测结果。为了便于绘图,我们创建一个由许多点组成的测试数据集:
import matplotlib.pyplot as plt fig, axes = plt.subplots(1, 3, figsize=(15, 4)) # 创建1000个数据点,在-3和3之间均匀分布 line = np.linspace(-3, 3, 1000).reshape(-1, 1) for n_neighbors, ax in zip([1, 3, 9], axes): # 利用1个,3个,9个令居分别进行预测 reg = KNeighborsRegressor(n_neighbors=n_neighbors) reg.fit(X_train, y_train) ax.plot(line, reg.predict(line)) ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8) ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize=8) ax.set_title( "{} neighbor(s)\n train score: {:.2f} test_score: {:.2f}".format(n_neighbors, reg.score(X_train, y_train), reg.score(X_test, y_test))) ax.set_xlabel("Feature") ax.set_ylabel("Target") axes[0].legend(["Model predictions", "Training data/target", "Test data/target"], loc="best")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

从图中可以看出,仅使用单一邻居,训练集中的每个点都对预测结果有显著影响,预测结果的图像经过所有数据点。这导致预测结果非常不稳定。考虑更多的邻居之后,预测结果变得更加平滑,但对训练数据的拟合也不好。
6 小结
一般来说,KNeighbors 分类器有2个重要参数:邻居个数与数据点之间距离的度量方法。在实践中,使用较小的邻居个数(比如3个或5个)往往可以得到比较好的结果,但你应该调节这个参数(交叉验证)。默认使用欧式距离,它在许多情况下的效果都很好。
KNN的主要优点有:
- 理论成熟,思想简单,既可以用来做分类也可以用来做回归,由于不需要过多调节就可以得到不错的性能,在考虑使用更高级的技术之前,尝试此算法是一种很好的基准方法
- 可用于非线性分类
- 训练时间复杂度比支持向量机之类的算法低,仅为O(n)
- 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
- 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
- 该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
KNN的主要缺点有: - 计算量大,尤其训练集很大(特征数很多或者样本数很大)
- 样本不平衡的时候,对稀有类别的预测准确率低
- KD树,球树之类的模型建立需要大量的内存
- 使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
- 相比决策树模型,KNN模型可解释性不强
- 对于有很多特征(几百或更多)的数据集往往效果不好,对于大多数特征的大多数取值都为0的数据集(所谓的稀疏数据集)来说,这一算法的效果尤其不好
温馨提示: 使用k-NN 算法时,对数据进行预处理是很重要的。
补充:
这里我们再讨论下KNN算法的扩展,限定半径最近邻算法。有时候我们会遇到这样的问题,即样本中某系类别的样本非常的少,甚至少于K,这导致稀有类别样本在找K个最近邻的时候,会把距离其实较远的其他样本考虑进来,而导致预测不准确。为了解决这个问题,我们限定最近邻的一个最大距离,也就是说,我们只在一个距离范围内搜索所有的最近邻,这避免了上述问题。这个距离我们一般称为限定半径。
接着我们再讨论下另一种扩展,最近质心算法。这个算法比KNN还简单。它首先把样本按输出类别归类。对于第 L L L类的 C l C_l Cl个样本。它会对这 C l C_l Cl个样本的 n n n维特征中每一维特征求平均值,最终该类别所有维度的 n n n个平均值形成所谓的质心点。对于样本中的所有出现的类别,每个类别会最终得到一个质心点。当我们做预测时,仅仅需要比较预测样本和这些质心的距离,最小的距离对于的质心类别即为预测的类别。这个算法通常用在文本分类处理上。
参考
- K近邻法(KNN)原理小结:https://www.cnblogs.com/pinard/p/6061661.html
- 机器学习算法系列(二十一)-k近邻算法(k-Nearest Neighbor / kNN Algorithm):https://blog.csdn.net/sai_simon/article/details/124209904?spm=1001.2014.3001.5502
- K-近邻算法(KNN):https://blog.csdn.net/weixin_45884316/article/details/115221211
- 参考代码:https://github.com/wzyonggege/statistical-learning-method
-
相关阅读:
JAVA基础(四十二)——集合之Collection
浅谈在操控器类中,为何要通过osgGA::CameraManipulator的逆矩阵改变视点位置
关于Oracle数据库字段排序的问题
Atomic Mail Sender 9.6.X 中文版Crack
第十九章总结:Java绘图
Debye-Wolf积分计算器的用法
Android打包脚本和上传apk托管平台
FFMpeg解复用流程
LeetCode 55. 跳跃游戏
51-43 DragNUWA,集成文本、图像和轨迹实现视频生成细粒度控制
- 原文地址:https://blog.csdn.net/xq151750111/article/details/127741006
