-
MySQL 慢查询经典案例分析

案例1:隐式转换
- 创建 user 表,并且添加 user_id 索引
CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, user_id varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid (user_id) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
user_id 字段为字串类型,B+树的普通索引,查询条件传数字,会导致索引失效

-
给数字加上 ’ ’ ,传字符串,会走索引

-
为什么未加单引号不走索引
- 不加单引号是字符串跟数字的比较,类型不匹配,MySQL 会做隐式的类型转换,把它们转换为浮点数再做比较,隐式的类型转换,索引会失效
案例2:最左匹配
- 表结构
CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, user_id varchar(32) NOT NULL, age varchar(16) NOT NULL, name varchar(255) NOT NULL, PRIMARY KEY (id), KEY idx_userid_name (user_id,name) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
MySQl 建立联合索引时,遵循最左前缀匹配的原则,即最左优先,建立一个(a,b,c)的联合索引,相当于建立(a)、(a,b)、(a,b,c)三个索引
-
查询条件列不是联合索引的第一个列,不满足最左匹配原则

-
在联合索引中,查询条件满足最左匹配原则时,索引才生效

案例3:深分页问题
- 表结构
CREATE TABLE account ( id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', name varchar(255) DEFAULT NULL COMMENT '账户名', balance int(11) DEFAULT NULL COMMENT '余额', create_time datetime NOT NULL COMMENT '创建时间', update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (id), KEY idx_name (name), KEY idx_create_time (create_time) //索引 ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 以以下这条SQL为例子:
select id,name,balance from account where create_time> '2022-11-7' limit 100000,10;
- 这个SQL的执行流程:
- 通过普通二级索引树 idx_create_time,过滤 create_time 条件,找到满足条件的主键id
- 通过主键id,回到 id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)
- 扫描满足条件的100010行,然后扔掉前100000行,返回

- limit 深分页,导致SQL变慢原因有两个:
- limit 语句会先扫描 offset + n 行,然后再丢弃掉前 offset 行,返回后 n 行数据,也就是说 limit 100000,10,就会扫描100010行,而 limit 0,10,只扫描10行
- limit 100000,10 扫描更多的行数,也意味着回表次数更多
- 如何优化深分页
- 通过减少回表次数来优化,一般有标签记录法和延迟关联法
- 标签记录法
- 就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描,就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦
- 假设上一次记录到100000,则SQL可以修改为:
select id,name,balance FROM account where id > 100000 limit 10; - 这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引,但是这种方式有局限性:需要一种类似连续自增的字段
- 延迟关联法
- 延迟关联法,就是把条件转移到主键索引树,然后减少回表。如下:
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2022-11-7' limit 100000, 10) AS acct2 on acct1.id= acct2.id; - 优化思路就是,先通过 idx_create_time 二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表
- 延迟关联法,就是把条件转移到主键索引树,然后减少回表。如下:
- 标签记录法
- 通过减少回表次数来优化,一般有标签记录法和延迟关联法
案例4:in元素过多
- 如果使用 in,即使后面的条件加了索引,还是要注意 in 后面的元素不要过多,in 元素一般建议不要超过200个,如果超过了,建议分组,每次 200 一组进行
- 如果对 in 的条件不做任何限制的话,该查询语句一次性可能会查询出非常多的数据
select * from user where user_id in (select author_id from artilce where type = 1);
- in 查询为什么慢
- in 查询底层是通过 n*m 的方式去搜索,类似 union
- in 查询在cost代价计算时(代价 = 元组数 * IO平均值),将 in 包含的数值,一条条去查询获取元组数,这个计算过程比较的慢,所以MySQL设置临界值 eq_range_index_dive_limit
- 5.6之后超过临界值后该列的cost就不参与计算,会导致执行计划选择不准确,默认是200,即 in 条件超过200个数据,会导致in的代价计算存在问题,可能会导致MySQL选择的索引不准确
案例5:order by 文件排序
- 表结构
DROP TABLE IF EXISTS `staff`; CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表'; SET FOREIGN_KEY_CHECKS = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 查看 order by 的执行计划,有一个 Using filesort,表示用到文件排序

-
order by 排序 ⇒ \Rightarrow ⇒ rowid排序 和 全字段排序
- max_length_for_sort_data > 结果行数据长度 ⇒ \Rightarrow ⇒ rowid排序
- max_length_for_sort_data < 结果行数据长度
⇒
\Rightarrow
⇒ 全字段排序

-
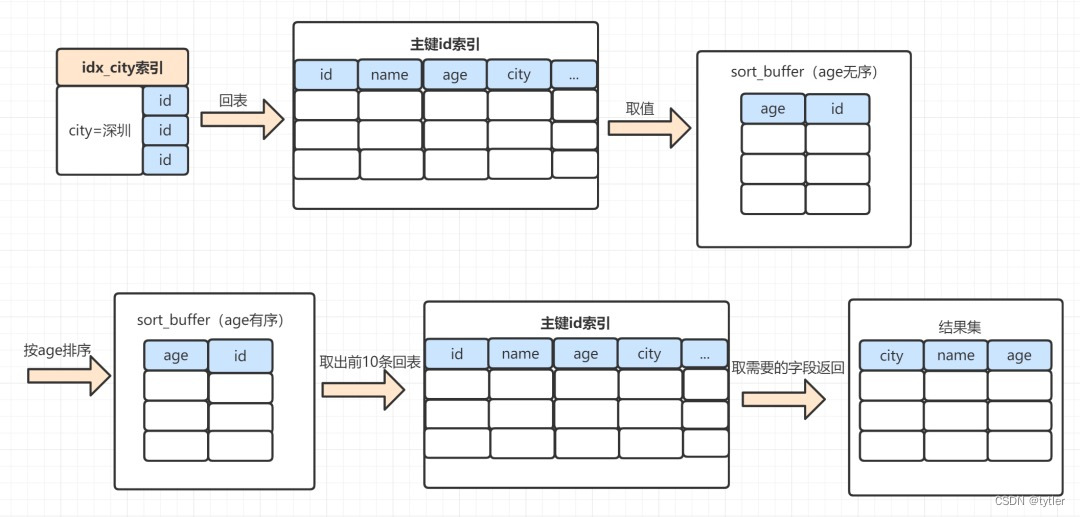
rowid排序执行过程:
select name,age,city from staff where city = '深圳' order by age limit 10;- 1.MySQL为对应的线程初始化sort_buffer,放入需要排序的age字段,以及主键id
- 2.从索引树idx_city, 找到第一个满足 city='深圳’条件的主键id,假设id为X
- 3.到主键id索引树拿到id=X的这一行数据, 取age和主键id的值,存到sort_buffer
- 4.从索引树idx_city拿到下一个记录的主键id,假设id=Y
- 5.重复步骤 3、4 直到city的值不等于深圳为止
- 6.前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序
- 7.遍历排序结果,取前10行,并按照id的值回到原表中,取出city、name 和 age三个字段返回给客户端
- 8.一般要回表,效率会慢点
-
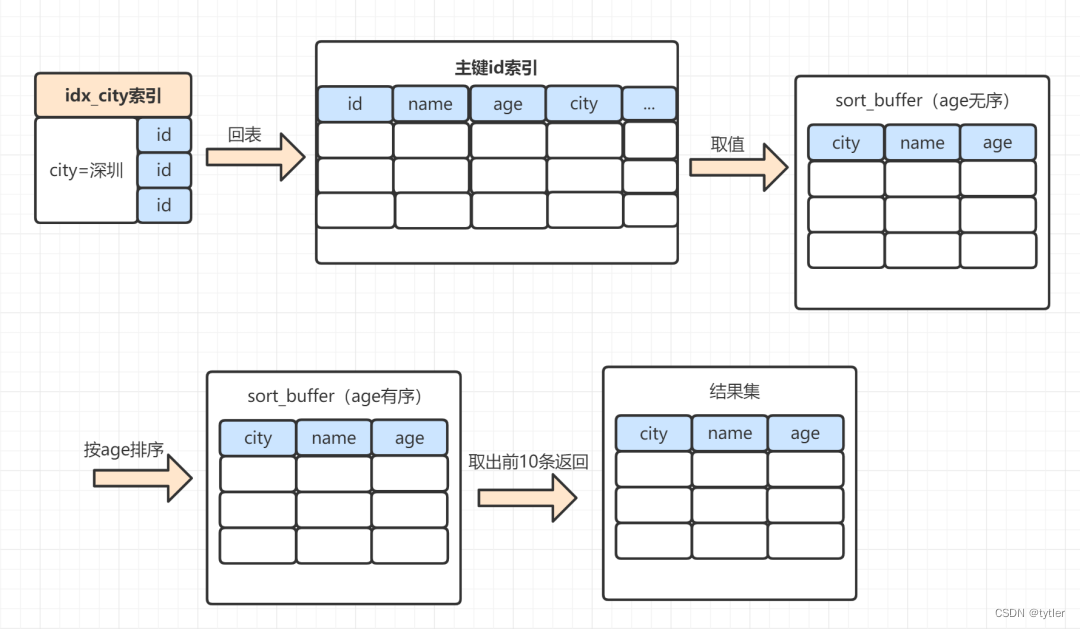
全字段排序执行过程
select name,age,city from staff where city = '深圳' order by age limit 10;- 1.MySQL 为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段
- 2.从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,假设找到id=X
- 3.到主键id索引树拿到id=X的这一行数据, 取name、age、city三个字段的值,存到sort_buffer
- 4.从索引树idx_city 拿到下一个记录的主键id,假设id=Y
- 5.重复步骤 3、4 直到city的值不等于深圳为止
- 6.前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序
- 7.按照排序结果取前10行返回给客户端
-
sort_buffer 大小由 sort_buffer_size 参数决定
- 排序的数据 < sort_buffer_size ⇒ \Rightarrow ⇒ sort_buffer内存排序
- 排序的数据 > sort_buffer_size ⇒ \Rightarrow ⇒ 磁盘文件排序
- 磁盘文件排序,效率会更慢一点
- 因为先把数据放入 sort_buffer,当快要满时,会排一下序,然后把 sort_buffer 中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件
- 优化 order by 文件排序
- 数据无序,需要排序,如果数据有序,不需要文件排序,索引数据有序,建立索引优化
- 需要留意 desc 和 asc 混用导致索引失效
- 可以调整 max_length_for_sort_data、sort_buffer_size 参数调优
案例6:索引字段上使用 is null, is not null,索引可能失效
- 表结构
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `card` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE, KEY `idx_card` (`card`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
单个name字段加索引,查询name非空,走索引

-
单个card字段加索引,查询card非空,走索引

-
如果用 or 连接,不走索引

-
因为数据量问题,导致 MySQL 优化器放弃走索引,平时用 explain 分析 SQL 的时候,如果 type=range,要注意一下,这个可能因为数据量问题,导致索引无效
案例7:索引字段上使用(!= 或者 < >),索引可能失效
- 假设表结构
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
age 加索引,使用 != 或者 < >,not in,进行表达式计算,索引失效

-
这个跟 MySQL 优化器有关,优化器觉得即使走索引,还要扫描很多行,觉得不划算,不如不走索引,平时用的 != 或者 < >,not in ,需要留意
案例8:左右连接,关联的字段编码格式不一样
- 新建 user、user_job 表,name 字段有索引
- user ⇒ \Rightarrow ⇒ name ⇒ \Rightarrow ⇒ utf8mb4
- user_job ⇒ \Rightarrow ⇒ name ⇒ \Rightarrow ⇒ utf8
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL, `age` int(11) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8; CREATE TABLE `user_job` ( `id` int(11) NOT NULL, `userId` int(11) NOT NULL, `job` varchar(255) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
左外连接查询,user_job 表走全表扫描

-
name 字段编码一致,相同 SQL,走索引

案例9:group by 使用临时表
- 表结构
CREATE TABLE `staff` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `id_card` varchar(20) NOT NULL COMMENT '身份证号码', `name` varchar(64) NOT NULL COMMENT '姓名', `age` int(4) NOT NULL COMMENT '年龄', `city` varchar(64) NOT NULL COMMENT '城市', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- SQL 执行计划 :Using temporary 使用临时表,Using filesort 使用文件排序

- 分析 group by 执行流程
- 创建内存临时表,表里有两个字段 city 和 num
- 全表扫描 staff 的记录,依次取出 city = ‘X’ 的记录
- 判断临时表中是否有为 city=‘X’ 的行,没有就插入一个记录 (X,1)
- 如果临时表中有 city=‘X’ 的行,就将 X 这一行的 num 值加 1
- 遍历完成后,再根据字段 city 做排序,得到结果集返回给客户端,这个流程的执行图如下:

- 临时表的排序
- 就是把需要排序的字段,放到 sort buffer,排完就返回;需要留意,排序分全字段排序和rowid排序
- 如果是全字段排序,需要查询返回的字段,都放入 sort buffer,根据排序字段排完,直接返回
- 如果是 rowid排序,只是需要排序的字段放入 sort buffer,然后多一次回表操作,再返回
- group by 慢在哪里
- group by使用不当,很容易就会产生慢SQL问题,因为它既用到临时表,又默认用到排序,有时候还可能用到磁盘临时表
- 如果执行过程中,发现内存临时表大小到达上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表
- 如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间
- 如何优化 group by,从哪些方向去优化
- 方向1:默认会排序,不给排序
- 方向2:临时表是影响 group by 性能的因素,可以不用临时表(松散索引扫描、紧凑索引扫描)
- 可以有这些优化方案:
- group by 后面的字段加索引
- order by null 不用排序
- 尽量只使用内存临时表
- 使用 SQL_BIG_RESULT
- 参考文档:http://www.weijingbiji.com/1939/
案例10:delete + in 子查询不走索引
- delete 遇到 in 子查询时,即使有索引,也是不走索引的
- 对应的 select + in 子查询,却可以走索引
- MySQL 版本是5.7,两张表 account 和 old_account,表结构如下:
CREATE TABLE `old_account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='老的账户表'; CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
查看 delete 执行计划,发现不走索引

-
查看 select 执行计划,就会走索引

-
查看 select 语句如何执行
explain select * from account where name in (select name from old_account);
show WARNINGS; --可以查看优化后,最终执行的sql
select `employees`.`account`.`id` AS `id`,`employees`.`account`.`name` AS `name`,`employees`.`account`.`balance` AS `balance`,`employees`.`account`.`create_time` AS `create_time`,`employees`.`account`.`update_time` AS `update_time` from `employees`.`account` semi join (`employees`.`old_account`) where (`employees`.`old_account`.`name` = `employees`.`account`.`name`)- 1
- 可以发现,实际执行的时候,MySQL 对 select in 子查询做了优化,把子查询改成 join 的方式,所以可以走索引;但是对于 delete in 子查询,MySQL 却没有对它做这个优化
参考资料
-
相关阅读:
第1天:环境搭建与Django基础
S6---ZYNQ硬件板级原理图实战导学
安卓开发环境安装教程
iterm2免密码连接远程服务器教程
低代码开发如何助力数字化企业管理系统平台构建
数据结构:栈
C++ while 循环
java基础题
Java elasticsearch scroll模板实现
十一、WSGI与Web框架
- 原文地址:https://blog.csdn.net/qq_41956014/article/details/127725899