-
AI加速(五)| 一个例子看懂流水——从指令到算法
大家好啊,我是董董灿。
前文回顾:
之前的两篇文章介绍了流水这一技术,它用来进行程序的性能加速。作为入门级的科普文章,当然不会写的太深入太专业,只是从概念上希望大家对流水有个感性的认识。
本篇打算再通过一个生活中的小例子,让大家更直观的了解什么是流水。
举个例子
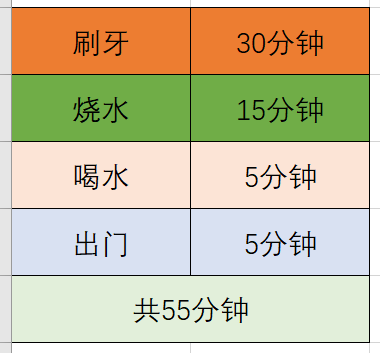
早晨从起床到上班出门,我们一般会做以下几件事:刷牙、烧水、喝水、出门。
如果正常按顺序去做,可能就是先刷牙,然后烧水,等水烧开了喝水,然后出门。假设做每件事需要的时间如下表,那么整个出门前需要花费的时间为55分钟。
但是,如果你稍微会一点时间管理的话,我相信你肯定不会先刷牙、然后烧水的,毕竟,烧水和刷牙没有任何关系,而且烧水的时候,也不需要人在边上看着。
于是,就有了下面的做事顺序——起来先烧水,然后在烧水的同时,刷牙,等水烧开了,喝水,出门。
这么算下来,总共需要40分钟就能完成。

这两种做事顺序最终的结果都是一样的,而且该做的事都做了。区别在于,后面比前面节省了15分钟的时间。
这里需要注意2个概念。
依赖——后面的事依赖前面的事情。也就是说喝水肯定依赖烧水完成之后才能出门。
并行——烧水和刷牙没有任何依赖关系,他俩就可以并行去做。
上图中,烧水和刷牙在同一时刻去做了。因此我们可以说,在整个从起床到出门的时间流水线中,烧水和刷牙并行起来了。单纯的一个并行处理,就可以节省15分钟的时间。
在理解了并行的概念之后,流水就好理解了。
流水排布到底是什么样的
继续上面的例子,比如我们起床需要刷两次牙,烧两次水,喝两次水。(当然现实中不会有人这么做,但是在AI神经网络中,重复某个计算是常有的事。感兴趣可以看下 长文解析Resnet50的算法原理 中的Rensnet网络结构)。
如果刷两次牙,烧两次水,喝两次水,然后出门,我们该怎么管理时间呢?
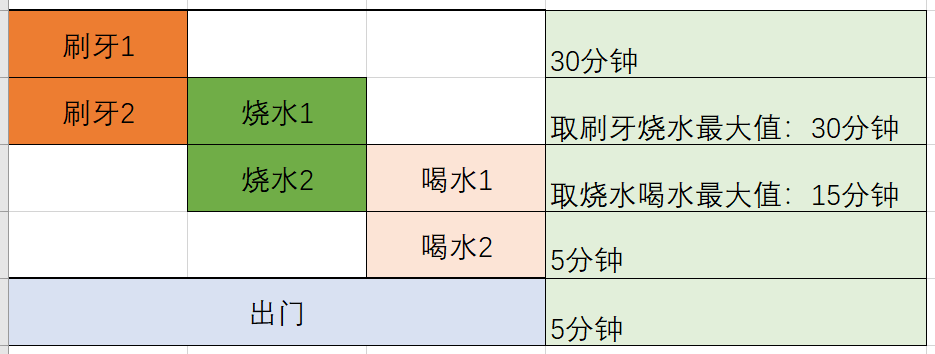
刷牙1和刷牙2肯定是顺序来的,同理烧水1和烧水2,喝水1和喝水2都是需要有顺序的,也就是前面说的依赖。但是刷牙与烧水之间、烧水与喝水之间是有可能并行起来的。比如烧第二次水的时候,我们可以喝第一次的水。
上图中,整个左上角的的排布,像一个瀑布一样由上而下,每一行都有两件事同时在做,同一时刻两件事互不影响,但整个系统又井然有序。
这种排布,就叫做流水。
-
在指令序列中,将刷牙、烧水、喝水替换成指令,就完成了指令流水;
-
在神经网络中,将刷牙、烧水、喝水替换成AI算法,就完成了算法流水。
但是能排流水总是需要满足前面说的两个前提:同一时刻的两件事、或两条指令、或两个算法是解除依赖的,并且可以并行处理的。
说到这,有同学可能会问,既然这样,我们弄两个烧水壶同时烧水不就行了么?
当然可以,这就是升级硬件喽。双核CPU肯定要比单核CPU性能好,就是这个原因了。排流水是在硬件资源有限的前提下,最大限度的减少程序运行时间,提升整个AI软件栈的性能!
Resnet50 中的算法并行
在Resnet50的网络结构(详见:长图展示Resnet全貌和可视化CNN!)中,存在很多可并行的算法。

上图是截取的Resnet50网络中的一部分,可以看到中间有个加法节点,加法节点有两个输入,分别为左边的卷积1和右边的卷积2(Conv为Convolution的缩写,中文名为卷积)。
左边的卷积1依赖于它前面的Relu的输出,而右边的卷积2依赖于很靠前的某个节点的输出,两者并没有实际上的数据依赖,因此,在深度学习编译器对两个节点进行编译调度时,可以将两者进行并行化处理(Parallelization),从而减少一个卷积运算的耗时。
总结
之所以又花了一篇文章来介绍流水和并行技术,是因为并行和流水技术在AI软件的性能优化中占据了很重要的位置。
在硬件资源有限的前提下,我们只能通过软件手段来持续进行AI的加速优化。这里面,更深刻的理解硬件的架构,利用好硬件的优势,编写更加硬件友好的软件代码,才能更加有效的实现AI加速。
知己知彼,百战不殆。
好了,这篇就介绍到这。欢迎持续关注AI加速系列文章。
所有文章均为作者原创,免费阅读,欢迎关注。专栏地址 >>>>>>>
AI加速专栏——有你想要的软硬件程序加速知识
 https://blog.csdn.net/dongtuoc/category_11895363.html
https://blog.csdn.net/dongtuoc/category_11895363.html
v v v v v v**本文为作者原创,请勿转载,转载请联系作者。**
**点击下方卡片,关注我的公众号,有最新的文章和项目动态。**v v v v v v
-
-
相关阅读:
VR失重太空舱游乐设备|航空航天VR体验|VR航天航空体验馆
非极大值抑制算法(NMS)的python实现
MySQL,刷题之对多表查询,题+代码!!
经典设计原则 - SOLID
14.IP协议-bite
Vue 源码解读(4)—— 异步更新
Base64
Elasticsearch常用API与IK分词器
SpringBoot 发送邮件
风控特征的优化分箱,看看这样教科书的操作
- 原文地址:https://blog.csdn.net/dongtuoc/article/details/127734412