-
【小想法】第1期:模型工程化,向量相似度,早停机制,BERT微调小trick
背景
现在工作和生活比较忙碌,写一些长文的闲暇时间不多。不过自己依然在不断学习、思考和总结。后面我也会把平时针对深度学习中的一些算法的一些思考,一些总结汇总起来。一些思考,由于书写比较简单,我也会逐渐同步到各个平台上,欢迎前来交流。
稍微闲下来的时候,我会把以往的小总结汇总到博文中。欢迎留言沟通哦。想法同步平台:模型工程化
深度学习模型工程化可以使用方式比较多,如使用Java的DJL库对模型进行封装构建java SDK,使用fastapi(python web框架,flask也是可以的)对模型保证,对外提供服务,或者书写成python SDK供他人使用,如果想保护模型服务源码,也可以进行使用pyinstaller打包,如果方便部署,也可以进一步使用docker构建镜像,除此之外还可以使用onnx进行工程化等。
向量相似度
在深度学习论文中,我们经常看到使用向量相乘的结果来衡量两个向量的相似度,这样做是为什么呢?
我们可以联想一下余弦相似度的计算公式,将会两个向量相乘后除以两个向量模的积,除以模的积主要使用进行归一化,就相似度归一化到[0,1]范围内而已。
这么说来,使用向量相乘的结果来衡量两个向量的相似度就很好理解了。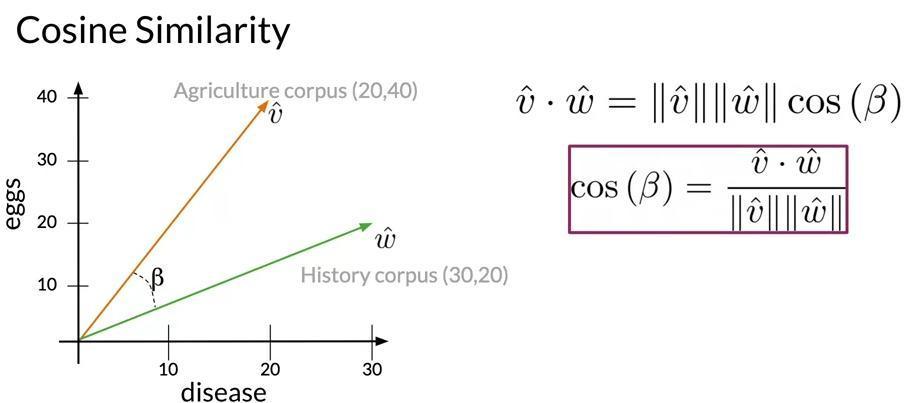
早停机制
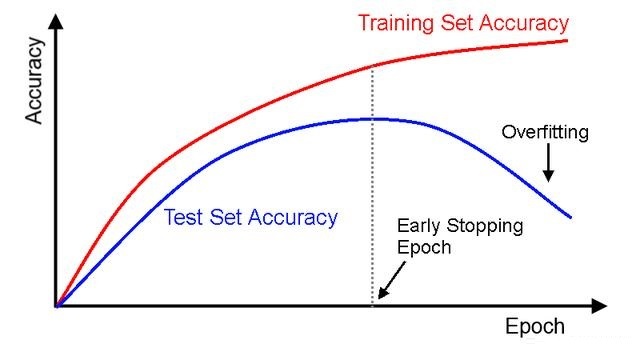
在深度学习模型训练中经常会用到EarlyStopping,即早停机制。早停机制的背后原理就是监控模型训练过程中的一些参数,当符合要求后就停止训练,以减少模型训练时间等。 常见的早停策略有:监控模型在开发集上的损失,当损失值在连续几个batch上基本上不变时,就停止训练。除此之外,还可以监控f1值,accuracy等,具体监控的参数可以根据任务来定。 好的模型训练框架都会提供相关的早停机制api,如pytorch-lightning。
BERT微调小trick
在使用BERT做下游任务微调时,可以考虑调整下游任务的batch size,learning rate,epoch这几个超参数,来对自己的模型进行炼丹:
- batch-size: 16,32
- learning rate(Adam): 5e-5,3e-5,2e-5
- number of epochs:2,3,4

-
相关阅读:
异步函数(async/await)
Python接口自动化搭建过程,含request请求封装
【leetcode】331. 验证二叉树的前序序列化
Arbitrum:二维费用
【java】java list.stream().map().collect(Collectors.toList())
基于JAVA视频点播系统设计与实现 开题报告
RSA非对称加密算法中的密钥对生成与传输
linux-定时任务
软考重点5 程序设计语言
Guitar Pro8吉他打谱下载自学制作教程
- 原文地址:https://blog.csdn.net/meiqi0538/article/details/127739612