-
云计算实验3 基于Scala编程语言的Spark数据预处理实验
一、 实验目的
掌握Scala语言编程基础和弹性分布式数据集RDD的基本操作,掌握大数据格式与大数据预处理方法
二、 实验环境
Linux的虚拟机环境和实验指导手册
三、 实验任务
完成Scala编程语言基础实验、RDD编程实验和大数据预处理实验。
四、 实验步骤
请按照实验指导手册 ,完成以下实验内容:
实验3-1 Scala语言编程基础(1) Scala基本语法 (2) Scala基本数据类型和Scala函数等- 1
- 2
实验3-2 弹性分布式数据集RDD基本操作
(1) RDD编程基础 (2) 转化和行动操作等- 1
- 2
实验3-3 Spark数据预处理实验——Apache服务器访问日志分析行
(1) 日志数据格式与数据预处理 (2) 统计PV、IP、页面访问量等- 1
- 2
五、 实验作业
- 提交实验报告电子稿和纸质稿,内容包括安装步骤及主要配置方法说明,关键步骤截图,并对截图内容进行解释说明;
- 个人对实验的总结和心得,本实验具有一定难度和繁琐程度,请总结与撰写自身遇到的问题,以及解决问题的过程。
- 搜索互联网并回答问题:谈谈我们如何利用大数据技术减少能源消耗和保护环境?
六、 实验结果与分析
1、安装步骤及主要配置方法说明
A、实验3-1 Scala语言编程基础
(1) Scala基本语法
(2) Scala基本数据类型和Scala函数等
1、编写脚本,安装scala


#! /bin/sh #run as zkpk@master #configure scala #configure scala echo "=====start to install scala=====" tar -xzvf /home/zkpk/tgz/spark/scala-2.11.0.tgz -C /home/zkpk echo 'export SCALA_HOME=/home/zkpk/scala-2.11.0' >> /home/zkpk/.bash_profile echo 'export PATH=$SCALA_HOME/bin:$PATH' >> /home/zkpk/.bash_profile source /home/zkpk/.bash_profile echo "=====scala installed successfully====="- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2、基础语法示例—输出hello,world
编写代码

测试

3、常见的数据类型和变量使用
命令行测试

4、函数的使用
编写代码1

运行测试1

编写代码2

运行测试2

编写代码3

运行测试3

柯里化函数的使用

可变长参数:可以向函数中传入多个同类型的参数

5、类的使用
构造函数


抽象类


B、实验3-2 弹性分布式数据集RDD基本操作
(1) RDD编程基础
(2) 转化和行动操作等1、启动spark-shell

2、RDD的创建与使用

使用textFile读取本地的系统文件,并计算整个文件中的字符总长度

3、RDD操作
4、函数的使用

5、用于操作k-v对的RDD操作

6、共享变量的使用
广播变量

累加器

C、实验3-3 Spark数据预处理实验——Apache服务器访问日志分析行
(1) 日志数据格式与数据预处理
(2) 统计PV、IP、页面访问量等1、启动spark-shell

2、解析日志文件

3、统计每日PV,使用count操作
4、使用sortByKey,按照请求日期字段进行排序,并将结果保存到本地


5、统计独立IP数
6、统计每种不同的HTTP状态对应的访问次数,并且以降序展示
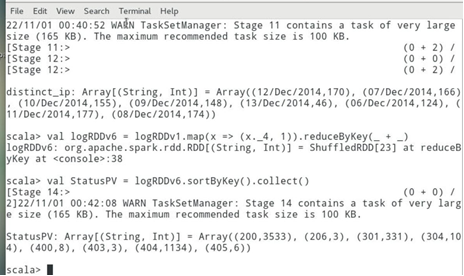
7、统计不同独立IP的访问量,按照降序排列并展示前10条

8、统计不同页面的访问量

9、由于日志中有大量的js文件的访问,因此我们增加一个去除列表,过滤掉属于列表中后缀名的文件再对过滤后的logRDDv9执行统计操作

2、实验的总结和心得
本次实验主要使用了Scala语言进行基本的操作,基本熟悉Scala的基本语法、数据类型以及函数的使用,在spark-shell下完成RDD的基本操作,根据实际业务需求使用spark 完成对Apache格式的日志内容的分析,了解了自定义日志过滤函数、日志预处理、日志的相关指标等操作。
因为Spark的源码是用Scala语言编写的,所以对我们来说学习Scala语言就很有意义,但是没有必要完全重新去学Scala,只要我们有一定的Java和C++的编程基础,基本看懂Scala问题不大,遇到不懂的再去查阅资料,这是一种更有效率的学习方法。
日志记录了web服务器接收处理请求以及运行时错误等各种原始信息。通过对日志进行统计、分析、综合,就能有效地掌握服务器的运行状况,发现和排除错误原因,所以学会日志的使用对我们更好的使用大数据平台至关重要。实验总结
- 利用脚本完成重复化的工作
- 在Scala中,如果子类和父类在实际上没有什么区别,那么类型别名是优于继承的
- RDDa.sortBy和RDDa.sortByKey中的sortBy和sortByKey都是transform操作,遇到action操作后才会触发操作
3、谈谈我们如何利用大数据技术减少能源消耗和保护环境?
随着现代信息通讯技术的迅速发展和广泛应用,智能制造、网络购物、移动支付、共享经济等产业蓬勃发展,大数据在其中发挥着非常重要的作用,对绿色发展特别是在绿色生产、绿色生活和美好环境等方面也表现出显著的促进作用。具体而言,大数据促进绿色发展主要是通过大数据进行资源整合、实施科学决策、建立公共服务平台、创新生态环境监管模式,促进提质增效、技术创新和环境治理,推动产业转型升级、需求结构优化,最终形成绿色生产和绿色生活的绿色发展模式,以及人民所向往的美好环境。
- 通过大数据整合资源,促进产业转型升级,实现提质增效
以互联网为桥梁,大数据把产品从生产到消费的全过程连接起来,成为绿色生产的关键
要素,为中国经济注入新动能。 - 通过建立公共服务平台和数据库推动绿色发展
随着大数据、互联网的迅速发展和节能、绿色生活、减少消费浪费等新观念的形成,分
享经济出现并得到快速发展。分享经济的出现,打破了企业对企业( B2B) 、企业对个人( B2C) 的传统交易模式,这种公共服务平台不仅为企业和个人带来巨大的经济效益,也极大地促进了绿色发展。公共服务平台依托大数据,通过对海量数据的分析和运用在供给与需求之间进行有效匹配,提高资源配置效率,减少资源消耗,实现绿色发展。这种公共服务平台在生产和生活方面都对绿色发展产生影响。 - 通过大数据保护生态环境,建设环境监管体系,促进绿色发展
目前,许多地方政府和有关管理部门都建立了生态环境数据信息管理系统,包括数据库、操作系统、开发应用等。但受部门间、部门内部封闭式的管理模式的影响,使得政府的不同部门之间、政府与企业之间、政府与社会公众之间数据信息资源不能顺利交流和有效利用,大量数据信息资源处于闲置状态,造成数据信息资源的严重浪费。生态环境大数据具有较强的数据信息整合功能,通过大数据的充分开发与应用,整合环保系统、相关部门、互联网企业的部门化、企业化、碎片化的生态环境数据信息,打破数据信息壁垒,形成全面完整的生态环境数据信息系统,从而实现生态环境决策的科学化,生态环境监管的精准化以及生态环境服务的便捷化。
-
相关阅读:
Go编译到linux运行出现 cannot execute binary file
[iOS开发]frame和bounds
好看的水滴登录页面
异常是怎么被处理的?这题的答案不在源码里面。
centos7安装mysql8.0
关于log4j安全漏洞以及版本替换的记录
xv6 进程切换中的锁:MIT6.s081/6.828 lectrue12:Coordination 以及 Lab6 Thread 心得
周志华机器学习——聚类算法。
拓世大模型 | 立足行业所需,发力终端,缔造智能无限可能
企业怎样申请SSL证书?
- 原文地址:https://blog.csdn.net/qq_50195602/article/details/127730710