-
从实际出发⭐《G1、JDK17、Flux性能调优》⭐
⭐本文从实际项目出发记录一次项目性能调优,很多时候都是无效优化,但学习过程十分有意义⭐
一、 项目介绍
项目主要是一个短连接服务,短连接服务的主要功能是减少占用文章主要内容,在实际链接和压缩后的链接做一层映射,功能类似网关;
本文不探讨短连压缩方案,只探讨怎么达到高性能;- 微博和Twitter都有140字数的限制,如果分享一个长网址,很容易就超出限制。
- 营销短信,字数的限制,当字数过长: 1.不美观 2.超出字符额外收费。
- 生成二维码的原始链接,当原始链接过长时,生成的二维码过于复杂,导致一些像素较低的手机无法扫描.
二、 项目主要架构
整体流程
以下是本次优化项目的架构,单纯的转换明显不满足性能要求,“过滤和拦截请求”中包含有主要业务需求:
- 黑名单拦截
- 访问域名拦截
- 白名单api配置
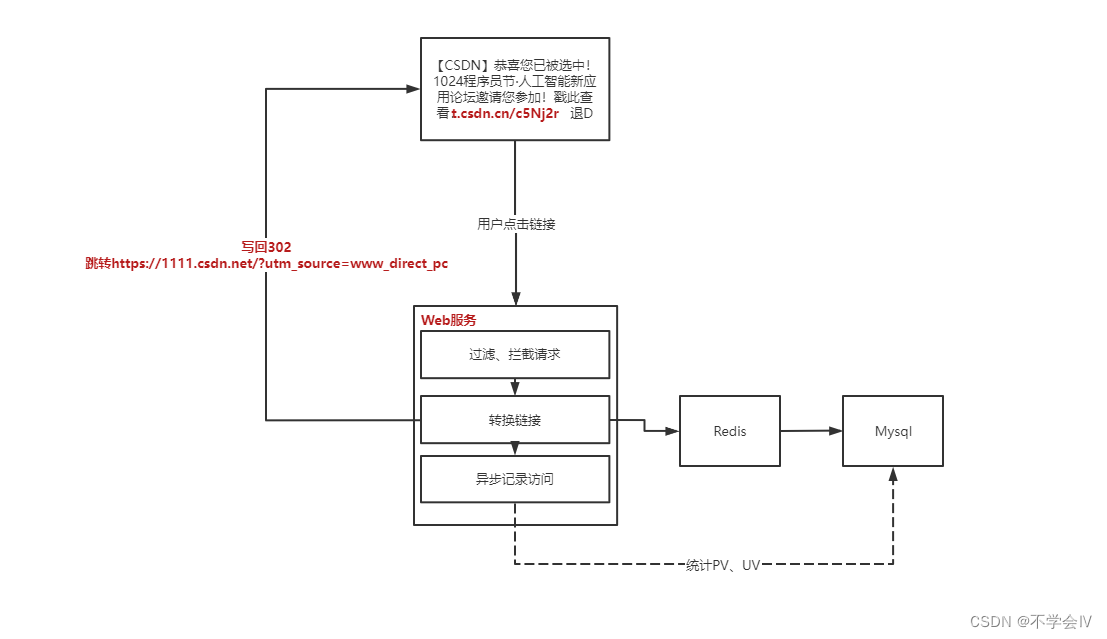
架构细节
Spring WebFlux:响应式框架、Netty容器
JDK17:G1垃圾收集器
同步Queue->定时任务:每1秒同步访问记录至数据库中,
优化前性能报告
- 部署环境是基于K8s
- 测试平台Jmeter(每次4000/共10轮下也保持tps900的数据)

三、性能优化
默认配置一核两G内存
3.1 JVM
本段主要谈论JVM层面优化
- 目前为JVM设置 -Xmx(最大堆内存) -Xms(最小堆内存) 已经谈不上专门优化,属于基本的操作,意义上就是避开后续申请释放堆内存的损耗。
- 为新生代设置内存 -Xmn ,在默认情况下不设置新生代内存
可以看出设置80%为新生代的时候GC次数是最少的,但这是结合项目而言,在上文描述项目里,并没有大批量的导出数据或大批量的需要长时间(1秒以上就算)维护的数据,请求产生的对象都是跟随请求结束而消亡,也就是:本项目产生的对象基本都是跟随请求结束变成垃圾;
此上分析本项目的垃圾既不会长时间存在,同时也都是小对象,所以垃圾基本分布在年轻代,调大年轻代对于gc频率是非常有帮助的。
非常重要的点-确认自己的项目:
- 不会有大对象&大量长时间存在的对象–调大年轻代
- 需要同步计算大数据量,没有长时间维护的对象–1/3早点让对象进入老年代,反而更加合理
- 最稳健的做法–不设置-JDK17默认G1,G1的存在避免很多优化,且动态分配内存更加合理

- JIT
笔者在学习JIT并且优化后,并没有发现相比默认配置下性能更优秀,故不解释,希望后续能Get到JIT的点后再优化
- JVM日志配置
3.2 编码层面
当下CPU的性能执行效率已经是非常快的程度了,几乎编码上不犯错,优化性能上是比较小的;
而项目为了优化存储效率上使用了本地异步落库:因为访问记录主要是为了统计PV、UV此类型数据丢失几秒是关系不大的。同时为了确保一定的安全系数,利用的Spring2.3后的”优雅关闭Spring项目”,异步的存在也是可以批量处理sql从而大幅度提高项目性能
而并发存入队列中使用的并发队列是本节的重点探讨反向,关于同步等待性能上是一大重点

上文中可以看到主要是投入线程安全队列中处理,故对主要的线程安全队列做了基准测试,结果 :并发队列基准测试
3.3 容器
flux采用的是Netty作为web容器,相比传统企业级、重量级的Tomcat提供的配置少之又少


在笔者一顿查找笔记和查看源码后:netty最直接的优化线程数与请求缓存大小,默认核心数从下文可以看出是跟随系统核心数,且Accept线程和Worker线程是一直的(Netty知识,读者自行补充)

设置Netty线程
当然也可以调整线程大小:通过设置程序变量修改线程数,调大固然是好的,但目前看起来框架本身不太推荐我们修改;
要想设置只能通过环境变量或者在java -jar 项目 -Dreactor.netty.ioSelectCount=10 以上两种方式去设置,而且设置必须按照核心数*1.5,那就得写脚本启动,不然只能每台机子自己设置reactor.netty.ioSelectCount=10 reactor.netty.ioWorkerCount=10- 1
- 2
设置请求缓存大小
而请求缓存主要是针对本项目,默认为128B

而本项目只有一个固定请求,故可以在application.property中设置请求初始buffer大小,减少内存分配次数(但会一定程度上浪费内存)
server.netty.initial-buffer-size=384B- 1

3.4 服务器
对于服务器上,基本上性能由硬件决定,而笔者的部署环境是K8s

需要注意的是K8s有弹性扩容配置的功能,那初始资源(所需资源)越小,会导致动态增加配置的次数增加和减低,这对突然的高并发是极其受限的
四、总结
可能确实是无效优化,但是学习过程十分有意义
-EOF-
-
相关阅读:
机器学习-4-模型评估和混淆矩阵和ROC曲线
基于Multisim的LC正弦波振荡器的设计与仿真
XUbuntu22.04之关闭todesk开机自启动(二百二十一)
2023年A-Level(IAL)考试安排
后续遍历非递归算法
【C++】模板初阶
map方法的使用:将原数组的每一项的属性值放大三倍?
Python知识点7---字典与集合
vue学习笔记:还不会上传文件,10分钟教会你使用input file上传文件
Linux工具(一)
- 原文地址:https://blog.csdn.net/qq_35040959/article/details/127694181