-
python-(6-3-1)爬虫---requests入门
一 安装requests
如果是按照我之前的方法,安装好了anaconda,那么系统是有requests的
如果没有,可以在控制台的命令窗口安装requests
命令是pip install requests
如果觉得安装太慢,可以用镜像源, 我这用的是清华镜像源pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests- 1
二 分析需求与代码展示
需求
在搜狗中,根据用户需求自由搜索某个内容,并将其内容爬取下来
步骤
首先,导入requests库
import requests- 1
然后,将用户输入的内容赋值给一个变量
query = input("请输入你要查询的内容:")- 1
接着,将输入的变量赋值给一个需要的url中。
请注意,这一步可以直接复制笔者的url,也可以在搜狗浏览器中随便搜一个内容,将得到的url复制下来,结果你会发现非常长,只需要将后面看不懂的那一部分删除掉,删除成笔者给出的下面url的格式,然后,重新搜索这个url,页面相同,表示url没有问题。url = f"https://www.sogou.com/web?query={query}"- 1
其次,得到url的get请求后的相应内容,并打印出来
resp = requests.get(url) print(resp.text)- 1
- 2
执行代码后,会出现下列的提示。

大概意思是,系统认为我们的浏览器请求是机器程序发出(的确如此),是异常的。反爬虫机制侦测到了,所以无法爬取内容。
这时我们需要引入一个概念
User-Agent,它描述了当前请求是由哪个设备发出的,我们需要利用这个参数伪装一下。在我们url的那个网页右键点击一下
“检查”—“Network"—url再次刷新一下—选择”web?query"那一列—Headers—“User-Agent”
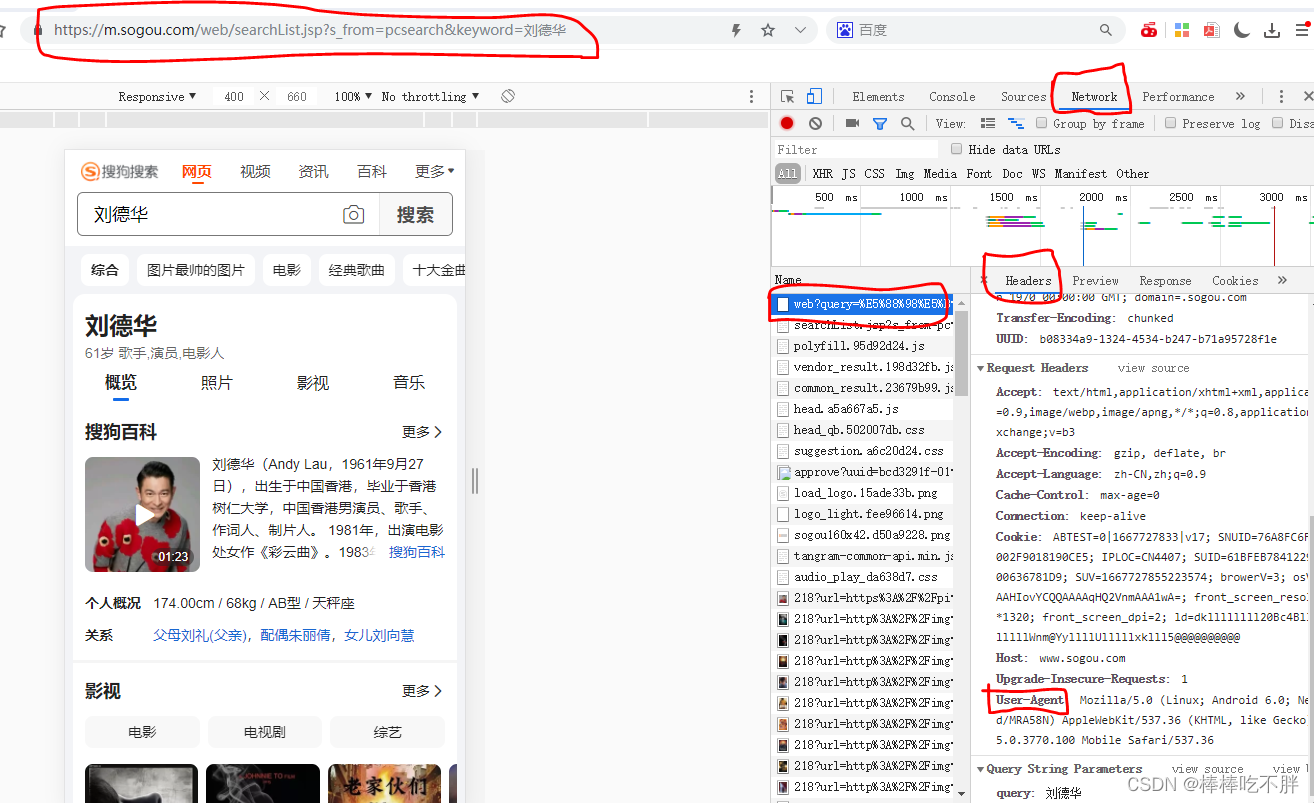
然后就可以得到我们需要的“User-Agent”代码如下:
dict = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36" } resp = requests.get(url,headers=dict) print(resp.text)- 1
- 2
- 3
- 4
- 5
如此,我们就处理了一个简单的小小的反爬,得到了网页源代码
最终结果
# 导入模块 import requests # 输入需要查询的内容 query = input("请输入你要查询的内容:") # 定义url变量 url = f"https://www.sogou.com/web?query={query}" # 获得User-Agent dict = { "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36" } # 处理了一个小小的反爬 resp = requests.get(url, headers=dict) # 得到了源代码 print(resp.text) # 关闭访问的链接,防止以后访问其他网页报错 resp.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
相关阅读:
无缝投屏技巧:怎样将Windows电脑屏幕共享到安卓手机?
Selenium-CSS定位
Linux使用之xshell、xftp保姆教学(含安装包,详细使用方法,连接失败解决方法)
《低代码指南》——国内首个向量数据库标准亮相,腾讯云联合50家企业共同编制
PostgreSql学习(基于菜鸟课程)
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC...
你需要知道的 TCP 四次挥手
SSRF漏洞
【业务功能篇102】springboot+mybatisPlus分页查询,统一返回封装规范
Connor学JVM - 执行引擎
- 原文地址:https://blog.csdn.net/oldboy1999/article/details/127718707
