-
Kafka学习笔记之进阶篇
Kafka 消息幂等性
enable.idempotence=true。设置了这个参数后,Producer自动升级成幂等性Producer。
两个重要机制:
1、Producer Id,幂等性的生产者每个客户端都有一个唯一编号id。
2、sequence number,幂等性的生产者发送的每条消息都会带相应的sequence number,Server端就是根据这个值来判断数据是否重复。如果发现sequence number比服务端已经记录的要小,那么说明数据已经重复了。
这个sequence number并不是全局有序的,不能保证所有时间上的幂等。它的作用范围有限。
1、 只能保证单分区上的幂等性,一个幂等性Producer能够保证某个Topic的一个分区上不出现重复。
2、 只能实现单会话上的幂等性,这里指Producer进程的一次运行,当重启了Producer进程后,幂等性不保证。分布式事务
1、 因为生产者的消息可能跨分区,所以这里的事务是属于分布式事务。分布式事务的实现方式有很多,kafka选择了最常见的两阶段提交(2PC)。如果大家都可以commit,那就commit,否则就abort。
2、 既然是2pc,那么就一定有一个协调者的角色,叫做Transaction Coordinator。
3、 事务管理必须有事务日志,来记录事务的状态,以便Coordinator在意外挂掉之后继续处理原来的事务。跟消费者offset的存储一样,kafka使用了一个特殊的topic_transcation_state来记录事务状态。
4、 如果生产者挂了,事务要在重启后可以继续处理,接着处理之前未处理完的事务,或者在其他机器上处理,必须有一个全局的唯一ID,这个就是transaction.id。配置了transaction.id,enable.idempotence会被设置为true。事务id相同的生产者,可以接着处理原来的事务。
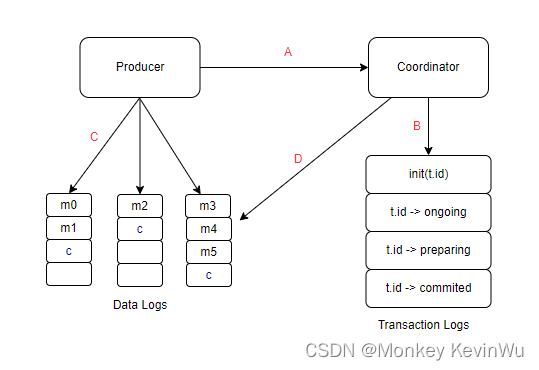
步骤:
1、 生产者通过initTransactions API向Coordinator注册事务id。
2、 Coordinator记录事务日志。
3、 生产者把消息写入目标分区。
4、 分区和Coordinator交互。当事务完成后,消息的状态应该是已提交,这样消费者才可以消费到。 -
相关阅读:
基于IoT全链路实时质量 - 魔洛哥
如何物理控制另一台电脑以及无网络用作副屏(现成设备和使用)
C++继承(二)多继承,菱形继承,继承中同名成员问题的解决,虚继承。虚基类表和虚基类表指针。
文学类容易发表的期刊或者学报有哪些?
Kotlin 开发Android app(九):Android两大布局LinearLayout和RelativeLayout
PCL (一)点云的格式
KMP算法(题目)
(附源码)spring boot信佳玩具有限公司仓库管理系统 毕业设计 011553
转自【AI科技评论】专访李海洲教授 | 机器智能对话是毕生所求
人工智能、深度学习、机器学习常见面试题83~100
- 原文地址:https://blog.csdn.net/u012663412/article/details/127729848