-
网络模型的参数量和FLOPs的计算 Pytorch
目录
FLOPS和FLOPs的区别:
- FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
- FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
在介绍torchstat包和thop包之前,先总结一下:
- torchstat包可以统计卷积神经网络和全连接神经网络的参数和计算量。
- thop包可以统计统计卷积神经网络、全连接神经网络以及循环神经网络的参数和计算量,程序示例等详见下文。
1、torchstat
pip install torchstat -i https://pypi.tuna.tsinghua.edu.cn/simple在实际操作中,我们可以调用torchstat包,帮助我们统计模型的parameters和FLOPs。如果不修改这个包里面的一些代码,那么这个包只适用于输入为3通道的图像的模型。
- import torch
- import torch.nn as nn
- from torchstat import stat
- class Simple(nn.Module):
- def __init__(self):
- super().__init__()
- self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1, bias=False)
- self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1, bias=False)
- def forward(self, x):
- x = self.conv1(x)
- x = self.conv2(x)
- return x
- model = Simple()
- stat(model, (3, 244, 244)) # 统计模型的参数量和FLOPs,(3,244,244)是输入图像的size

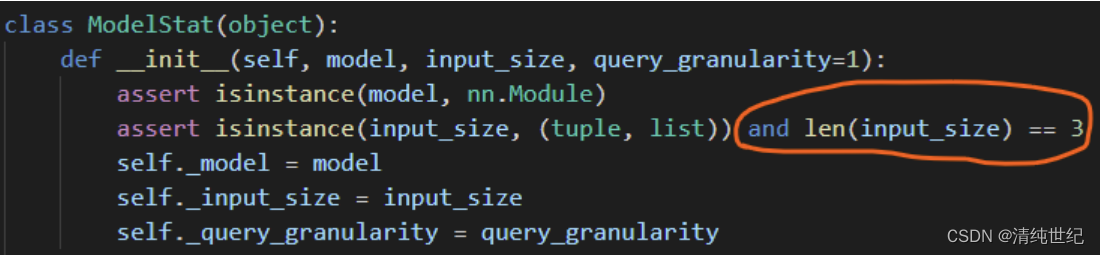
如果把torchstat包中的一行程序进行一点点改动,那么这个包可以用来统计全连接神经网络的参数量和计算量。当然手动计算全连接神经网络的参数量和计算量也很快 =_= 。进入torchstat源代码之后,如下图所示,注释掉圈红的地方,就可以用torchstat包统计全连接神经网络的参数量和计算量了。
2、thop
pip install thop -i https://pypi.tuna.tsinghua.edu.cn/simple- import torch
- import torch.nn as nn
- from thop import profile
- class Simple(nn.Module):
- def __init__(self):
- super().__init__()
- self.fc1 = nn.Linear(10, 10)
- def forward(self, x):
- x = self.fc1(x)
- return x
- net = Simple()
- input = torch.randn(1, 10) # batchsize=1, 输入向量长度为10
- macs, params = profile(net, inputs=(input, ))
- print(' FLOPs: ', macs*2) # 一般来讲,FLOPs是macs的两倍
- print('params: ', params)
3、fvcore
pip install fvcore -i https://pypi.tuna.tsinghua.edu.cn/simple用它比较好
- import torch
- from torchvision.models import resnet50
- from fvcore.nn import FlopCountAnalysis, parameter_count_table
- # 创建resnet50网络
- model = resnet50(num_classes=1000)
- # 创建输入网络的tensor
- tensor = (torch.rand(1, 3, 224, 224),)
- # 分析FLOPs
- flops = FlopCountAnalysis(model, tensor)
- print("FLOPs: ", flops.total())
- # 分析parameters
- print(parameter_count_table(model))
终端输出结果如下,FLOPs为4089184256,模型参数数量约为25.6M(这里的参数数量和我自己计算的有些出入,主要是在BN模块中,这里只计算了beta和gamma两个训练参数,没有统计moving_mean和moving_var两个参数),具体可以看下我在官方提的issue。
通过终端打印的信息我们可以发现在计算FLOPs时并没有包含BN层,池化层还有普通的add操作(我发现计算FLOPs时并没有统一的规定,在github上看的计算FLOPs项目基本每个都不同,但计算出来的结果大同小异)。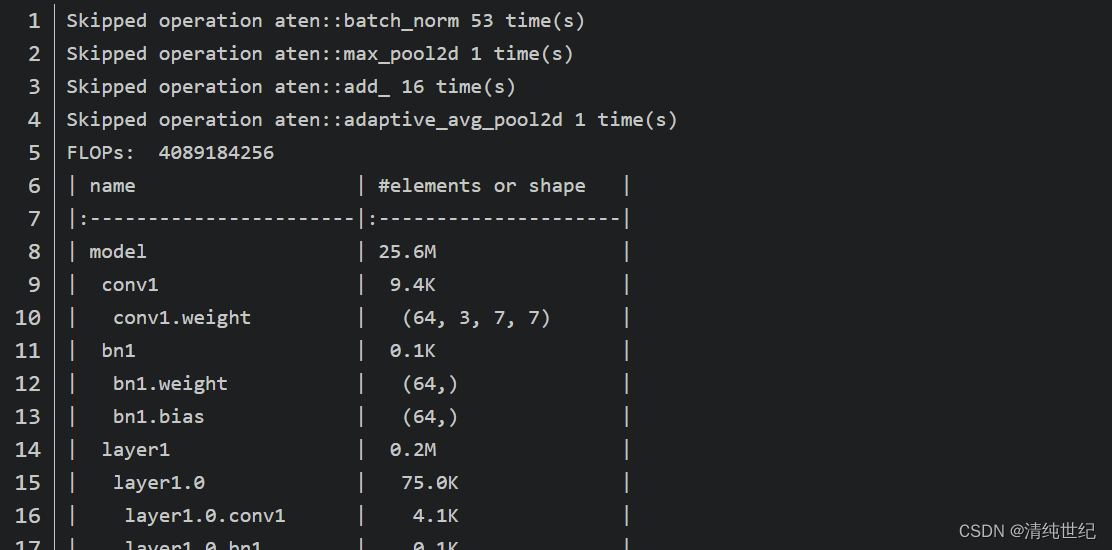
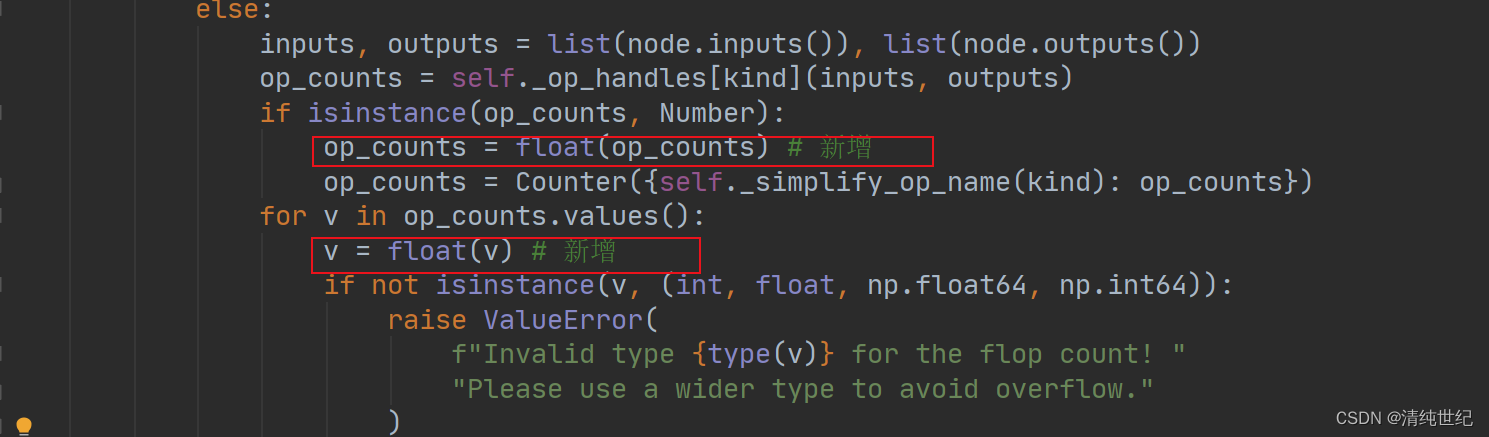
注意:在使用fvcore模块计算模型的flops时,遇到了问题,记录一下解决方案。首先是在jit_analysis.py的589行出错。经过调试发现,op_counts.values()的类型是int32,但是计算要求的类型只能是int、float、np.float64和np.int64,因此需要手动进行强制转换。修改如下:
4、flops_counter
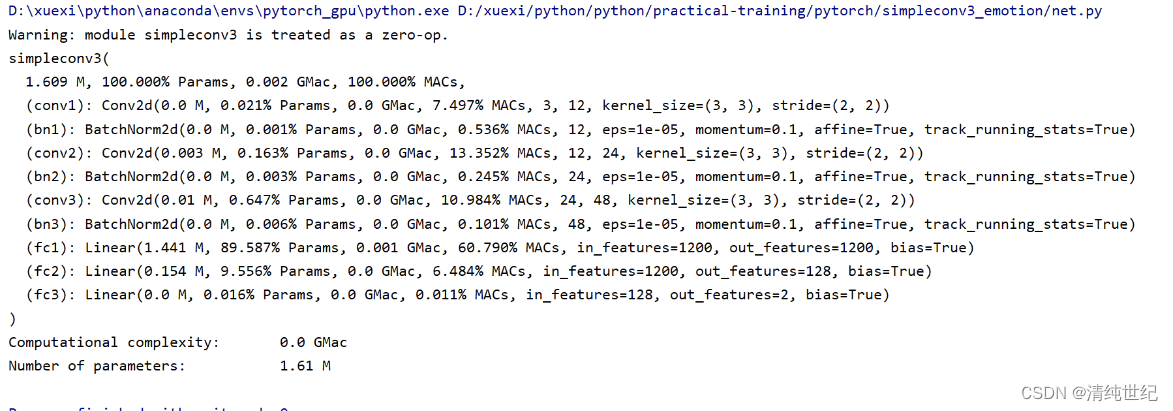
pip install ptflops -i https://pypi.tuna.tsinghua.edu.cn/simple用它也很好,结果和fvcore一样
- from ptflops import get_model_complexity_info
- macs, params = get_model_complexity_info(model, (112, 9, 9), as_strings=True,
- print_per_layer_stat=True, verbose=True)
- print('{:<30} {:<8}'.format('Computational complexity: ', macs))
- print('{:<30} {:<8}'.format('Number of parameters: ', params))
5、自定义统计函数
- import torch
- import numpy as np
- def calc_flops(model, input):
- def conv_hook(self, input, output):
- batch_size, input_channels, input_height, input_width = input[0].size()
- output_channels, output_height, output_width = output[0].size()
- kernel_ops = self.kernel_size[0] * self.kernel_size[1] * (self.in_channels / self.groups) * (
- 2 if multiply_adds else 1)
- bias_ops = 1 if self.bias is not None else 0
- params = output_channels * (kernel_ops + bias_ops)
- flops = batch_size * params * output_height * output_width
- list_conv.append(flops)
- def linear_hook(self, input, output):
- batch_size = input[0].size(0) if input[0].dim() == 2 else 1
- num_steps = input[0].size(0)
- weight_ops = self.weight.nelement() * (2 if multiply_adds else 1)
- bias_ops = self.bias.nelement() if self.bias is not None else 0
- flops = batch_size * (weight_ops + bias_ops)
- flops *= num_steps
- list_linear.append(flops)
- def fsmn_hook(self, input, output):
- batch_size = input[0].size(0) if input[0].dim() == 2 else 1
- weight_ops = self.filter.nelement() * (2 if multiply_adds else 1)
- num_steps = input[0].size(0)
- flops = num_steps * weight_ops
- flops *= batch_size
- list_fsmn.append(flops)
- def gru_cell(input_size, hidden_size, bias=True):
- total_ops = 0
- # r = \sigma(W_{ir} x + b_{ir} + W_{hr} h + b_{hr}) \\
- # z = \sigma(W_{iz} x + b_{iz} + W_{hz} h + b_{hz}) \\
- state_ops = (hidden_size + input_size) * hidden_size + hidden_size
- if bias:
- state_ops += hidden_size * 2
- total_ops += state_ops * 2
- # n = \tanh(W_{in} x + b_{in} + r * (W_{hn} h + b_{hn})) \\
- total_ops += (hidden_size + input_size) * hidden_size + hidden_size
- if bias:
- total_ops += hidden_size * 2
- # r hadamard : r * (~)
- total_ops += hidden_size
- # h' = (1 - z) * n + z * h
- # hadamard hadamard add
- total_ops += hidden_size * 3
- return total_ops
- def gru_hook(self, input, output):
- batch_size = input[0].size(0) if input[0].dim() == 2 else 1
- if self.batch_first:
- batch_size = input[0].size(0)
- num_steps = input[0].size(1)
- else:
- batch_size = input[0].size(1)
- num_steps = input[0].size(0)
- total_ops = 0
- bias = self.bias
- input_size = self.input_size
- hidden_size = self.hidden_size
- num_layers = self.num_layers
- total_ops = 0
- total_ops += gru_cell(input_size, hidden_size, bias)
- for i in range(num_layers - 1):
- total_ops += gru_cell(hidden_size, hidden_size, bias)
- total_ops *= batch_size
- total_ops *= num_steps
- list_lstm.append(total_ops)
- def lstm_cell(input_size, hidden_size, bias):
- total_ops = 0
- state_ops = (input_size + hidden_size) * hidden_size + hidden_size
- if bias:
- state_ops += hidden_size * 2
- total_ops += state_ops * 4
- total_ops += hidden_size * 3
- total_ops += hidden_size
- return total_ops
- def lstm_hook(self, input, output):
- batch_size = input[0].size(0) if input[0].dim() == 2 else 1
- if self.batch_first:
- batch_size = input[0].size(0)
- num_steps = input[0].size(1)
- else:
- batch_size = input[0].size(1)
- num_steps = input[0].size(0)
- total_ops = 0
- bias = self.bias
- input_size = self.input_size
- hidden_size = self.hidden_size
- num_layers = self.num_layers
- total_ops = 0
- total_ops += lstm_cell(input_size, hidden_size, bias)
- for i in range(num_layers - 1):
- total_ops += lstm_cell(hidden_size, hidden_size, bias)
- total_ops *= batch_size
- total_ops *= num_steps
- list_lstm.append(total_ops)
- def bn_hook(self, input, output):
- list_bn.append(input[0].nelement())
- def relu_hook(self, input, output):
- list_relu.append(input[0].nelement())
- def pooling_hook(self, input, output):
- batch_size, input_channels, input_height, input_width = input[0].size()
- output_channels, output_height, output_width = output[0].size()
- kernel_ops = self.kernel_size * self.kernel_size
- bias_ops = 0
- params = output_channels * (kernel_ops + bias_ops)
- flops = batch_size * params * output_height * output_width
- list_pooling.append(flops)
- def foo(net):
- childrens = list(net.children())
- if not childrens:
- print(net)
- if isinstance(net, torch.nn.Conv2d) or isinstance(net, torch.nn.ConvTranspose2d):
- net.register_forward_hook(conv_hook)
- # print('conv_hook_ready')
- if isinstance(net, torch.nn.Linear):
- net.register_forward_hook(linear_hook)
- # print('linear_hook_ready')
- if isinstance(net, torch.nn.BatchNorm2d):
- net.register_forward_hook(bn_hook)
- # print('batch_norm_hook_ready')
- if isinstance(net, torch.nn.ReLU) or isinstance(net, torch.nn.PReLU):
- net.register_forward_hook(relu_hook)
- # print('relu_hook_ready')
- if isinstance(net, torch.nn.MaxPool2d) or isinstance(net, torch.nn.AvgPool2d):
- net.register_forward_hook(pooling_hook)
- # print('pooling_hook_ready')
- if isinstance(net, torch.nn.LSTM):
- net.register_forward_hook(lstm_hook)
- # print('lstm_hook_ready')
- if isinstance(net, torch.nn.GRU):
- net.register_forward_hook(gru_hook)
- # if isinstance(net, FSMNZQ):
- # net.register_forward_hook(fsmn_hook)
- # print('fsmn_hook_ready')
- return
- for c in childrens:
- foo(c)
- multiply_adds = False
- list_conv, list_bn, list_relu, list_linear, list_pooling, list_lstm, list_fsmn = [], [], [], [], [], [], []
- foo(model)
- _ = model(input)
- total_flops = (sum(list_conv) + sum(list_linear) + sum(list_bn) + sum(list_relu) + sum(list_pooling) + sum(
- list_lstm) + sum(list_fsmn))
- fsmn_flops = (sum(list_fsmn) + sum(list_linear))
- lstm_flops = sum(list_lstm)
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
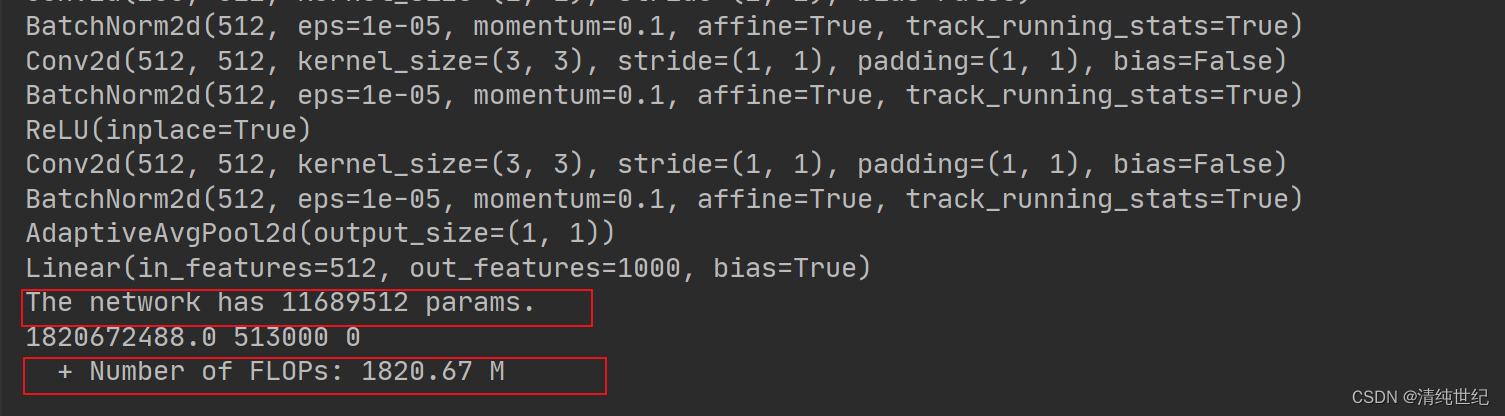
- print('The network has {} params.'.format(params))
- print(total_flops, fsmn_flops, lstm_flops)
- print(' + Number of FLOPs: %.2f M' % (total_flops / 1000 ** 2))
- return total_flops
- if __name__ == '__main__':
- from torchvision.models import resnet18
- model = resnet18(num_classes=1000)
- imput_size = torch.rand((1,3,224,224))
- calc_flops(model, imput_size)
-
相关阅读:
YOLO目标检测——汽车头部尾部检测数据集【含对应voc、coco和yolo三种格式标签】
Spring-重新认识IoC二
聊一聊国内大模型公司,大模型面试心得、经验、感受
C++进阶篇1---继承
Spring Cloud Alibaba Seata 实现分布式事物
题目:2729.判断一个数是否迷人
一篇文章让你彻底掌握 shell 语言
k8s 集群安装
Docker:学习笔记【1】
归并排序--排序算法
- 原文地址:https://blog.csdn.net/qq_45100200/article/details/127728053