-
Reading Note(7)——AutoDSE
这篇文章是梳理AutoDSE的一篇札记,论文是:
《AutoDSE: Enabling Software Programmers to Design Efficient FPGA Accelerators》
ACM Trans on DAES‘22这是一篇专注于自动设计空间探索的文章,目的是减少FPGA加速器开发过程中的手动代码重构和繁琐的参数调整。
0. Abstract
这篇文章的摘要部分简单地介绍了AutoDSE框架的设计初衷,一方面是因为高性能可重构加速器的需求猛增,另一方面又是因为FPGA编程的门槛太高导致软件设计人员无法对FPGA进行自由高效的开发。虽然FPGA开发门槛因为HLS的引入而大幅降低,但是在这个过程中设计人员仍然需要对很多设计参数进行探索和尝试,这也带来了巨大的负担。
虽然已经有类似的基于学习技术的模型来进行自动设计空间探索,但是因为HLS工具的不可预测性导致这些模型的学习精度都比较差。
AutoDSE是一种基于瓶颈引导的坐标优化器(Bottleneck-guided coordinate optimizer)的优化框架,AutoDSE自动检测每一步设计中的瓶颈并聚焦于高影响力参数来克服它。结果显示AutoDSE在很多测试集合上的表现远远超过了CPU,并且远远优于现有HLS工具链手工优化的结果。
1. Introduction
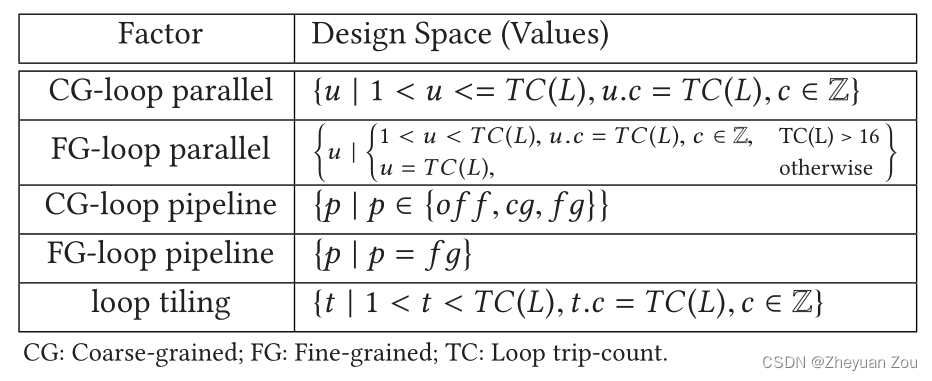
这部分首先通过一些实例表明了人们对FPGA可定制计算的兴趣越来越大,但是囿于FPGA开发的高门槛FPGA的相关部署始终难以铺展开来。虽然HLS工具链的出现在一定程度上缓解了这样的问题,但是HLS的开发同样需要丰富的硬件知识,还需要以一种特殊的方式来编写HLS程序才可以比较好地挖掘比较好的加速器架构。以下是一个卷积算子的例子:

这是以一种以软件工程师友好的方式编写的代码,逻辑上也完全正确,这样的代码也可以被HLS工具链综合生成可以正确完成卷积运算的RTL电路,但是它的性能大约是单核CPU的几十分之一,性能非常低。这表明HLS工具链距离自动生成高性能加速器之间还有很大的距离,这需要设计者进行适当的循环变换和插入编译指导语句,工作量很大,涉及到的硬件架构知识点也非常多,一般的软件设计人员很难驾驭。但是如果按照更加高效的方式来编写代码,但是在分析了下表的5个性能瓶颈因素并且插入了28个编译指导项之后,卷积运算就可以加速到单核性能的7041倍,从而得到了高效的FPGA加速器。下面是影响加速器结构的5个常见因素,和它们对应的解决方法。

然后,这部分提出了三个优化级别帮助设计者开发出高性能的FPGA加速器,这也是设计出一款加速器所必须的三个优化层次。
1.通过施加循环变换来增加数据重用和减少数据依赖性,这一条对于软件设计人员是容易接受的,因为写出cache友好的代码也需要这样的变换。
2.需要施加重复的架构优化来使得性能提升(这里之所以叫做重复的架构优化,是因为这样的优化技术适用于大部分场景),比如memory burst和memory coalescing,它们分别对应于上述表格中的因素1和2。这样的一些重复工作目前可以由Merlin编译器自动完成,Merlin编译器也作为标准的一部分被Xilinx所采纳,所以这部分也不需要设计人员来手动参与。
3.最后一部分是涉及特定的FPGA体系结构的优化,这部分对于设计人员来说是最难驾驭的。它对应于表格中的因素3-5,Merlin编译器可以在这里做一些简单的工作,但还远远不够,DSE框架往往作用于此。
最后,这部分提出目前上面所提的第三个优化层次是导致FPGA设计门槛很高的原因,所以DSE工具应运而生,它旨在让只有软件经验的设计者以最小的努力设计最高效的加速器结构。但是已有的DSE工作面临如下的一些挑战:
挑战1:超大规模搜索空间,可选的方案随着编译指导语句的的增加呈现指数级增长
挑战2:设计参数对性能/面积的影响是非单调/非平滑的,每一个设计参数的选择对整体架构设计的影响不是完全平滑和单调的。
挑战3:不同设计因素之间是相关的,各个设计参数之间是相互关联的,改变其中一个参数会影响到其他参数的表现。
挑战4:HLS工具链的异构性,不同厂商之间提供的HLS工具链之间具有很大的实现差异,这也会导致相同的代码综合出不同的硬件结构。
挑战5:DSE工具应该是高效的,DSE工具应该在有限的迭代步骤中快速找到帕累托最优点。(帕累托最优是经济学中的一个概念,这里可以理解为最优设计点)这篇文章将使用基于瓶颈的坐标优化器(bottleneck-guided coordinate optimizer)来系统地搜索设计最优点,这种基于瓶颈的优化器已经被用在了CPU和GPU上,并且速度很快。但是对于FPGA来说这样的搜索方式较慢,为了解决这个问题,AutoDSE提出了一种灵活的列表理解语法(a flexible list-comprehension syntax)来帮助刻画网状的设计空间,并且可以将无效的设计点标记从而达到剪枝的效果。
这篇工作的贡献如下:
1.提出了两种可以指导DSE的策略方法,第一种是使用有限微分法调整坐标下降法(coordinate descent with the finite difference method),另外一种就是瓶颈引导的坐标优化器(bottleneck-guided coordinate optimizer)。2.在这个分析框架中结合了列表理解(list comprehension),来表示一个平滑的网格设计空间,其中无效的设计点都被标出,方便剪枝。
3.AutoDSE框架构建于Merlin编译器之上,使用基于瓶颈的优化器来系统地搜索设计空间。
4.本篇工作使用Xilinx optimized vision library这样一个高度优化的库来对AutoDSE进行评估,结果表明AutoDSE可以达到和上述库几乎一样的性能,但是插入的编译优化项少了26.38倍,平均下来一个计算核心只需要少于一个编译优化项。
5.AutoDSE可以在包括MachSuite和Rodinia等测试基准上实现相对于单线程CPU 19.9倍的加速效果,这和手工优化相比只有7%的差距。
2.PROBLEM FORMULATION
这部分给出了AutoDSE要解决的问题的公式化定义,首先这部分将HLS中现有的编译指导语句分为了两种类型:非优化类型和优化类型,使用非优化类型的指导语句比较简单,而使用优化类型的指导语句(比如PIPELINE和UNROLL)就比较困难,需要比较深刻的微体系结构知识。
AutoDSE要解决的问题有两个:
1.定义设计空间
2.在定义的设计空间中找出最优配置而AutoDSE的要解决问题2的定义就是在用户可用资源有限的情况下,尽可能地减少需要手动插入的优化编译指导项的数量,并且获得尽可能高性能的加速器结构,形式化定义的解释在这里不再详细阐述,而是简单截图保存:
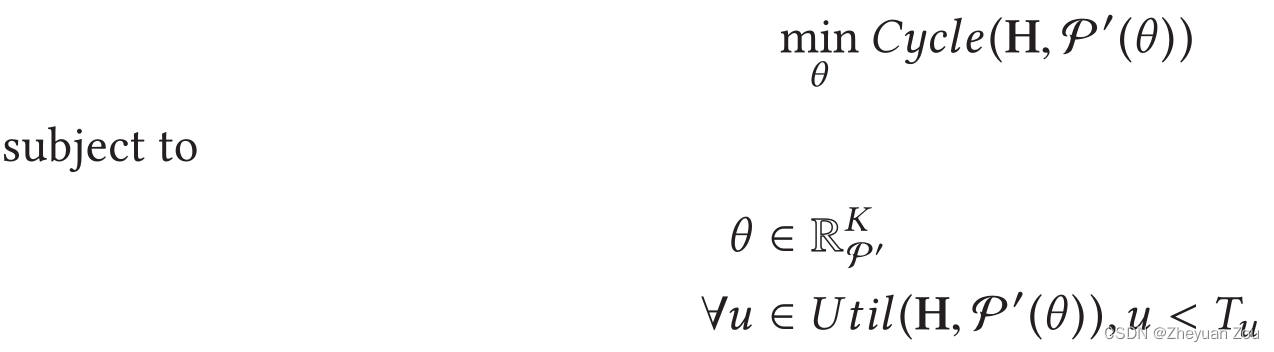
注意我们要优化的问题2的目标有两个:
1.获得尽可能高性能的加速器架构
2.手工插入尽可能少的优化编译指导项3. RELATED WORK
这部分介绍了有关DSE的相关工作,将已有的DSE工作分为基于模型(model-based)和无模型(model-free)的方法。
4.THE AUTODSE FRAMEWORK
4.1 Merlin Compiler and Design Space Definition
之前提过,AutoDSE的构建基于Merlin编译器,Merlin编译器通过引入一组高级别的编译优化指令来提高FPGA的抽象级别,这样可以大大减少插入的编译指导项的数量。Merlin编译器编译优化项中与架构有关的部分展示如下:

注意其中粗粒度流水线指的其实是通过代码变换来实现双缓冲技术,细粒度流水线指的是将子循环完全展开并施加细粒度的流水化。正是因为Merlin编译器自动提升了FPGA的设计抽象程度,所以它支持插入更少的编译指导语句。这使得DSE的空间大大缩小,这篇工作选用Merlin编译器的原因也在于此,它的特征支持了对DSE的大幅度剪枝,从而可以提升DSE的效率。使用Merlin编译器加速卷积需要插入的编译指导语句如下:

Merlin编译器可以提供的优化结构如下,我们首先将前面提及的设计关键瓶颈因素表复制过来:
在这里的5个因素中,Merlin编译器可以通过代码变换直接将因素1-2进行消除,而对于剩下的限制因素Merlin编译器则提供了相应的编译指导项来帮助解决。只需要提供编译指导项,Merlin编译器就会自动地将代码重写为编译指导项所要求的格式,所以DSE的问题最终就变成了如何在Merlin C语言中的合适位置和层次插入编译指导项。因此在Merlin编译器的帮助下,问题的最终定义落回了如何在合适的位置插入Merlin C编译指导语句,所以问题1(定义设计空间)得到了良好的解决。AutoDSE对设计空间的定义如下:
在实际运行时,AutoDSE通过分析每个计算核心的抽象语法树,来收集包括循环趟数,可用位宽等信息。4.2 Framework Overview
AutoDSE的整体框架如下:
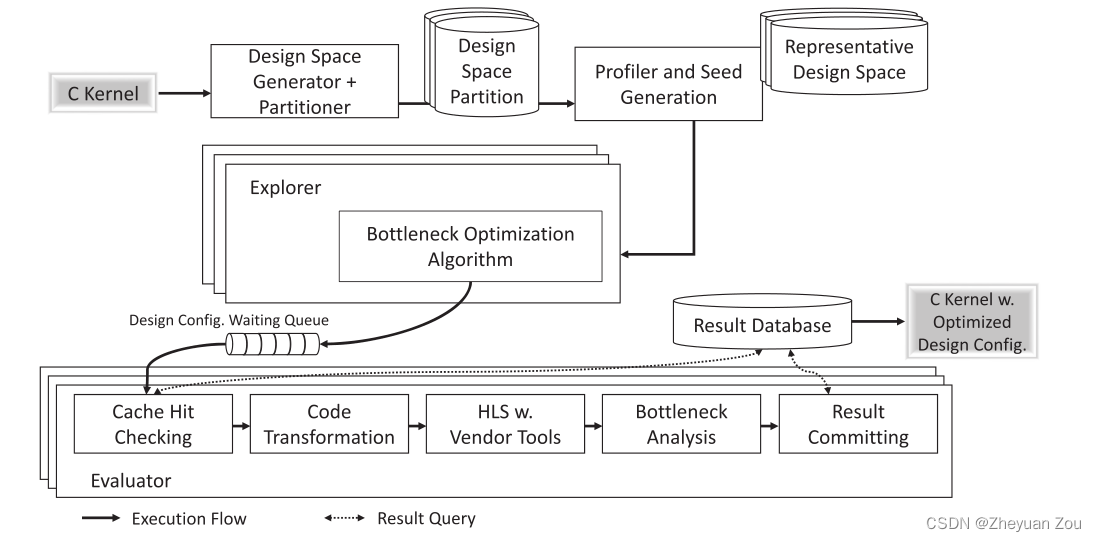
结合上图AutoDSE的工作流程大致可以总结如下,框架首先通过分析输入内核的抽象语法树,并根据规则来建立一个设计空间。随后使用K-Means聚类算法来从中选取比较有代表性的划分方案。对于每一个划分方案AutoDSE执行基于瓶颈的坐标优化和参数排序来进行设计空间探索,在进行探索时可以设置不同的评估指标(比如可以是:功耗、面积或性能)。当完成对当前分区的探索时,资源管理器可以将工作线程分配给其他分区以提升资源利用率。在所有分区探索完成之后,AutoDSE可以输出所有分区中具有最佳效果的设计点。5. AUTODSE METHODOLOGY
在这部分首先将展示应用无关的启发式方法的局限性,应用无关的启发式方法对程序参数的语义一无所知,因而会在对设计没有作用的参数探索上花费大量时间。而基于瓶颈的坐标优化器则有效地模拟了专家手动探索的过程,因而可以以更短的时间找到更好的设计点。
5.1 Application-oblivious Heuristics
应用无关的启发式搜索
这里首先提及了Jason Cong课题组之前的一个工作:S2FA,这个框架基于OpenTuner,而OpenTuner采用了multi-armed bandit (MAB) (多臂老虎机?)的方式集成了多种启发式搜索方法。(这里顺带提一嘴,OpenTuner也是提出Halide的那个MIT实验室的作品)S2FA这个自动设计空间探索框架也是基于Merlin编译器构建的,但是在实际使用时发现S2FA这样一种基于启发式规则的搜索很难找到影响设计的参数瓶颈,每次都会在瓶颈参数的搜索中耗费大量的时间,尝试大量的无用配置。此外,S2FA需要大约16.8小时才可以找到最优解决方案,这个效率还是太低了。
含有有限差分法的坐标下降
除了使用S2FA基于的启发式规则来寻找全局最优点,坐标下降法也是另外一种基于迭代的优化算法,此算法的基本思想是一个多元函数可以通过一次最小化一个方向的坐标值来分阶段求解,这样多变量优化问题就转化为了多阶段的单变量优化问题。
具体来说,假设我们有k个可调参数,那么每一次迭代向算法输入的候选配置就有k个,也就是说每一次将每一维度上的参数向后更新一步来获得一个新的候选。
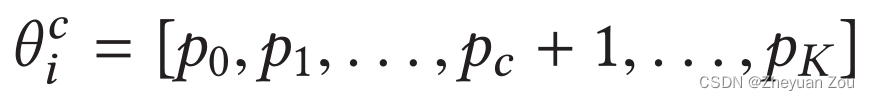
接下来要做的就是按照给定的评价指标来寻找下一个更好的配置,也就是说对于上述生成的k个候选,我们要将HLS当作黑盒运行k次来获得一个最优解,并以此最优解作为下一步的迭代开始点:
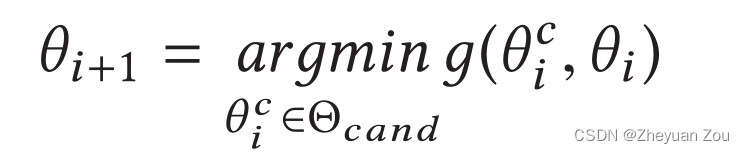
为了避免上述的坐标下降法陷入局部最优解,这里还加上了有限差分法来评估每一个候选的实际质量。有限差分法着眼于搜索的长远性,而不是使用贪心策略寻找最优解。具体而言使用如下的差分公式来评估候选的质量,这个差分在考虑性能的同时还一并考虑到了资源利用率,这会使得盲目消耗资源以换取最优性能的设计点被淘汰。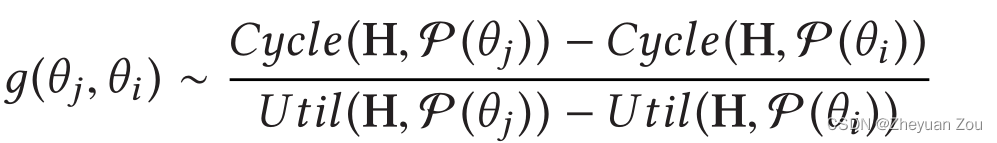
看上去含有有限差分的坐标优化法还挺不错,但事实上它的效果比S2FA的启发式规则还要差,这就是因为之前提过的单个因素对性能的影响不是单调的/平滑的,所以这种方法很容易被困在局部最优点。此外,这种方法的效率也受到可调参数的限制,事实上在所有的k个参数中,只有少数的几个对性能起着决定性作用,这种方法会对所有的候选进行探索,而事实上我们只需要对处于关键地位(瓶颈地位)的少数几个参数进行探索就可以获得很好的结果,多余的搜索是徒劳的。5.2 AutoDSE Exploring Strategy - Bottleneck-guided Coordinate Optimizer
在之前的部分中我们总结了两种方法,这两种方法的弊端可以总结如下:
1.它们必须评估足够多的设计点,才可以找到设计瓶颈
2.它们都不知道参数的语义,所以它们无法区分它们,也无法找出重要的参数那么AutoDSE如何确定参数呢?在这里它使用Merlin编译器的反馈报告来确定瓶颈参数。Merlin编译器可以将用户输入代码的性能分解报告(performance breakdown)回传给用户代码,通过遍历Merlin编译器生成的报告,就可以将瓶颈语句映射到设计参数。
以下是一个例子,Merlin编译器会将转换过程详细地记录在转换记录中,所以它可以将HLS估计的延迟回传给用户代码。

1.首先,AutoDSE会建立一个循环或函数声明到设计参数的映射,以便知道对于特定的语句应该关注哪一个设计参数。2.接着,AutoDSE使用DFS的方式遍历Merlin报告来获取关键路径和类型,更确切地说它会从顶层函数开始,对每一个层级检查它是否含有子语句并将其按照延迟进行排序,这个过程会逐层递归下去,对于函数也是一样,会深入到函数体中构建它的组成路径。最后会返回一个列表,这个列表中的每条关键路径都会按照Merlin报告中的延迟进行由大到小的排序。
3.最后,AutoDSE会针对每一条语句,再次遍历Merlin报告来确认它的瓶颈是访存还是计算。
在完成上述工作之后,我们获得了按照延迟进行排序的关键路径列表和每一条语句的瓶颈,AutoDSE着手开始进行解决瓶颈参数问题。因为之前的是按照DFS的顺序来进行的,所以解决问题也会从循环最内部的语句开始。 AutoDSE会根据它的瓶颈是访存还是计算来选择不同的优化参数,如果瓶颈是访存那么将尝试TILING,反之则尝试PARALLEL。
由此可见,至此,AutoDSE使用了三个方式来减少DSE探索过程中的开销,从而加速探索过程:
1.使用Merlin编译器而非原生HLS来进行探索,Merlin编译器的高抽象性天然地缩减了搜索空间
2.在设计空间中分析Merlin报告找到设计瓶颈来专门探索
3.涉及到具体的优化,AutoDSE会根据瓶颈类型(访存or计算)来施加针对性的优化,避免盲目尝试AutoDSE对所谓设计点(Design Point)的定义如下,这是DSE评估的对象:

各个参数的含义如下:1.configuration存储着所有参数的当前值
2.tuned存储着当前设计点已经评估过的参数
3.result存储着从HLS反馈回来的所有相关信息,包括资源消耗和时钟周期
4.quality存储着使用差分法计算出来的设计点质量
5.children是一个栈,里面按照瓶颈分析器得到的重要性存放着一系列将要探索的设计点,每一个孩子都是将设计参数的某一维,步进一步得到的此外还有一个概念,就是设计点的级别(level),一个设计点位于级别n表示它固定了n个参数的值。
随后这部分粘贴了一个
又臭又长的算法来细致地描述何谓基于瓶颈引导的坐标优化器,代码实在太长了,我也不想贴出来了orz,可以自己看原文。5.3 Parameter Ordering
这部分描述的大体意思是,AutoDSE往往会面临一个瓶颈有多种优化方案,在这里AutoDSE根据HLS处理的实际情况,对尝试这些参数的先后顺序(优先级)做了提前的约定,这可以看作是一种特殊的启发式优化。比如说,对于瓶颈是计算的情况,AutoDSE规定尝试的优先级如下:
1. fine-grained pipelining
2. parallel
3. coarse-grained pipelining之所以这样做,一方面是HLS可以更好地处理细粒度流水化,另一方面也是因为这样可以进一步提升AutoDSE找到最优设计点的速度。在实际执行时,对HLS工具的时间限制是60分钟,如果不按照上述的顺序进行调度,不仅仅不能很好地利用HLS工具的特性,甚至还会在时间限制内无法完成评估,导致最优解直接丧失。
所以,参数排序也是AutoDSE中非常重要的一种优化手段。
5.4 Efficient Design Space Representation
这一步是为了进一步提升搜索效率而对设计空间进行剪枝,也就是说在不同层次循环中施加的优化选项之间可能是相互矛盾的,在设计空间探索时将这些无效的、矛盾的设计点排除掉就可以得到更加高效的探索方式。如下所示:

如果P1是施加在外层循环的优化措施,P2是施加在内部循环的优化措施,当P1选择双缓冲区技术来进行优化时(即cg pipeline选项),P2在内部无法并行。所以这些设计点都是无效,对设计空间的探索应该将这些点全部排除在外(就像在上图中打叉)。为此AutoDSE提出了一种基于python列表的表示方案,它的一个简单的例子如下:

P1的options表示它有三种选择,并且在默认情况下不施加优化,P2的options则表示它只有在P1的不是cg pipeline时才有探索的必要。通过这样一种基于python列表的表示反感,AutoDSE成功实现了对互斥设计空间点的排除。文中说,这样一种基于列表的设计空间表达方法有三个明显的优点:
1.这种表示方法有效地减少了要探索的设计点数量,加速了探索过程
2.这种基于python列表的表示方法是通用的,它可以自然地和多面体分析或其他DSL进行结合来生成设计空间
3.这种表示方法和python解释器兼容,可以在未来使用python解释器来评估设计空间这里提了一下,AutoDSE使用了Rose编译器来对计算核心代码进行分析,Rose编译器这项工作可以关注一下。
在这一段的最后,总结了AutoDSE涉及到的设计空间剪枝规则,展示如下,基于列表的表示方法将对下面的情况进行剪枝。:

最后回顾一下,我们之前提过AutoDSE加快设计空间探索的三个措施:

而这一节提出的手段是第四点加速手段,即引入特殊的设计空间表示方法排除一些存在互斥的选项。5.5 Design Space Partitioning
上述的诸多优化手段并没有解决单个设计参数对性能的影响非单调/非平滑这样一种情况。为此,AutoDSE将设计空间划分为多个分区,并行地对它们进行搜索,并从中找出表现最好的值,防止搜索结果落入局部最优。
但是为了避免分区过于膨胀,AutoDSE只从中选择了可能对最终性能结果和耗费资源影响最大的两个设计参数,即粗粒度和细粒度流水化(fg/cg pipeline),作为可能的设计空间划分因素。不仅如此,这些流水化划分出来的分区结果,可能相当一部分的性能表现是十分接近的,所以AutoDSE额外对分区执行了K-MEANS聚类算法,从中找出最具有代表性的一些设计点(聚类中心)去探索,从而在保证设计点不落入局部最优的同时维持了比较高的探索效率。
6. EVALUATION
从略,请参见原文。
7. CONCLUSION AND FUTURE WORK
从略,请参见原文。
-
相关阅读:
【无标题】
【自学开发之旅】Flask-标准化返回-连接数据库-分表-orm-migrate-增删改查(三)
讲座记录|1024学科周讲座分享
【区块链 | solidity】智能合约Gas 优化的几个技术
【C++面向对象】5. this指针
Hadoop
【Postman-windows-9.12.2版本安装与汉化】
51单片机项目(10)——基于51单片机的电压计
阿里云服务器10M带宽容纳多少人同时在线?
解决vue A对象赋值给B对象,修改B属性会影响到A的问题
- 原文地址:https://blog.csdn.net/zzy980511/article/details/127629269