-
实验七—高级数据管理(一)
实验7 高级数据管理(一)
实验目的:
(1) 使用规范的R语言完成程序设计。
(2) 掌握R语言自定义函数的方法,了解R语言自定义函数返回值的特殊性。
(3) 掌握R语言多种类型的系统库函数。
实验内容
1 编程实现:10以内所有偶数的和。
even_sum<-function(x){ sum=0 for (i in x) { if(i%%2==0){ sum=sum+i } } return(sum) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

2 编程实现:随机生成向量X,由20个[1,50]之间服从均匀分布的正整数组成,求X中偶数的个数。
even_count<-function(X){ count=0 for(i in X){ if(i%%2==0){ count=count+1 } } return(count) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

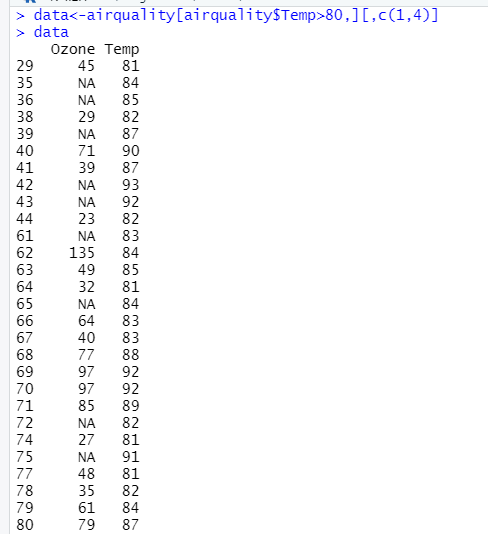
3 从R自带airquality数据集中取出Temp值大于80 的Ozone、Temp列的值。
> data<-airquality[airquality$Temp>80,][,c(1,4)] > data Ozone Temp 29 45 81 35 NA 84 36 NA 85 38 29 82 39 NA 87 40 71 90 41 39 87 42 NA 93 43 NA 92 44 23 82 61 NA 83 62 135 84 63 49 85 64 32 81 65 NA 84 66 64 83 67 40 83 68 77 88 69 97 92 70 97 92 71 85 89 72 NA 82 74 27 81 75 NA 91 77 48 81 78 35 82 79 61 84 80 79 87 81 63 85 83 NA 81 84 NA 82 85 80 86 86 108 85 87 20 82 88 52 86 89 82 88 90 50 86 91 64 83 92 59 81 93 39 81 94 9 81 95 16 82 96 78 86 97 35 85 98 66 87 99 122 89 100 89 90 101 110 90 102 NA 92 103 NA 86 104 44 86 105 28 82 117 168 81 118 73 86 119 NA 88 120 76 97 121 118 94 122 84 96 123 85 94 124 96 91 125 78 92 126 73 93 127 91 93 128 47 87 129 32 84 134 44 81 143 16 82 146 36 81- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
4 验证性实验:
按照课本5.3“数据处理难题的一套解决方案”,生成一组包含10条观测的原始学生花名册(自己设计并生成学生姓名信息,如 Yilong Zhu),math数据由rnorm(10,400,50)随机获得,Science数据由rnorm(10,60,10)随机获得,English数据由rnorm(10,20,5)随机获得。验证代码清单5-6。其中的步骤7尝试用自己的方法解决。
#数据准备 options(digits = 2)#限定了输出小数点后数字位数,提高可读性 Student<-c("Yilong Zhu","Kezhi Zhou","John Davis","Mary Rayburn","Kobe Bryant", "Michael Jordan","Leborn James","Legend Wang","Cheryl Cushing","David Jones") Math<-round(rnorm(10,400,50)) Science<-round(rnorm(10,60,10)) English<-round(rnorm(10,20,5)) roster<-data.frame(Student,Math,Science,English,stringsAsFactors = FALSE) print(roster) #计算综合得分 z<-scale(roster[,2:4])#标准化 score<-apply(z, 1, mean) roster<-cbind(roster,score) print(roster) #对学生评分 y<-quantile(score,c(.8,.6,.4,.2)) roster$grade[score>=y[1]]<-"A" roster$grade[score- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40




5 自定义函数:
编写R函数,输入一个整数n,如果n<=0,则中止运算,并输出“Please input a positive integer.”否则,如果n是偶数,则将n除以2,并赋值给n;否则,将3n+1赋值给n,不断循环,直到n=1,停止运算。并输出“Success”. 调用该函数,验证函数的正确性。
jiaogu<-function(n){ if(n<=0) return("Please input a positive integer.") else while(n!=1) if(n%%2==0) n=n/2 else n=3*n+1 return("Success") }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

6 自定义函数,计算n的阶乘。并调用该函数,输出1-10的阶乘。
fact<-function(n){ if(n==0) return(1) else return(n*fact(n-1)) } for(i in 1:10) print(fact(i))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

7 编写函数计算f(n)=11+22+33+…nn,并调用计算n=2和n=4时的值。
fn<-function(n){ sum=0 for(i in 1:n) sum=sum+i^i return(sum) }- 1
- 2
- 3
- 4
- 5
- 6

8 R语言中包含一个名为 stackloss 的基础数据集,请加载该数据集,用str() head() tail()探索该数据集,并得出每一个变量的均值,分位数,方差,标准差,以及两两之间的协方差。
> data<-stackloss > str(x) 'data.frame': 21 obs. of 4 variables: $ Air.Flow : num 80 80 75 62 62 62 62 62 58 58 ... $ Water.Temp: num 27 27 25 24 22 23 24 24 23 18 ... $ Acid.Conc.: num 89 88 90 87 87 87 93 93 87 80 ... $ stack.loss: num 42 37 37 28 18 18 19 20 15 14 ... > head(x) Air.Flow Water.Temp Acid.Conc. stack.loss 1 80 27 89 42 2 80 27 88 37 3 75 25 90 37 4 62 24 87 28 5 62 22 87 18 6 62 23 87 18 > tail(x) Air.Flow Water.Temp Acid.Conc. stack.loss 16 50 18 86 7 17 50 19 72 8 18 50 19 79 8 19 50 20 80 9 20 56 20 82 15 21 70 20 91 15 > mean<-apply(data, 2, mean) > mean Air.Flow Water.Temp Acid.Conc. stack.loss 60 21 86 18 > quantile<-apply(data,2,quantile) > quantile Air.Flow Water.Temp Acid.Conc. stack.loss 0% 50 17 72 7 25% 56 18 82 11 50% 58 20 87 15 75% 62 24 89 19 100% 80 27 93 42 > var<-apply(data,2,var) > var Air.Flow Water.Temp Acid.Conc. stack.loss 84 10 29 103 > sd<-apply(data,2,sd) > sd Air.Flow Water.Temp Acid.Conc. stack.loss 9.2 3.2 5.4 10.2 > cov(data) Air.Flow Water.Temp Acid.Conc. stack.loss Air.Flow 84 22.7 24.6 86 Water.Temp 23 10.0 6.6 28 Acid.Conc. 25 6.6 28.7 22 stack.loss 86 28.1 21.8 103- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50


9 熟悉系统函数:
1.) 使用strsplit()拆分字符串,已知字符串c("1990-1995”,”1996-2000”,”2001-2005”),以”-”作为分隔符将其拆分为包含三个元素的列表,并使用unlist()将列表转换为向量。
> s<-c("1990-1995","1996-2000","2001-2005") > s [1] "1990-1995" "1996-2000" "2001-2005" > year<-strsplit(s,"-") > year [[1]] [1] "1990" "1995" [[2]] [1] "1996" "2000" [[3]] [1] "2001" "2005" > unlist(year) [1] "1990" "1995" "1996" "2000" "2001" "2005"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

2.) 使用paste()生成如下字符串x
“AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz”,
- 使用substr提取出其中的第8到第20个字符之间的字符串
- 使用substr将x中第第8到第20个字符全部替换为“1”
> s=paste(LETTERS,letters,sep = "",collapse = "") #或者paste0(LETTERS,letters,collapse = "") > s [1] "AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz" > substr(s,8,20) [1] "dEeFfGgHhIiJj" > substr(s,8,20)<-"1111111111111" > s [1] "AaBbCcD1111111111111KkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

3.) substr()也可以处理字符串向量,请验证如下代码
website<-c(www.google.com,”www.yahoo.com”,”www.facebook.com”)
substr(wetsite,5,nchar(website)-4)
> website<-c("www.google.com","www.yahao.com","www.facebook.com") > substr(website,5,nchar(website)-4) [1] "google" "yahao" "facebook"- 1
- 2
- 3
- 4

10 某班学生考试成绩如下表所示,完成下列任务:

a) 要求至少有10个观测,成绩列随机生成,姓名列自己编写。
b) 对每位学生的各科成绩求均值,要求小数点保留两位小数。
c) 将求得的均值添加为表的最后一列score。
d) 平均成绩90分以上的划分为等级A,90-80分的划分等级为B,70-80分的划分等级为C,60-70的划分等级为D,60分以下的划分等级为E。并将等级添加为表的一列。列名为level.
e) 将数据框按照等级进行升序排序
name<-c("Linda","Mike","John","Emily","James","Mark","White","Tom","Aimy","Frank") math<-round(rnorm(10,85,12)) english<-round(rnorm(10,85,6)) python<-round(rnorm(10,87,10)) df<-data.frame(name,math,english,python) print(df) score<-apply(df[,2:4],1,mean) df$score<-score print(df) df$level[score>=90]<-"A" df$level[score>=80 & score<90]<-"B" df$level[score>=70 & score<80]<-"C" df$level[score>=60 & score<70]<-"D" df$level[score<60]<-"E" df<-df[order(df$level),] print(df)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16


一键整合,万用万灵,Python3.10项目嵌入式一键整合包的制作(Embed)
操作系统第五章——输入输出管理(上)
延时消息队列
BGP联邦综合实验
【科学文献计量】标准参考出版年谱(Standard RPYS)和多维参考出版年谱(Multi RPYS)
【FPGA教程案例54】深度学习案例1——基于FPGA的CNN卷积神经网络之理论分析和FPGA模块划分
数字化转型巨浪拍岸,成长型企业如何“渡河”?
Codeforces Round #835 (Div. 4) F. Quests
缓存学习总结3(服务器内存缓存)推荐使用