-
【4. 主从复制】
概述
- 在实际工作中,经常用
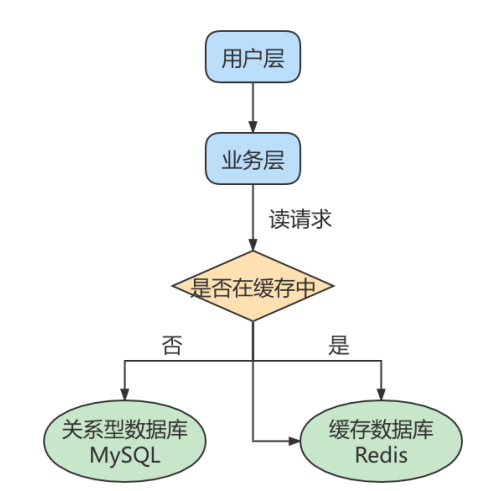
Redis和MySQL搭配使用,当有请求时,首先会从缓存中进行查询,如果存在就直接取出。如果不存在在访问数据库,这样就提升了读取效率,也减少了后端数据库的访问压力。 - 一般对数据库而言都是
读多写少,对于数据库的读取数据压力比较大,所以可以采用数据库集群的方案,做主从架构、进行读写分离,同样可以提升数据库并发处理能力。
主从复制作用
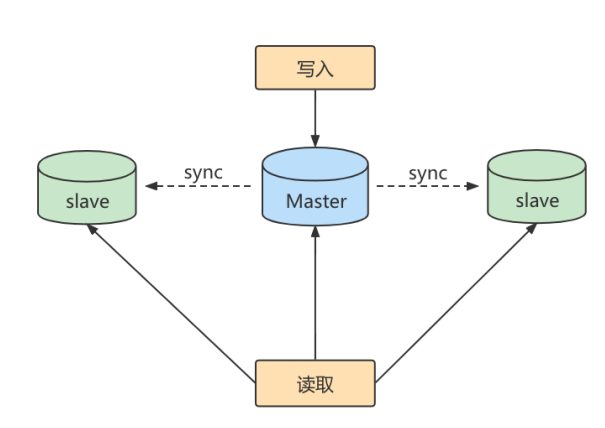
读写分离:由于读多写少,master主库充当写库,salve从库充当读库,当主库更新时,会自动将数据复制到从库中,而客户端读取数据时,会从从库中进行读取,面对读多写少,采用读写分离,在实现高并发的同时,还能对从服务器进行负载均衡,让不同的读请求按照相应策略均匀的分发到不同的从服务器上,而且减少锁表的影响,主库写锁时,从库依旧可以读。数据备份:通过主从复制将主库上的数据复制到了从库上,相当于一种热备份机制,也就是在主库正常运行的情况下的备份,不会影响到服务高可用性:数据库备份实际上是一种冗余的机制,通过冗余的方式可以换取数据库的高可用性,也就是当服务器出现故障或宕机情况下们可以切换到从服务器上,保证服务的正常运行。
主从复制原理
- MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。
- 这个过程是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。
Slave会从Master读取binlog来进行数据同步。但是也可能出现主库将数据同步到从库需要500ms,而此时主库刚写完,就要从读库读(假设读200ms),此时就会出现延迟问题,这就需要后面的方法。
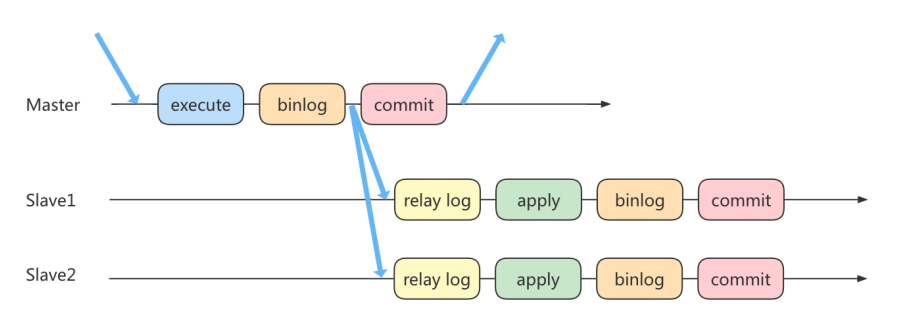
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程
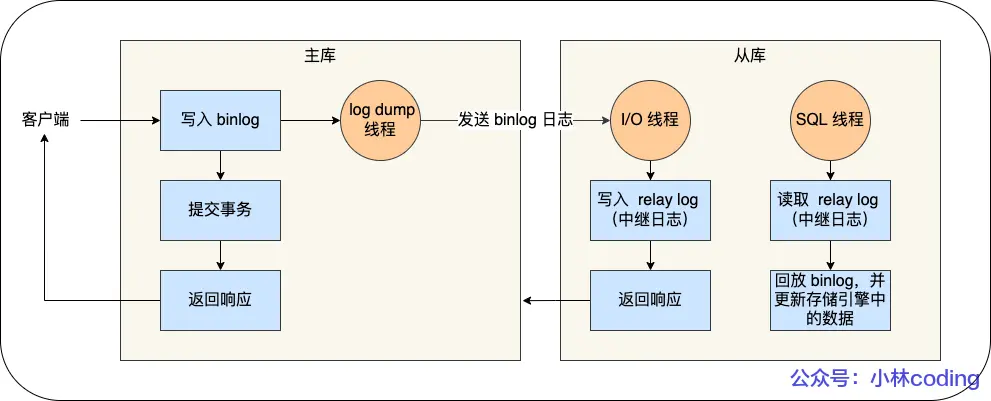
复制三步骤
- 写入 Binlog: 主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog: 把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog: 回放 binlog,并更新存储引擎中的数据。
具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
- 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
- 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
复制的问题
- 复制的最大问题:
延时
从库是不是越多越好?
- 从库连接上来的 I/O 线程也比较多,主库也要创建同样多的 log dump 线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。
MySQL 主从复制还有哪些模型?
- 同步复制
- 异步复制
- 半同步复制
数据同步一致性问题
主从延迟
- 进行主从同步的内容是二进制日志,它是一个文件,在进行 网络传输 的过程中就一定会 存在主从延迟。这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的 数据
不一致性问题。
主从延迟问题原因
- 在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T2-T1的值是非常小的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢
如何减少主从延迟
- 优化SQL,避免慢SQL,
减少批量操作 提高从库机器的配置,减少主库写binlog和从库读binlog的效率差- 尽量采用
短的链路,提升端口带宽 - 实时性要求的业务读强制走主库,从库只做灾备,备份。
如何解决一致性问题
- 如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。但这时从库的作用就是
备份,并没有起到读写分离,分担主库读压力的作用。 读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题
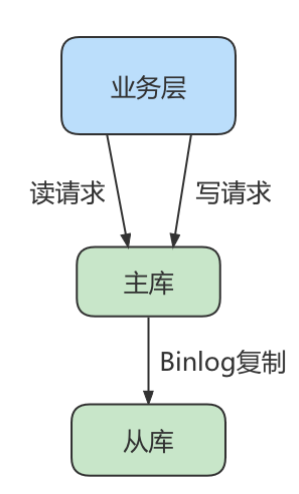
方法 1:异步复制- 异步模式就是客户端提交COMMIT之后不需要等从库返回任何结果,而是直接将结果返回给客户端,这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而Binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,这种复制模式下的数据一致性是最弱的。
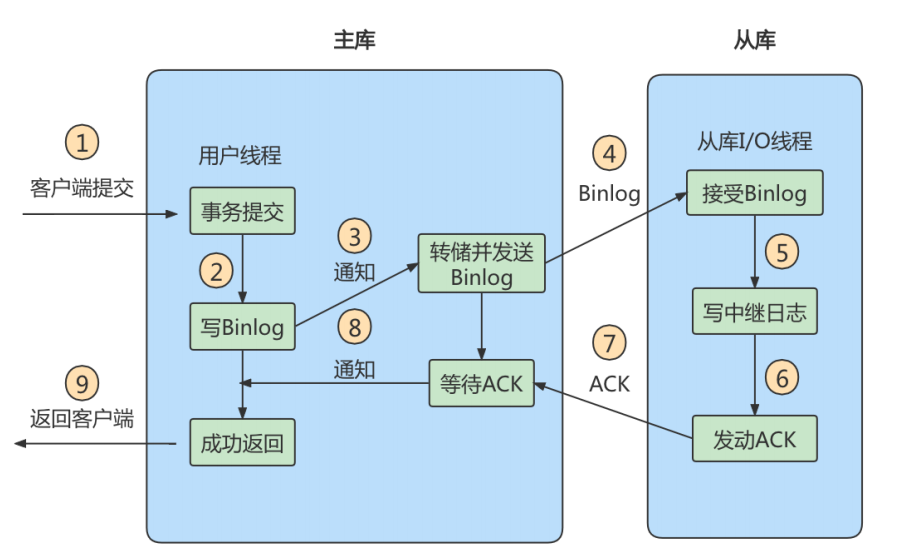
方法 2:半同步复制- 原理是在客户端提交COMMIT之后不直接将结果返回给客户端,而是等待至少有一个从库接收到了Binlog,并且写入到中继日志中,再返回给客户端。这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
方法 3:组复制- 异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景
- 首先我们将多个节点共同组成一个复制组,在 执行读写(RW)事务 的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对 只读(RO)事务 则不需要经过组内同意,直接 COMMIT 即可。
- 在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。

- 在实际工作中,经常用
-
相关阅读:
10/15/2022
Yakit单兵作战神器简单使用
Fanuc发那科数采
RCP-第2章 ROS+Matlab
解读谷歌Pathways架构(二):向前一步是OneFlow
docker部署Golang程序
cs231n作业1——Softmax
【Android】反编译与预防被反编译
【服务器虚拟化数据恢复】ESXI虚拟机误还原快照的数据恢复案例
redis悲观锁和乐观锁
- 原文地址:https://blog.csdn.net/weixin_45043334/article/details/127712202