-
Ylearn因果推断入门实践——Kaggle银行客户流失
YLearn的因果学习开源项目,它提供了一站式处理因果学习完整流程的开源算法工具包,解决了因果学习中的因果发现、因果量识别、因果效应估计、反事实推断和策略学习等五大关键问题,可以有效帮助客户进一步提升自动化决策的能力。
YLearn覆盖从因果发现、评估到决策一系列模块的端到端开源框架,能够有效降低决策者的使用门槛。
https://github.com/DataCanvasIO/YLearn
YLearn的使用从Why开始。
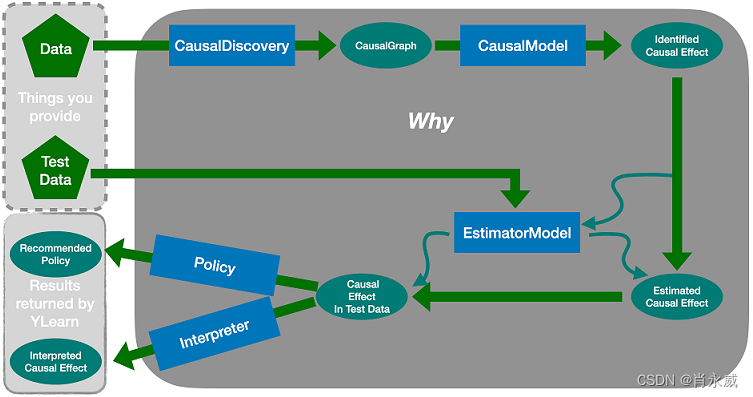
Why 是一个封装了YLearn中几乎所有功能的API,比如,识别因果效应和给一个训练好的估计器模型打分。它提供给用户一个简单且有效的方式来使用YLearn的包:能够直接传入你仅有的东西,数据到 Why 中并使用它的多个方法,而不是学习多个概念,比如在能够找到藏在你的数据中有趣的信息之前学习调整集合。Why 被设计成能够执行因果推断的完整流程:给出数据,它首先尝试发现因果图,如果没有提供的话。接着它尝试找到可能作为干预的变量和识别因果效应。在此之后,一个合适的估计器模型将被训练用以估计因果效应。最终,估计对于每一个个体最佳的选项的策略。
1. 概述
本实践案例用一个典型的银行客户流失预测数据集来演示YLearn的一体式API Why的使用。Why涵盖因果学习的整个流程,包括因果发现、因果效应识别、因果效应估计、反事实推理和政策学习。
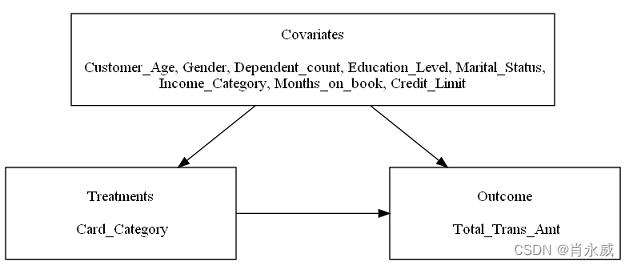
首先,创建一个Why实例,该实例需要通过调用其方法fit()进行训练。引入了自定义设置(具有定义的干预)和默认设置(通过算法本身发现干预)。执行以下实用程序(如plot_causal_graph()、causal_effect()和whatif())来分析各种反事实场景。另一个关键方法policy_interpreter()提供了一个定制的解决方案来优化输出。
预测客户流失的目的是为了留住客户,让客户更多的使用信用卡,消费多了,银行的收益也就最大化了。把预测流失,怎么能留住客户的问题,变换为直接目标,让客户更多的消费而银行获利,怎么办呢?本例的策略是提升客户信用卡的级别(提升信用卡级别,透支额度增大,使用费用增加)。
2. 数据集
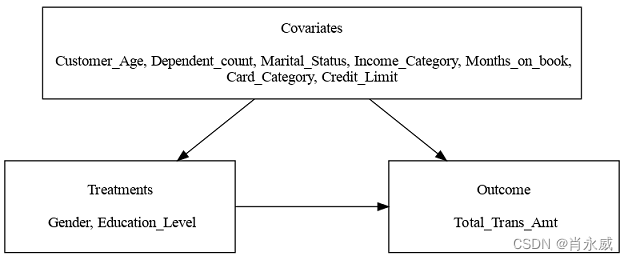
本案例中使用的数据集是Kaggle银行客户流失数据集的一个子集。它的目的是预测流失的客户。然而,我们使用它来分析产生总交易金额的原因,并提供定制策略以最大化交易金额。数据集包含约1万名客户的信息,其中近20个连续和分类变量代表了用户的特征。我们手动选择10个变量来分析它们的因果关系和因果效应,如下所示:
- 客户一般特征:Customer_Age(年龄)、Gender(性别)、Dependent_count(相关账户数)、Education_Level(受教育程度)、Marital_Status(婚姻状态)、Income_Category(收入分类区间)
- 客户信用卡功能:Months_on_book(账面月数)、card_Category(卡类别/级别)、credit_Limit(信用额度)
- 客户交易金额:Total_Trans_Amt,Total_Trans_Amt是此笔记本中的结果。
数据集地址:https://www.kaggle.com/datasets/syviaw/bankchurners
数据集内容描述如下:
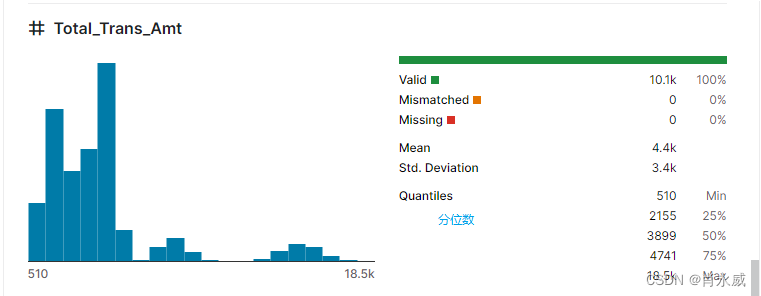
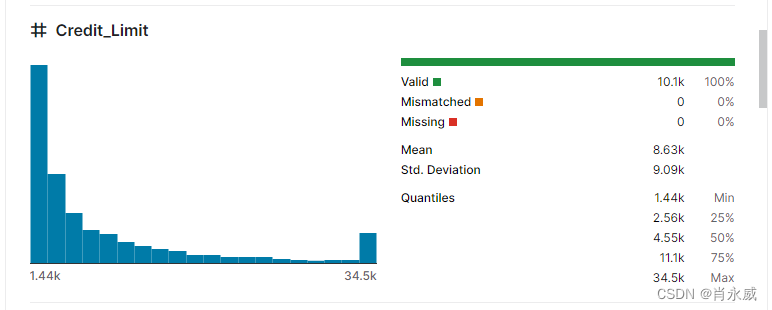
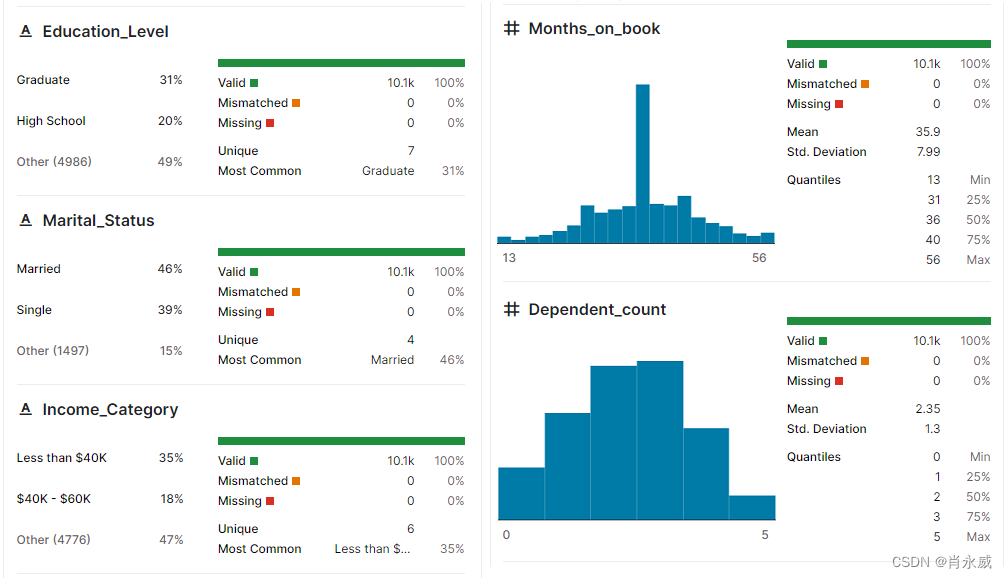
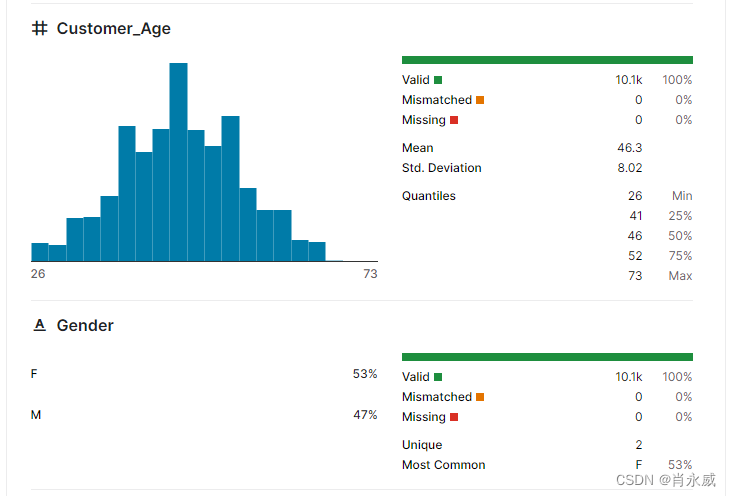
3. 开始第一个YLearn实践
案例开源地址:
https://github.com/DataCanvasIO/YLearn/blob/main/example_usages/case_study_bank.ipynb数据集地址:
https://github.com/DataCanvasIO/YLearn/blob/main/example_usages/data/BankChurners.csv.zip3.1. 安装YLearn
由于本案例使用开源最新代码,直接安装的Release 0.1.3(Latest)版本不是最新的,缺少功能,需要手动编译最新源代码进行安装,我已经把安装包上传为资源“YLearn安装包”。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple E:\temp\YLearn-main\dist\ylearn-0.1.3-cp38-cp38-win_amd64.whl
3.2. 开始并获取数据
import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.model_selection import train_test_split from ylearn import Why import warnings warnings.filterwarnings('ignore') df = pd.read_csv('data/BankChurners.csv.zip') cols = ['Customer_Age', 'Gender', 'Dependent_count', 'Education_Level', 'Marital_Status', 'Income_Category', 'Months_on_book', 'Card_Category', 'Credit_Limit', 'Total_Trans_Amt' ] data = df[cols] outcome = 'Total_Trans_Amt' train_data,test_data=train_test_split(data,test_size=0.3,random_state=123) data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.3.明确干预的因果关系
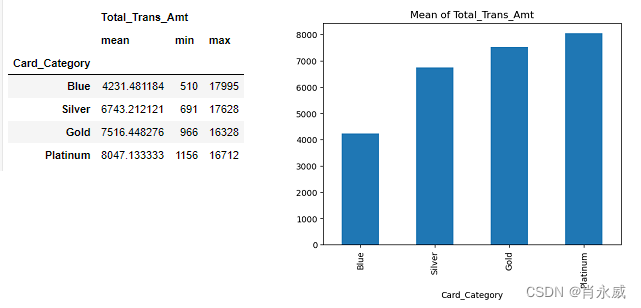
3.3.1. 统计卡片类别
Card_Category是一个分类的、合理的变量。卡片类别和相应的平均交易金额概览如下所示。
card_stat=train_data[['Card_Category','Total_Trans_Amt']].groupby('Card_Category').agg(['mean','min','max',]).sort_values(by=('Total_Trans_Amt','mean')) card_stat[('Total_Trans_Amt','mean')].plot(kind='bar', title='Mean of Total_Trans_Amt') card_stat- 1
- 2
- 3
- 4
3.3.2. 了解为什么,treatment=‘Card_Category’
首先,创建一个Why实例。然后使用fit()方法训练模型,该方法定义了treatment=‘Card_Category’。打印的日志显示了已识别结果和使用的标识符的信息。
要可视化因果关系,请使用plot_causal_graph()获得因果图。
why=Why() why.fit(train_data,outcome,treatment='Card_Category') why.plot_causal_graph()- 1
- 2
- 3
- 4
3.3.3. 估计因果影响
有四种类型的卡片类别:蓝色、银色、金色和白金。将蓝色作为控制变量,其余三个作为治疗变量,方法causal_effect()输出三个因果效应估计。从结果中,我们发现卡片升级会增加个人交易金额。金卡的效果最强。
effect=why.causal_effect(control='Blue',return_detail=True) effect=effect.loc['Card_Category'].sort_values(by='mean') details=effect.pop('detail') plt.figure(figsize=(10, 5)) plt.violinplot(details.tolist(), showmeans=True) plt.ylabel('Effect distribution') plt.xticks(range(1,len(effect)+1), details.index.tolist()) plt.plot( [0, ]*(len(effect)+2) ) plt.show() effect- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
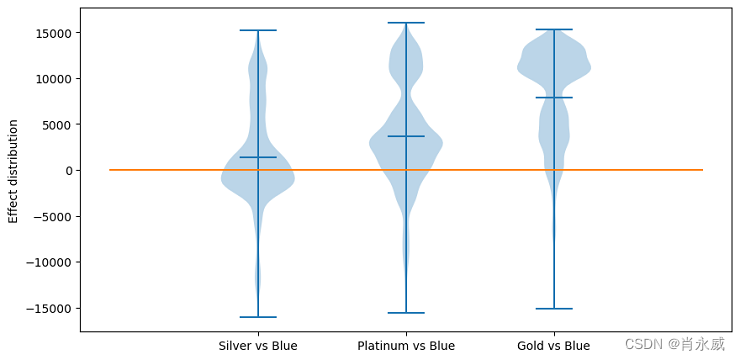
其中:
causal_effect(test_data=None, treatment=None, treat=None, control=None, target_outcome=None, quantity=‘ATE’, return_detail=False, **kwargs)
估计因果效应。参数:
- test_data (pandas.DataFrame, optional) – 用于评估因果效应的数据集。如果是None的话则使用fit时的数据集。
- treatment (str or list, optional) – treatment名称或列表。应当是属性 treatment_ 的子集。缺省是属性 **treatment_**的所有元素。
- treat (treatment value or list or ndarray or pandas.Series, default None) – 对于单个离散的treatment,treat应当是treatment所有可能值中的一个;对于多个离散的treatment,treat应当是由每个treatment的值组成的一个列表(list);对于连续性treatment,treat应当是与test_data行数相同的ndarray或pandas.Series。缺省是None,由Why自行推断。
- control (treatment value or list or ndarray or pandas.Series, default None) – 与treat类似。
- target_outcome (outcome value, optional) – 仅当outcome是离散型是生效。缺省是属性 y_encoder_.classes_ 中的最后一个元素。
- quantity (str, optional, default ‘ATE’, optional) – ‘ATE’ or ‘ITE’, 缺省是 ‘ATE’。
return_detail (bool, default False) – 是否在返回结果中包括因果效应的详细数据(detail)
返回:
所有治疗的因果效应。当quantity=’ATE’时,返回结果的DataFrame包括如下列:- mean: 因果效应的均值
- min: 因果效应的最小值
- max: 因果效应的最大值
- detail (当 return_detail=True时 ): 以ndarray表示的因果效应的详细数据。
当quantity=’ITE’时,返回结果是由个体因果效应组成的DataFrame。
返回类型:
pandas.DataFrame其中ATE —— Average Treatment Effect(ATE),平均干预效果:
A T E = E [ Y ( W = 1 ) − Y ( W = 0 ) ] ATE = E[Y(W=1)-Y(W=0)] ATE=E[Y(W=1)−Y(W=0)]3.3.4. 反事实推理
作为决策者,他们想知道如果升级客户的卡类别,估计的增量。Whatif()提供了进行反事实推理的解决方案。
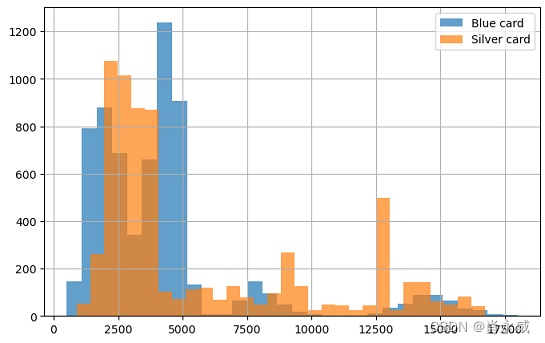
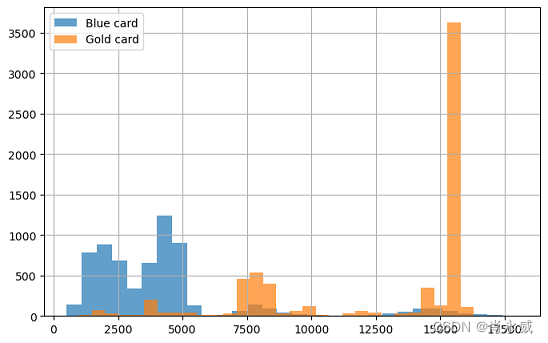
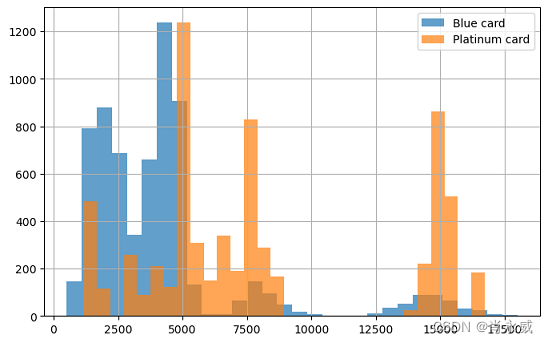
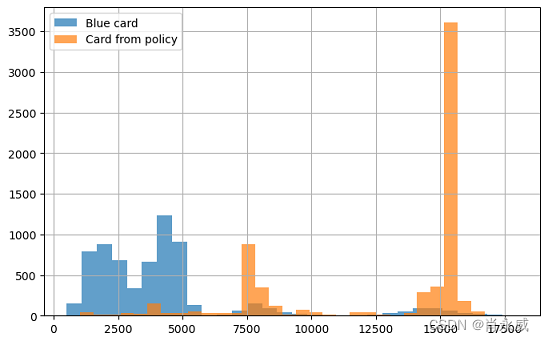
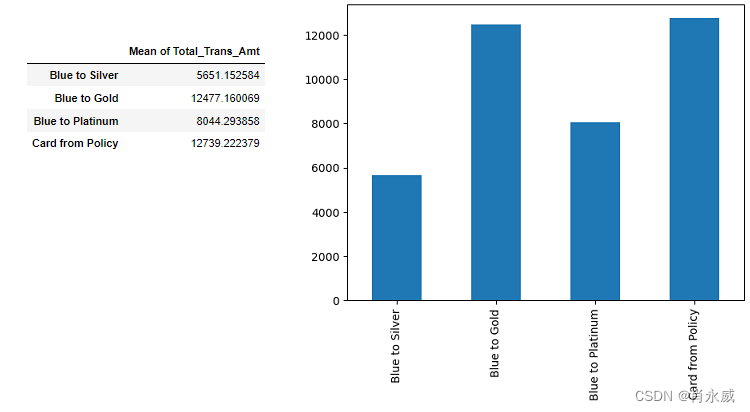
通过将所有蓝卡升级为银卡、金卡和白金卡,平均Total_Trans_Amt的估计值分别从4231增加到5651、12477和8044。这是一个有希望的改进。然而,我们可能想知道,将所有蓝色升级为金色是否是优化的解决方案。
- 将所有蓝卡升级为银卡
whatif_data= train_data[lambda df: df['Card_Category']=='Blue' ] out_orig=whatif_data[outcome] value_sliver=whatif_data['Card_Category'].map(lambda _:'Silver') out_silver=why.whatif(whatif_data,value_sliver,treatment='Card_Category') print('Selected customers:', len(whatif_data)) print(f'Mean {outcome} with Blue card:\t{out_orig.mean():.3f}' ) print(f'Mean {outcome} if Silver card:\t{out_silver.mean():.3f}' ) plt.figure(figsize=(8, 5), ) out_orig.hist(label='Blue card',bins=30,alpha=0.7) out_silver.hist(label='Silver card',bins=30,alpha=0.7) plt.legend()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 将所有蓝卡升级为金卡
whatif_data= train_data[lambda df: df['Card_Category']=='Blue' ] out_orig=whatif_data[outcome] value_gold=whatif_data['Card_Category'].map(lambda _:'Gold') out_gold=why.whatif(whatif_data,value_gold,treatment='Card_Category') print('Selected customers:', len(whatif_data)) print(f'Mean {outcome} with Blue card:\t{out_orig.mean():.3f}' ) print(f'Mean {outcome} if Gold card:\t{out_gold.mean():.3f}' ) plt.figure(figsize=(8, 5), ) out_orig.hist(label='Blue card',bins=30,alpha=0.7) out_gold.hist(label='Gold card',bins=30,alpha=0.7) plt.legend()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 将所有蓝卡升级为铂金卡
whatif_data= train_data[lambda df: df['Card_Category']=='Blue' ] out_orig=whatif_data[outcome] value_platinum=whatif_data['Card_Category'].map(lambda _:'Platinum') out_platinum=why.whatif(whatif_data,value_platinum,treatment='Card_Category') print('Selected customers:', len(whatif_data)) print(f'Mean {outcome} with Blue card:\t{out_orig.mean():.3f}' ) print(f'Mean {outcome} if Platinum card:\t{out_platinum.mean():.3f}' ) plt.figure(figsize=(8, 5), ) out_orig.hist(label='Blue card',bins=30,alpha=0.7) out_platinum.hist(label='Platinum card',bins=30,alpha=0.7) plt.legend()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.3.5. 策略解释器
YLean还提供了policy_interpreter()方法来搜索优化的解决方案。
pi=why.policy_interpreter(whatif_data, max_depth=2) # 获取策略解释器 plt.figure(figsize=(12, 8), ) pi.plot()- 1
- 2
- 3
- 4
- 5
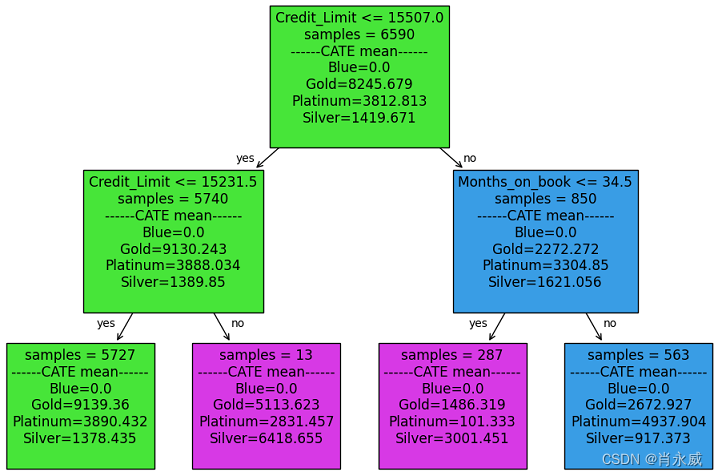
基于Credit_Limit和Month_on_book,树整数被分成四个节点。数值数组表示控制变量(蓝色与蓝色)和三种处理(金与蓝色、铂与蓝色、银与蓝色)的因果关系。高值越高表示性能越好。值越高意味着性能越好。查看第一个节点,策略树建议为“Credit_limit<=15231.5”的客户将蓝卡升级为金卡。
- 使用因果政策升级信用卡
whatif_data= train_data[lambda df: df['Card_Category']=='Blue' ] out_orig=whatif_data[outcome] value_from_policy=pi.decide(whatif_data) out_from_policy=why.whatif(whatif_data,value_from_policy,treatment='Card_Category') print('Selected customers:', len(whatif_data)) print(f'Mean of {outcome} with Blue card:\t{out_orig.mean():.3f}' ) print(f'Mean of {outcome} if apply policy:\t{out_from_policy.mean():.3f}' ) plt.figure(figsize=(8, 5), ) out_orig.hist(label='Blue card',bins=30,alpha=0.7) out_from_policy.hist(label='Card from policy',bins=30,alpha=0.7) plt.legend()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.3.6. 效果比较
whatif_summary=pd.Series({ 'Blue to Silver': out_silver.mean(), 'Blue to Gold': out_gold.mean(), 'Blue to Platinum': out_platinum.mean(), 'Card from Policy': out_from_policy.mean(), },name=f'Mean of {outcome}').to_frame() whatif_summary.plot(kind='bar',legend=False) whatif_summary- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.3.7. 结论
从比较结果来看,我们的策略获得了最高的交易金额!虽然该策略不考虑成本和风险,但它提供了定制策略,以帮助增加交易金额。
3.4. 因果发现的因果效应
3.4.1. 了解Why treatment=None
本节使用fit()方法的默认设置,这意味着应用因果发现来查找因果关系。
why=Why(random_state=123) why.fit(train_data,outcome) why.causal_effect(control=['M','College'])- 1
- 2
- 3
我们观察到,客户性别和教育水平是影响交易总额的重要因素。这两个特征相当合理。然而,在实践中很难将它们作为干预手段(不能改变客户的性别)。
3.4.2. 估计对训练集数据的因果影响
为了说明方法的使用,我们以“M”(性别)和“大学”(教育程度)作为治疗方法来估计因果效应。
why.causal_effect(control=['M','College'])- 1
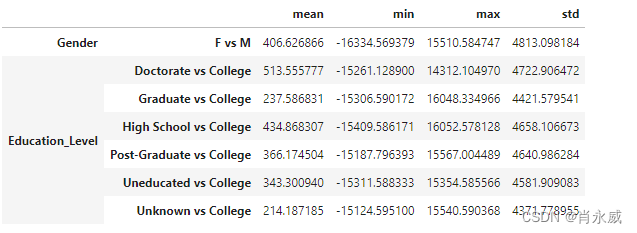
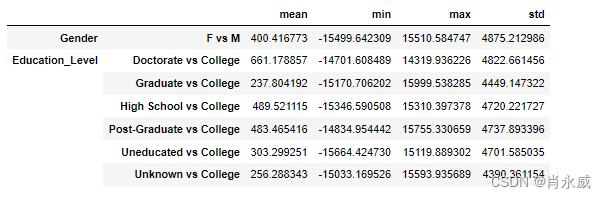
3.4.3. 估计对测试数据的因果影响
why.causal_effect(test_data, control=['M','College'])- 1
显示测试数据的因果效应估计。
3.4.4. 结论
由于性别和教育水平是属性特征,因此将其作为治疗手段是不现实的。本节介绍因果发现的含义。此外,来自列车数据和测试数据的估计结果非常相似,这反映了该方法的鲁棒性。
4. 总结
这是我的因果推断入门第一个实践,按开源给的案例学习研究,代码简单内涵丰富,思维也要由相关关系转换到因果关系。
参考:
[1]. 千年灬相思. Microsoft Visual C++ 14.0下载方法. 2022.06
[2]. 肖永威. 大数据因果推理与学习入门综合概述. CSDN博客. 2022.10
[3]. jinzhao. 如何通俗的理解小提琴图. 知乎. 2021.05
[4]. Why: 一个一体化的因果学习API -
相关阅读:
YIGSR-PEG-IR825 五肽YIGSR-聚乙二醇-近红外荧光染料IR825
查看libc版本
C#悬浮窗口 图像背景
Kafka系列之:NoBrokersAvailable和Failed to update metadata after 60.0 secs.
Fake权限验证小例子
java计算机毕业设计网上花店源码+系统+mysql数据库+LW文档+部署文件
springboot和spring对比
Java学习笔记6.1.1 字节流 - 数据字节输入流与数据字节输出流
Mycat
[附源码]计算机毕业设计JAVAjsp-在线排课系统
- 原文地址:https://blog.csdn.net/xiaoyw/article/details/127586560
