-
ES之倒排索引
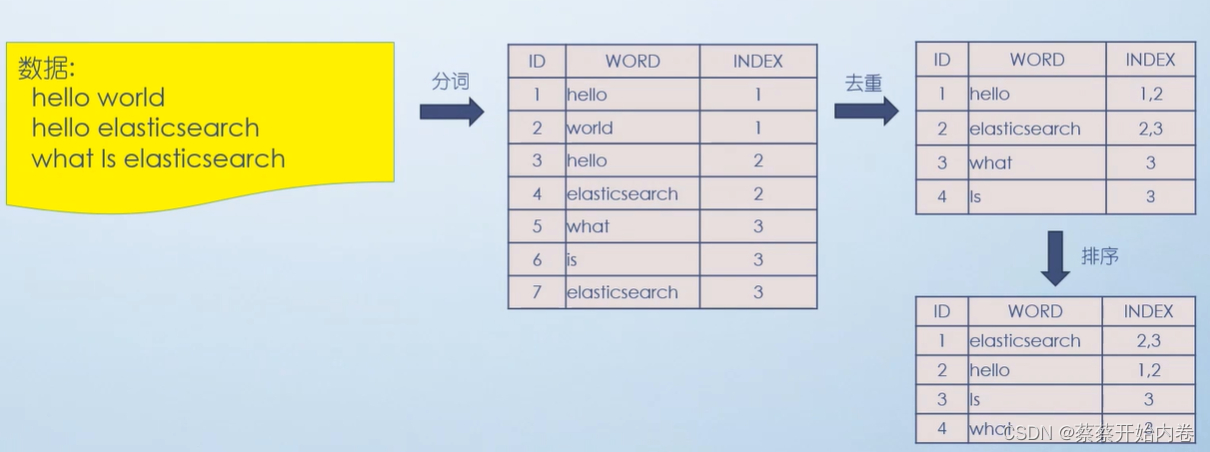
我们在这篇文章初识ElasticSearch,简单的了解了倒排索引的概念。
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这种建立索引的方式叫倒排索引。
当数据写入ES时,数据将会通过分词被切分为不同的term,ES将term与其对应的文档列表建立一种映射关系,这种结构就是倒排索引。如下图所示:
为了进一步提升索引的效率,
ES在term的基础上利用term的前缀或者后缀构建了term index, 用于对term本身进行索引,ES实际的索引结构如下图所示:
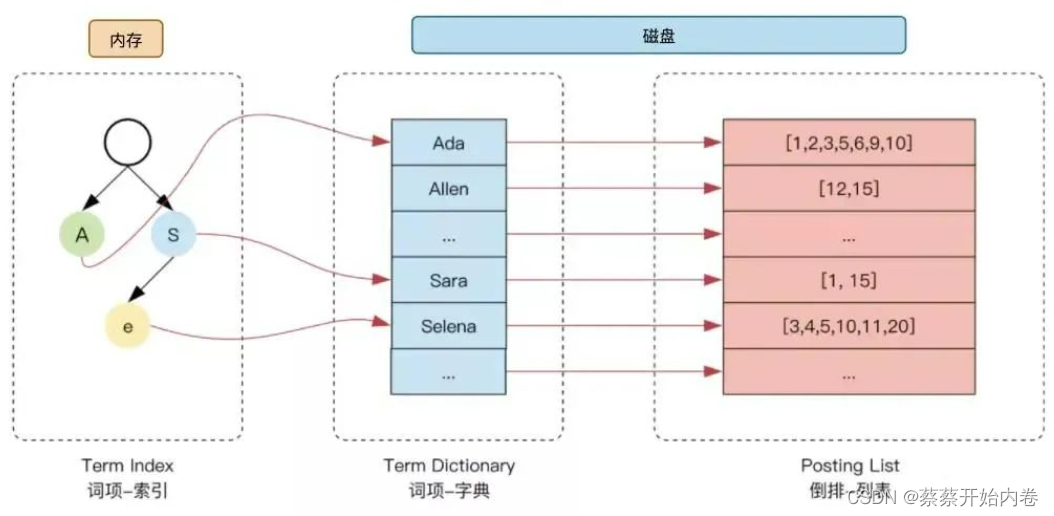
这样当我们去搜索某个关键词时,ES首先根据它的前缀或者后缀迅速缩小关键词的在term dictionary中的范围,大大减少了磁盘IO的次数。
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系- 常用字典数据结构
数据结构 优缺点 排序列表Array/List 使用二分法查找,不平衡 HashMap/TreeMap 性能高,内存消耗大,几乎是原始数据的三倍 Skip List 跳跃表 可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景(Skip List介绍) Trie 适合英文词典 如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存(数据结构之trie树) Double Array Trie 适合做中文词典,内存占用小,很多分词工具均采用此种算法(深入双数组Trie) Ternary Search Tree 三叉树,每一个node有3个节点,兼具省空间和查询快的优点(Ternary Search Tree) Finite State Transducers (FST) 一种有限状态转移机,Lucene 4有开源实现,并大量使用 - 倒排列表
(Posting List)-记录了单词对应的文档结合,由倒排索引项组成。
倒排索引项
(Posting):- 文档ID;
- 词频TF–该单词在文档中出现的次数,用于相关性评分;
- 位置(Position)-单词在文档中分词的位置。用于短语搜索(match phrase query);
- 偏移(Offset)-记录单词的开始结束位置,实现高亮显示;
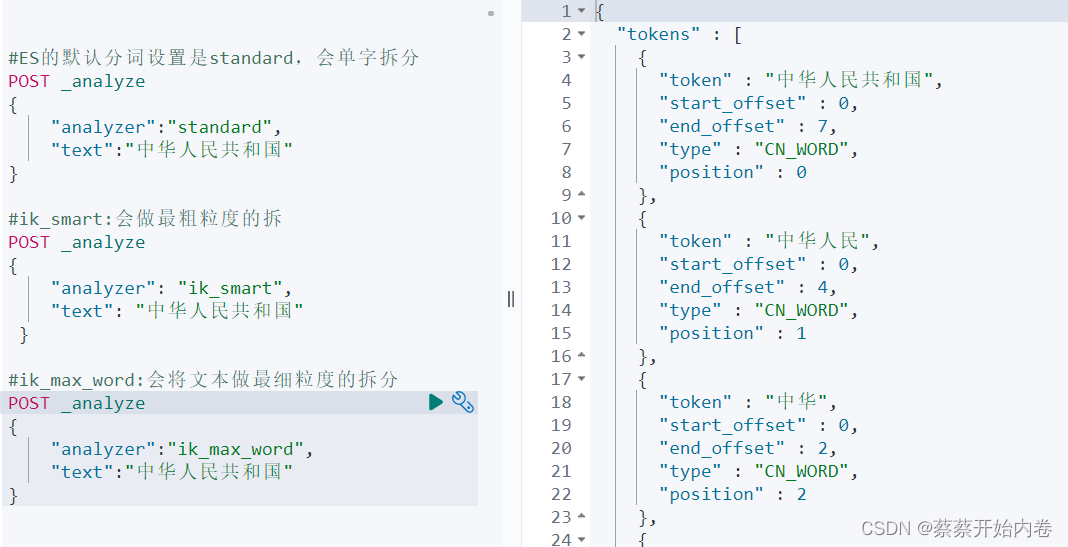
倒排索引不可变的好处- 不需要锁,提升并发能力,避免锁的问题;
- 数据不变,一直保存在os cache中,只要cache内存足够;
- filter cache一直驻留在内存,因为数据不变;
- 可以压缩,节省cpu和io开销;
Elasticsearch的JSON文档中的每个字段,都有自己的倒排索引。
可以指定对某些字段不做索引:- 优点︰节省存储空间
- 缺点: 字段无法被搜索
FST原理简析
FST有两个优点:- 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
- 查询速度快。O(len(str))的查询时间复杂度。
工具演示:fst
我们对“cat”、 “deep”、 “do”、 “dog” 、“dogs”这5个单词进行插入构建FST(注:必须已排序)。
过程- 插入
“cat”: 插入cat,每个字母形成一条边,其中t边指向终点。

- 插入
“deep”:与前一个单词“cat”进行最大前缀匹配,发现没有匹配则直接插入,P边指向终点。

- 插入
do: 与前一个单词“deep”进行最大前缀匹配,发现是d,则在d边后增加新边o,o边指向终点。

- 插入
“dog”:与前一个单词“do”进行最大前缀匹配,发现是do,则在o边后增加新边g,g边指向终点。
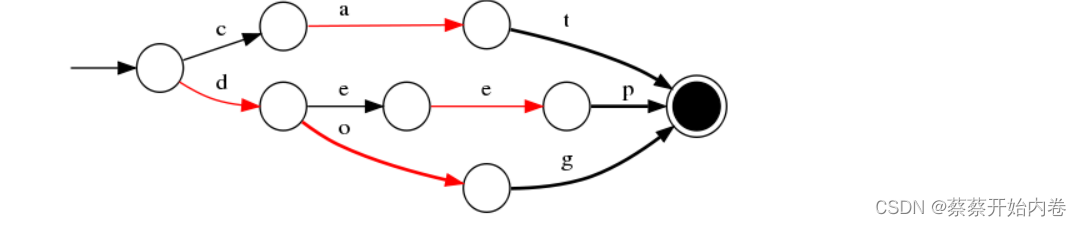
- 插入
“dogs”:与前一个单词“dog”进行最大前缀匹配,发现是dog,则在g后增加新边s,s边指向终点。
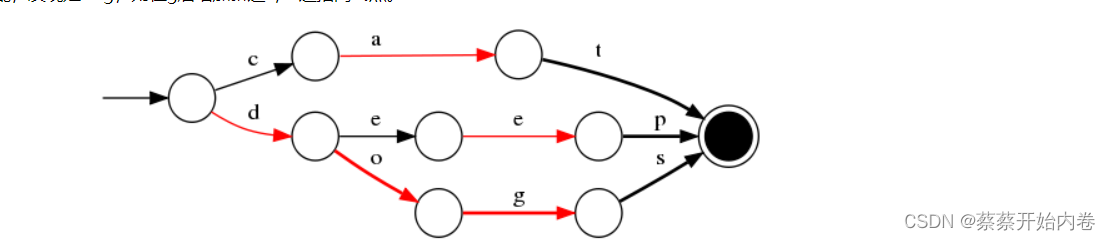
最终我们得到了如上一个有向无环图。利用该结构可以很方便的进行查询,如给定一个term “dog”,我们可以通过上述结构很方便的查询存不存在,甚至我们在构建过程中可以将单词与某一数字、单词进行关联,从而实现key-value的映射。
-
相关阅读:
Linux chmod命令使用介绍
如何在MATLAB中创建和操作矩阵?
c++ 类的多态以及虚函数
Java Web学习笔记6——盒子模型
Android 每日答题
线上如何优雅停机和调整线程池参数?
Docker简介与为什么要用Docker?
部署keepalived+LVS
vue-swiper组件化:解决异步请求数据时swiper过早初始化问题:
javaScript关于闭包的理解
- 原文地址:https://blog.csdn.net/weixin_42128977/article/details/127705236