-
spring探秘之ConfigurationClassPostProcessor(一):处理@ComponentScan注解
1. 回顾
BeanFactoryPostProcessor的执行回忆下
BeanFactoryPostProcessor的执行,调用链如下:- AnnotationConfigApplicationContext#AnnotationConfigApplicationContext(java.lang.String...)
- |-AbstractApplicationContext#refresh
- |-AbstractApplicationContext#invokeBeanFactoryPostProcessors
- |-PostProcessorRegistrationDelegate
- #invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory, List)
- 复制代码
在
PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory, List)中,会两次调用ConfigurationClassPostProcessor的方法:invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry):调用的是BeanDefinitionRegistryPostProcessor#postProcessBeanDefinitionRegistry方法;invokeBeanFactoryPostProcessors(registryProcessors, beanFactory):调用的是BeanFactoryPostProcessor#postProcessBeanFactory方法;
ConfigurationClassPostProcessor同时实现了BeanDefinitionRegistryPostProcessor与BeanFactoryPostProcessor,因此上述两个方法都会执行到,下面我们来看下ConfigurationClassPostProcessor的这两个方法:- /**
- * 先执行 postProcessBeanDefinitionRegistry(...)
- */
- @Override
- public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
- int registryId = System.identityHashCode(registry);
- if (this.registriesPostProcessed.contains(registryId)) {
- throw new IllegalStateException(...);
- }
- if (this.factoriesPostProcessed.contains(registryId)) {
- throw new IllegalStateException(...);
- }
- this.registriesPostProcessed.add(registryId);
- // 又调用了一个方法
- processConfigBeanDefinitions(registry);
- }
- /**
- * 执行完 postProcessBeanDefinitionRegistry(...) 后,再执行 postProcessBeanFactory(...)
- */
- @Override
- public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
- int factoryId = System.identityHashCode(beanFactory);
- if (this.factoriesPostProcessed.contains(factoryId)) {
- throw new IllegalStateException(
- "postProcessBeanFactory already called on this post-processor against " + beanFactory);
- }
- this.factoriesPostProcessed.add(factoryId);
- if (!this.registriesPostProcessed.contains(factoryId)) {
- // 如果 beanFactory 没有被处理,会再执行一次 processConfigBeanDefinitions 方法
- // 一般情况下,这里不会被执行到
- processConfigBeanDefinitions((BeanDefinitionRegistry) beanFactory);
- }
- // 增强配置类
- enhanceConfigurationClasses(beanFactory);
- // 添加处理 ImportAware 回调的 BeanPostProcessor,与本文主题关系不大,不分析
- beanFactory.addBeanPostProcessor(new ImportAwareBeanPostProcessor(beanFactory));
- }
- 复制代码
对上述两个方法,说明如下:
- 按照
PostProcessorRegistrationDelegate#invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory, List)的执行逻辑,会先执行postProcessBeanDefinitionRegistry(...),再执行postProcessBeanDefinitionRegistry(...) postProcessBeanDefinitionRegistry(...)主要是调用processConfigBeanDefinitions(...)方法;postProcessBeanFactory(...)会先判断当前beanFactory是否执行过processConfigBeanDefinitions(...)方法,如果没有,则会执行processConfigBeanDefinitions(...)方法,之后会enhanceConfigurationClasses(...)方法对配置类进行增强。
从以上分析来看,以上两个方法最终调用的是
processConfigBeanDefinitions(...)与enhanceConfigurationClasses(...),因此这两个方法是我们接下来分析的重点。2. spring 是如何处理
@ComponentScan注解的?2.1 demo 准备
在分析流程前,我们先准备调试demo:
首先准备一个类,上面标了
@ComponentScan注解:- @ComponentScan("org.springframework.learn.explore.demo02")
- public class BeanConfigs {
- }
- 复制代码
再准备两个
Bean:- @Component
- public class BeanObj1 {
- public BeanObj1() {
- System.out.println("调用beanObj1的构造方法");
- }
- @Override
- public String toString() {
- return "BeanObj1{}";
- }
- }
- @Component
- public class BeanObj2 {
- public BeanObj2() {
- System.out.println("调用beanObj2的构造方法");
- }
- @Override
- public String toString() {
- return "BeanObj2{}";
- }
- }
- 复制代码
最后是主类:
- public class Demo05Main {
- public static void main(String[] args) {
- ApplicationContext context = new AnnotationConfigApplicationContext(BeanConfigs.class);
- Object obj1 = context.getBean("beanObj1");
- Object obj2 = context.getBean("beanObj2");
- System.out.println("obj1:" + obj1);
- System.out.println("obj2:" + obj2);
- System.out.println(context.getBean("beanConfigs"));
- }
- }
- 复制代码
以上只是demo的主要部分,完整的demo见gitee/funcy.
运行,结果如下:
- 调用beanObj1的构造方法
- 调用beanObj2的构造方法
- obj1:BeanObj1{}
- obj2:BeanObj2{}
- org.springframework.learn.explore.demo05.BeanConfigs@13eb8acf
- 复制代码
接下来,就以这个demo为例,一步步进行分析。
2.2
ApplicationContext的构造方法:AnnotationConfigApplicationContext(Class)我们进入
AnnotationConfigApplicationContext的构造方法:- public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
- this();
- register(componentClasses);
- // spring 容器启动类
- refresh();
- }
- /**
- * this() 方法的调用内容
- */
- public AnnotationConfigApplicationContext() {
- // 对两个成员进行赋值
- // 如果调用的是`AnnotationConfigApplicationContext(Class)`方法 ,这两个属性不会用到
- // 如果调用的是`AnnotationConfigApplicationContext(String)`方法 ,这两个属性才会用到
- this.reader = new AnnotatedBeanDefinitionReader(this);
- this.scanner = new ClassPathBeanDefinitionScanner(this);
- }
- /**
- * register(...) 方法的内容
- */
- @Override
- public void register(Class<?>... componentClasses) {
- Assert.notEmpty(componentClasses, "At least one component class must be specified");
- this.reader.register(componentClasses);
- }
- 复制代码
AnnotationConfigApplicationContext的构造方法内容如下:this():调用无参构造方法,这个方法里主要是给reader与scanner成员变量赋值;register(componentClasses):注册component类到beanFactory中,调用的是reader.register(...)方法;refresh():spring的容器启动方法,就不分析。
执行完
register(componentClasses);前后,beanFactory内的BeanDefinitionMap内容如下:执行前:

执行后:

可以看到,
beanConfigs已经注册到beanDefinitionNames了。到这里,spring仅仅只是把
beanConfigs注册到了beanDefinitionNames(BeanConfigs由new AnnotationConfigApplicationContext(BeanConfigs.class)传入的),并没有扫描@ComponentSacn注解指定的包名,也就是org.springframework.learn.explore.demo05,那么包的扫描是在哪里进行的呢?答应就是ConfigurationClassPostProcessor中,我们继续往下看。2.3 处理配置类:
ConfigurationClassPostProcessor#processConfigBeanDefinitions根据开篇的分析,我们直接进入
ConfigurationClassPostProcessor#processConfigBeanDefinitions方法,调用链如下:- AnnotationConfigApplicationContext#AnnotationConfigApplicationContext(Class)
- |-AbstractApplicationContext#refresh
- |-AbstractApplicationContext#invokeBeanFactoryPostProcessors
- |-PostProcessorRegistrationDelegate
- #invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory, List)
- |-PostProcessorRegistrationDelegate#invokeBeanDefinitionRegistryPostProcessors
- |-ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry
- |-ConfigurationClassPostProcessor#processConfigBeanDefinitions
- 复制代码
方法内容如下:
- public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
- List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
- // 1. 获取所有BeanDefinition名称
- String[] candidateNames = registry.getBeanDefinitionNames();
- // 2. 循环candidateNames数组,标识Full与Lite
- for (String beanName : candidateNames) {
- BeanDefinition beanDef = registry.getBeanDefinition(beanName);
- // 判断当前BeanDefinition是已经处理过了,处理过了就不再处理了
- if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
- // 这里只是打了个log,省略
- ...
- }
- // 判断是否为配置类,这里分两种情况:
- // 1. 带有 @Configuration 注解且 proxyBeanMethods != false 的类,spring 称其为 Full 配置类
- // 2. 带有 @Configuration 注解且 proxyBeanMethods == false, 或带有 @Component、@ComponentScan、
- // @Import、@ImportResource、@Bean 其中之一注解的类,spring 称其为 Lite 配置类
- // 这里会对Full与Lite,进行标识
- else if (ConfigurationClassUtils
- .checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
- configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
- }
- }
- // 如果没有配置类,直接返回
- if (configCandidates.isEmpty()) {
- return;
- }
- // 省略无关的代码
- ...
- // 配置类解析器,这个类非常重要,下面就是用它来解析 对@Component、@Import等注解的
- ConfigurationClassParser parser = new ConfigurationClassParser(
- this.metadataReaderFactory, this.problemReporter, this.environment,
- this.resourceLoader, this.componentScanBeanNameGenerator, registry);
- // 两个结构,candidates:需要解析的配置类,alreadyParsed:完成解析的配置类
- Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
- Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
- do {
- // 3. 解析配置类,这个方法做了很多事,
- // 如:解析@Component,@PropertySources,@ComponentScans,@ImportResource等注解
- // 注:这里是一次性解析所有的candidates
- parser.parse(candidates);
- parser.validate();
- Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
- configClasses.removeAll(alreadyParsed);
- // 创建 reader,这个reader与前面ApplicationContext中的reader不是同一个
- if (this.reader == null) {
- this.reader = new ConfigurationClassBeanDefinitionReader(
- registry, this.sourceExtractor, this.resourceLoader, this.environment,
- this.importBeanNameGenerator, parser.getImportRegistry());
- }
- // 4. 处理本次解析的类
- // 就是把@Import引入的类、配置类中带@Bean的方法、@ImportResource引入的资源等转换成BeanDefinition
- this.reader.loadBeanDefinitions(configClasses);
- // 把configClasses加入到alreadyParsed
- alreadyParsed.addAll(configClasses);
- // 解析完成后,会把candidates的清空,接下来会把新添加的、未解析过的Full配置类添加到candidates中
- candidates.clear();
- // 5. 处理返回结果,如果新添加的类为 Full 配置类且未解析过,就把它添加到candidates中,在下次循环时再解析
- // 获得注册器里面BeanDefinition的数量 和 candidateNames进行比较
- // 如果大于的话,说明有新的BeanDefinition注册进来了
- if (registry.getBeanDefinitionCount() > candidateNames.length) {
- String[] newCandidateNames = registry.getBeanDefinitionNames();
- Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
- Set<String> alreadyParsedClasses = new HashSet<>();
- // 循环alreadyParsed。把类名加入到alreadyParsedClasses
- for (ConfigurationClass configurationClass : alreadyParsed) {
- alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
- }
- for (String candidateName : newCandidateNames) {
- if (!oldCandidateNames.contains(candidateName)) {
- BeanDefinition bd = registry.getBeanDefinition(candidateName);
- // 如果新加的类为配置类,且未解析过,就把它添加到candidates中,等待下次循环解析
- if (ConfigurationClassUtils
- .checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
- !alreadyParsedClasses.contains(bd.getBeanClassName())) {
- candidates.add(new BeanDefinitionHolder(bd, candidateName));
- }
- }
- }
- candidateNames = newCandidateNames;
- }
- }
- // 省略与本文流程无关的代码
- ...
- }
- 复制代码
正式分析以上方法前,先明确spring关于配置类的几个概念::
- 配置类:带有
@Configuration、@Component、@ComponentScan、@Import、@ImportResource等其中之一注解的类; Full配置类:带有@Configuration注解且proxyBeanMethods != false的类,spring称其为Full配置类;Lite配置类:带有@Configuration注解且proxyBeanMethods == false, 或带有@Component、@ComponentScan、@Import、@ImportResource等其中之一注解的类,spring称其为Lite配置类。
以上方法有点长,总结下来大概做了以下几件事:
-
获取所有
BeanDefinition的名称这步执行完成后,结果如下:
-
循环
candidateNames数组,标识配置类的类型为Full还是Lite,这一步所做的工作就是对配置类对应的BeanDefinition进行标识(至于标识后有什么作用,在后面分析@Configuration注解时会再分析),beanConfigs没有@Configuration注解,因此是Lite配置类。这一步得到的configCandidates如下:
-
解析配置类,即解析
@Component,@PropertySources,@ComponentScans,@ImportResource等注解标注的类,这个方法非常重要,下面会重点分析; -
处理本次解析的类,把@Import引入的类、配置类中带@Bean的方法、@ImportResource引入的资源等转换成BeanDefinition,加载到
BeanDefinitionMap中; -
处理返回结果,如果新添加的类为
Full配置类,且未解析过,就把它添加到candidates中,在下次循环时再解析。
以上方法的流程就这样了,接下来我们就来看看配置类的解析,也就是上述的第3步。
2.4 解析:
ConfigurationClassParser#parse(Set) - public void parse(Set<BeanDefinitionHolder> configCandidates) {
- // 循环传进来的配置类
- for (BeanDefinitionHolder holder : configCandidates) {
- BeanDefinition bd = holder.getBeanDefinition();
- try {
- // 如果获得BeanDefinition是AnnotatedBeanDefinition的实例
- // 前面得到的 beanConfigs就是AnnotatedBeanDefinition的实例,if里的方法会执行
- if (bd instanceof AnnotatedBeanDefinition) {
- parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
- }
- else if (bd instanceof AbstractBeanDefinition
- && ((AbstractBeanDefinition) bd).hasBeanClass()) {
- parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
- }
- else {
- parse(bd.getBeanClassName(), holder.getBeanName());
- }
- }
- catch (...) {
- ...
- }
- }
- this.deferredImportSelectorHandler.process();
- }
- /**
- * 调用parse进行解析
- */
- protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException {
- // ConfigurationClass:metadata与beanName的包装类
- processConfigurationClass(new ConfigurationClass(metadata, beanName));
- }
- 复制代码
前面传入的
BeanConfigs会被包装成AnnotatedGenericBeanDefinition,它是AnnotatedBeanDefinition的实例,然后就会调用ConfigurationClassParser#parse(String, String),这里其实并没做什么实质性的工作,继续进入processConfigurationClass(...)方法:- /**
- * 这个方法是在判断条件,保证配置类不重复解析
- * 实际干活的是 doProcessConfigurationClass(...)
- */
- protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
- // 判断是否需要跳过处理,针对于 @Conditional 注解,判断是否满足条件
- if (this.conditionEvaluator.shouldSkip(configClass.getMetadata() ,
- ConfigurationPhase.PARSE_CONFIGURATION)) {
- return;
- }
- ConfigurationClass existingClass = this.configurationClasses.get(configClass);
- // 判断是否解析过,解析过就不解析了,与解析内容关系不大,省略
- if (existingClass != null) {
- ...
- }
- // SourceClass 同前面的 ConfigurationClass 一样,也是对metadata与beanName的包装
- SourceClass sourceClass = asSourceClass(configClass);
- do {
- // doXxx(...) 方法才是真正干活的
- // 如果返回的内容不为空,下面会再次循环
- sourceClass = doProcessConfigurationClass(configClass, sourceClass);
- }
- while (sourceClass != null);
- this.configurationClasses.put(configClass, configClass);
- }
- 复制代码
这个方法先判断配置类是否满足执行条件,然后在
do-while循环中执行doProcessConfigurationClass(...),循环条件是doProcessConfigurationClass(...)返回的内容不为空,我们继续往下看。2.5 解析配置类:
ConfigurationClassParser#doProcessConfigurationClass- /**
- * 这个方法才是真正处理解析的方法
- */
- protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass,
- SourceClass sourceClass) throws IOException {
- // 1. 如果是 @Component 注解,递归处理内部类,本文不关注
- ...
- // 2. 处理@PropertySource注解,本文不关注
- ...
- // 3. 处理 @ComponentScan/@ComponentScans 注解
- // 3.1 获取配置类上的 @ComponentScan/@ComponentScans 注解
- Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
- sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
- // 如果没有打上ComponentScan,或者被@Condition条件跳过,就不再进入这个if
- if (!componentScans.isEmpty() && !this.conditionEvaluator
- .shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
- // 循环处理componentScans,也就是配置类上的所有@ComponentScan注解的内容
- for (AnnotationAttributes componentScan : componentScans) {
- // 3.2 componentScanParser.parse(...):具体解析componentScan的操作
- // componentScan就是@ComponentScan上的具体内容,
- // sourceClass.getMetadata().getClassName()就是配置类的名称
- Set<BeanDefinitionHolder> scannedBeanDefinitions = this.componentScanParser
- .parse(componentScan, sourceClass.getMetadata().getClassName());
- // 3.3 循环得到的 BeanDefinition,如果对应的类是配置类,递归调用parse(...)方法
- // componentScan引入的类可能有被@Bean标记的方法,或者有@ComponentScan注解
- for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
- BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
- if (bdCand == null) {
- bdCand = holder.getBeanDefinition();
- }
- // 判断BeanDefinition对应的类是否为配置类
- if (ConfigurationClassUtils
- .checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
- // 对得到的类,调用parse(...)方法,再次进行解析
- parse(bdCand.getBeanClassName(), holder.getBeanName());
- }
- }
- }
- }
- // 4. 处理@Import注解,本文不关注
- ...
- // 5. 处理@ImportResource注解,本文不关注
- ...
- // 6. 处理@Bean的注解,,本文不关注
- ...
- // 7. 返回配置类的父类,会在 processConfigurationClass(...) 方法的下一次循环时解析
- // sourceClass.getMetadata()就是配置类
- if (sourceClass.getMetadata().hasSuperClass()) {
- String superclass = sourceClass.getMetadata().getSuperClassName();
- if (superclass != null && !superclass.startsWith("java") &&
- !this.knownSuperclasses.containsKey(superclass)) {
- this.knownSuperclasses.put(superclass, configClass);
- return sourceClass.getSuperClass();
- }
- }
- return null;
- }
- /**
- * 这个方法会再次调用processConfigurationClass(...)方法进行解析
- * 目的是,新引入的类也有可能有被@Bean标记的方法,或者有ComponentScan等注解
- */
- protected final void parse(@Nullable String className, String beanName) throws IOException {
- Assert.notNull(className, "No bean class name for configuration class bean definition");
- MetadataReader reader = this.metadataReaderFactory.getMetadataReader(className);
- // 又调回 processConfigurationClass(...) 方法了
- processConfigurationClass(new ConfigurationClass(reader, beanName));
- }
- 复制代码
ConfigurationClassParser#doProcessConfigurationClass这个方法就是对@PropertySource、@ComponentScan、@Import、@ImportResource、@Bean等注解,本文我们仅关注@ComponentScan注解的处理,流程如下:- 获取配置类上的
@ComponentScan/@ComponentScans注解; componentScanParser.parse(...):具体解析componentScan的操作,后面会重点分析;- 循环得到的
BeanDefinition,如果对应的类是配置类,递归调用parse(...)方法,如果扫描到的类包含@Import、@Bean、@ComponentScan等注解,递归调用parse(...)方法时会被解析到。
上面的操作流程在代码中已经注释得很清楚了,就不多说了,我们直接来看
@ComponentScan的解析操作.2.6 真正解析的地方:
ComponentScanAnnotationParser#parse@ComponentScan的解析在ComponentScanAnnotationParser#parse方法中,代码如下:- public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
- // 1. 定义一个扫描器,用来扫描包
- ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
- componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
- // 2. 判断是否重写了默认的命名规则
- Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
- boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
- scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
- BeanUtils.instantiateClass(generatorClass));
- // 3. 解析 @ComponentScan 注解的属性
- // 3.1 处理 @ComponentScan 的 scopedProxy 属性
- ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
- if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
- scanner.setScopedProxyMode(scopedProxyMode);
- }
- else {
- Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
- scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
- }
- // 3.2 处理 @ComponentScan 的 resourcePattern 属性
- scanner.setResourcePattern(componentScan.getString("resourcePattern"));
- // 3.3 处理 @ComponentScan 的 includeFilters 属性
- // addIncludeFilter addExcludeFilter,最终是往List<TypeFilter>里面填充数据
- for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
- for (TypeFilter typeFilter : typeFiltersFor(filter)) {
- scanner.addIncludeFilter(typeFilter);
- }
- }
- // 3.4 处理 @ComponentScan 的 excludeFilters 属性
- for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
- for (TypeFilter typeFilter : typeFiltersFor(filter)) {
- scanner.addExcludeFilter(typeFilter);
- }
- }
- boolean lazyInit = componentScan.getBoolean("lazyInit");
- if (lazyInit) {
- scanner.getBeanDefinitionDefaults().setLazyInit(true);
- }
- Set<String> basePackages = new LinkedHashSet<>();
- // 3.5. @ComponentScan 指定了 basePackages 属性,这个属性的类型是String
- String[] basePackagesArray = componentScan.getStringArray("basePackages");
- for (String pkg : basePackagesArray) {
- String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
- ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
- Collections.addAll(basePackages, tokenized);
- }
- // 3.6. @ComponentScan 指定了 basePackageClasses, 这个属性的类型是Class,
- // 即只要是与这几个类同级的,或者在这几个类下级的都可以被扫描到
- for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
- basePackages.add(ClassUtils.getPackageName(clazz));
- }
- // 3.7 以上都没有指定,默认会把配置类所在的包名作为扫描路径
- if (basePackages.isEmpty()) {
- basePackages.add(ClassUtils.getPackageName(declaringClass));
- }
- // 3.8 添加排除规则,这里就把注册类自身当作排除规则,真正执行匹配的时候,会把自身给排除
- scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
- @Override
- protected boolean matchClassName(String className) {
- return declaringClass.equals(className);
- }
- });
- // 4. 到这里,才开始扫描 @ComponentScan 指定的包
- // 扫描完成后,对符合条件的类,spring会将其添加到beanFactory的BeanDefinitionMap中
- return scanner.doScan(StringUtils.toStringArray(basePackages));
- }
- 复制代码
以上方法执行流程如下:
- 定义一个扫描器,用来扫描包
- 判断是否重写了默认的命名规则
- 解析
@ComponentScan注解的属性,完善扫描器- 处理
@ComponentScan的scopedProxy属性 - 处理
@ComponentScan的resourcePattern属性 - 处理
@ComponentScan的includeFilters属性 - 处理
@ComponentScan的excludeFilters属性 - 处理
@ComponentScan的basePackages属性,这个属性的类型是String - 处理
@ComponentScan的basePackageClasses属性, 这个属性的类型是Class - 如果没有指定扫包规则,默认会把配置类所在的包名作为扫描路径
- 添加排除规则,这里就把注册类自身当作排除规则,真正执行匹配的时候,会把自身给排除
- 处理
- 调用
ClassPathBeanDefinitionScanner#doScan完成扫描
最终,调用了
ClassPathBeanDefinitionScanner#doScan方法来完成包的描述,这个方法我们在spring启动流程之包的扫描流程已经详细分析过了,这里就不再分析了。让我们回到
ConfigurationClassPostProcessor#processConfigBeanDefinitions方法:- public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
- ...
- parser.parse(candidates);
- ....
- }
- 复制代码
执行前:

执行后:
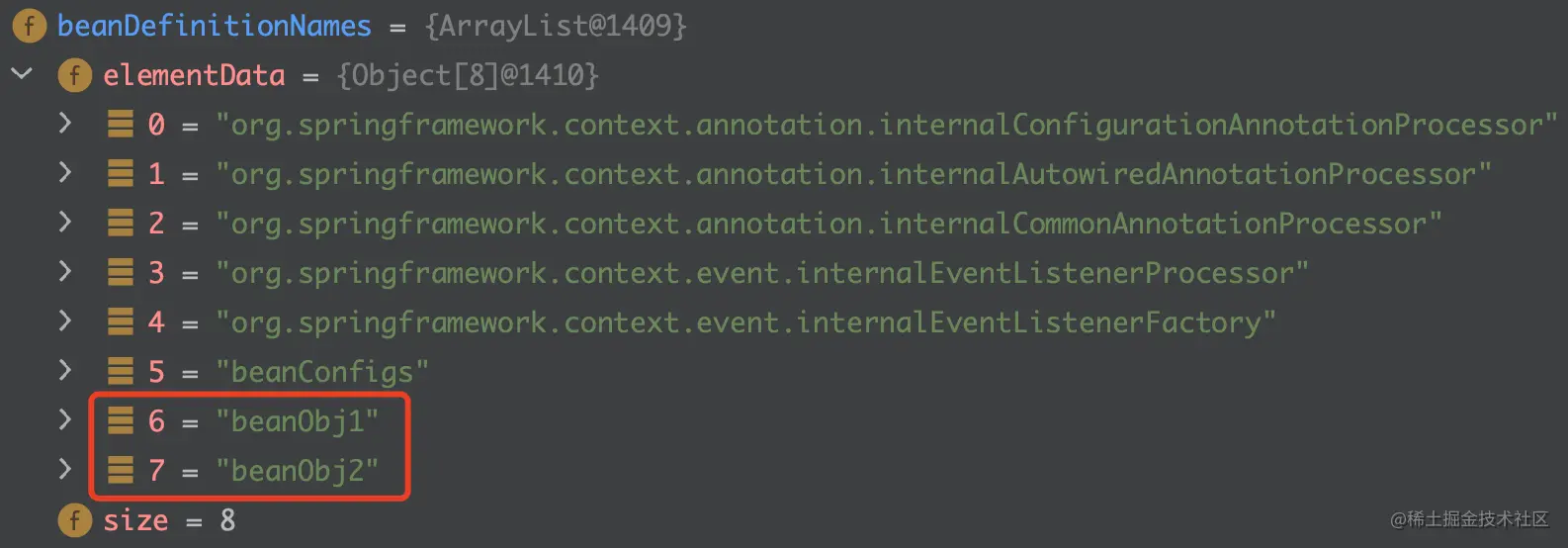
可以看到,
BeanObj1、BeanObj2已经放入了BeanFactory的BeanDefinitionMap中了 。2.7 总结
spring处理
@ComponentScan的流程到这里就结束了,解析流程位于ConfigurationClassParser#doProcessConfigurationClass方法,这个方法除了解析@ComponentScan,还会解析@Bean、@Import等注解,本文只分析@ComponentScan的处理流程,对以上流程总结如下:- 获取配置类上的
@ComponentScan/@ComponentScans注解 - 进行解析
@ComponentScan的操作,解析时,先定义了一个描述器,然后根据@ComponentScan的属性,对描述器器进行属性填充,处理完这些之后,就开始进行包扫描操作; - 遍历扫描得到的类,如果其为配置类,会通过调用
parse(...)方法再一次调用ConfigurationClassParser#doProcessConfigurationClass进行解析,这一点非常重要,这就保证了扫描得到的类中的@Bean、@Import、@ComponentScan等注解得到解析。
好了,本文就先到这里了,接下来几篇文章会继续分析
ConfigurationClassPostProcessor对其他注解的处理。 -
相关阅读:
LeetCode hot100-61-G
关于App不同方式更新的测试点归纳
java 闭包的用途是什么
Windows下网络编程及多线程模型
Python sort 自定义函数排序
Cuda cmake支持C++17
rollback-only异常令我对事务有了新的认识
Flink CDC引起的Mysql元数据锁
c++ VS2019中使用Log4cplus打印日志最新介绍、详细编译过程及使用
移动App安全检测的必要性,app安全测试报告的编写注意事项
- 原文地址:https://blog.csdn.net/BASK2311/article/details/127699930
