-
基于Python+Nodejs+MONGODB的电影推荐网站
2 用途
2.1功能
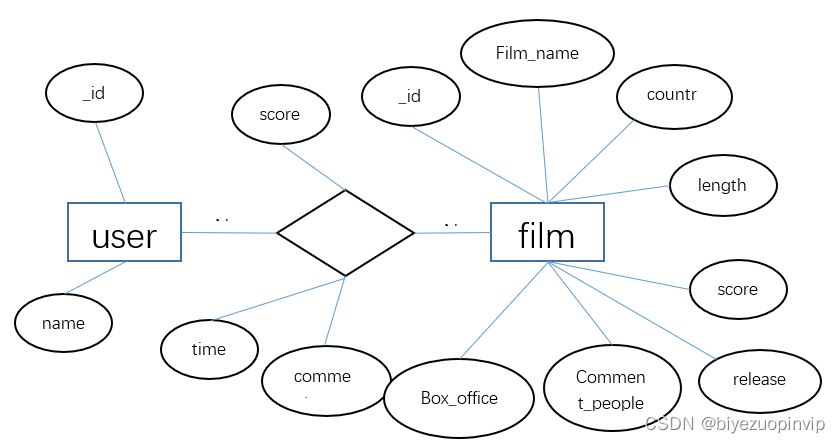
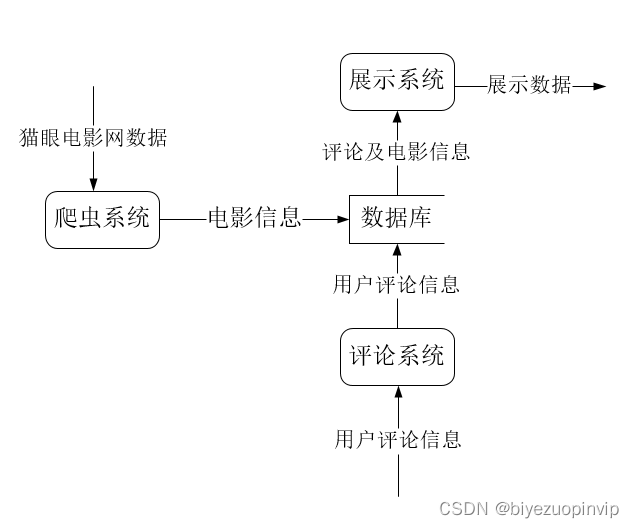
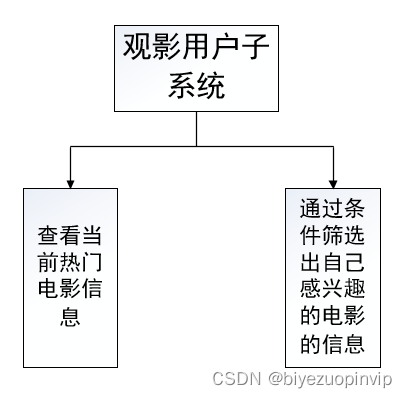
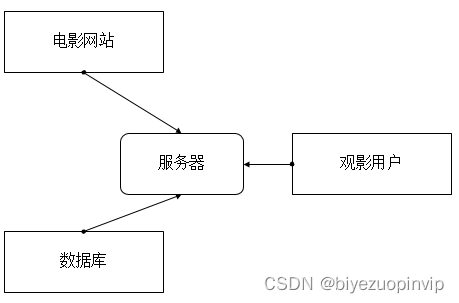
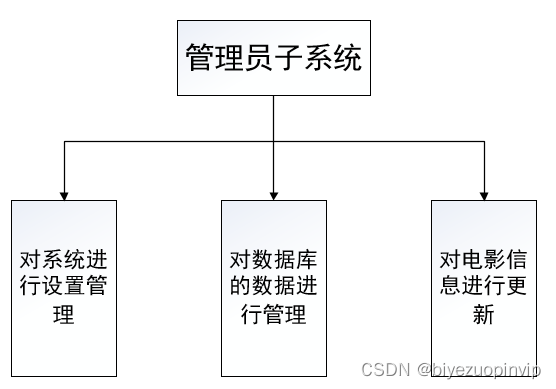
本软件是面向小型电影数据分析电影爱好者,及推荐电影所做成的。主要包括:数据爬取、数据维护、电影信息展示、电影推荐等模块。
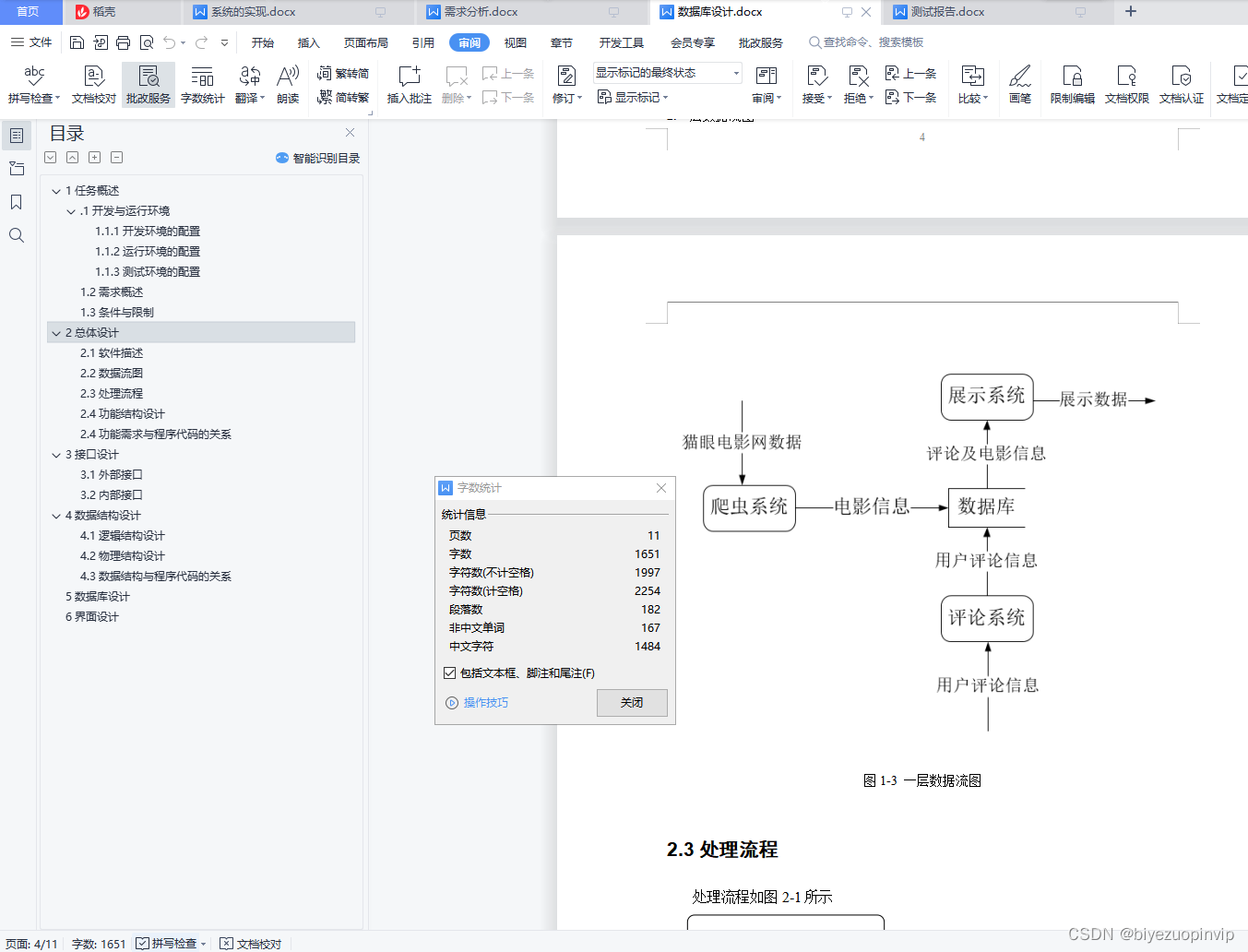
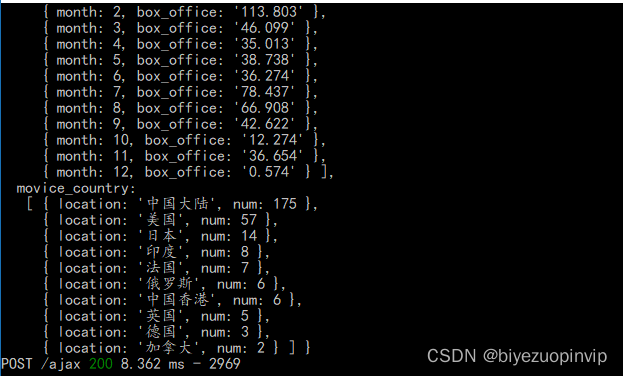
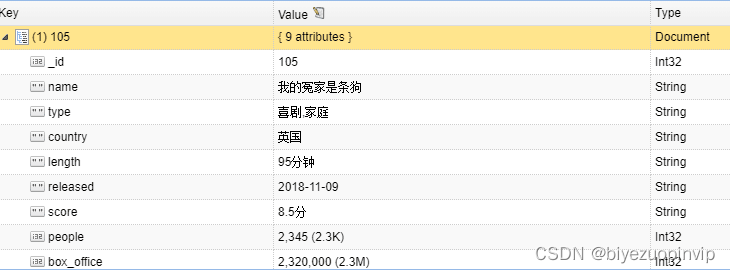
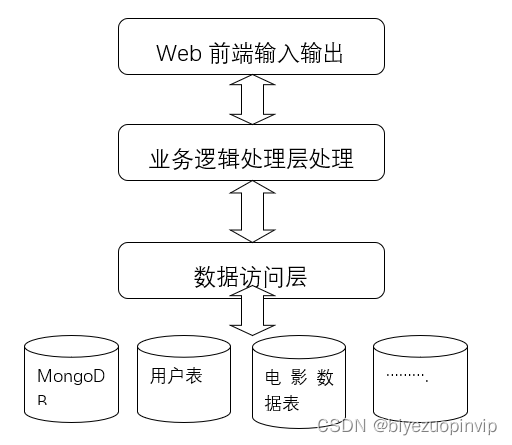
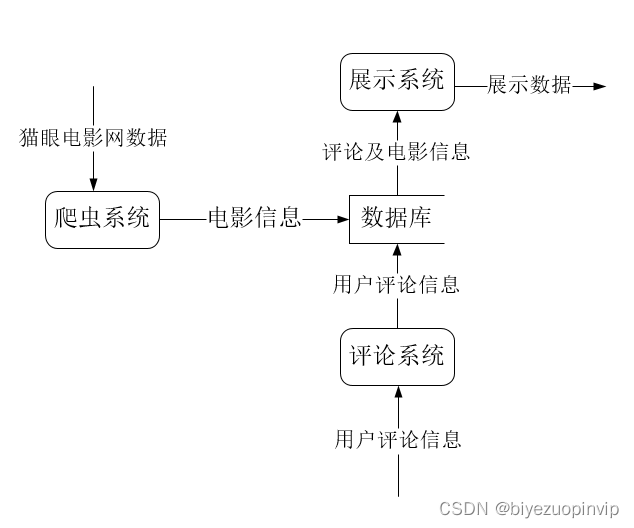
数据爬取业务模块主要包括从猫眼电影数据进行爬取,并且将其存入数据库中。该业务获取的基础数据是整个系统的根基,关系到后续功能的实现。
数据维护主要是对其中的数据进行管理,能够保证数据能个得到及时且有效的管理。也就是进行相应的修改、添加、删除、查找等操作。
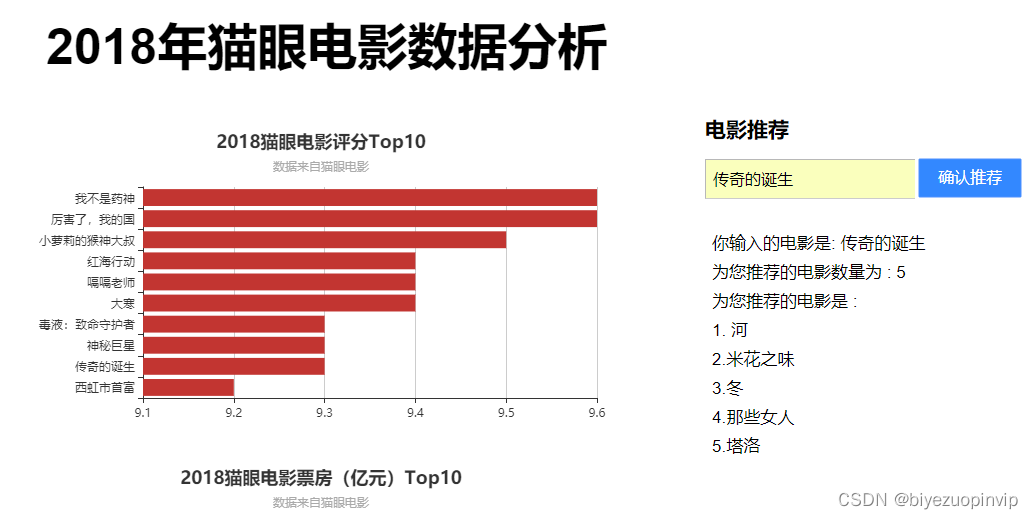
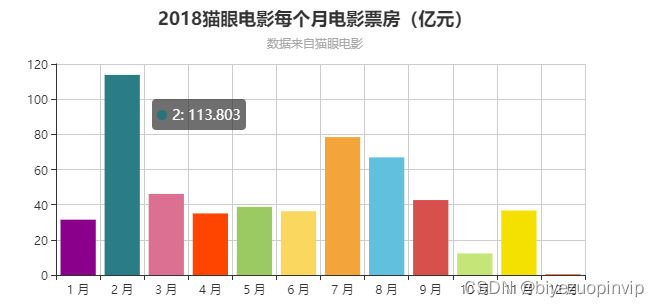
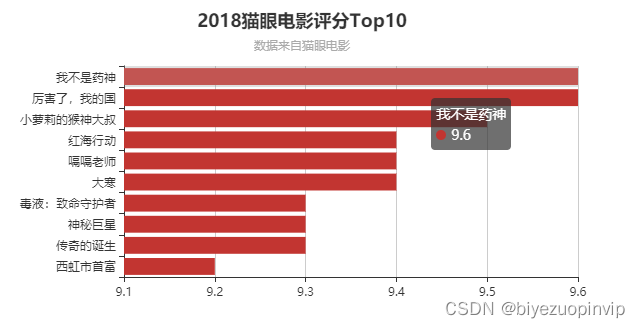
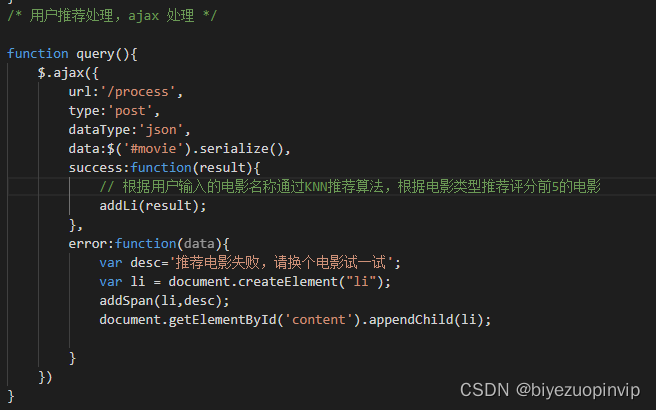
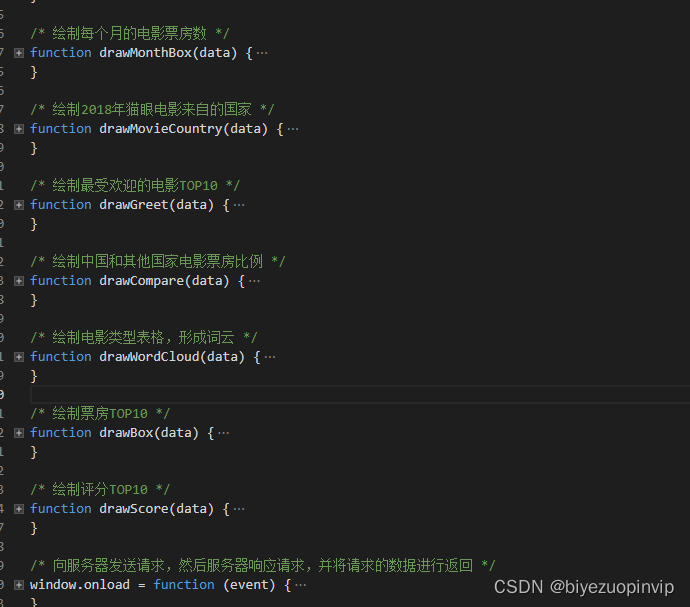
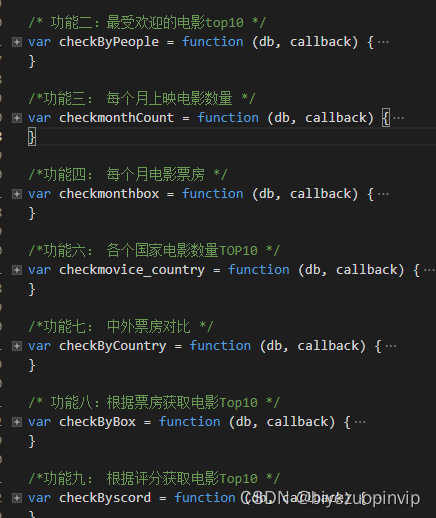
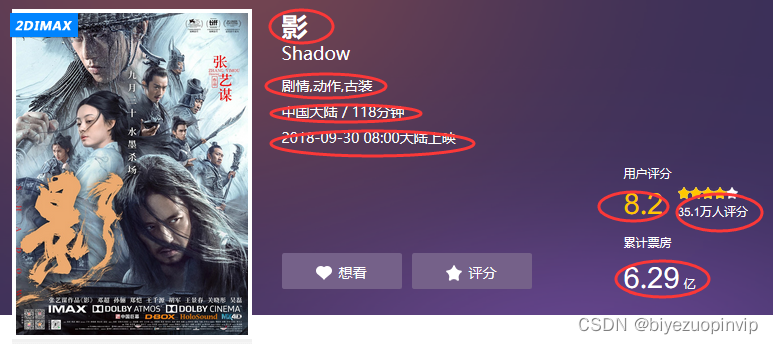
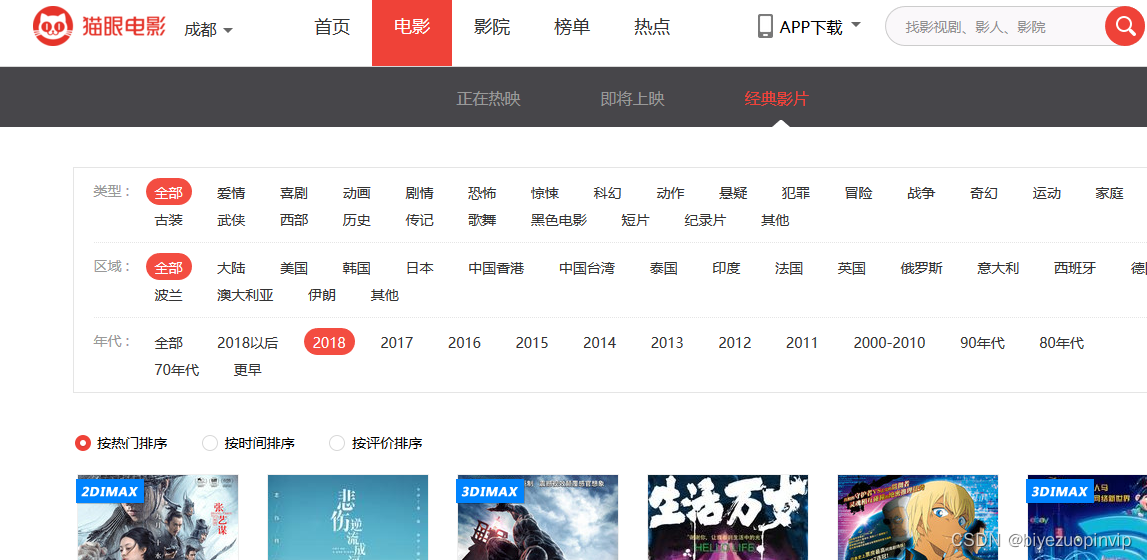
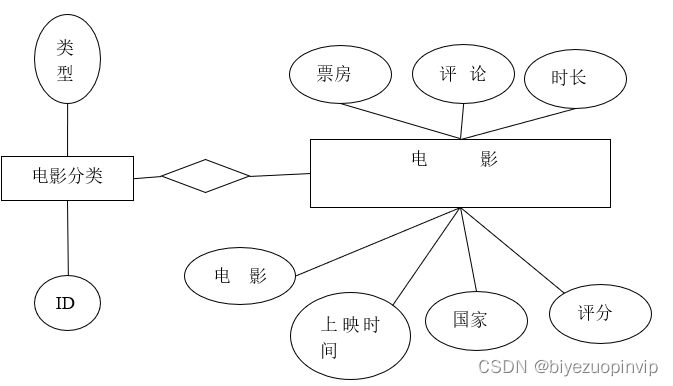
电影信息展示主要是按照用户的需求对所筛选出的电影信息进行对于的展示,方便用户进行阅读比如电影评分TOP10、电影票房TOP10、每月电影上映数量、每月电影票房、电影来源、最受欢迎电影TOP10、中外电影票房对比以及上映电影类型等信息。
电影评分TOP10主要是分析从猫眼电影爬取2018这一年上映的所有的电影进行对比,从中评出用户评分最高的10部电影;每月电影票房,就是将电影按照上映的时间进行分类,一共分为12个月,并将每个月上映的电影票房进行累加,然后横向进行比较电影。上映电影类型信息是将每一部电影类型进行统计,统计出2018年电影类型最多的那一种类型,也进一步反映市场对某一类型电影票房的反响。
2.2性能
2.2.1 精度
本软件基于图表进行展示,用户很容易就能看出各部电影的特点,几乎不用什么操作,我们对各个用户请求进行了封装,默认显示。所以用户打开系统就可以看到系统要展现给用户的结果。
2.2.2 时间特性
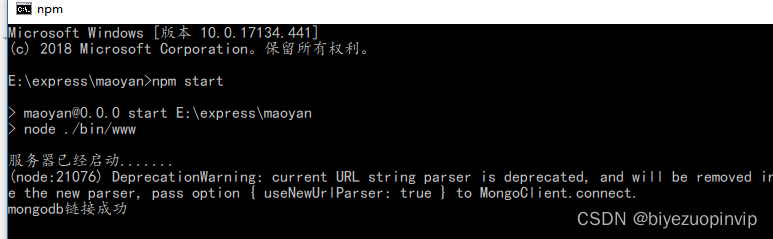
本软件使用的是面向对象的数据库,也是目前最流行的数据库mongoDB数据库,它是介于关系数据库和非关系数据库之间,查询功能非常强大。对用户的请求能够很快的进行响应,更新处理时间、数据传输、转换时间、计算时间都非常迅速。
2.2.3 灵活性
本软件各个模块的操作非常简单,灵便。在数据爬取、数据维护、数据展示各个模块中,相关的信息可以快速集中的输入以及进行查询,而各个模块间的转换和信息的增删改的操作,都可以通过系统管理员进行相关的操作。2.3 安全保密
本软件在安全保密上设置的比较细致,因为该系统的数据库比较重要,以及数据库的登录进行修改、增加、删除等数据库操作的时候,需要系统管理员提供正确的密码及用户名才可以进行操作,本文转载自http://www.biyezuopin.vip/onews.asp?id=17000因此可以防止数据库里的信息被丢失。保证了数据库的安全性。
3 运行环境
3.1硬件平台
运行本人家所要求的硬设备的最小配置:
A.Intel i5 处理器、内存1G;
B.I/O设备;显示器、鼠标、键盘;
3.2支持软件
说明为运行本软件所需要的支持软件,如
A.操作系统:windows7及以上版本;
B.支撑框架:服务器使用的是基于Nodejs 的Express服务器搭建框架,python3.0、java8.0 等环境;
C.数据库:Mongodb4.0,Npm3.10 模块管理;
D.开发工具:pycharm,vscode;
3.3 数据库
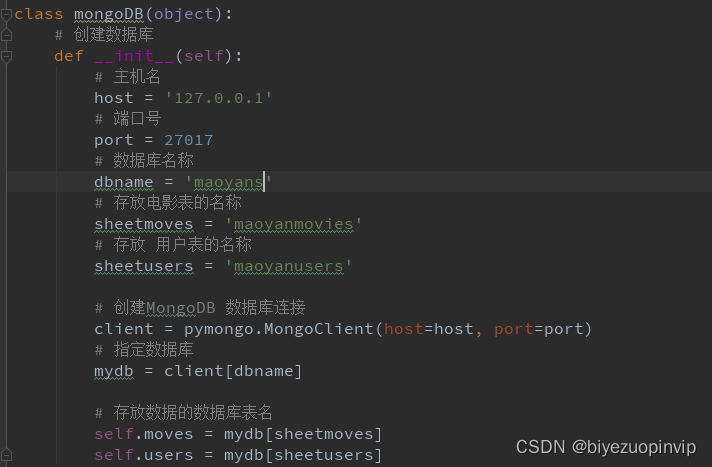
为支持本软件的运行所需要的数据库:MongoDB4.0# ------------------------------------------------------------------------------- # Name: testMogodb # Description: mogodb 压力测试 # # # Author: Admin # Date: 2018/12/13 # ------------------------------------------------------------------------------- import datetime import mongodb import multiprocessing import time from pymongo import MongoReplicaSetClient class testmongoDB: def __init__(self, dbname, collection): # 连接数据库 self.db = mongodb.mongoDB(dbname, collection) # 时间记录器 def func_time(self, func): def _wrapper(*args, **kwargs): start = time.time() func(*args, **kwargs) print(func._name_ + 'run:' + time.time() - start) return _wrapper # @func_time def insert(self, num): start = time.time() for x in range(num): post = { '_id': str(x), 'name': str(x) + '斗罗大陆', 'type': '动漫', 'country': '中国', 'lenght': '180分钟', 'socre': '8分', 'data': datetime.datetime.utcnow() } self.db.process_item(post, True) print("插入成功:%s"% post) usertime = time.time() - start print("数据插入结束,用时:%s"%usertime) # 查询测试 def query(self, num): get = self.db.device for i in range(num): get.find_one({"scanid": "010000138101010000009aaaaa"}) # @func_time def main(self, process_num, num): pool = multiprocessing.Pool(processes=process_num) for i in range(num): pool.apply_async(self.query(num)) pool.close() pool.join() print("sub_process(es) done.") # 主函数运行开始的地方 if __name__ == '__main__': dbname = 'maoyan' collectionName = 'maoyanusers' test = testmongoDB(dbname, collectionName) # 设定循环5000次 num = 5000 test.insert(num) # test.main(800, 500)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77

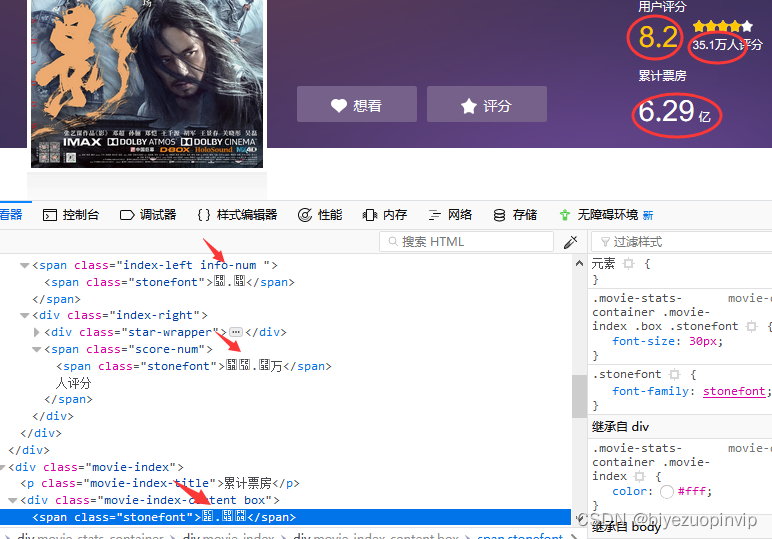
-
相关阅读:
OSPF路由策略引入
算法 | 分支限界法和回溯法的搜索策略&动态规划特性&贪心算法特性
12个yyds的低代码开源项目,一天开发一个系统!
Linux ARM平台开发系列讲解(调试篇) 1.6.4 NVIDIA AGX Xavier以太网MAC TO MAC模式
【pytorch】torchvion.transforms.RandomResizedCrop
Java学习笔记:高级数据过滤
深度学习——(7)分类任务
MongoDB 6.1 及以上版本使用配置文件的方式启动报错 Unrecognized option: storage.journal.enabled
C++ 函数
C++11新特性 auto
- 原文地址:https://blog.csdn.net/newlw/article/details/127700276
