-
自底向上语法分析(bottom-up parsing)
自底向上语法分析(bottom-up parsing)
在自顶向下语法分析(top-down parsing) 中介绍了一种自顶向上语法分析法——LL(1)分析法,但它存在两个问题:
- 能够分析的文法有限;
- 很多时候需要进行文法转换。
为此,将介绍一种使用更加广泛的自底向上语法分析法——LR分析法。这也是当前实际运用最广泛的一种语法分析方法。
本文主要是对 哈工大编译原理课件 的学习和总结。
自底向上分析概述
自底向上语法分析是从分析树的底部(叶子节点)向顶部根节点方向构造分析树,也即是将输入串归约为文法开始符号的过程。自顶向下的语法分析是采用最左推导方式,而自底向上的语法分析是采用最左归约方式,其实就是反向构造最右推导 。
自顶向上语法分析的通用框架是:移入-规约分析(Shift-Reduce Parsing)。下面通过一个例子来介绍移入-规约分析的算法思想。

移动-规约分析法的大致过程为:
- 对输入串的一次从左到右扫描过程中,将零个或多个输入符号移入到栈的顶端,直到它可以对栈顶的一个文法符号串 β 进行归约为止。
- 然后,将 β 归约为某个产生式的左部(使用左部的非终结符替换 β )。
- 不断地重复上面的循环,直到它检测到一个语法错误或者栈中包含了开始符号且输入缓冲区为空为止。
移入-规约语法分析过程中的四个动作:
- 移入:将下一个输入符号移入到栈顶。
- 归约:被归约的符号串的右端必然处于栈顶。语法分析器在栈中确定这个串的左端,并决定用哪个非终结符来替换这个串。
- 接收:语法分析过程成功完成。
- 报错:发现一个语法错误,并调用错误恢复子例程。

如何正确地识别句柄是移动-规约分析法的关键问题。
LR分析概述
LR文法是最大的、可以构造出相应移入-归约语法分析器的文法类。
- L:输入串进行从左(Left)到右的扫描;
- R:反向(Reverse)构造出一个最右推导序列;
LR(k)分析表示需要向前查看 k 个输入符号的LR分析。k = 0 和 k = 1 这两种情况具有实践意义。当(k)省略时,表示k =1。
自底向上分析的关键问题是如何正确识别句柄,句柄是逐步形成的,LR分析法用“状态”表示句柄识别的进展程度。LR分析法的总体结构为:
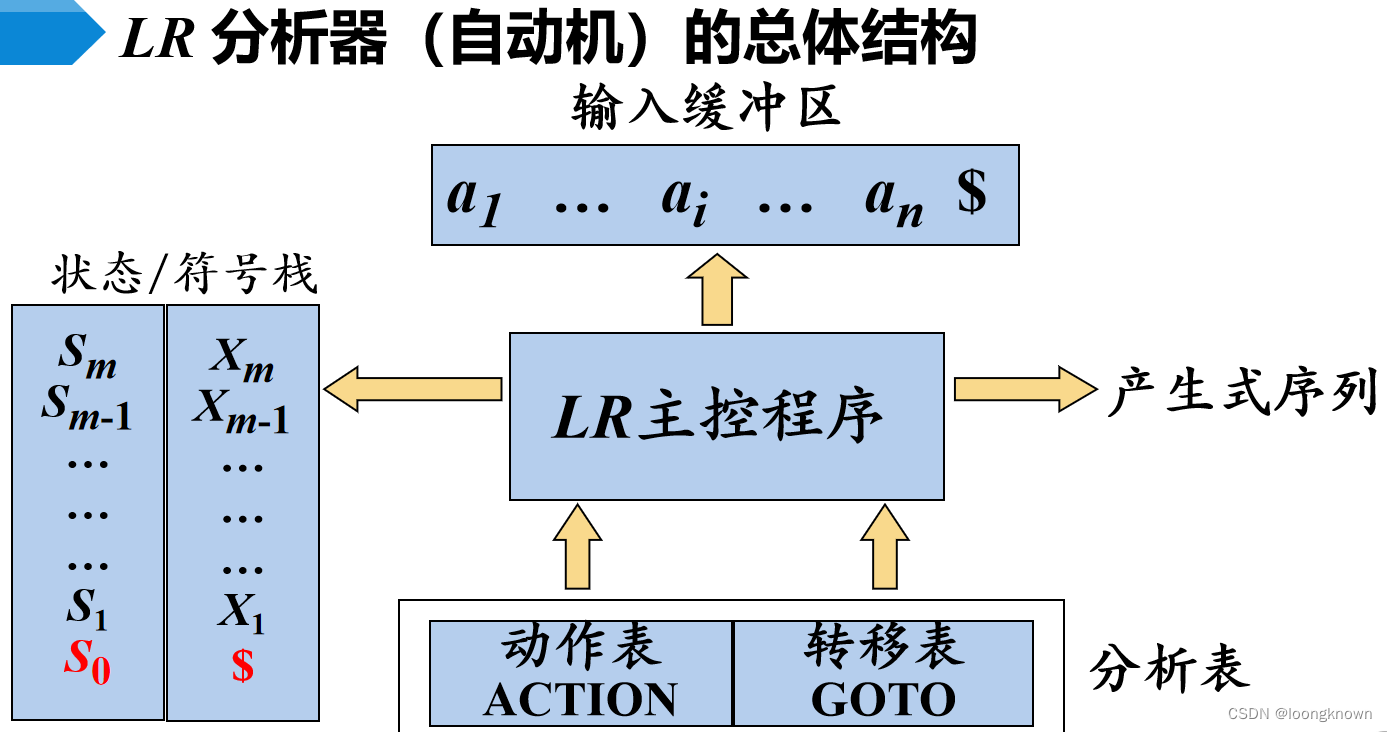
LR分析器使用自动机的机制,通过读头读入输入串,根据输入串查询动作表和转移表(统称LR分析表),将符号和状态压栈或出栈的过程完成语法分析。动作表和转移表是LR分析法的关键。LR分析算法如下:
- 输入:串w和LR分析表,该表描述了文法G的ACTION函数和GOTO函数。
- 输出:如果w在L(G)中,则输出w的自底向上语法分析过程中的归约步骤,否则给出一个错误指示。
- 方法:初始时,语法分析器栈中的内容为初始状态 s 0 s_0 s0 ,输入缓冲区中的内容为w$。然后,语法分析器执行下面的程序:
令a为w$的第一个符号; while(1) { /* 永远重复*/ 令s是栈顶的状态; if ( ACTION[s,a] = st ) { 将t压入栈中; 令a为下一个输入符号; } else if ( ACTION[s,a] = 归约A → β ) { 从栈中弹出│β│个符号; 将GOTO[t,A]压入栈中; 输出产生式 A → β ; } else if ( ACTION[s,a] = 接受 ) break; /* 语法分析完成*/ else调用错误恢复例程; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
LR分析算法的关键过程:



下面通过一个例子介绍LR分析法的工作过程:

对于上面的文法和LR分析表,输入串 bab ,LR分析其工作过程如下:
输入 栈 剩余输入 操作 初始化 0 b a b $ bab$ --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 迭代一 04 ACTION[0,b]=s4 b a b $b ab$ --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 迭代二 B 02 ACTION[4,a]=r3 | $B ab$ B→b b a b GOTO[0,B]=2 --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 迭代三 B 023 ACTION[2,a]=s3 | $Ba b$ b a b --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 迭代四 B 0234 ACTION[3,b]=s4 | $Bab $ b a b --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 迭代五 B B 0236 ACTION[4,$]=r3 | | $BaB $ B→b b a b GOTO[3,B]=6 --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 B 025 ACTION[6,$]=r2 | \ $BB $ B→aB 迭代六 B | B GOTO[2,B]=5 | | | b a b -------------------------------------------------------------------------- 输入 栈 剩余输入 备注 S ACTION[5,$]=r1 |\ S→BB | B 01 GOTO[0,S]=1 | | \ $S $ 迭代七 B | B | | | b a b --------------------------------------------------------------------------- 输入 栈 剩余输入 备注 S ACTION[1,$]=acc |\ | B 01 | | \ $S $ 迭代八 B | B | | | b a b --------------------------------------------------------------------------- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
上面的例子很好地描述了LR分析器的过程。接下来,如何构建LR分析表成了LR分析的关键。
LR(0)分析
增广文法
对于下面的算术表达式文法G:
// G 1) E → E + T 2) E → T 3) T → T * F 4) T → F 5) F → ( E ) 6) F → id- 1
- 2
- 3
- 4
- 5
- 6
- 7
这个文法G中,起始符号 E 出现在多个产生式的左部(1、2),会使得分析器有多个接收状态。
为了解决这个问题,在 G 中新增一个起始符号 S’ 和产生式 S’→S,称为 G 的增广文法(Augmented Grammar) G’,使得开始符号仅出现在一个产生式的左部,从而使得分析器只有一个接受状态。
G 的增广文法 G’ 为:
// G' 0) E'→ E 1) E → E + T 2) E → T 3) T → T * F 4) T → F 5) F → ( E ) 6) F → id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
点标记
为了标记语法分析器已经读入了多少输入,引入一个点标记 ·
例如: E + 3 · * 4。· 前面的表示已经读入串,· 后面表示剩余读入串。
项目
项目(Item):右部某位置标有圆点的产生式称为相应文法的一个项目。例如: A → α 1 ⋅ α 2 A \rightarrow \alpha_1·\alpha_2 A→α1⋅α2。产生式 A → ε A\rightarrowε A→ε 只生成一个项目 A → ⋅ A \rightarrow · A→⋅。项目描述了句柄的识别状态。
后继项目 (Successive Item):同属于一个产生式的项目,但圆点的位置只相差一个符号,则称后者是前者的后继项目,例如: A → α ⋅ X β A \rightarrow α· Xβ A→α⋅Xβ 的后继项目是 A → α X ⋅ β A \rightarrow αX·β A→αX⋅β。
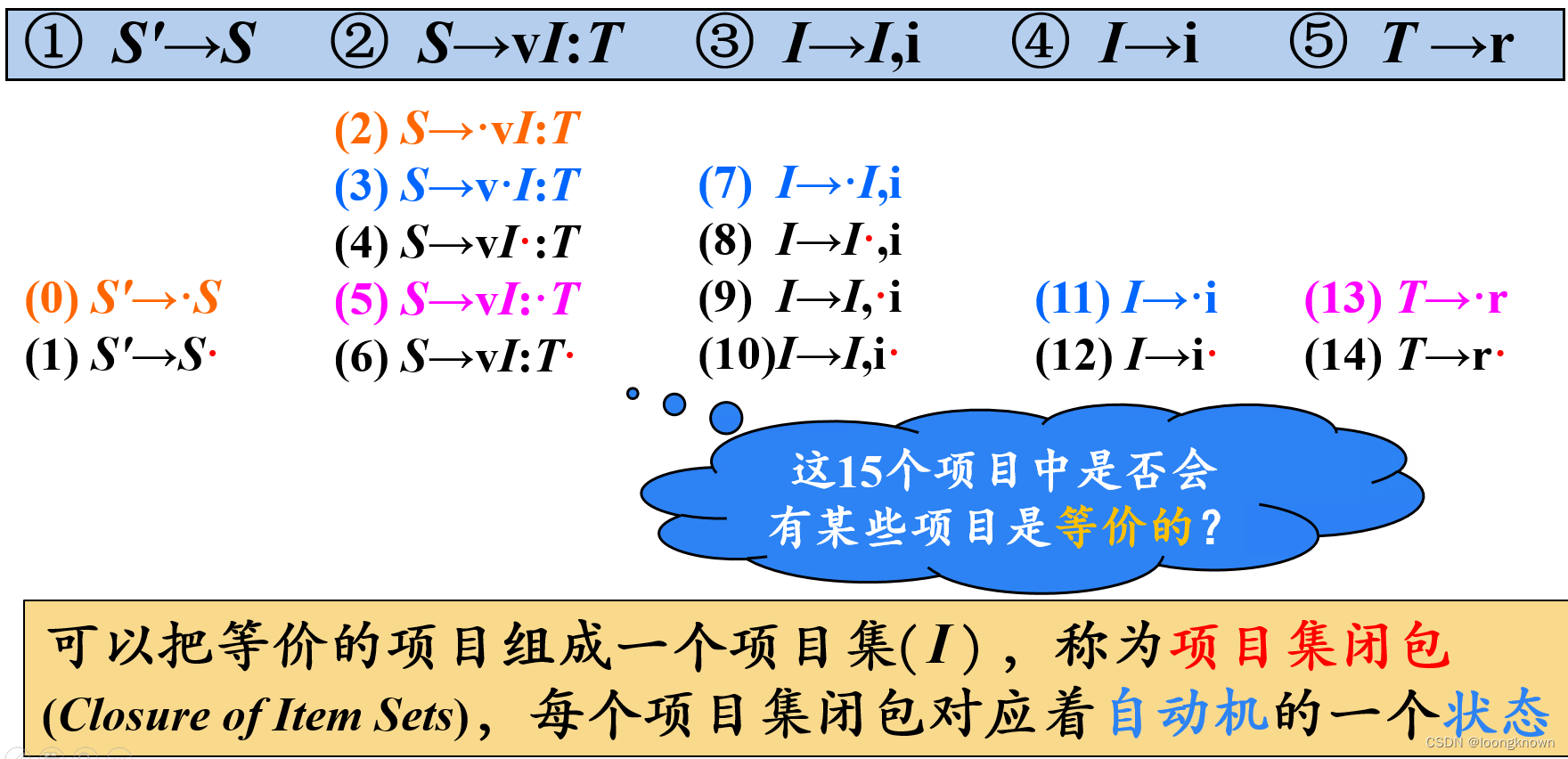
这个例子中,标有相同彩色标记的项目(如0、2)属于一个项目集闭包,也是自动机的一个状态。
LR(0)分析表
很容易将上述文法的项目集转换为LR(0)自动机和LR(0)分析表:

CLOSURE函数
根据项目集等价的含义,很容计算给定项目集 I I I 的 C L O S U R E CLOSURE CLOSURE 函数:
C L O S U R E ( I ) = I ∪ { B → ⋅ γ ∣ A → α ⋅ B β ∈ C L O S U R E ( I ) , B → γ ∈ P } CLOSURE( I ) = I∪ \{B→ · γ \ | \ A→α·Bβ∈CLOSURE( I ) , B→γ∈P\} CLOSURE(I)=I∪{B→⋅γ ∣ A→α⋅Bβ∈CLOSURE(I),B→γ∈P}
SetOfltems CLOSURE ( I ) { J = I; repeat for ( J中的每个项A → α·Bβ ) for ( G的每个产生式 B → γ ) if ( 项B → · γ 不在J中 ) 将 B → · γ 加入J中; until 在某一轮中没有新的项被加入到J中; return J; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
GOTO函数
返回项目集 I I I 对应于文法符号 X X X 的后继项目集闭包:
G O T O ( I , X ) = C L O S U R E ( { A → α X ⋅ β ∣ A → α ⋅ X β ∈ I } ) GOTO( I, X )=CLOSURE(\{A→αX·β \ | \ A→α·Xβ∈I \}) GOTO(I,X)=CLOSURE({A→αX⋅β ∣ A→α⋅Xβ∈I})
SetOfltems GOTO ( I,X ) { 将J 初始化为空集; for ( I 中的每个项A → α·Xβ ) 将项 A → αX·β 加入到集合J 中; return CLOSURE ( J ); }- 1
- 2
- 3
- 4
- 5
- 6
LR(0)自动机的状态集
规范LR(0)项集族 (Canonical LR(0) Collection):
C = { I 0 } ∪ { I ∣ ∃ J ∈ C , X ∈ V N ∪ V T , I = G O T O ( J , X ) } C=\{I_0 \}∪\{ I \ | \ \exists J ∈ C, X∈V_N ∪ V_T , I=GOTO(J , X) \} C={I0}∪{I ∣ ∃J∈C,X∈VN∪VT,I=GOTO(J,X)}
void items( G' ) { C={ CLOSURE ({[ S'→ ·S ] } ) }; repeat for ( C中的每个项集 I ) for( 每个文法符号 X ) if ( GOTO( I,X )非空且不在C中) 将GOTO( I,X )加入C中; until在某一轮中没有新的项集被加入到C中; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
LR(0)分析表构造算法
- 构造G’的规范LR(0)项集族 C = { I 0 , I 1 , . . . , I n } C = \{ I_0 , I_1 , ... , I_n \} C={I0,I1,...,In}
- 令
I
i
I_i
Ii 对应状态
i
i
i。状态
i
i
i 的语法分析动作按照下面的方法决定:
2.1. i f A → α ⋅ a β ∈ I i a n d G O T O ( I i , a ) = I j t h e n A C T I O N [ i , a ] = s j if A→α·aβ∈I_i \ and \ GOTO( I_i , a )=I_j \ then \ ACTION[ i, a ]=sj ifA→α⋅aβ∈Ii and GOTO(Ii,a)=Ij then ACTION[i,a]=sj
2.2. i f A → α ⋅ B β ∈ I i a n d G O T O ( I i , B ) = I j t h e n G O T O [ i , B ] = j if A→α·Bβ∈I_i \ and \ GOTO( I_i , B )=I_j \ then \ GOTO[ i, B ]=j ifA→α⋅Bβ∈Ii and GOTO(Ii,B)=Ij then GOTO[i,B]=j
2.3. i f A → α ⋅ ∈ I i if A→α·∈I_i ifA→α⋅∈Ii 且 A ≠ S ′ t h e n f o r ∀ a ∈ V T ∪ { A ≠ S' \ then \ for \ \forall a∈V_T ∪ \{ A=S′ then for ∀a∈VT∪{ $ } \} } d o A C T I O N [ i , a ] = r j do \ ACTION[ i, a ]=rj do ACTION[i,a]=rj ( j j j 是产生式 A → α A→α A→α 的编号)
2.4. i f S ′ → S ⋅ ∈ I i t h e n A C T I O N [ i , if S'→S· ∈I_i \ then \ ACTION[i, ifS′→S⋅∈Ii then ACTION[i, $ ] = a c c ]=acc ]=acc - 没有定义的所有条目都设置为“error”
LR(0)自动机的形式化定义
文法 G:
G = ( V N , V T , P , S ) G=(V_N,V_T,P,S) G=(VN,VT,P,S)LR(0)自动机:
M = ( C , V N ∪ V T , G O T O , I 0 , F ) M=(C,V_N \cup V_T,GOTO,I_0,F) M=(C,VN∪VT,GOTO,I0,F)- C = { I 0 } ∪ { I ∣ ∃ J ∈ C , X ∈ V N ∪ V T , I = G O T O ( J , x ) } C=\{I_0\}\cup\{I \ | \ \exist J \in C,X \in V_N \cup V_T,I=GOTO(J,x) \} C={I0}∪{I ∣ ∃J∈C,X∈VN∪VT,I=GOTO(J,x)}
- I 0 = C L O S U R E ( { S ′ → ∙ S } ) I_0=CLOSURE(\{S^{'} \rightarrow \bullet S\}) I0=CLOSURE({S′→∙S})
- F = { C L O S U R E ( { S ′ → S ∙ } ) } F=\{CLOSURE(\{S^{'} \rightarrow S\bullet \})\} F={CLOSURE({S′→S∙})}
LR(0)分析的冲突问题
LR(0)分析过程中可能会出现移进和归约二者间的冲突问题。例如:
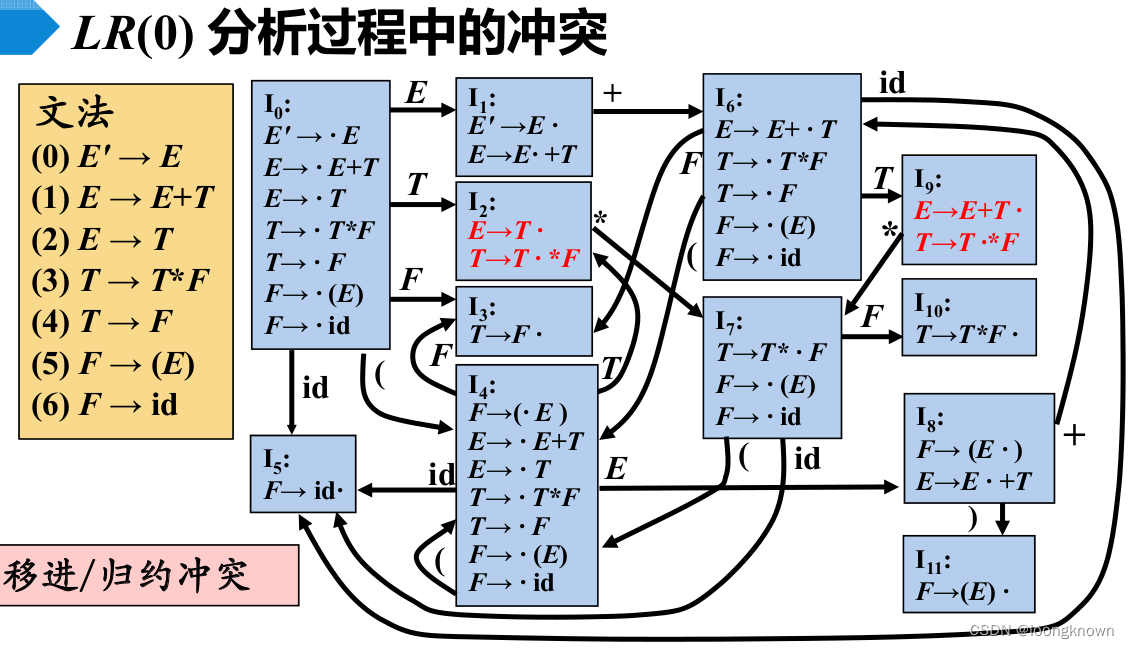

如果LR(0)分析表中没有语法分析动作冲突,那么给定的文法就称为LR(0)文法。不是所有CFG都能用LR(0)方法进行分析,也就是说,CFG不总是LR(0)文法。
SLR分析
SLR算法的关键
有的LR(0)分析表的冲突的问题,可以使用SLR分析解决。SLR分析算法和LR(0)分析算法基本步骤相同,仅在分析表构造算法的2.3中处理归约项目时不同:
- 对于 i i i 状态上的项目 A − > α ∙ A->\alpha \bullet A−>α∙,仅对 y ∈ F O L L O W ( A ) y \in FOLLOW(A) y∈FOLLOW(A) 时才添加 A C T I O N [ i , y ] ACTION[i,y] ACTION[i,y]。
对于上面的数学表达式。得到SLR分析表如下:
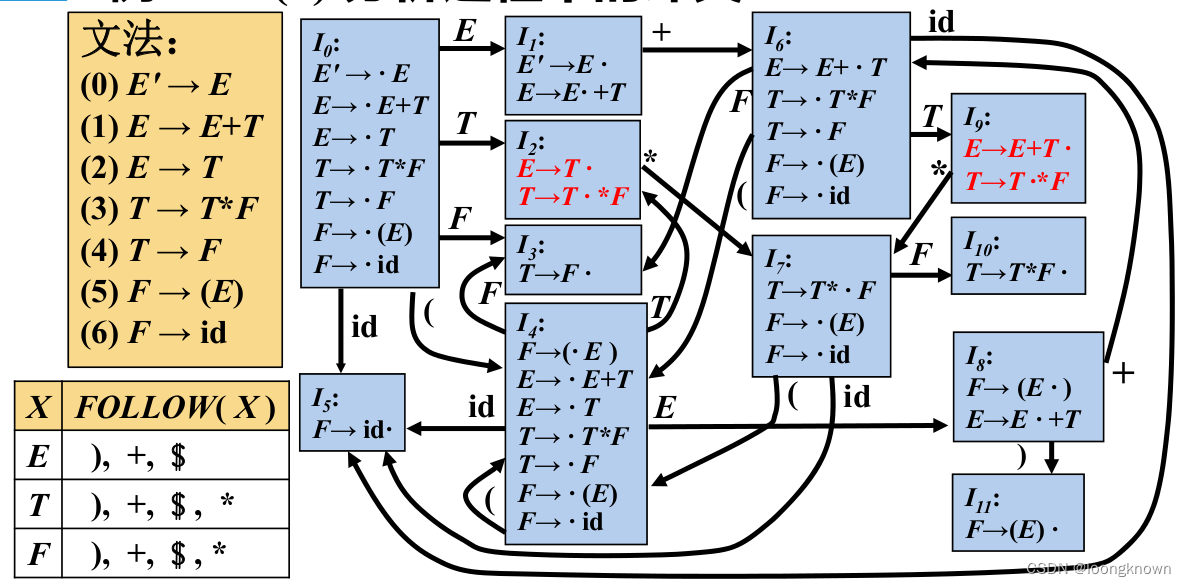
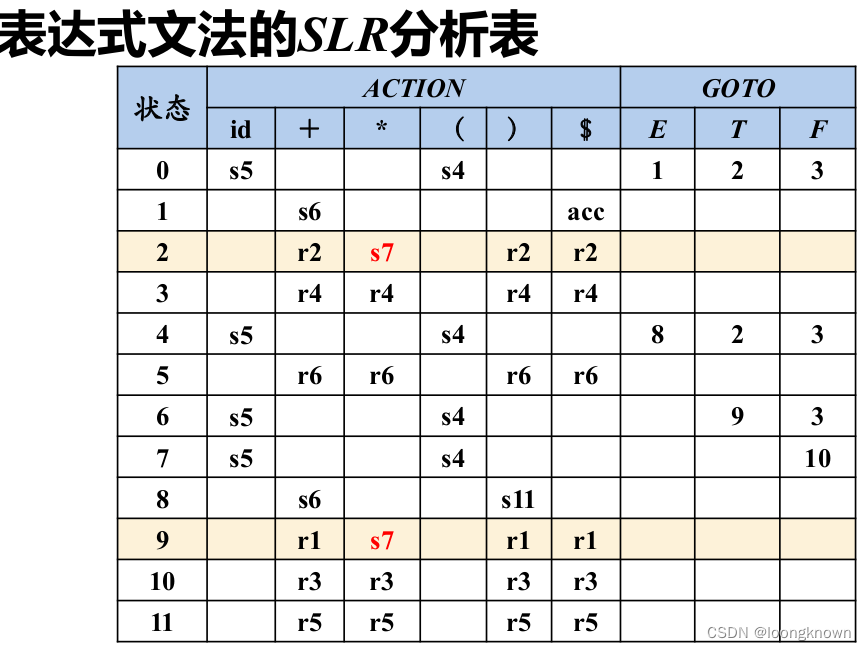
可以消除LR(0)分析表的冲突问题。下面再给一个例子:

SLR分析的冲突问题
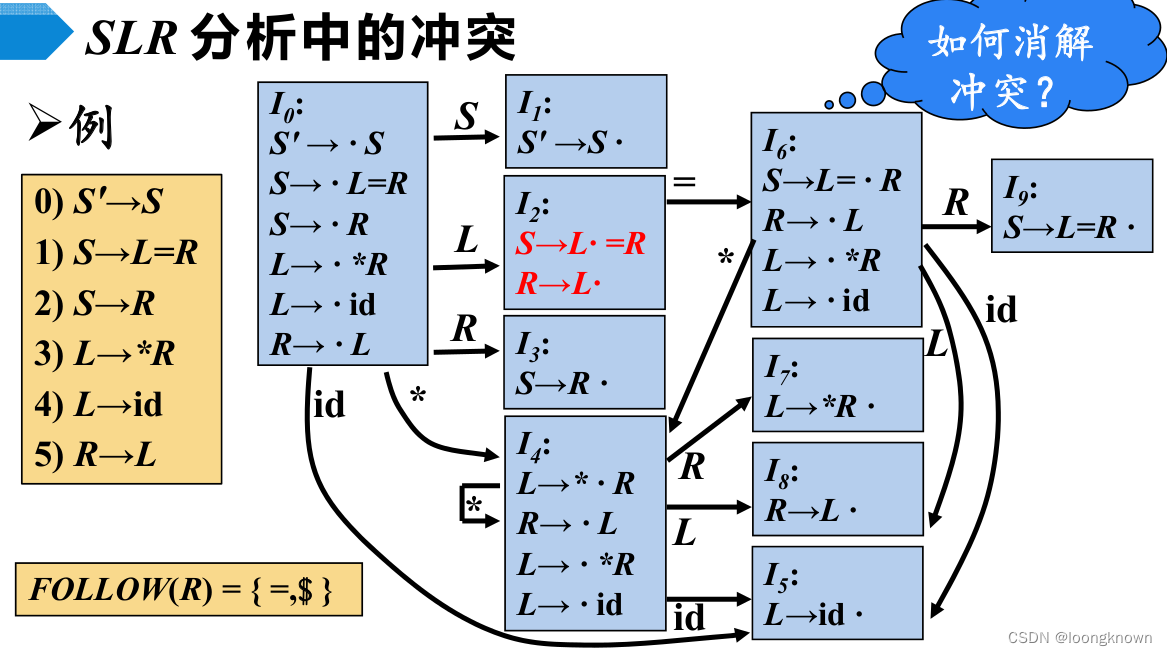
如果给定文法的SLR分析表中不存在有冲突的动作,那么该文法称为SLR文法。
LR(1)分析
SLR只是简单地考察下一个输入符号 b 是否属于与归约项目 A→α 相关联的 FOLLOW(A)。但 b∈FOLLOW(A) 只是归约 α 的一个必要条件,而非充分条件。
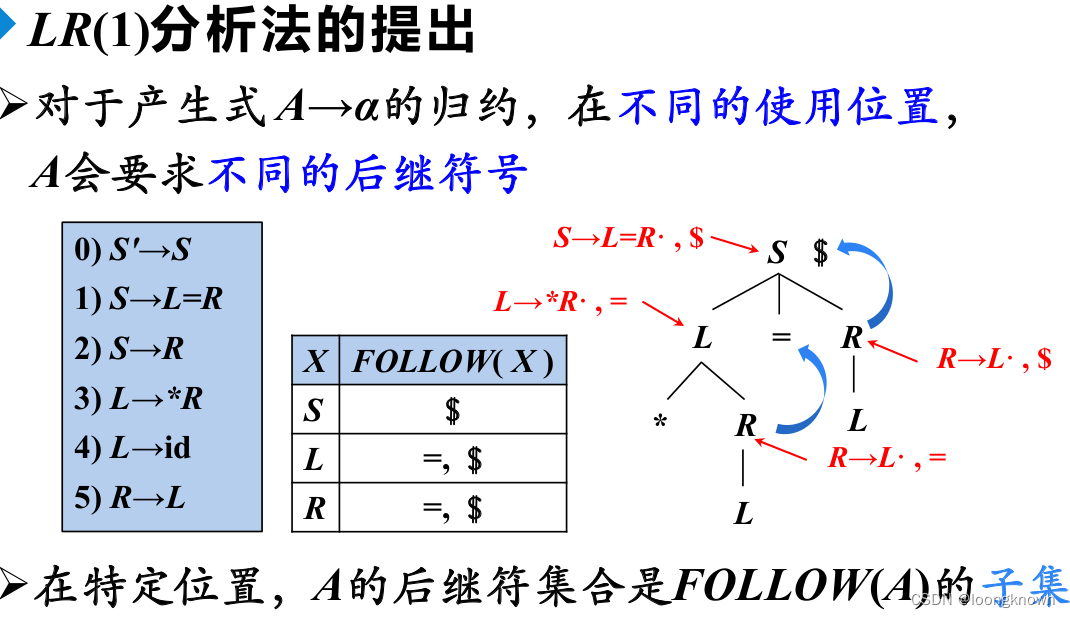
在不同的位置,A会有不同的后继符号。使用 FOLLOW(A) 判定 A − > α A->\alpha A−>α 是否可以归约,显然扩大了归约的范围。LR(1)分析会使用特定位置的后继符号,从而解决这个问题。
规范LR(1)项目
将一般形式为 [A→α · β, a] 的项称为 LR(1) 项 。 a 是一个终结符(展望符,lookahead),用于表示当前状态下,A后面必须紧跟的终结符。
- LR(1) 中的 1 指的是项的第二个分量的长度。
- 在形如 [A→α · β, a] 且 β ≠ ε 的项中,展望符 a 没有任何作用。
- 但是一个形如 [A→α · , a] 的项在只有在下一个输入符号等于 a 时才可以按照 A→α 进行归约。
等价LR(1)项目

因为这里 β 可能推导为空,因此 b ∈ FIRST (βa) 。
当 β = > + ε β=>^+ ε β=>+ε 时,此时 b=a 叫 继承的 后继符,否则叫 自生的 后继符。
则赋值语句文法的 LR(1) 自动机和分析表如下:


构造过程和LR(0)和SLR自动机和分析过程一样,主要是在遇到待归约的LR(1)项目时,计算等价项目(也即闭包集)的方法不一样。
同心项目集

则同心的项目集为:
- I 10 I_{10} I10 和 I 8 I_8 I8
- I 11 I_{11} I11 和 I 4 I_4 I4
- I 12 I_{12} I12 和 I 5 I_5 I5
- I 13 I_{13} I13 和 I 7 I_7 I7
如果把同心项目集合并,则LR(1)自动机的状态数目和SLR是一样的。
CLOSURE函数
C L O S U R E ( I ) = I ∪ { [ B → ⋅ γ , b ] ∣ [ A → α ⋅ B β , a ] ∈ C L O S U R E ( I ) , B → γ ∈ P , b ∈ F I R S T ( β a ) } CLOSURE( I ) = I ∪ \{ [B→·γ, b] \ | \ [A→α·Bβ, a] ∈ CLOSURE( I ), B→γ∈P, b∈FIRST(βa)\} CLOSURE(I)=I∪{[B→⋅γ,b] ∣ [A→α⋅Bβ,a]∈CLOSURE(I),B→γ∈P,b∈FIRST(βa)}
SetOfltems CLOSURE ( I ) { repeat for ( I中的每个项 [A → α·Bβ,a ]) for (G' 的每个产生式 B → γ) for ( FIRST (βa)中的每个符号 b ) 将[ B → · γ ,b]加入到集合 I 中; until 不能向I中加入更多的项; until I ; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
GOTO函数
G O T O ( I , X ) = C L O S U R E ( { [ A → α X ⋅ β , a ] ∣ [ A → α ⋅ X β , a ] ∈ I } ) GOTO( I, X ) = CLOSURE(\{[A→αX · β,a] \ | \ [A→α · Xβ, a]∈I \}) GOTO(I,X)=CLOSURE({[A→αX⋅β,a] ∣ [A→α⋅Xβ,a]∈I})
SetOfltems GOTO ( I,X ) { 将J 初始化为空集; for ( I 中的每个项 [A → α·Xβ,a ]) 将项 [A → αX·β,a]加入到集合 J 中; return CLOSURE ( J ); }- 1
- 2
- 3
- 4
- 5
- 6
文法G’ 构造LR(1)项集族
void items (G' ) { 将C初始化为{CLOSURE ({[ S' → · S, $]} )} ; repeat for ( C 中的每个项集 I ) for ( 每个文法符号 X ) if (GOTO(I,X )非空且不在 C 中) 将 GOTO(I,X )加入 C 中; until 不再有新的项集加入到C中; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
LR(1)分析表的构造算法
LR(1)分析表算法和LR(0)分析表算法流程一致,稍加修改即可:

LALR分析
对于LR(1)自动机中,同心的项目集其实是不存在动作冲突,只是展望符不同,可以进行合并,以减少其状态。这就是 LALR分析。
-
寻找具有相同核心的LR(1) 项集,并将这些项集合并为一个项集;
-
然后根据合并后得到的项集族构造语法分析表;
-
如果分析表中没有语法分析动作冲突,给定的文法就称为LALR(1) 文法,就可以根据该分析表进行语法分析。

合并同心项目集时可能产生归约-归约的冲突。例如:

同心项目集合并是合并的是展望符,展望符只在归约的时候起作用,因此,合并同心项目集不会产生移进-归约的冲突。但合并同心项目集可能产会推迟错误的发现。例如:

I 4 I_4 I4 和 I 9 I_9 I9 是同心项目集, I 6 I_6 I6 和 I 1 0 I_10 I10 是同心项目集。
对于错误输入d$,合并同心项目集前,从状态 I 0 I_0 I0 转移到状态 I 4 I_4 I4 后,由于展望符是 $,而不是 c,则会报错。而合并同心项目集后,在状态 I 4 I_4 I4 时不会报错,而是执行归约,回到状态 I 0 I_0 I0,状态 I 0 I_0 I0 遇到刚归约的A到状态 I 2 I_2 I2,状态 I 2 I_2 I2 遇到 $ 则报错。可见合并同心项目集可能使得报错推迟。
LALR(1)的特点:
-
形式上与LR(1)相同,都是采用LR(1)项目的形式;
-
大小上与LR(0)/SLR相当(自动机的状态相当);
-
分析能力介于SLR和LR(1)二者之间;
S L R < L A L R ( 1 ) < L R ( 1 ) SLR -
合并后的展望符集合仍为FOLLOW集的子集。
参考
-
相关阅读:
基于Redis(SETNX)实现分布式锁,案例:解决高并发下的订单超卖,秒杀
JavaScript函数高级应用
SpringBoot 接收xml数据
github 中关于Pyqt 的module view 操作练习
Python学习三:正则表达式
实战分析:SpringBoot项目 JSR303校验、Hutool工具类的具体使用
SPASS-曲线估计
python3 修行之基础篇(一)python 简介
UDF提权(mysql)
基于FPGA的频率计与串口通信
- 原文地址:https://blog.csdn.net/Dong_HFUT/article/details/127699421
