-
【论文精读】MVSNet架构各组件详解
MVSNet(ECCV2018)是使用神经网络做三维重建的一篇经典论文,但大部分讲解其实都是翻译…看来看去最重要的网络训练各步骤原理和作用都是朦朦胧胧,感谢@朽一的博文用书来比喻特征图让我大致理解了整个过程。
下边结合我自己的理解做了图示来逐流程介绍,个人认为是比较易懂的,当然也欢迎讨论交流!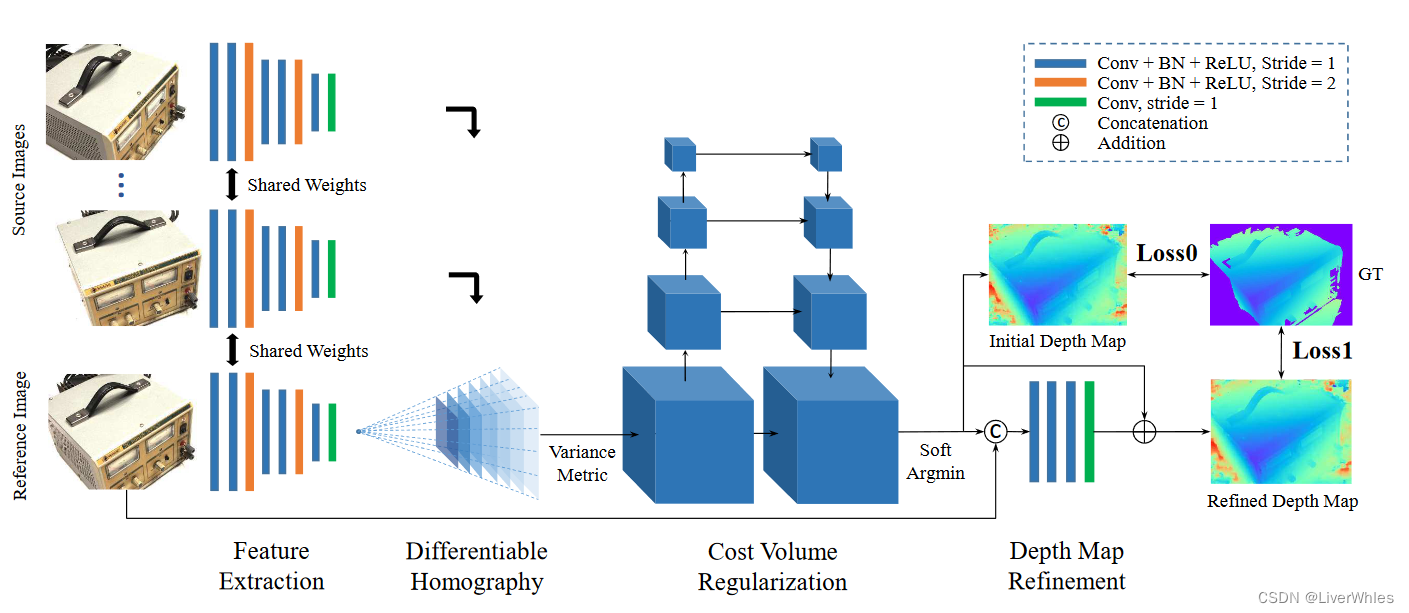
一、训练流程
1.特征提取
与传统三维重建方法类似,第一步是提取图像特征(SIFT等特征子),不同点在于本文使用8层的卷积网络从图像当中提取更深层的图像特征表示,网络结构如下图所示:
输入:N张3通道的图像,宽高为W,H
输出:N组32通道图,每通道尺度为,H/4,W/4
2.构建特征体(Feature Volume)
2.1 单应性变换
单应性变换简单来说,对于3D空间的点X,我们通过相机1拍照,得到照片1上的对应二维像素点P(x,y);在另一个位置用相机2拍照,得到照片2上的对应二维像素点P’(x’,y’)——通过一个正确的单应矩阵H(包含相机1,2的位置转换参数R,T、相机1到点X的距离d),可以实现P’ = HP。即在已经提前获取相机的内外参数前提下,因此只需要一个深度值变量,就可以找到参考图像上点P对应在源图像上点P’的位置。
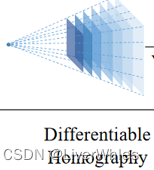
若我们已知两个位姿的相机参数(相机1,2的位置转换参数),现在设置一个深度区间[d1,d2],并设置分辨率为Δd,由此得到D=(d2-d1)/Δd个平面,那么每个d都对应了一个单应变换矩阵h。
如果对一张图片上每个像素点,使用di对应的矩阵hi进行变换可以得到一张变换后的图片,意义为假设各个像素点真实深度都为d时,在另一位姿下各像素点的应有的对应特征值。
而我们假设了D个深度,也即将得到D幅变换后的图像,各图代表了其像素点真实深度为当前深度时变换对应的特征值,即可理解为上图中各层蓝色由深变浅的图层。为什么是“锥形视锥”,因为当单应矩阵对应的真实深度不同时,由近大远小原理可知能被当前位置的相机看到的特征点数量随着深度减小而减小,因而出现锥形。(在下一步构建特征体时使用了双线性插值来保证所有深度的特征图尺寸一致)
2.2 特征体构建
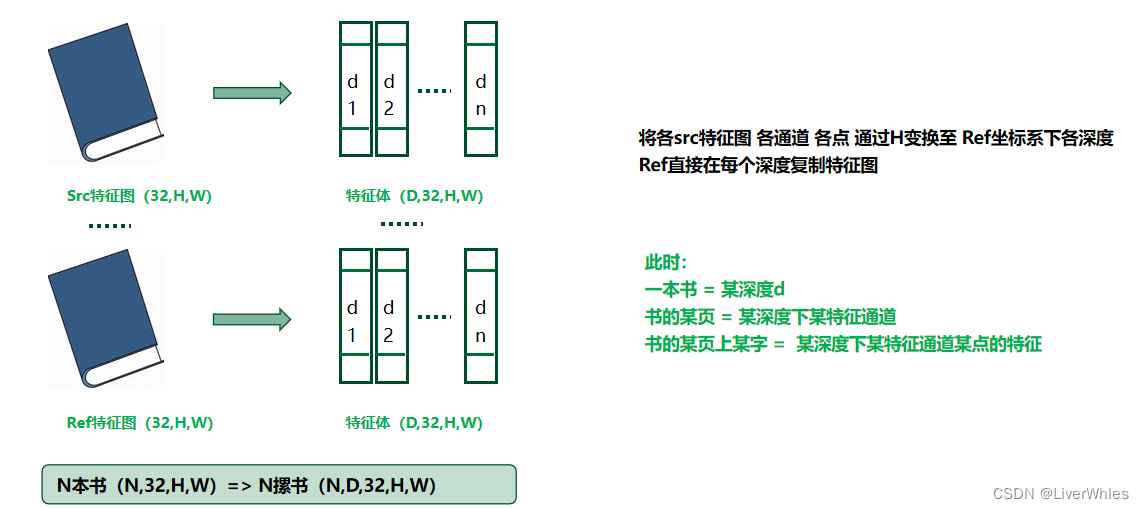
在本文当中,我们通过特征提取得到的是N个特征图(1个参考图、N-1个原图),每个特征图有32通道。
每个特征图可以理解为一本书,有32页,每页尺寸是HxW
那么,一本书(一个特征体)通过2.1中的单应变换就变成了一摞书,等于将原来第一页通过深度为[d1,d2]的矩阵[h1,h2]变换成n个深度下的第一页,将原来第二页变成n个深度下的第二页……
此时,一本书 = 某深度d
书的某页 = 某深度下某特征通道
书的某页上某字 = 某深度下某特征通道某点的特征需要注意的是,对于Ref的特征图则是直接在每个深度下复制,因为多个Src都是要变换到这个参考图下的
3.生成代价体(Cost Volume)
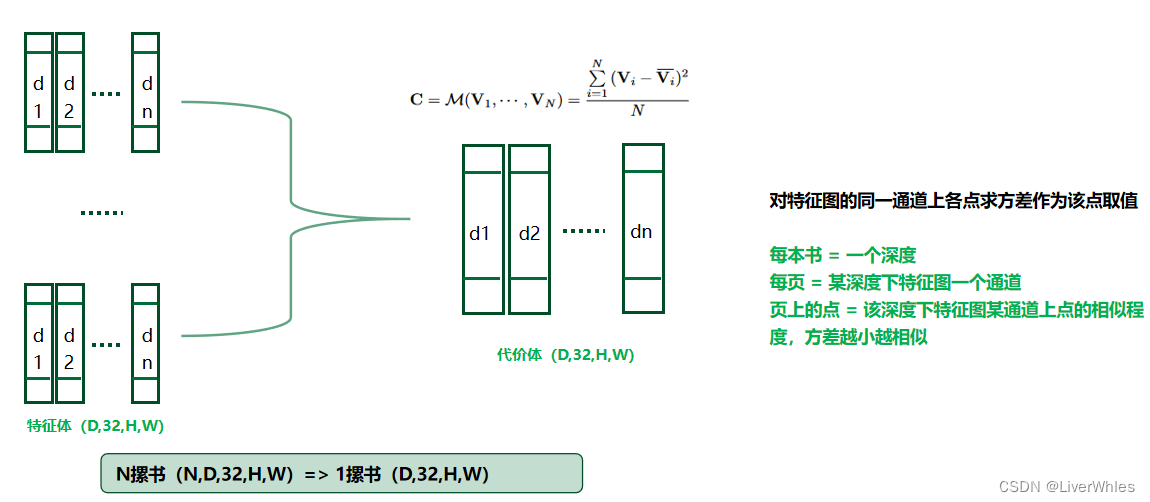
通过第2步我们得到了N摞书,现在竖着看每摞书的第一本,代表了假设深度为d1时,各特征图上各像素经过变换后的特征值——若某个像素真实深度接近d1的话,那变换后该列该处的特征值应该是近似的。
基于这样的想法,对每一列书的每一页上的每个像素计算方差,代表了假设深度为di时,各图像特征图的各通道各特征点的差异情况,方差越小,越相似,该特征点真实深度就越可能是di。该步得到了一摞书,每本书 = 一个深度
每页 = 某深度下特征图一个通道
页上的点 = 该深度下特征图某通道上点的相似程度,方差越小越相似这里就是论文所说能够接受任意N个输入的原因,因为是取方差所以输入几个都一样。
4.代价体正则化(Cost Volume Regularization)
在第3步中得到了代价体,但论文说 “The raw cost volume computed from image features could be noise-contaminated” ,即这个代价体由于非朗伯面、遮挡等原因是包含噪声的,要通过正则化来得到一个概率体P(probability volume),具体采用了一个类似UNet的网络结构,对原代价体进行编码和解码,并最终将各通道数压缩为1,即将一摞书变成了一本书
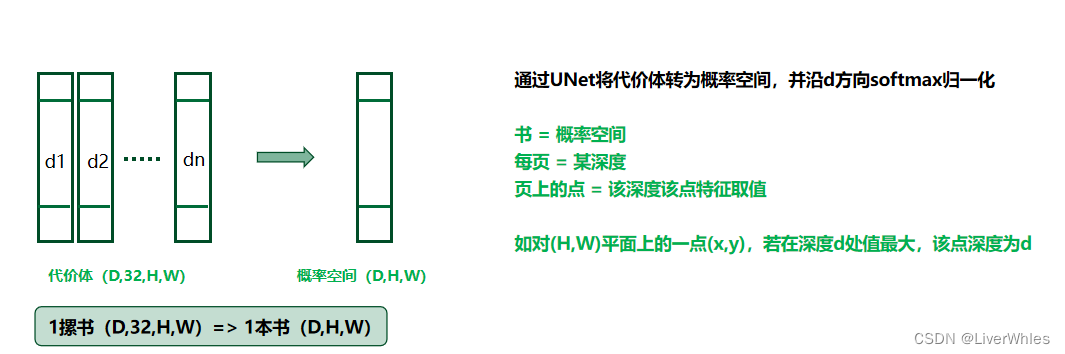
此时书 = 概率体
每页 = 某深度
页上的点 = 该点在该深度的概率如对(H,W)平面上的一点(x,y),若在深度d处值最大,该点深度为d
个人感觉把多个通道特征压缩成一个通道,直观想法是保留其中方差最小(最可能属于当前深度)的那个通道的特征,然后方差越小说明这个像素点的深度越可能是当前层深度;但文章说是出于噪声目的试用网络来正则化获得最终的概率体,不太理解为什么要用这个UNet网络。
5.深度图初始估计(Depth Map Initial Estimation)

利用第4步的概率体,沿深度d方向求期望,就得到对应像素点的初始深度值;
对每个像素点求期望,即将概率体变成了一张概率图。6.深度图优化(Depth Map Refinement)

7.损失计算(Loss)

二、后处理
论文在摘要中提到*“With simple post-processing”*之后模型效果很好,这个post-processing主要包括深度图滤波和深度图融合两部分。
1.深度图滤波(Depth Map Filter)
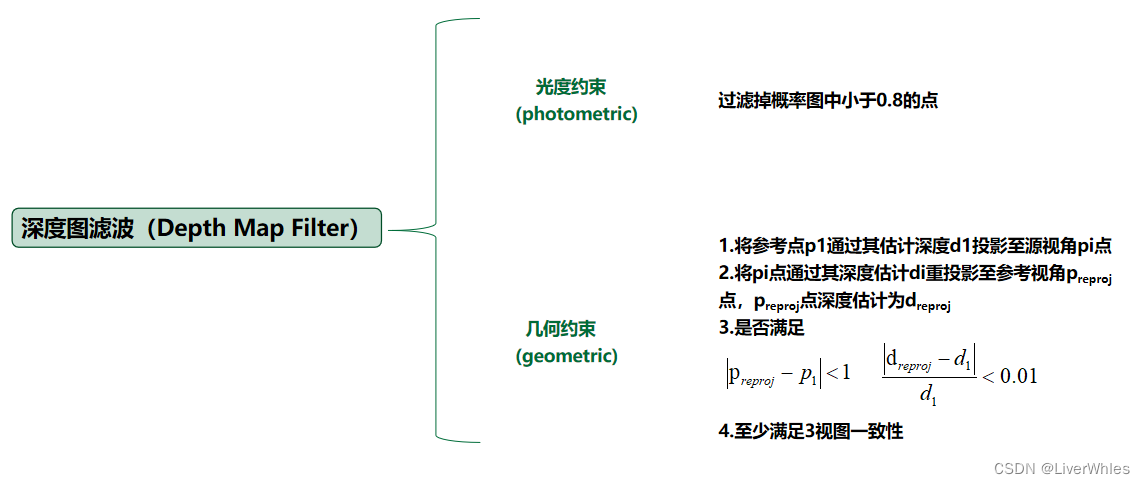
深度图滤波主要提出了两个约束,光度约束和几何约束。1.1 几何约束
首先几何约束比较简单,就是说将参考点p1通过其估计深度d1投影至源视角pi点,再将pi点通过其深度估计di重投影至参考视角preproj点,这个重投影后的preproj点深度估计为dreproj,若满足
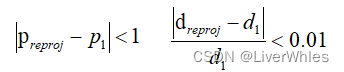
则说是满足几何约束的,论文里保证三视图满足该几何约束一致性。1.2 光度约束
光度约束,其实是在通过概率体得到初始深度图的同时计算了一个概率图

各像素点的深度越集中在某个深度附近,则该点深度判断的准确概率越高,最后过滤掉概率小于0.8的点。2.深度图融合(Depth Map Fusion)
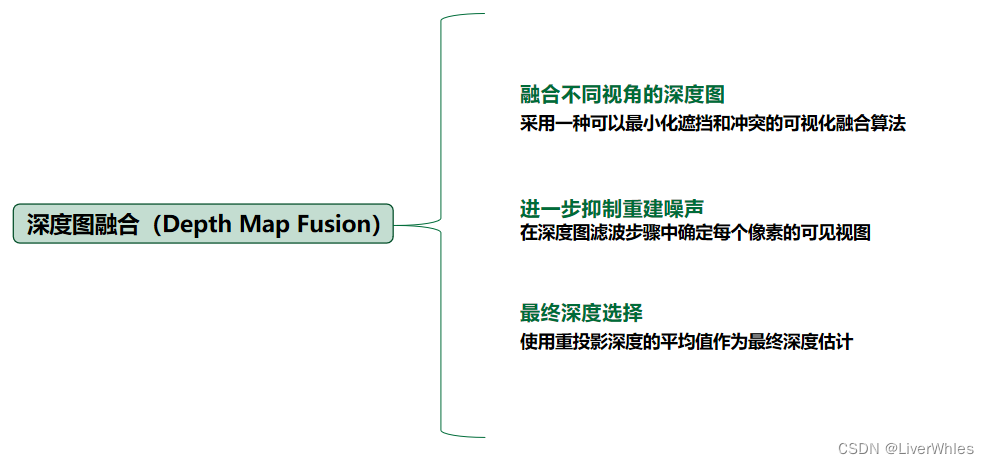
即在多个视角下推测深度图,并采取特定融合算法融合;其中每个深度图的像素深度选择是使用了几何约束时计算的重投影的均值作为最终深度估计。三、总结

-
相关阅读:
JavaScript 中的构造函数与原型:有什么区别?
autoReg | 自动线性和逻辑回归和生存分析
Qt中定时器的所有使用方式
JS解混淆
太多了,咖啡加盟哪个品牌好,投资者怎么选择?
Zookeeper三台机器集群搭建
招投标系统软件源码,招投标全流程在线化管理
【零基础入门MyBatis系列】第十五篇——分页插件与注解式开发
【笔者感悟】笔者的学习感悟【八】
Docker笔记-10 Swarm mode
- 原文地址:https://blog.csdn.net/qq_41794040/article/details/127692123