-
Hadoop3 - MapReduce ORC 列式存储
一、列式存储
常见的 DB 数据库,大多都是行式存储系统,比如 MySql,Oracle 等,利于数据一行一行的写入,所以数据的写入会更快,对按行查询数据也更简单。但是像现在常见的 HBase 存储大数据确使用的列式存储,那列式存储有什么优点呢。
在大数据场景下,核心便是 OLAP,对于这种场景下,如果是行式存储,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,而一般情况下仅仅对其中某些感兴趣的列做运算,那一行中那些无关的列也不得不参与扫描。如果是列式存储,可以只扫描我们需要的列,不需要将无关的列进行扫描,减少不必要的IO及磁盘检索消耗,可以大大提升读的性能。
同理列式存储在写操作时便性能不如行式存储,因此对于平常的 OLTP 场景基本都是使用的 MySql、Oracle 这类的行式数据库,而在大数据分析时的 OLAP 时可以考虑使用列式存储。
例如下面这种数据:
id name 1001 张三 1002 李四 1003 王五 如果是行式存储则转化后是:
1001 张三 1002 李四 1003 王五 如果是列的话则是:
1001 1002 1003 张三 李四 王五 读取某一列数据直接将列的块取出即可,并且相同的列数据类型一致,有利于数据结构填充的优化和压缩,而且对于数字列这种数据类型可以采取更多有利的算法去压缩存储。
下面是列式存储和行式存储对比:
行式存储 列式存储 读取特点 会扫描不需要的数据列 只读取需要的数据列 适用场景 适合于按记录读写数据的场景,不适合聚合统计的场景 适合于数据过滤、聚合统计的场景,不适合按记录一个一个读写场景 应用 OLTP OLAP 压缩 不利于压缩数据 适合压缩数据 二、ORC
ORC(OptimizedRC File)文件格式是一种 Hadoop 生态圈中的列式存储格式,源自于RC(RecordColumnar File),它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。
ORC文件基本存储结构:
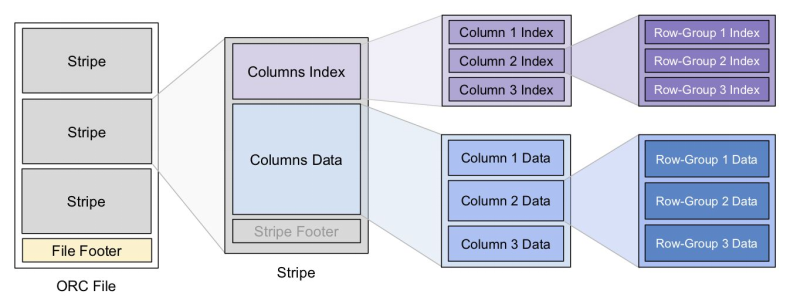
ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据 Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息。
下面是网上公布的性能对比效果:
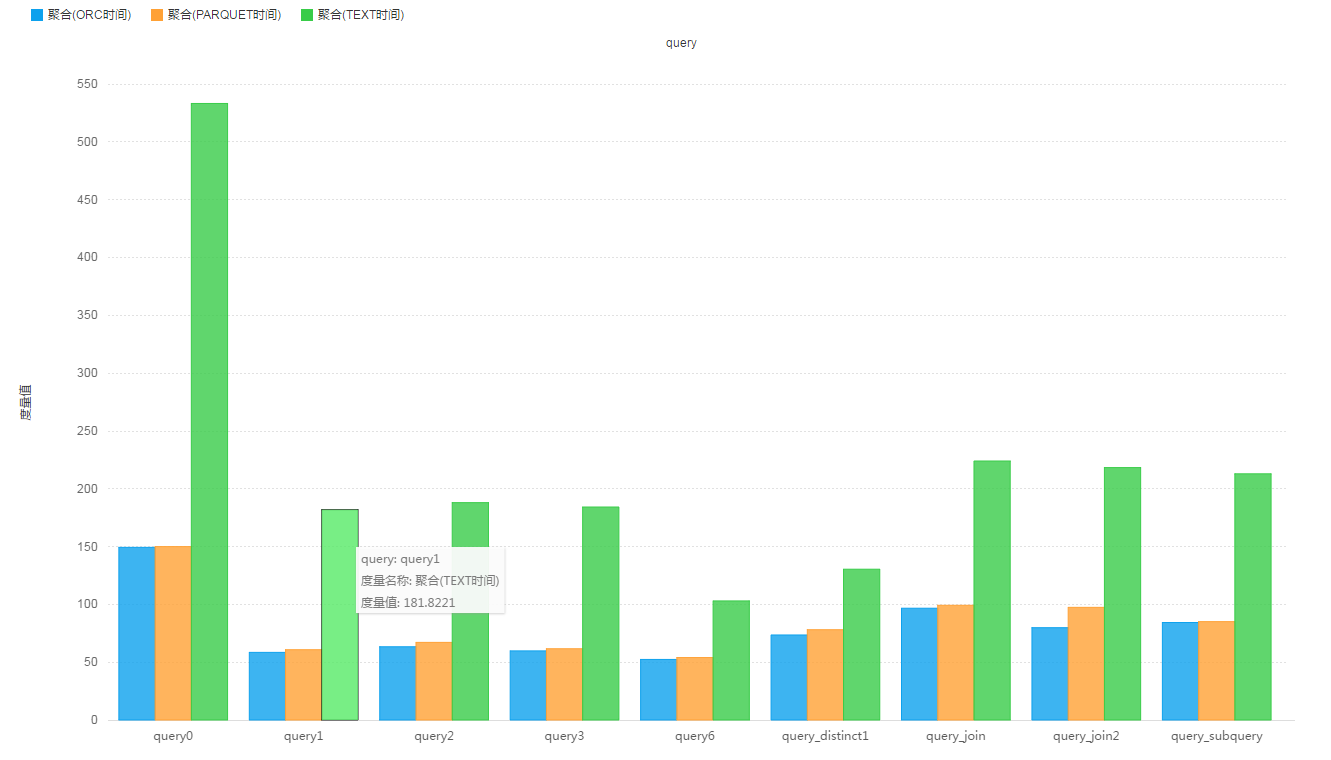
可以看出 ORC 的性能还是较不错的。下面在 MapReduce 中适用 ORC 存储。
三、MapReduce 适用 ORC 格式存储
首先添加 ORC 依赖:
<dependency> <groupId>org.apache.orcgroupId> <artifactId>orc-shimsartifactId> <version>1.6.3version> dependency> <dependency> <groupId>org.apache.orcgroupId> <artifactId>orc-coreartifactId> <version>1.6.3version> dependency> <dependency> <groupId>org.apache.orcgroupId> <artifactId>orc-mapreduceartifactId> <version>1.6.3version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
下面将下面文本数据,转化为 ORC 文件格式,分别对应的字段信息:
date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)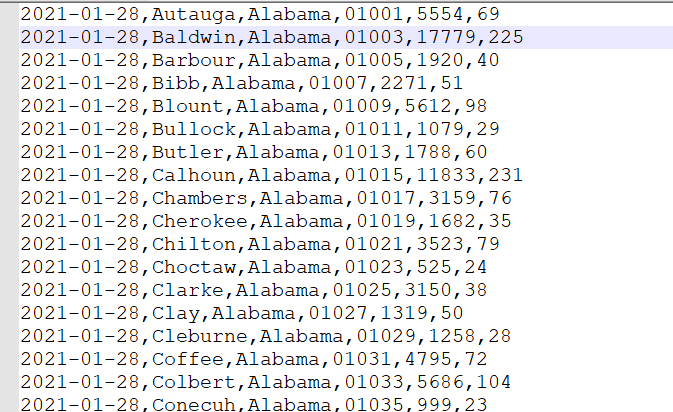
public class OrcFileDriver extends Configured implements Tool { private static final String SCHEMA = "struct- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
下面读取 ORC 文件,转化为文本:public class OrcFileDriver extends Configured implements Tool { private static final String SCHEMA = "struct- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
注意如果打包后发布到 Yarn 集群中运行,需要将 orc-mapreduce 的jar包依赖添加到Hadoop的环境变量中,注意所有NodeManager节点都要添加。
-
相关阅读:
Flutter SQLite 教程之笔记App 数据存储CRUD操作基于 Flutter Sqflite 插件
Spring中给容器中注册组件的4种方式
1.0、C语言——初识C语言
【论文笔记】CrossKD: Cross-Head Knowledge Distillation for Object Detection
openharmony容器组件之Refresh
【postgresql】替换 mysql 中的ifnull()
PyTorch深度学习(30)OpenCV图像处理
什么是PCB中的光学定位点,不加可不可以?
【leetcode】【初级算法】【链表3】反转链表
AcWing---转圈游戏---快速幂
- 原文地址:https://blog.csdn.net/qq_43692950/article/details/127687346