-
Mybatis缓存,一篇就够了
1.Mybatis缓存
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>- 1
基本上就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
这些属性可以通过 cache 元素的属性来修改。比如:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>- 1
- 2
- 3
- 4
- 5
这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU🦆
2.一级缓存
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存
这个缓存的生命周期为一个sqlSession开始直到一个sqlSession结束
SqlSession sqlSession = MybatisUtils.getSqlSession(); // ...一级缓存位置... sqlSession.close();- 1
- 2
- 3
测试一级缓存:
该测试查询了两次一样ID的对象,又查询了一个新的对象:
@Test public void test3() { SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); Blog blog1 = mapper.getBlobById(1); Blog blog2 = mapper.getBlobById(1); Blog blog3 = mapper.getBlobById(2); System.out.println(blog1); System.out.println(blog2); System.out.println(blog3); sqlSession.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
通过Log4j2的日志分析,发现只执行了两条SQL语句,也就是第一次
getBlobById(1)的结果对象被缓存当第二次查询时,只去查找缓存中的数据即可
==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, Kiwi, 谢睿, 2022-01-05 12:25:54, 513 <== Total: 1 ==> Preparing: select * from blog where id = ? ==> Parameters: 2(Integer) <== Columns: id, title, author, create_time, views <== Row: 2, Raspberry, 魏秀英, 2006-12-09 11:07:58, 426 <== Total: 1 Blog(id=1, title=Kiwi, author=谢睿, createTime=Wed Jan 05 12:25:54 CST 2022, views=513) Blog(id=1, title=Kiwi, author=谢睿, createTime=Wed Jan 05 12:25:54 CST 2022, views=513) Blog(id=2, title=Raspberry, author=魏秀英, createTime=Sat Dec 09 11:07:58 CST 2006, views=426)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存🐓
@Test public void test3() { SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); Blog blog1 = mapper.getBlobById(1); Blog blog = new Blog(1, "球球知名", "大河", new Date(), 0); int i = mapper.updateBlogById(blog); Blog blog2 = mapper.getBlobById(1); System.out.println(blog1); System.out.println(blog2); sqlSession.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
通过Log4j2的日志分析,发现执行了三条SQL语句,也就是映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存,以保证数据的一致性
==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, Kiwi, 谢睿, 2022-01-05 12:25:54, 513 <== Total: 1 ==> Preparing: update blog set title=? , author=? where id = ? ==> Parameters: 球球知名(String), 大河(String), 1(Integer) <== Updates: 1 ==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, 球球知名, 大河, 2022-01-05 12:25:54, 513 <== Total: 1 Blog(id=1, title=Kiwi, author=谢睿, createTime=Wed Jan 05 12:25:54 CST 2022, views=513) Blog(id=1, title=球球知名, author=大河, createTime=Wed Jan 05 12:25:54 CST 2022, views=513)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们还可以选择手动清理缓存🦃
@Test public void test3() { SqlSession sqlSession = MybatisUtils.getSqlSession(); BlogMapper mapper = sqlSession.getMapper(BlogMapper.class); Blog blog1 = mapper.getBlobById(1); sqlSession.clearCache(); // 手动清理缓存 Blog blog2 = mapper.getBlobById(1); System.out.println(blog1); System.out.println(blog2); sqlSession.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, 球球知名, 大河, 2022-01-05 12:25:54, 513 <== Total: 1 ==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, 球球知名, 大河, 2022-01-05 12:25:54, 513 <== Total: 1 Blog(id=1, title=球球知名, author=大河, createTime=Wed Jan 05 12:25:54 CST 2022, views=513) Blog(id=1, title=球球知名, author=大河, createTime=Wed Jan 05 12:25:54 CST 2022, views=513)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.二级缓存
要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>- 1
二级缓存也叫全局缓存,是基于namespace级别的缓存,一个sqlSession会话关闭后,一级缓存的内容会保存到二级缓存
现在我们开启二级缓存来测试一下:
开启两个sqlSession,查找同样的数据:
@Test public void test3() { SqlSession sqlSession1 = MybatisUtils.getSqlSession(); SqlSession sqlSession2 = MybatisUtils.getSqlSession(); BlogMapper mapper1 = sqlSession1.getMapper(BlogMapper.class); Blog blog1 = mapper1.getBlobById(1); System.out.println(blog1); sqlSession1.close(); BlogMapper mapper2 = sqlSession2.getMapper(BlogMapper.class); Blog blog2 = mapper2.getBlobById(1); System.out.println(blog2); sqlSession2.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
通过Log4j2的日志分析,发现执行了一条SQL语句,也就是第一次查询的结果被缓存到二级缓存中
==> Preparing: select * from blog where id = ? ==> Parameters: 1(Integer) <== Columns: id, title, author, create_time, views <== Row: 1, 球球知名, 大河, 2022-01-05 12:25:54, 513 <== Total: 1 Blog(id=1, title=球球知名, author=大河, createTime=Wed Jan 05 12:25:54 CST 2022, views=513) Resetting autocommit to true on JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@4a8ab068] Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@4a8ab068] Returned connection 1250603112 to pool. As you are using functionality that deserializes object streams, it is recommended to define the JEP-290 serial filter. Please refer to https://docs.oracle.com/pls/topic/lookup?ctx=javase15&id=GUID-8296D8E8-2B93-4B9A-856E-0A65AF9B8C66 Cache Hit Ratio [top.imustctf.dao.BlogMapper]: 0.5 Blog(id=1, title=球球知名, author=大河, createTime=Wed Jan 05 12:25:54 CST 2022, views=513)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.Mybatis缓存原理
Mybatis缓存结构图:
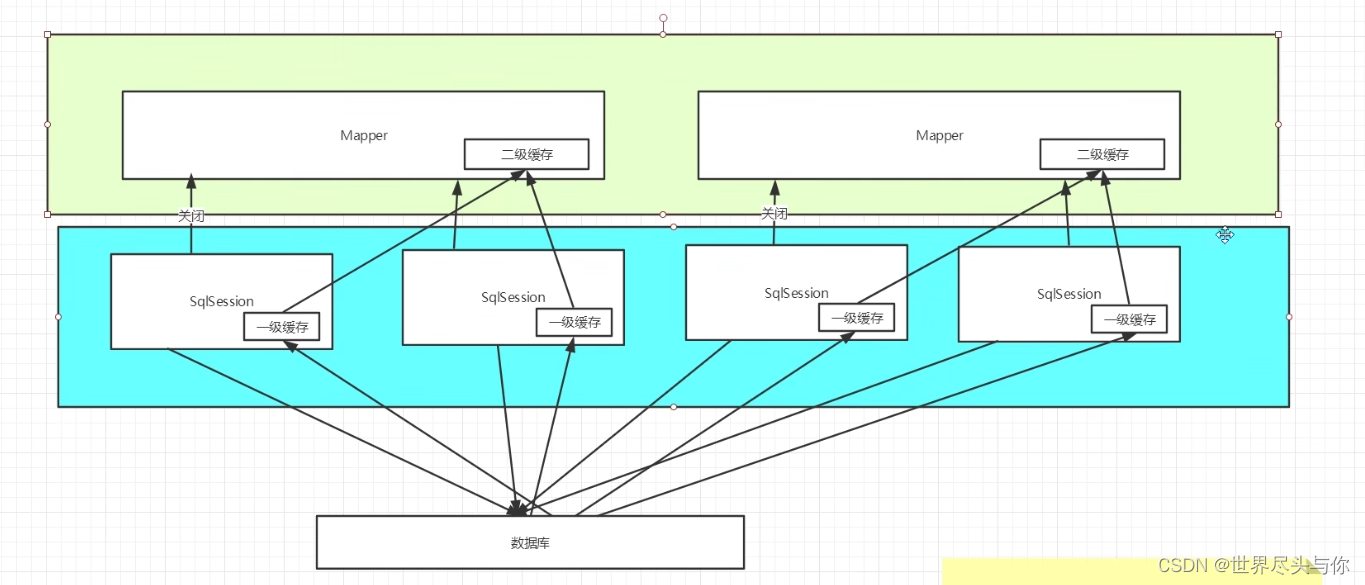
缓存顺序:
先查找二级缓存
再查找一级缓存
最后查找数据库 -
相关阅读:
Jenkins部署spring boot项目
笔记1.4 计算机网络性能
codeforces刷题二
黑马Java热门面试题SpringBoot(七)
C# 12 中的新增功能
【推荐系统】多任务学习模型
Spring之bean的生命周期
2022版shardingsphere4.1.1结合mybatis-plus进行简单依赖YML文件进行分片、自定义生成主键、自定义水平分片的相关策略
Gin Web框架在Go语言中的应用与实践
《爆肝整理》保姆级系列教程-玩转Charles抓包神器教程(15)-Charles如何配置反向代理
- 原文地址:https://blog.csdn.net/Gherbirthday0916/article/details/127680018