-
基础IO —— Linux
目录
write read close lseek ,类比C文件相关接口
注意这里和平时习惯是反的,相当于是用前面的数据去覆盖后面的数据(duplicate 复制)
作者和朋友建立的社区:非科班转码社区-CSDN社区云💖💛💙
期待hxd的支持哈🎉 🎉 🎉
最后是打鸡血环节:想多了都是问题,做多了都是答案🚀 🚀 🚀
最近作者和好友建立了一个公众号
公众号介绍:
专注于自学编程领域。由USTC、WHU、SDU等高校学生、ACM竞赛选手、CSDN万粉博主、双非上岸BAT学长原创。分享业内资讯、硬核原创资源、职业规划等,和大家一起努力、成长。(二维码在文章底部哈!)
文件描述符fd
先来认识一下两个概念 : 系统调用 和 库函数write read close lseek ,类比C文件相关接口
系统接口
write read close lseekC库函数
- #include
- #include
- int main()
- {
- FILE *fp = fopen("./bite", "wb+");
- if (fp == NULL) {
- perror("fopen error");
- return -1;
- }
- fseek(fp, 0, SEEK_SET);
- char *data = "linux so easy!\n";
- //size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
- size_t ret = fwrite(data, 1, strlen(data), fp);
- if (ret != strlen(data)) {
- perror("fwrite error");
- return -1;
- }
- //注意读的时候要fseek!!!因为之前写了之后,文件指向位置就已经变了
- fseek(fp, 0, SEEK_SET);//跳转读写位置到,从文件起始位置开始偏移0个字节
- char buf[1024] = {0};
- //size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
- ret = fread(buf, 1, 1023, fp);//因为设置读取块大小位1,块个数为1023因此fread返回值为实际读取到的数据长度
- if (ret == 0) {
- if (ferror(fp)) //判断上一次IO操作是否正确
- printf("fread error\n");
- if (feof(fp)) //判断是否读取到了文件末尾
- printf("read end of file!\n");
- return -1;
- }
- printf("%s", buf);
- fclose(fp);
- return 0;
- }
通过使用open,我们知道了文件描述符就是一个小整数,用其来操作文件(传参)fopen fclose fread fwrite 都是 C 标准库当中的函数,我们称之为库函数( libc )。而, open close read write lseek 都属于系统提供的接口,称之为系统调用接口回忆一下我们讲操作系统概念时,画的一张图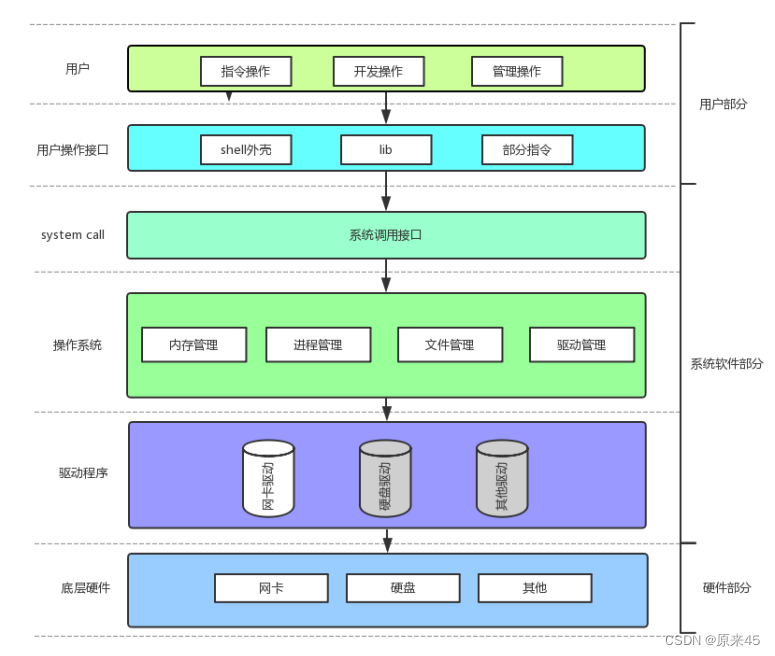 系统调用接口和库函数的关系,一目了然。所以,可以认为, f# 系列的函数,都是对系统调用的封装,方便二次开发。文件 = 文件内容 + 文件属性文件操作 = 文件内容的操作 + 文件属性的操作我们平时说的打开文件:就是将文件的属性或内容加载到内存中 -- 冯诺依曼体系结构决定的通常我们说的打开文件,访问文件是我们写的代码运行起来也就是说是进程去进行操作的我们常常听说当前路径
系统调用接口和库函数的关系,一目了然。所以,可以认为, f# 系列的函数,都是对系统调用的封装,方便二次开发。文件 = 文件内容 + 文件属性文件操作 = 文件内容的操作 + 文件属性的操作我们平时说的打开文件:就是将文件的属性或内容加载到内存中 -- 冯诺依曼体系结构决定的通常我们说的打开文件,访问文件是我们写的代码运行起来也就是说是进程去进行操作的我们常常听说当前路径什么是当前路径
就是当前进程所处的工作路径查看进程当前路径
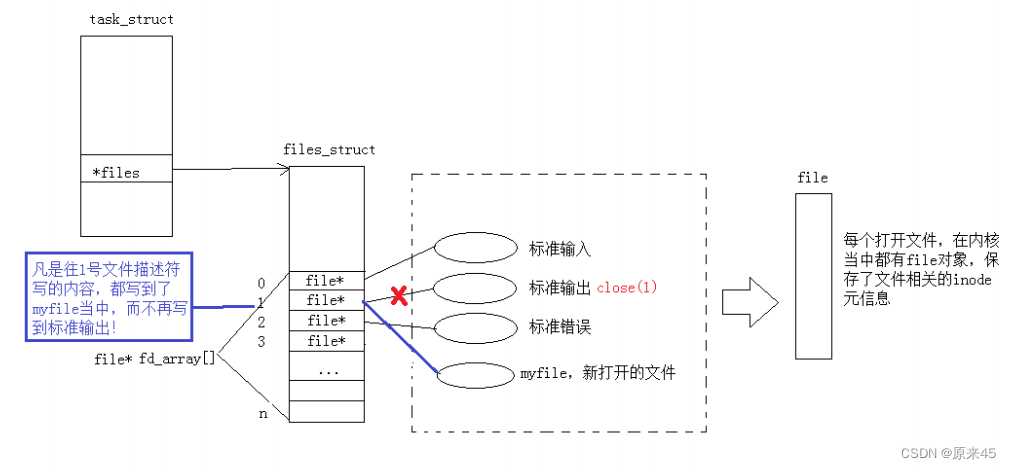
:ls /proc 进程pid看见一个 cwd 会软连接一个路径那个就是当前路径啦cwd(Current Working Directory)PS:Linux下的 FILE 里面的 fileno 就是文件描述符( 我们知道了文件描述符就是一个小整数)Linux进程默认情况下会有3个缺省打开的文件描述符分别是标准输入0, 标准输出1, 标准错误2.0,1,2对应的物理设备一般是:键盘,显示器,显示器所以输入输出还可以采用如下方式: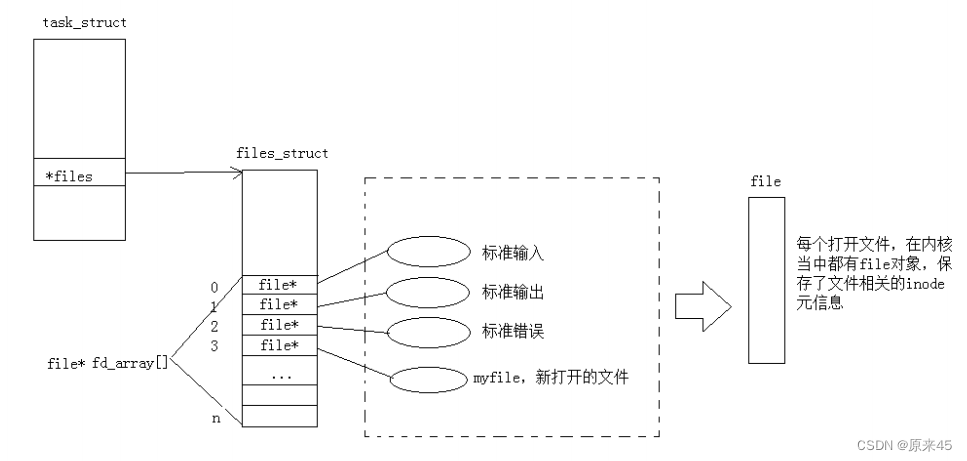 现在知道,文件描述符就是从 0 开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file 结构体。表示一个已经打开的文件对象。而进程执行 open 系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表 files_struct, 该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件(重点)
现在知道,文件描述符就是从 0 开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file 结构体。表示一个已经打开的文件对象。而进程执行 open 系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表 files_struct, 该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件(重点)文件描述符的分配规则
- #include
- #include
- #include
- #include
- int main()
- {
- int fd = open("myfile", O_RDONLY);
- if(fd < 0){
- perror("open");
- return 1;
- }
- printf("fd: %d\n", fd);
- close(fd);
- return 0;
- }
输出发现是 fd: 3关闭 0 或者 2 ,在看- #include
- #include
- #include
- #include
- int main()
- {
- close(0);
- //close(2);
- int fd = open("myfile", O_RDONLY);
- if(fd < 0){
- perror("open");
- return 1;
- }
- printf("fd: %d\n", fd);
- close(fd);
- return 0;
- }
发现是结果是: fd: 0 或者 fd 2 可见,文件描述符的分配规则:在 fifiles_struct 数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符重定向
那如果关闭 1 呢?看代码:- #include
- #include
- #include
- #include
- #include
- int main()
- {
- close(1);
- int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
- if(fd < 0){
- perror("open");
- return 1;
- }
- printf("fd: %d\n", fd);
- fflush(stdout);
- close(fd);
- exit(0);
- }
此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中, fd = 1 。这种现象叫做输出重定向。常见的重定向有:>, >>, <FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。所以C库当中的FILE结构体内部,必定封装了fd。缓冲区
来段代码在研究一下: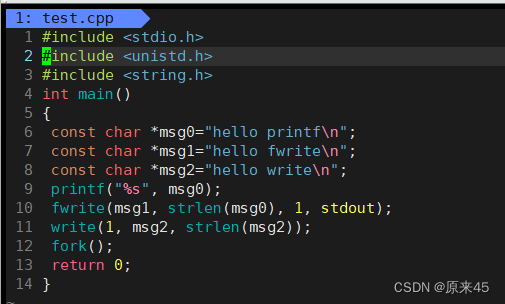
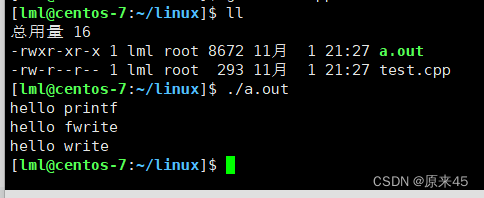 但如果对进程实现输出重定向呢? ./hello > file , 我们发现结果变成了:
但如果对进程实现输出重定向呢? ./hello > file , 我们发现结果变成了: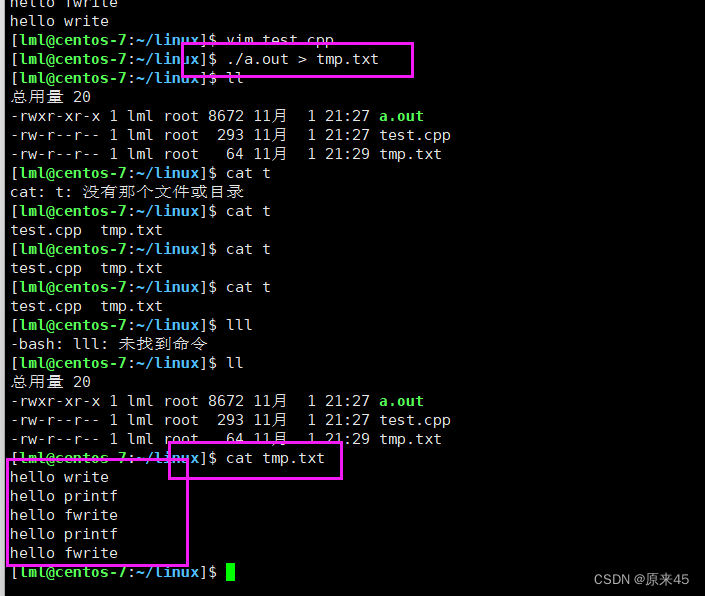 我们发现 printf 和 fwrite (库函数)都输出了 2 次,而 write 只输出了一次(系统调用)。为什么呢?肯定和fork有关!一般 C 库函数写入文件时是全缓冲的,而写入显示器是行缓冲。printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至 fork 之后但是进程退出之后,会统一刷新,写入文件当中。但是 fork 的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。write 没有变化,说明没有所谓的缓冲。综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区, 都是用户级缓冲区。其实为了提升整机性能,OS 也会提供相关内核级缓冲区,不过不再我们讨论范围之内。那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的 “ 上层 ” , 是对系统调用的“ 封装 ” ,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由 C 标准库提供(这里的缓冲区是属于语言级别的缓冲区)。输出重定向的时候有5条数据(行缓冲变成了全缓冲所以就算加了\n还是不能直接输出)可以看看FILE结构体:typedef struct _IO_FILE FILE ; 在 /usr/include/stdio.h
我们发现 printf 和 fwrite (库函数)都输出了 2 次,而 write 只输出了一次(系统调用)。为什么呢?肯定和fork有关!一般 C 库函数写入文件时是全缓冲的,而写入显示器是行缓冲。printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。而我们放在缓冲区中的数据,就不会被立即刷新,甚至 fork 之后但是进程退出之后,会统一刷新,写入文件当中。但是 fork 的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。write 没有变化,说明没有所谓的缓冲。综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区, 都是用户级缓冲区。其实为了提升整机性能,OS 也会提供相关内核级缓冲区,不过不再我们讨论范围之内。那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的 “ 上层 ” , 是对系统调用的“ 封装 ” ,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由 C 标准库提供(这里的缓冲区是属于语言级别的缓冲区)。输出重定向的时候有5条数据(行缓冲变成了全缓冲所以就算加了\n还是不能直接输出)可以看看FILE结构体:typedef struct _IO_FILE FILE ; 在 /usr/include/stdio.h标准输出和标准错误的区别(补充)

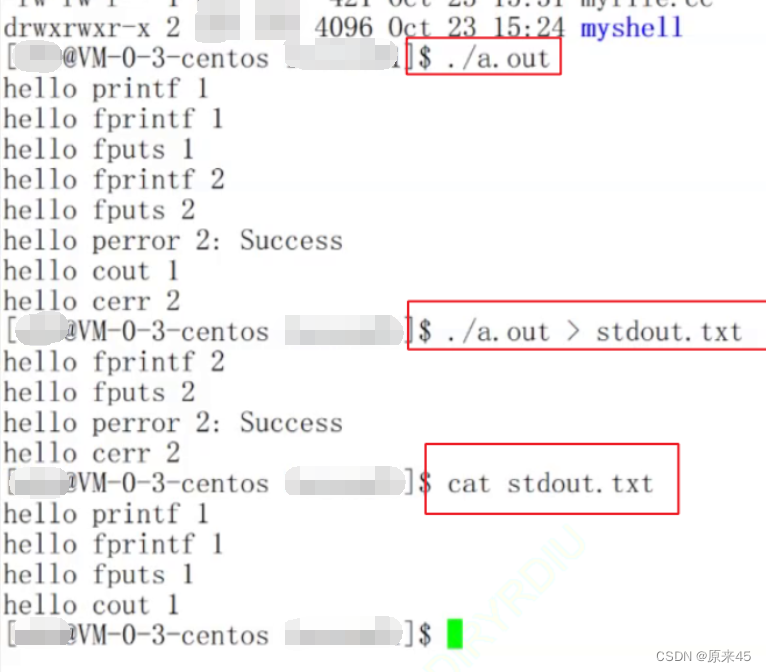
虽然都是向显示器打印,但是自己的文件描述符是不一样的,重定向只是对 1 重定向了
如何分开 1 2
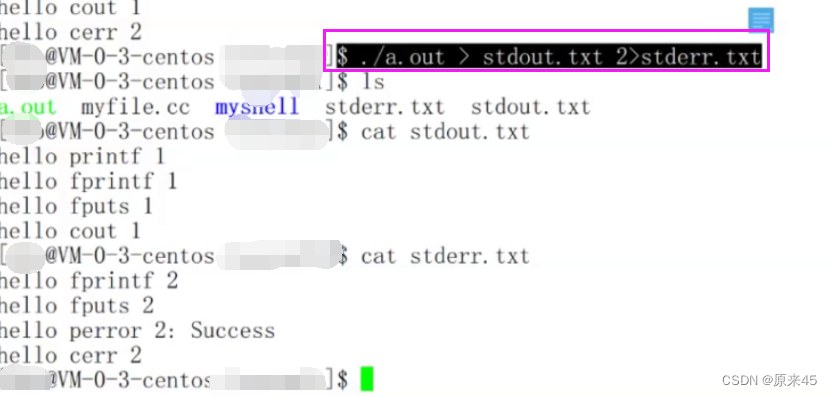
这么做的意义就是哪些是日常输出,哪些是错误
如何打到一起文件系统
什么是文件系统
上面的所以内容,都是内存中的东西,但是我们知道,大量的文件是在磁盘中的,也就是说我们需要去管理他们!而这就是文件系统(要做的工作)!关于磁盘
磁盘的存储结构

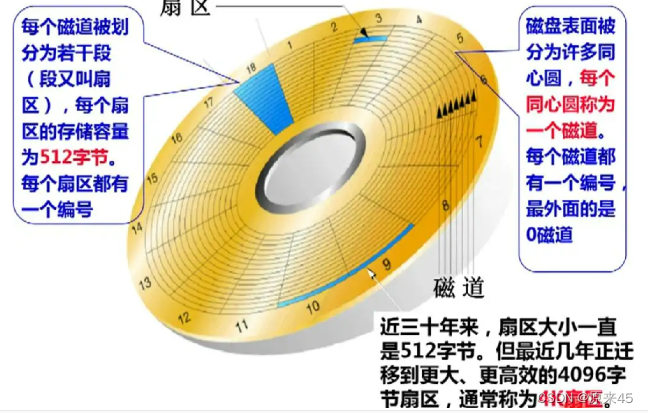 每片磁盘有两面,每面有很多磁道,每个磁道被分为n段,每小段称作扇区。
每片磁盘有两面,每面有很多磁道,每个磁道被分为n段,每小段称作扇区。所有盘的里圆心同距离的磁道组成磁柱。
虽然每个扇区是512byte,但是并不是意味着操作系统去访问的时候也是按1512byte去访问的,文件系统访问磁盘的基本单位是4KB
意义:
1. 提高IO效率(因为一下512byte太小了会频繁访问)
2. 不要让软件(OS)设计和硬件(磁盘)具有强相关性,换句话说,就是解耦合

CHS地址
想找到一个存储单元,我们只要找到他在磁盘上的那个盘面,那个磁道,那个扇区我们就可以找到他!用同样的方法,我们可以找到所有的基本单元!
磁盘的逻辑结构
还是先描述后组织。虽然磁盘是一盘一盘的进行存储,但是我们可以想象成像数组一样的线性存储结构,也就是LBA(逻辑块地址),这样对磁盘的管理就变成了对数组的管理。然后我们使用的是LBA地址去访问磁盘也就是把LBA地址转换为CHS(Clinder head Sector)地址。
inode
ls -i 可以看文件的 inode
磁盘那么大,我们就要进行管理。
为了能解释清楚 inode 我们先简单了解一下文件系统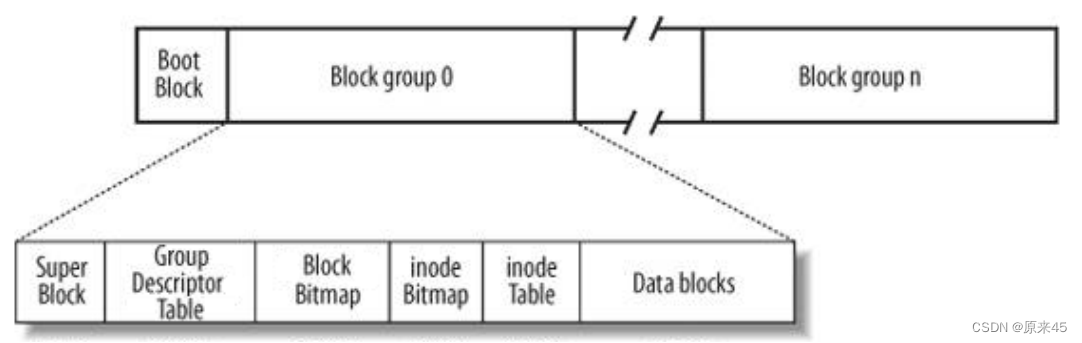 上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的 block 。一个 block 的大小是由格式化的时候确定的,并且不可以更改。例如 mke2fs 的 -b 选项可以设定block 大小为 1024 、 2048 或 4096 字节。而上图中启动块( Boot Block )的大小是确定的Block Group : ext2 文件系统会根据分区的大小划分为数个 Block Group 。而每个 Block Group 都有着相同的结构组成。政府管理各区的例子超级块( Super Block ):存放文件系统本身的结构信息。记录的信息主要有: bolck 和 inode 的总量,未使用的block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了GDT, Group Descriptor Table :块组描述符,描述块组属性信息块位图( Block Bitmap ): Block Bitmap 中记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用inode 位图( inode Bitmap ):每个 bit 表示一个 inode 是否空闲可用。i节点表 : 存放文件属性 如 文件大小,所有者,最近修改时间等数据区:存放文件内容(占大部分空间)
上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的 block 。一个 block 的大小是由格式化的时候确定的,并且不可以更改。例如 mke2fs 的 -b 选项可以设定block 大小为 1024 、 2048 或 4096 字节。而上图中启动块( Boot Block )的大小是确定的Block Group : ext2 文件系统会根据分区的大小划分为数个 Block Group 。而每个 Block Group 都有着相同的结构组成。政府管理各区的例子超级块( Super Block ):存放文件系统本身的结构信息。记录的信息主要有: bolck 和 inode 的总量,未使用的block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了GDT, Group Descriptor Table :块组描述符,描述块组属性信息块位图( Block Bitmap ): Block Bitmap 中记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用inode 位图( inode Bitmap ):每个 bit 表示一个 inode 是否空闲可用。i节点表 : 存放文件属性 如 文件大小,所有者,最近修改时间等数据区:存放文件内容(占大部分空间)SB(超级块):表示整个分区有多少个块,一个块组的inode table 和block 的使用情况,整个分区从磁盘的几号到几号分区是我的等等一些数据,宏观上管理的是整个分区
而GDP是管理分区中的一个组,剩余的段就是管理一个组的文件属性和文件内容
对应SB为什么不单独放出来,而是放在了Block group里面,其实并不是每个Block group里面都有,而是比如10个里面有2-3个有而且完全一样,主要是为了备份,就是怕损坏之后,整个分区全部没用了!(重要)那一个inode文件如何把自己的文件属性和文件内容关联起来呢?(在这里我们看到是分开存的)
首先 inode table 里面会有一个 inode 来标识 inode(每个 struct inode)的唯一性。然后是struct inode 里面会存有 一个blocks的数组,比如 blocks【15】,比如前12位置直接保存的就是该文件对应的blocks(Date blocks)编号,后面三个位置指向一个date blocks,但是这个 date blocks 不保存有效数据,而保存该文件所适用的其他块的编号。
文件名并不保存在 struct inode 里面
首先文件名是属性吗?答案是是。但是inode里面并不保存文件名,Linux下底层实际都是通过inode编号标识文件的!
那么我们怎么找到文件呢?找文件就要找到inode编号,那么inode编号谁告诉我呢?
其实是目录!目录也是文件,目录文件的内容就是文件名和inode的映射关系!,所以Linux同一个目录下,不可以创建多个同名文件,因为文件名本身就是具有Key值的东西。所以!创建一个文件的时候,一定是在一个目录下!
当我们创建一个文件,操作系统做了什么
首先创建的文件有自己的文件名和inode编号,然后去找到自己所处的目录,根据目录的inode,找到目录的dateblock,然后将文件名和inode编号的映射关系写入到目录的数据块中!
那么删除一个文件?
根据文件名在目录的文件内容里面找到删除文件的inode,然后根据删除文件的inode去找到自己的Blockbitmap和inodebitmap然后置为0就可以了!
上面是理论(重要),下面是实例:
将属性和数据分开存放的想法看起来很简单,但实际上是如何工作的呢?我们通过 touch 一个新文件来看看如何工作。当我们touch一个文件时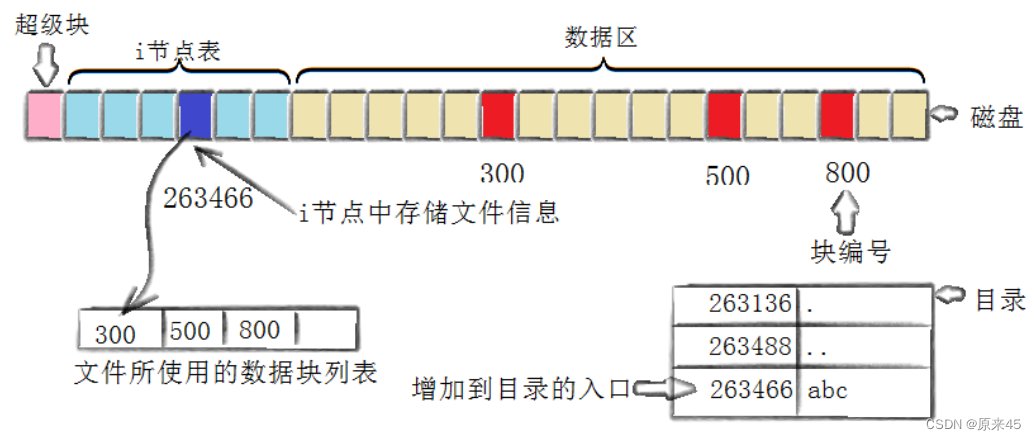
创建一个新文件主要有一下4个操作:
1. 存储属性内核先找到一个空闲的 i 节点(这里是 263466 )。内核把文件信息记录到其中。2. 存储数据该文件需要存储在三个磁盘块,内核找到了三个空闲块: 300,500 , 800 。将内核缓冲区的第一块数据复制到300 ,下一块复制到 500 ,以此类推。3. 记录分配情况文件内容按顺序 300,500,800 存放。内核在 inode 上的磁盘分布区记录了上述块列表。4. 添加文件名到目录新的文件名 abc 。 linux 如何在当前的目录中记录这个文件?内核将入口( 263466 , abc )添加到目录文件。文件名和inode 之间的对应关系将文件名和文件的内容及属性连接起来。软硬链接
软硬连接的创建
带 -s 的是软连接

软硬连接分析
软链接就是一个独立的文件(Linux下的快捷方式),有自己独立的inode和inode编号(既然是独立的文件,那就有其内容,里面存的就是指向文件的所在路径!)。
硬链接不是一个独立文件(单纯在Linux的指定目录下,给文件新增文件名和inode的映射关系),他和目标文件使用的是同一个inode。
最后的最后,创作不易,希望读者三连支持💖
赠人玫瑰,手有余香💖
-
相关阅读:
金九失足,10月喜提“Java高分指南”,11月冲击大厂
最长回文子串
如何在一台服务器上同时运行搭载JDK 8, JDK 17, 和 JDK 21的项目:终极指南
[CMD]常用命令
2022-8-18 第七小组 学习日记 (day42)JDBC+练习题
西安生物素-四聚乙二醇-酰胺-4苯酚 浅黄色半固态
【JavaEE基础学习打卡08】JSP之初次认识say hello!
【Ubuntu】Systemctl 管理 MinIO 服务器的启动和停止
优化|运筹学Management Science 6-7月文章精选:运筹学与金融业的契合
第五站:操作符(第二幕)
- 原文地址:https://blog.csdn.net/weixin_62700590/article/details/127624440